前言:
软工第一次作业是实现对文件夹中文件的词频统计,具体要求在博客中。
题目:软工第一次作业
需求:
1. 统计文件的字符数
2. 统计文件的单词总数
3. 统计文件的总行数
4. 统计文件中各单词的出现次数
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个
PSP:
| PSP | Personal Software Process Stages | Time /h | |
|---|---|---|---|
| Planning | 计划 | 20 | |
| Estimate | 估计这个任务需要多少时间 | 20 | |
| Development | 开发 | 52 | |
| Analysis | 需求分析 (包括学习新技术) | 2 | |
| Design Spec | 生成设计文档 | 1 | |
| Design | 具体设计 | 4 | |
| Coding | 具体编码 | 13 | |
| Code Review | 代码复审 | 2 | |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | |
| Reporting | 报告 | 10 | |
| Test Report | 测试报告 | 6 | |
| Size Measurement | 计算工作量 | 2 | |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 2 | |
思路:
一开始准备写个字典树,字典树的搜索效率是O(n)。转念一想,为什么不用Hash呢,Hash的查找只需要O(1),于是准备一鼓作气写个hash。Google如何写一个perfect的hash的时候,某位大佬提到了unordered_map。(在这感谢这位不愿意透露姓名的赵r大佬)。
然后Google Unordered_map 看到最全面的一篇blog就是这个,博主讲的很详细。
又恶补了一通map的用法,详情戳这里。
好了开始动工~
class word_time {
public:
string word; //最后输出的按照字典顺序的字母
int time; //单词出现的次数
public:
word_time(){ //构造函数,init
this->word = "";
this->time = 0;
}
};
unordered_map<string, word_time> word_list; //从“一个单词”到“单词最简形式和出现次数构成的类”的一个字典
主要思想就是这样了,废话不多说,直接上代码~
代码:
#include <io.h>
#include <iostream>
#include <unordered_map>
#include <string>
#include <cctype>
#include <algorithm>
#include <fstream>
using namespace std;
class word_time {
public:
string word;
int time;
public:
word_time(){
this->word = "";
this->time = 0;
}
};
class word_word_time : public word_time {
public:
string word_s;
word_word_time() {
this->time = 0;
this->word = "";
this->word_s = "";
}
void operator=(const word_word_time &another) {
this->time = another.time;
this->word = another.word;
this->word_s = another.word_s;
}
};
class bi_word {
public:
string str1;
string str2;
bi_word() {
this->str1 = "";
this->str2 = "";
}
bi_word(const bi_word &another) {
this->str1 = another.str1;
this->str2 = another.str2;
}
bool operator==(const bi_word &another) {
if (this->str1 == another.str1&&this->str2 == another.str2)
return true;
return false;
}
void operator=(const bi_word &another) {
this->str1 = another.str1;
this->str2 = another.str2;
}
};
unordered_map<string, word_time> word_list;
unordered_map<string, word_word_time> bi_word_list;
/*
判断一个char是不是字母
参数类型: char
*/
bool is_letter(char m) {
if (m >= 65 && m <= 90 || m >= 97 && m <= 122)
return true;
return false;
}
/*
判断一个char是不是分隔符
*/
bool is_fengefu(char m) {
if (m >= 65 && m <= 90 || m >= 97 && m <= 122 || m >= 48 && m <= 57)
return false;
return true;
}
/*
添加一个字母到word_list中,并统计词数
参数类型: string
*/
void add_a_word(string word) {
if (!is_letter(word[0]))
return; //如果word[0]不是字母就return
string word_ = word;
string::iterator it;
word_time word__time;
it = word.end();
it--;
while (!is_letter(*it)) {
it--;
}; //*it不是字母
word.erase(it+1, word.end()); //截取前面一部分
/*for (it = word.begin(); it - word.begin() < 4; it++) {
if (!is_letter(*it)) return;
}*/ //如果it前四位不是纯字母,直接
transform(word.begin(), word.end(), word.begin(), ::toupper); //转换为大写
//word_time one = word_list[word];
word_list[word].time++; //把化简后的word塞入word_list并++次数
if (word_list[word].word == "" || word_list[word].word.compare(word_)>0) {
word_list[word].word = word_;
} //如果word_比原来的小 就更新
}
/*
统计一行字符数
参数类型:string
*/
int count_char_sum(string str) {
return(str.length());
}
/*
声明一下add_a_bi_word函数
*/
void add_a_bi_word(bi_word b_word);
/*
将一行的单词输入进word_list,并生成n-1个词组,并将这n-1个词组输入进bi_word_list(其实是个map)
*/
int sum=0;
string str_temp,str_now;
void insert_into_wordlist(string &line) {
vector<vector<string>> wordlist_of_a_line_vec;
vector<bi_word> bi_wordlist_of_a_line;
bi_word temp;
//string::iterator it=line.begin(),it1=line.begin();
int it_last=0,it1;
bool flag=false;
line.append(" ");
for (; is_fengefu(line[it_last])&&(size_t)it_last<line.length(); it_last++);
for (int it=it_last; line[it]!= '\0'&& (size_t)it<line.length(); it++) {
if (is_fengefu(line[it])) {
for (it1 = it_last; it1 - it_last < 4 &&(size_t)it1<line.length(); it1++) {
if (!is_letter(line[it1])) {
flag = true;
break;
}
}//判断是否是单词 不是就丢掉
if (flag == false) {//如果是单词
/*if(wordlist_of_a_line_vec[0].size<40)
wordlist_of_a_line_vec[0].push_back(line.substr(it_last, it - it_last)); //插入进单词列表
else {
wordlist_of_a_line_vec[1].push_back(line.substr(it_last, it - it_last));
}*/
sum++;
str_now = line.substr(it_last, it - it_last);
