我们在爬取漫画的过程中,会不会觉得比爬一般的图片更困难一点? 今天我是遇到了, 但还是找了一些方法成功实现了它,那下面经验总结一下吧! 我是沙漏,关注我,不定期更新爬虫文章, 其他时间学linux 和 java 中!

【这很骚】好咧,废话不多说,这次我们爬的是一个国产动漫
============== 百妖谱 =================
网址: https://m.happymh.com/manga/baiyaopu
老规矩, 先讲爬虫思想, 后面再说代码实现。
漫画爬虫:
爬虫思想:
漫画爬虫和其他图片的爬虫是不一样的, 如果是其他图片的爬取, 小可直接request抓取, 大可scrapy 框架全网抓, 这一次,我没有使用scrapy框架去爬这个网站, 理由如下:
-
第一点, 我发现在csdn中讲scrapy框架而言, 访问量会很少, 一般都是爬虫新手小白居多, 这些人不是很懂这个框架的实现思想,对于知识点很难的讲, 其实效果还不如讲一点简易上手的小爬虫更加实在点,所以我还是用简单点的代码,效果更好哟。
-
第二点, 刚开始看这个网站的时候, 我就发现有一点问题了, 存在一个这样的按钮, 如图:
-
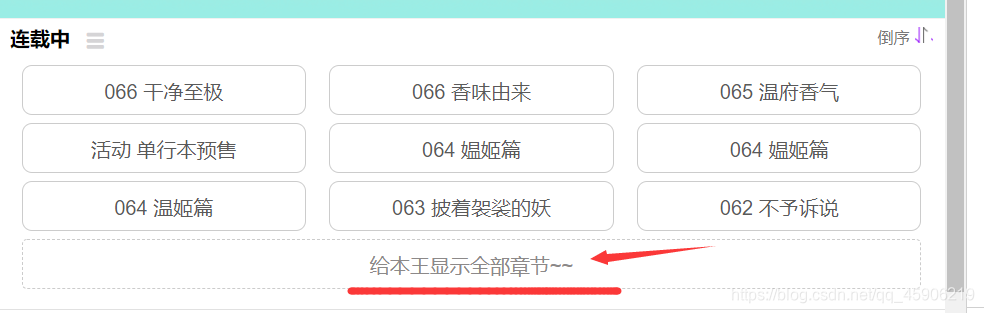
这是一个js按钮, 而且有开启的按钮, 还有收缩的按钮, 所以存在一个问题, 如果使用scrapy框架来说, 那么第一步就得在middle中去拦截这个请求,使用selenium去捕获, 天啊,这对于我们来说,太不友好了, 所以思考了一下,还是放弃了这个框架的使用, 于是转手简单的代码实现。 -
其他思想:
-
首先,我们需要使用
selenium去自动的点击这个按钮, 这个必须掌握的,爬虫还是要会点其他技巧, 展示出全部章节之后,就可以获得章节的url链接了, 这个我想大家应该都会, 重要的一点, 就是漫画页面的解析,这个就很让我们纠结了,解析三圣器–soup re xpath这三个到底选谁呢, 最后我还是选择了re, 为什么选择这个, 后面讲原因, 获得图片链接,之后就是下载环节了, 下载还是简单的, 只需要考虑到一点点因素,比如,章节标题,文件的重名混乱等等, 认真考虑下, 还是很容易做到的。
爬虫重要的点:
js按钮的问题:
【在上文中,我们讲到这个漫画爬虫有一个显示全部章节的按钮,所以我们要使用selenium去自动点击它,打开网页源代码, 我们查看一下 html网页, 如图:】
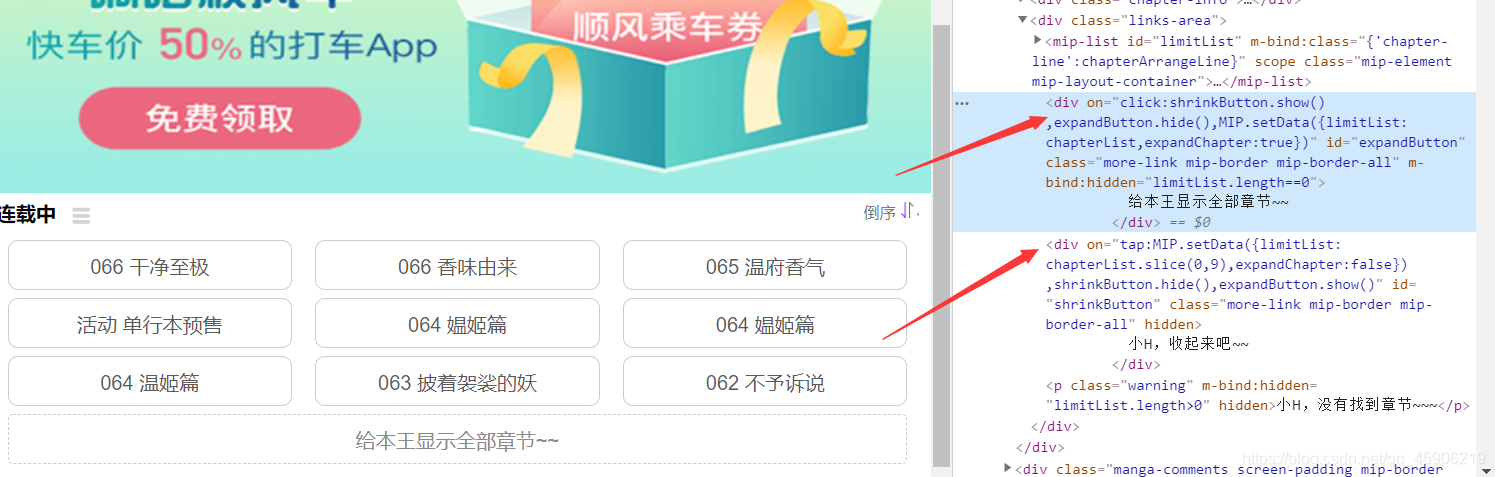
讲道理来说, 我们只需要定位到这个按钮, 然后点击它,就很顺利的完成了这个工作对吧, 但是经过我的代码测试, 结果还是出现了一个错误。
错误提示:Element:ElementClickInterceptedException
看了下, 发现是存在其他类是元素相互掩盖, 导致selenium无法正确的定位到这个按钮, 然后我回去看了下, 发现确实有一个 收起 按钮, 这二个按钮就相互冲突了, 开心的事情是,我成功的搞定了它,✌✌✌
get_all = self.browser.find_element_by_xpath('//*[@id="expandButton"]')
# 有多个节点掩盖 该 按钮 使用如下js方式 可以避免
self.browser.execute_script("arguments[0].click();", get_all)
【这里至于为什么是0? 不用我说吧, 从0开始计数!】
页面url获取的点:
- 大部分情况下, 我都是使用xpath去获取页面的节点来定位, 我觉得这样很快, xpath 确实很快, 但是在这个页面中, 我发现不能使用这个方式, 因为他所有url 都放在一个json数据包里面, 这样我们使用xpath就很难去处理所以我使用了正则, 直接去匹配这些页面, 效率一般, 但很简单理解。