add_a_word(str_now);
if (str_temp != "") {
temp.str1 = str_temp;
temp.str2 = str_now;
add_a_bi_word(temp);
}
str_temp = str_now;
}
/*for(int ii=0;wordlist_of_a_line_vec[ii].size()==40;ii++)*/
//wordlist_of_a_line_vec[0].push_back(line.substr(it_last, it - it_last));
flag = false;
it_last = it + 1;
}
}
//将单词列表一个个的map到map表中
/*int ii = 0;
for (vector<string>::iterator it1 = wordlist_of_a_line_vec[0].begin(); it1 < wordlist_of_a_line_vec[0].end(); it1++) {
add_a_word(*it1);//将单词一个一个的add进字典
if (it1 < wordlist_of_a_line_vec[0].end() - 1) {
bi_wordlist_of_a_line.push_back(temp);
bi_wordlist_of_a_line[ii].str1 = *it1;
bi_wordlist_of_a_line[ii].str2 = *(it1+1);
ii++;
} //插入词组列表
} //将单词一个一个的add进字典
for (vector<bi_word>::iterator it2 = bi_wordlist_of_a_line.begin(); it2 < bi_wordlist_of_a_line.end(); it2++) {
add_a_bi_word(*it2);
}*/
}
/*
将文件中出现频率最高的10个单词统计下来
返回一个vector<word_time>
*/
vector<word_time> the_most_ten() {
vector<word_time> most_ten(10);
unordered_map<string, word_time>::iterator it = word_list.begin();
while (it != word_list.end()) {
if (it->second.time > most_ten[9].time) {
if (it->second.time > most_ten[0].time)
most_ten.insert(most_ten.begin(), it->second);
else
for (int ii = 1; ii<=9; ii++) {
if (it->second.time > most_ten[ii].time && it->second.time <= most_ten[ii - 1].time) {
most_ten.insert(most_ten.begin() + ii, it->second);
break;
}
}
//if(it->second.time > most_ten[0].time)
//most_ten.insert(most_ten.begin(), it->second);
}
it++;
}
most_ten.erase(most_ten.begin() + 10, most_ten.end());
return most_ten;
}
/*
统计文件中的词组数,存入bi_word_list
*/
void add_a_bi_word(bi_word b_word) {
if (!is_letter(b_word.str1[0])|| !is_letter(b_word.str2[0]))
return; //如果word[0]不是字母就return
bi_word b_word_ = b_word;
string::iterator it1,it2;
word_word_time word_word__time;
it1 = b_word.str1.end();
it2 = b_word.str2.end();
it1--; it2--;
while (!is_letter(*it1)) {
it1--;
}; //*it不是字母
while (!is_letter(*it2)) {
it2--;
};
b_word.str1.erase(it1 + 1, b_word.str1.end()); //截取前面一部分
b_word.str2.erase(it2 + 1, b_word.str2.end());
/*for (it1 = b_word.str1.begin(); it1 - b_word.str1.begin() < 4; it1++) {
if (!is_letter(*it1)) return;
} //如果it前四位不是纯字母,直接
for (it2 = b_word.str2.begin(); it2 - b_word.str2.begin() < 4; it2++) {
if (!is_letter(*it2)) return;
}*/
transform(b_word.str1.begin(), b_word.str1.end(), b_word.str1.begin(), ::toupper); //转换为大写
transform(b_word.str2.begin(), b_word.str2.end(), b_word.str2.begin(), ::toupper);
string temp = b_word.str1 + b_word.str2;
bi_word_list[temp].time++; //把化简后的word塞入word_list并++次数
if (bi_word_list[temp].word == "" || (bi_word_list[temp].word+ bi_word_list[temp].word_s).compare(b_word_.str1+b_word_.str2)>0) {
bi_word_list[temp].word = b_word_.str1;
bi_word_list[temp].word_s = b_word_.str2;
} //如果word_比原来的小 就更新
}
//" hello fucking333 world hello fuck fuck abc fucking231 \n hello sd"
/*
将文件中出现频率最高的10个词组统计下来
返回一个vector<word_word_time>
*/
vector<word_word_time> the_most_ten_bi() {
vector<word_word_time> most_ten_bi(10);
word_word_time temp;
unordered_map<string, word_word_time>::iterator it = bi_word_list.begin();
while (it != bi_word_list.end()) {
/*most_ten_bi[10] = it->second;
for (int ii = 10; ii >= 1; ii--) {
if (most_ten_bi[ii].time > most_ten_bi[ii - 1].time) {
temp = most_ten_bi[ii];
most_ten_bi[ii] = most_ten_bi[ii - 1];
most_ten_bi[ii - 1] = temp;
}
}*/
if (it->second.time > most_ten_bi[9].time) {
if (it->second.time > most_ten_bi[0].time)
most_ten_bi.insert(most_ten_bi.begin(), it->second);
else
for (int ii = 1; ii <= 9; ii++) {
if (it->second.time > most_ten_bi[ii].time && it->second.time <= most_ten_bi[ii - 1].time) {
most_ten_bi.insert(most_ten_bi.begin() + ii, it->second);
break;
}
}
//if(it->second.time > most_ten[0].time)
//most_ten.insert(most_ten.begin(), it->second);
}
it++;
}
most_ten_bi.erase(most_ten_bi.begin() + 10, most_ten_bi.end());
return most_ten_bi;
}
/*
深度优先搜索文件夹和子目录
*/
long sum1 = 0;
int line_sum = 0;
void DfsFolder(string path, int layer)
{
_finddata_t file_info;
string current_path = path + "/*.*"; //也可以用/*来匹配所有
int handle = _findfirst(current_path.c_str(), &file_info);
//返回值为-1则查找失败
ifstream infile;
string temp, text;
if (-1 == handle)
{
cout << "cannot match the path" << endl;
return;
}
do
{
//判断是否子目录
if (file_info.attrib == _A_SUBDIR)
{
//递归遍历子目录
//打印记号反映出深度层次
/*for (int i = 0; i<layer; i++)
cout << "--";
cout << file_info.name << endl;*/
int layer_tmp = layer;
if (strcmp(file_info.name, "..") != 0 && strcmp(file_info.name, ".") != 0) //.是当前目录,..是上层目录,必须排除掉这两种情况
DfsFolder(path + '/' + file_info.name, layer_tmp + 1); //再windows下可以用\\转义分隔符,不推荐
}
else
{
//打印记号反映出深度层次
/*for (int i = 0; i<layer; i++)
cout << "--";
cout << file_info.name << endl;*/
infile.open(path + '/' + file_info.name, ios::in);
while (getline(infile, temp)) {
//text.append(temp);
//cout << temp << endl;
sum1 += temp.length();
line_sum++;
insert_into_wordlist(temp);
}
//insert_into_wordlist(text);
infile.close();
}
} while (!_findnext(handle, &file_info)); //返回0则遍历完
//关闭文件句柄
_findclose(handle);
}
int main() {
DfsFolder("E:/tales", 0);
word_time test = word_list["THAT"];
//前十词组
vector<word_word_time> a=the_most_ten_bi();
//前十单词
vector<word_time> b = the_most_ten();
//字符总数
sum1;
//单词总数
sum;
//总行数
line_sum;
//vector<word_word_time
}
/*
int main() {
bi_word a, b, c, d, e, f;
a.str1 = "hello"; a.str2 = "world";
b.str1 = "hello1"; b.str2 = "world";
c.str1 = "hello"; c.str2 = "world2";
d.str1 = "hello"; d.str2 = "fuck33";
e.str1 = "world"; e.str2 = "hello2";
f.str1 = "fucking"; f.str2 = "world";
add_a_bi_word(a);
add_a_bi_word(b);
add_a_bi_word(c);
add_a_bi_word(d);
add_a_bi_word(e);
add_a_bi_word(f);
}
*/
/*
int main() {
string h = " hello fucking333 world hello fuck fuck fuck abc fucking231 \n hello sd";
//string h = " abc";
insert_into_wordlist(h);
vector<word_time> ten_word=the_most_ten();
vector<word_word_time>ten_bi_word = the_most_ten_bi();
system("pause");
return 0;
}
*/
/*
int main() {
//定义结构体,在查找时,该结构体中存储了查找到文件相应的属性
_finddata_t file;
//查找所有文件,如果查找失败,则返回-1;查找成功,返回相应的句柄
int k;
long HANDLE;
k = HANDLE = _findfirst("*.*", &file);
//根据相应的句柄,可以依次查找下一个文件;直到无法查询到新的文件为止
while (k != -1) {
//cout << file.name << endl; 操作函数放在这
k = _findnext(HANDLE, &file);
}
_findclose(HANDLE);
return 0;
}*/
/*
int main() {
string word = "StRt123546";
if (!(word[0] >= 65 && word[0] <= 90 || word[0] >= 97 && word[0] <= 122))
return 0;
string word_ = word;
string::iterator it=word.end();
it--;
while (!(*it >= 65 && *it <= 90 || *it >= 97 && *it <= 122)) {
it--;
};//*it不是字母
word.erase(it+1, word.end());
for (it = word.begin(); it - word.begin() < 4; it++) {
if (!is_letter(*it)) return 0;
}
transform(word.begin(), word.end(), word.begin(), ::toupper);
word_list[word].time++; //把化简后的word塞入word_list并++次数
if (word_list[word].word == "" || word_list[word].word.compare(word_)) {
word_list[word].word = word_;
} //如果word_比原来的小 就更新
cout << word << endl;
system("pause");
return 0;
}*/
测试样例在main()的注释中,这是对每个单元的测试;
总测试集
1、空集

2、只有一个文本文件,且没有内容
3、只有一个文本文件,只有一个空格
4、只有一个文本文件,有一个空格和一个换行符
5、只有一个文本文件(极简情况)

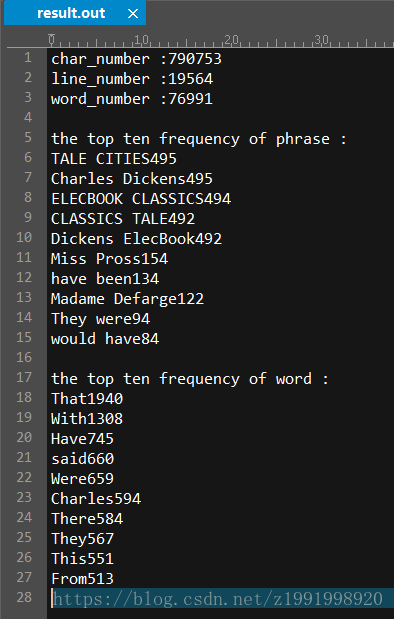
6、有两个文件,一个.txt(文本文件)和一个.pdf(二进制文件)

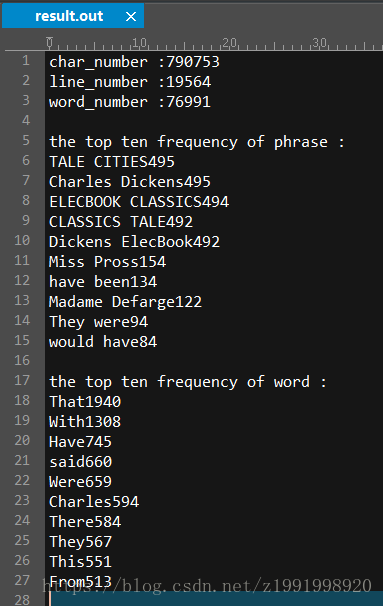
7、多文件多文件夹
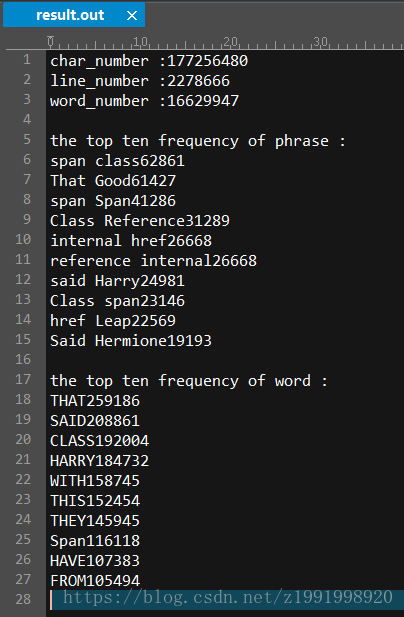
优化:
1、消除重复计算,在insert函数中减少每次的运算次数,代码运行时间减小5%左右;
2、改进读取模式,使用getline,虽然fread更快,但是对于某些样本不稳定,舍弃。代码稍微变快。
3、改进传参效率,使用引用string变量,使得代码运行时间平均减小30%;
4、删除word_list,采用即读即插的形式,使得代码运行时间平均减小10%;
附上最终代码:
#include <io.h>
#include <iostream>
#include <unordered_map>
#include <string>
#include <cctype>
#include <algorithm>
#include <fstream>
#include <time.h>
//#include <iomanip>
using namespace std;
class word_time {
public:
string word;
int time;
public:
word_time() {
this->word = "";
this->time = 0;
}
};
class word_word_time : public word_time {
public:
string word_s;
word_word_time() {
this->time = 0;
this->word = "";
this->word_s = "";
}
void operator=(const word_word_time &another) {
this->time = another.time;
this->word = another.word;
this->word_s = another.word_s;
}
};
class bi_word {
public:
string str1;
string str2;
bi_word() {
this->str1 = "";
this->str2 = "";
}
bi_word(const bi_word &another) {
this->str1 = another.str1;
this->str2 = another.str2;
}
bool operator==(const bi_word &another) {
if (this->str1 == another.str1&&this->str2 == another.str2)
return true;
return false;
}
void operator=(const bi_word &another) {
this->str1 = another.str1;
this->str2 = another.str2;
}
};
unordered_map<string, word_time> word_list;
unordered_map<string, word_word_time> bi_word_list;
/*
判断一个char是不是字母
参数类型: char
*/
bool is_letter(char m) {
if (m >= 65 && m <= 90 || m >= 97 && m <= 122)
return true;
return false;
}
/*
判断一个char是不是分隔符
*/
bool is_fengefu(char m) {
if (m >= 65 && m <= 90 || m >= 97 && m <= 122 || m >= 48 && m <= 57)
return false;
return true;
}
/*
添加一个字母到word_list中,并统计词数
参数类型: string
*/
void add_a_word(string word) {
if (!is_letter(word[0]))
return; //如果word[0]不是字母就return
string word_ = word;
string::iterator it;
word_time word__time;
it = word.end();
it--;
while (!is_letter(*it)) {
it--;
}; //*it不是字母
word.erase(it + 1, word.end()); //截取前面一部分
/*for (it = word.begin(); it - word.begin() < 4; it++) {
if (!is_letter(*it)) return;
}*/ //如果it前四位不是纯字母,直接
transform(word.begin(), word.end(), word.begin(), ::toupper); //转换为大写
//word_time one = word_list[word];
word_list[word].time++; //把化简后的word塞入word_list并++次数
if (word_list[word].word == "" || word_list[word].word.compare(word_)>0) {
word_list[word].word = word_;
} //如果word_比原来的小 就更新
}
/*
统计一行字符数
参数类型:string
*/
int count_char_sum(string str) {
return(str.length());
}
/*
声明一下add_a_bi_word函数
*/
void add_a_bi_word(bi_word b_word);
/*
将一行的单词输入进word_list,并生成n-1个词组,并将这n-1个词组输入进bi_word_list(其实是个map)
*/
int sum = 0;
string str_temp, str_now;
void insert_into_wordlist(string &line) {
vector<vector<string>> wordlist_of_a_line_vec;
vector<bi_word> bi_wordlist_of_a_line;
bi_word temp;
//string::iterator it=line.begin(),it1=line.begin();
int it_last = 0, it1;
bool flag = false;
line.append(" ");
for (; is_fengefu(line[it_last]) && (size_t)it_last<line.length(); it_last++);
for (int it = it_last; line[it] != '\0' && (size_t)it<line.length(); it++) {
if (is_fengefu(line[it])) {
for (it1 = it_last; it1 - it_last < 4 && (size_t)it1<line.length(); it1++) {
if (!is_letter(line[it1])) {
flag = true;
break;
}
}//判断是否是单词 不是就丢掉
if (flag == false) {//如果是单词
/*if(wordlist_of_a_line_vec[0].size<40)
wordlist_of_a_line_vec[0].push_back(line.substr(it_last, it - it_last)); //插入进单词列表
else {
wordlist_of_a_line_vec[1].push_back(line.substr(it_last, it - it_last));
}*/
sum++;
str_now = line.substr(it_last, it - it_last);
add_a_word(str_now);
if (str_temp != "") {
temp.str1 = str_temp;
temp.str2 = str_now;
add_a_bi_word(temp);
}
str_temp = str_now;
}
/*for(int ii=0;wordlist_of_a_line_vec[ii].size()==40;ii++)*/
//wordlist_of_a_line_vec[0].push_back(line.substr(it_last, it - it_last));
flag = false;
it_last = it + 1;
}
}
//将单词列表一个个的map到map表中
/*int ii = 0;
for (vector<string>::iterator it1 = wordlist_of_a_line_vec[0].begin(); it1 < wordlist_of_a_line_vec[0].end(); it1++) {
add_a_word(*it1);//将单词一个一个的add进字典
if (it1 < wordlist_of_a_line_vec[0].end() - 1) {
bi_wordlist_of_a_line.push_back(temp);
bi_wordlist_of_a_line[ii].str1 = *it1;
bi_wordlist_of_a_line[ii].str2 = *(it1+1);
ii++;
} //插入词组列表
} //将单词一个一个的add进字典
for (vector<bi_word>::iterator it2 = bi_wordlist_of_a_line.begin(); it2 < bi_wordlist_of_a_line.end(); it2++) {
add_a_bi_word(*it2);
}*/
}
/*
将文件中出现频率最高的10个单词统计下来
返回一个vector<word_time>
*/
vector<word_time> the_most_ten() {
vector<word_time> most_ten(10);
unordered_map<string, word_time>::iterator it = word_list.begin();
while (it != word_list.end()) {
if (it->second.time > most_ten[9].time) {
if (it->second.time > most_ten[0].time)
most_ten.insert(most_ten.begin(), it->second);
else
for (int ii = 1; ii <= 9; ii++) {
if (it->second.time > most_ten[ii].time && it->second.time <= most_ten[ii - 1].time) {
most_ten.insert(most_ten.begin() + ii, it->second);
break;
}
}
//if(it->second.time > most_ten[0].time)
//most_ten.insert(most_ten.begin(), it->second);
}
it++;
}
most_ten.erase(most_ten.begin() + 10, most_ten.end());
return most_ten;
}
/*
统计文件中的词组数,存入bi_word_list
*/
void add_a_bi_word(bi_word b_word) {
if (!is_letter(b_word.str1[0]) || !is_letter(b_word.str2[0]))
return; //如果word[0]不是字母就return
bi_word b_word_ = b_word;
string::iterator it1, it2;
word_word_time word_word__time;
it1 = b_word.str1.end();
it2 = b_word.str2.end();
it1--; it2--;
while (!is_letter(*it1)) {
it1--;
}; //*it不是字母
while (!is_letter(*it2)) {
it2--;
};
b_word.str1.erase(it1 + 1, b_word.str1.end()); //截取前面一部分
b_word.str2.erase(it2 + 1, b_word.str2.end());
/*for (it1 = b_word.str1.begin(); it1 - b_word.str1.begin() < 4; it1++) {
if (!is_letter(*it1)) return;
} //如果it前四位不是纯字母,直接
for (it2 = b_word.str2.begin(); it2 - b_word.str2.begin() < 4; it2++) {
if (!is_letter(*it2)) return;
}*/
//transform(b_word.str1.begin(), b_word.str1.end(), b_word.str1.begin(), ::toupper); //转换为大写
//transform(b_word.str2.begin(), b_word.str2.end(), b_word.str2.begin(), ::toupper);
for (string::iterator itfirst = b_word.str1.begin(); itfirst < b_word.str1.end(); itfirst++) {
if (*itfirst >= 'a') *itfirst -= 32;
}
for (string::iterator itsecond = b_word.str2.begin(); itsecond < b_word.str2.end(); itsecond++) {
if (*itsecond >= 'a') *itsecond -= 32;
}
string temp = b_word.str1 + b_word.str2;
bi_word_list[temp].time++; //把化简后的word塞入word_list并++次数
if (bi_word_list[temp].word == "" || (bi_word_list[temp].word + bi_word_list[temp].word_s).compare(b_word_.str1 + b_word_.str2)>0) {
bi_word_list[temp].word = b_word_.str1;
bi_word_list[temp].word_s = b_word_.str2;
} //如果word_比原来的小 就更新
}
//" hello fucking333 world hello fuck fuck abc fucking231 \n hello sd"
/*
将文件中出现频率最高的10个词组统计下来
返回一个vector<word_word_time>
*/
vector<word_word_time> the_most_ten_bi() {
vector<word_word_time> most_ten_bi(10);
word_word_time temp;
unordered_map<string, word_word_time>::iterator it = bi_word_list.begin();
while (it != bi_word_list.end()) {
/*most_ten_bi[10] = it->second;
for (int ii = 10; ii >= 1; ii--) {
if (most_ten_bi[ii].time > most_ten_bi[ii - 1].time) {
temp = most_ten_bi[ii];
most_ten_bi[ii] = most_ten_bi[ii - 1];
most_ten_bi[ii - 1] = temp;
}
}*/
if (it->second.time > most_ten_bi[9].time) {
if (it->second.time > most_ten_bi[0].time)
most_ten_bi.insert(most_ten_bi.begin(), it->second);
else
for (int ii = 1; ii <= 9; ii++) {
if (it->second.time > most_ten_bi[ii].time && it->second.time <= most_ten_bi[ii - 1].time) {
most_ten_bi.insert(most_ten_bi.begin() + ii, it->second);
break;
}
}
//if(it->second.time > most_ten[0].time)
//most_ten.insert(most_ten.begin(), it->second);
}
it++;
}
most_ten_bi.erase(most_ten_bi.begin() + 10, most_ten_bi.end());
return most_ten_bi;
}
/*
深度优先搜索文件夹和子目录
*/
long sum1 = 0;
int line_sum = 0;
void DfsFolder(string path, int layer)
{
_finddata_t file_info;
string current_path = path + "/*.*"; //也可以用/*来匹配所有
int handle = _findfirst(current_path.c_str(), &file_info);
//返回值为-1则查找失败
ifstream infile;
string temp, text;
if (-1 == handle)
{
cout << "cannot match the path" << endl;
return;
}
do
{
//判断是否子目录
if (file_info.attrib == _A_SUBDIR)
{
//递归遍历子目录
//打印记号反映出深度层次
/*for (int i = 0; i<layer; i++)
cout << "--";
cout << file_info.name << endl;*/
int layer_tmp = layer;
if (strcmp(file_info.name, "..") != 0 && strcmp(file_info.name, ".") != 0) //.是当前目录,..是上层目录,必须排除掉这两种情况
DfsFolder(path + '/' + file_info.name, layer_tmp + 1); //再windows下可以用\\转义分隔符,不推荐
}
else
{
//打印记号反映出深度层次
/*for (int i = 0; i<layer; i++)
cout << "--";
cout << file_info.name << endl;*/
infile.open(path + '/' + file_info.name, ios::in);
//line_sum++;
/*infile.seekg(0, ios::end);
if (infile.get() == '\n')
line_sum++;
infile.seekg(0, ios::beg);*/
while (getline(infile, temp)) {
//text.append(temp);
//cout << temp << endl;
sum1 += temp.length();
//if (temp.length()!=0)
line_sum++;
insert_into_wordlist(temp);
}
if (temp == "")line_sum++;
//insert_into_wordlist(text);
infile.close();
}
} while (!_findnext(handle, &file_info)); //返回0则遍历完
//关闭文件句柄
_findclose(handle);
}
int main(int argc, char * argv[]) {
//clock_t startTime, endTime;
//startTime = clock();
string path = argv[1];
DfsFolder(path, 0);
//DfsFolder("E:/Samples", 0);
ofstream outfile;
outfile.open("result.out", ios::out);
//outfile.flags(ios::left);
outfile << "char_number :" << sum1 << endl;
outfile << "line_number :" << line_sum << endl;
outfile << "word_number :" << sum << endl;
outfile << endl;
//outfile.open("result.out", ios::out);
vector<word_word_time> a = the_most_ten_bi();
outfile << "the top ten frequency of phrase :" << endl;
for (int ii = 0; ii < 10; ii++)
outfile << a[ii].word << ' ' << a[ii].word_s <<' '<< a[ii].time << endl;
vector<word_time> b = the_most_ten();
outfile << endl;
outfile << "the top ten frequency of word :" << endl;
for (int ii = 0; ii < 10; ii++)
outfile << b[ii].word << b[ii].time << endl;
outfile.close();
//endTime = clock();
//cout << "Totle Time : " << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
return 0;
}
/*
int main() {
//time_t start = clock();
DfsFolder("E:/Samples", 0);
//word_time test = word_list["THAT"];
//前十词组
vector<word_word_time> a=the_most_ten_bi();
cout << "bi_word_most" << endl;
for (int ii = 0; ii < 10; ii++)
cout << a[ii].word << ' ' << a[ii].word_s << ' ' << a[ii].time << endl;
//前十单词
vector<word_time> b = the_most_ten();
cout << "word_most" << endl;
for (int ii = 0; ii < 10; ii++)
cout << b[ii].word << ' ' << b[ii].time << endl;
//字符总数
cout << "char_sum" << endl;
cout << sum1 << endl;
//单词总数
cout << "word_sum" << endl;
cout << sum << endl;
//总行数
cout << "line_sum" << endl;
cout << line_sum << endl;
//time_t end = clock();
//cout << "xunxingshijian" << double(start - end) << endl;
system("pause");
//vector<word_word_time
}*/
/*
int main() {
bi_word a, b, c, d, e, f;
a.str1 = "hello"; a.str2 = "world";
b.str1 = "hello1"; b.str2 = "world";
c.str1 = "hello"; c.str2 = "world2";
d.str1 = "hello"; d.str2 = "fuck33";
e.str1 = "world"; e.str2 = "hello2";
f.str1 = "fucking"; f.str2 = "world";
add_a_bi_word(a);
add_a_bi_word(b);
add_a_bi_word(c);
add_a_bi_word(d);
add_a_bi_word(e);
add_a_bi_word(f);
}
*/
/*
int main() {
string h = " hello fucking333 world hello fuck fuck fuck abc fucking231 \n hello sd";
//string h = " abc";
insert_into_wordlist(h);
vector<word_time> ten_word=the_most_ten();
vector<word_word_time>ten_bi_word = the_most_ten_bi();
system("pause");
return 0;
}
*/
/*
int main() {
//定义结构体,在查找时,该结构体中存储了查找到文件相应的属性
_finddata_t file;
//查找所有文件,如果查找失败,则返回-1;查找成功,返回相应的句柄
int k;
long HANDLE;
k = HANDLE = _findfirst("*.*", &file);
//根据相应的句柄,可以依次查找下一个文件;直到无法查询到新的文件为止
while (k != -1) {
//cout << file.name << endl; 操作函数放在这
k = _findnext(HANDLE, &file);
}
_findclose(HANDLE);
return 0;
}*/
/*
int main() {
string word = "StRt123546";
if (!(word[0] >= 65 && word[0] <= 90 || word[0] >= 97 && word[0] <= 122))
return 0;
string word_ = word;
string::iterator it=word.end();
it--;
while (!(*it >= 65 && *it <= 90 || *it >= 97 && *it <= 122)) {
it--;
};//*it不是字母
word.erase(it+1, word.end());
for (it = word.begin(); it - word.begin() < 4; it++) {
if (!is_letter(*it)) return 0;
}
transform(word.begin(), word.end(), word.begin(), ::toupper);
word_list[word].time++; //把化简后的word塞入word_list并++次数
if (word_list[word].word == "" || word_list[word].word.compare(word_)) {
word_list[word].word = word_;
} //如果word_比原来的小 就更新
cout << word << endl;
system("pause");
return 0;
}*/
现在的调用树热行:
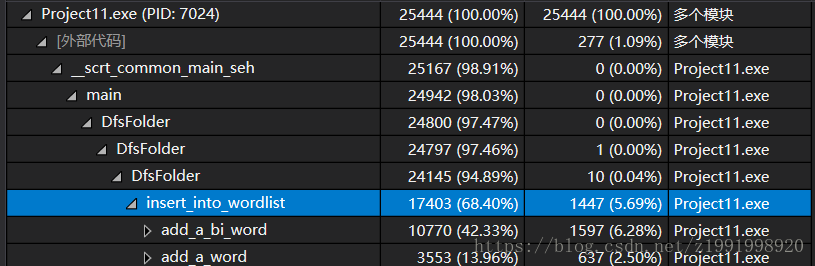
发现还是insert函数过于吃内存,然后看到最底端
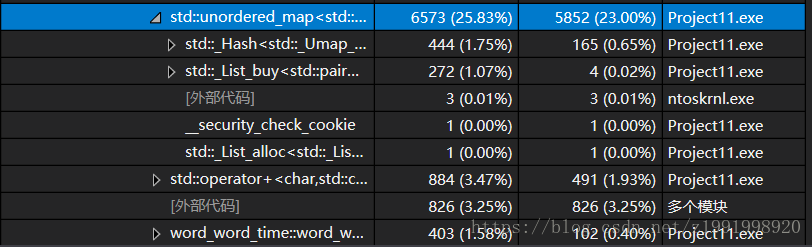
发现还是hash_map过于吃CPU了,但是这是数据结构本身的问题了,在调用数据结构的时候这个耗时已经决定了。可以说是优化的终点。
Linux下代码:
#include <dirent.h>
#include <sys/stat.h>
#include <iostream>
#include <unordered_map>
#include <string>
#include <cctype>
#include <algorithm>
#include <fstream>
#include<time.h>
#include <iomanip>
using namespace std;
class word_time {
public:
string word;
int time;
public:
word_time(){
this->word = "";
this->time = 0;
}
};
class word_word_time : public word_time {
public:
string word_s;
word_word_time() {
this->time = 0;
this->word = "";
this->word_s = "";
}
void operator=(const word_word_time &another) {
this->time = another.time;
this->word = another.word;
this->word_s = another.word_s;
}
};
class bi_word {
public:
string str1;
string str2;
bi_word() {
this->str1 = "";
this->str2 = "";
}
bi_word(const bi_word &another) {
this->str1 = another.str1;
this->str2 = another.str2;
}
bool operator==(const bi_word &another) {
if (this->str1 == another.str1&&this->str2 == another.str2)
return true;
return false;
}
void operator=(const bi_word &another) {
this->str1 = another.str1;
this->str2 = another.str2;
}
};
unordered_map<string, word_time> word_list;
unordered_map<string, word_word_time> bi_word_list;
/*
�ж�һ��char�Dz�����ĸ
��������: char
*/
bool is_letter(char m) {
if (m >= 65 && m <= 90 || m >= 97 && m <= 122)
return true;
return false;
}
/*
�ж�һ��char�Dz��Ƿָ��
*/
bool is_fengefu(char m) {
if (m >= 65 && m <= 90 || m >= 97 && m <= 122 || m >= 48 && m <= 57)
return false;
return true;
}
/*
���һ����ĸ��word_list�У���ͳ�ƴ���
�������ͣ� string
*/
void add_a_word(string word) {
if (!is_letter(word[0]))
return; //���word[0]������ĸ��return
string word_ = word;
string::iterator it;
word_time word__time;
it = word.end();
it--;
while (!is_letter(*it)) {
it--;
}; //*it������ĸ
word.erase(it+1, word.end()); //��ȡǰ��һ����
/*for (it = word.begin(); it - word.begin() < 4; it++) {
if (!is_letter(*it)) return;
}*/ //���itǰ��λ���Ǵ���ĸ��ֱ��
transform(word.begin(), word.end(), word.begin(), ::toupper); //ת��Ϊ��д
//word_time one = word_list[word];
word_list[word].time++; //�ѻ�����word����word_list��++����
if (word_list[word].word == "" || word_list[word].word.compare(word_)>0) {
word_list[word].word = word_;
} //���word_��ԭ����С ����
}
/*
ͳ��һ���ַ���
��������:string
*/
int count_char_sum(string str) {
return(str.length());
}
/*
����һ��add_a_bi_word����
*/
void add_a_bi_word(bi_word b_word);
/*
��һ�еĵ��������word_list,������n-1������,������n-1�����������bi_word_list����ʵ�Ǹ�map��
*/
int sum=0;
string str_temp,str_now;
void insert_into_wordlist(string &line) {
vector<vector<string>> wordlist_of_a_line_vec;
vector<bi_word> bi_wordlist_of_a_line;
bi_word temp;
//string::iterator it=line.begin(),it1=line.begin();
int it_last=0,it1;
bool flag=false;
line.append(" ");
for (; is_fengefu(line[it_last])&&(size_t)it_last<line.length(); it_last++);
for (int it=it_last; line[it]!= '\0'&& (size_t)it<line.length(); it++) {
if (is_fengefu(line[it])) {
for (it1 = it_last; it1 - it_last < 4 &&(size_t)it1<line.length(); it1++) {
if (!is_letter(line[it1])) {
flag = true;
break;
}
}//�ж��Ƿ��ǵ��� ���ǾͶ���
if (flag == false) {//����ǵ���
/*if(wordlist_of_a_line_vec[0].size<40)
wordlist_of_a_line_vec[0].push_back(line.substr(it_last, it - it_last)); //����������б�
else {
wordlist_of_a_line_vec[1].push_back(line.substr(it_last, it - it_last));
}*/
sum++;
str_now = line.substr(it_last, it - it_last);
add_a_word(str_now);
if (str_temp != "") {
temp.str1 = str_temp;
temp.str2 = str_now;
add_a_bi_word(temp);
}
str_temp = str_now;
}
/*for(int ii=0;wordlist_of_a_line_vec[ii].size()==40;ii++)*/
//wordlist_of_a_line_vec[0].push_back(line.substr(it_last, it - it_last));
flag = false;
it_last = it + 1;
}
}
//�������б�һ������map��map����
/*int ii = 0;
for (vector<string>::iterator it1 = wordlist_of_a_line_vec[0].begin(); it1 < wordlist_of_a_line_vec[0].end(); it1++) {
add_a_word(*it1);//������һ��һ����add���ֵ�
if (it1 < wordlist_of_a_line_vec[0].end() - 1) {
bi_wordlist_of_a_line.push_back(temp);
bi_wordlist_of_a_line[ii].str1 = *it1;
bi_wordlist_of_a_line[ii].str2 = *(it1+1);
ii++;
} //��������б�
} //������һ��һ����add���ֵ�
for (vector<bi_word>::iterator it2 = bi_wordlist_of_a_line.begin(); it2 < bi_wordlist_of_a_line.end(); it2++) {
add_a_bi_word(*it2);
}*/
}
/*
���ļ��г���Ƶ����ߵ�10������ͳ������
����һ��vector<word_time>
*/
vector<word_time> the_most_ten() {
vector<word_time> most_ten(10);
unordered_map<string, word_time>::iterator it = word_list.begin();
while (it != word_list.end()) {
if (it->second.time > most_ten[9].time) {
if (it->second.time > most_ten[0].time)
most_ten.insert(most_ten.begin(), it->second);
else
for (int ii = 1; ii<=9; ii++) {
if (it->second.time > most_ten[ii].time && it->second.time <= most_ten[ii - 1].time) {
most_ten.insert(most_ten.begin() + ii, it->second);
break;
}
}
//if(it->second.time > most_ten[0].time)
//most_ten.insert(most_ten.begin(), it->second);
}
it++;
}
most_ten.erase(most_ten.begin() + 10, most_ten.end());
return most_ten;
}
/*
ͳ���ļ��еĴ�����,����bi_word_list
*/
void add_a_bi_word(bi_word b_word) {
if (!is_letter(b_word.str1[0])|| !is_letter(b_word.str2[0]))
return; //���word[0]������ĸ��return
bi_word b_word_ = b_word;
string::iterator it1,it2;
word_word_time word_word__time;
it1 = b_word.str1.end();
it2 = b_word.str2.end();
it1--; it2--;
while (!is_letter(*it1)) {
it1--;
}; //*it������ĸ
while (!is_letter(*it2)) {
it2--;
};
b_word.str1.erase(it1 + 1, b_word.str1.end()); //��ȡǰ��һ����
b_word.str2.erase(it2 + 1, b_word.str2.end());
/*for (it1 = b_word.str1.begin(); it1 - b_word.str1.begin() < 4; it1++) {
if (!is_letter(*it1)) return;
} //���itǰ��λ���Ǵ���ĸ��ֱ��
for (it2 = b_word.str2.begin(); it2 - b_word.str2.begin() < 4; it2++) {
if (!is_letter(*it2)) return;
}*/
//transform(b_word.str1.begin(), b_word.str1.end(), b_word.str1.begin(), ::toupper); //ת��Ϊ��д
//transform(b_word.str2.begin(), b_word.str2.end(), b_word.str2.begin(), ::toupper);
for (string::iterator itfirst = b_word.str1.begin(); itfirst < b_word.str1.end(); itfirst++) {
if (*itfirst >= 'a') *itfirst -= 32;
}
for (string::iterator itsecond = b_word.str2.begin(); itsecond < b_word.str2.end(); itsecond++) {
if (*itsecond >= 'a') *itsecond -= 32;
}
string temp = b_word.str1 + b_word.str2;
bi_word_list[temp].time++; //�ѻ�����word����word_list��++����
if (bi_word_list[temp].word == "" || (bi_word_list[temp].word+ bi_word_list[temp].word_s).compare(b_word_.str1+b_word_.str2)>0) {
bi_word_list[temp].word = b_word_.str1;
bi_word_list[temp].word_s = b_word_.str2;
} //���word_��ԭ����С ����
}
//" hello fucking333 world hello fuck fuck abc fucking231 \n hello sd"
/*
���ļ��г���Ƶ����ߵ�10������ͳ������
����һ��vector<word_word_time>
*/
vector<word_word_time> the_most_ten_bi() {
vector<word_word_time> most_ten_bi(10);
word_word_time temp;
unordered_map<string, word_word_time>::iterator it = bi_word_list.begin();
while (it != bi_word_list.end()) {
/*most_ten_bi[10] = it->second;
for (int ii = 10; ii >= 1; ii--) {
if (most_ten_bi[ii].time > most_ten_bi[ii - 1].time) {
temp = most_ten_bi[ii];
most_ten_bi[ii] = most_ten_bi[ii - 1];
most_ten_bi[ii - 1] = temp;
}
}*/
if (it->second.time > most_ten_bi[9].time) {
if (it->second.time > most_ten_bi[0].time)
most_ten_bi.insert(most_ten_bi.begin(), it->second);
else
for (int ii = 1; ii <= 9; ii++) {
if (it->second.time > most_ten_bi[ii].time && it->second.time <= most_ten_bi[ii - 1].time) {
most_ten_bi.insert(most_ten_bi.begin() + ii, it->second);
break;
}
}
//if(it->second.time > most_ten[0].time)
//most_ten.insert(most_ten.begin(), it->second);
}
it++;
}
most_ten_bi.erase(most_ten_bi.begin() + 10, most_ten_bi.end());
return most_ten_bi;
}
/*
������������ļ��к���Ŀ¼
*/
long sum1 = 0;
int line_sum = 0;
void DfsFolder(string lname)
{
DIR *dir_ptr;
struct stat infobuf;
struct dirent *direntp;
string name, temp;
ifstream infile;
string text;
if ((dir_ptr = opendir(lname.c_str())) == NULL)
perror("can not open");
else
{
while ((direntp = readdir(dir_ptr)) != NULL)
{
temp = "";
name = direntp->d_name;
if (name == "." || name==".." )
{
;
}
else
{
temp+=lname;
temp+="/";
temp+=name;
//strcat(temp, lname);
//strcat(temp, "/");
//strcat(temp, name);
if ((stat(temp.c_str(), &infobuf)) == -1)
printf("#########\n");
if ((infobuf.st_mode & 0170000) == 0040000)
{
//printf("%s",name);
//printf(" this is a directory\n");
DfsFolder(temp);
}
else
{
//printf("%s",name);
//printf(" this is a file\n");
infile.open(temp, ios::in);
//line_sum++;
while (getline(infile, text)) {
//text.append(temp);
//cout << temp << endl;
sum1 += text.length();
line_sum++;
insert_into_wordlist(text);
}
if(temp == "") line_sum++;
//insert_into_wordlist(text);
infile.close();
}
}
}
}
closedir(dir_ptr);
}
int main(int argc, char * argv[]) {
string path=argv[1];
DfsFolder(path);
ofstream outfile;
outfile.open("result.out", ios::out);
//outfile.flags(ios::left);
outfile << "char_number :" << sum1 << endl;
outfile << "line_number :" << line_sum << endl;
outfile << "word_number :" << sum << endl;
outfile << endl;
//outfile.open("result.out", ios::out);
vector<word_word_time> a=the_most_ten_bi();
outfile << "the top ten frequency of phrase :" << endl;
for (int ii = 0; ii < 10; ii++)
outfile << a[ii].word << ' ' << a[ii].word_s <<setw(10) << a[ii].time << endl;
vector<word_time> b = the_most_ten();
outfile << endl;
outfile << "the top ten frequency of word :" << endl;
for (int ii = 0; ii < 10; ii++)
outfile << b[ii].word << setw(10) << b[ii].time << endl;
outfile.close();
}
/*
int main() {
bi_word a, b, c, d, e, f;
a.str1 = "hello"; a.str2 = "world";
b.str1 = "hello1"; b.str2 = "world";
c.str1 = "hello"; c.str2 = "world2";
d.str1 = "hello"; d.str2 = "fuck33";
e.str1 = "world"; e.str2 = "hello2";
f.str1 = "fucking"; f.str2 = "world";
add_a_bi_word(a);
add_a_bi_word(b);
add_a_bi_word(c);
add_a_bi_word(d);
add_a_bi_word(e);
add_a_bi_word(f);
}
*/
/*
int main() {
string h = " hello fucking333 world hello fuck fuck fuck abc fucking231 \n hello sd";
//string h = " abc";
insert_into_wordlist(h);
vector<word_time> ten_word=the_most_ten();
vector<word_word_time>ten_bi_word = the_most_ten_bi();
system("pause");
return 0;
}
*/
/*
int main() {
//����ṹ�壬�ڲ���ʱ���ýṹ���д洢�˲��ҵ��ļ���Ӧ������
_finddata_t file;
//���������ļ����������ʧ�ܣ��
用grof进行代码分析:

可以看到跑了之后还是 在unordered_map的Hash函数占用了很多CPU 占用很多内存

在调用树的层面上,可以看到遍历、插入unmap的过程非常耗时,但是由于stl的局限性,也有同学试着自己写hash,发现效果还没有stl好。
总结:
这个项目主要是通过unmap模拟字典,当然其实这个项目用python实现效果会更好。所有的单词化简后存入unmap,这样豁免的统计会很方便。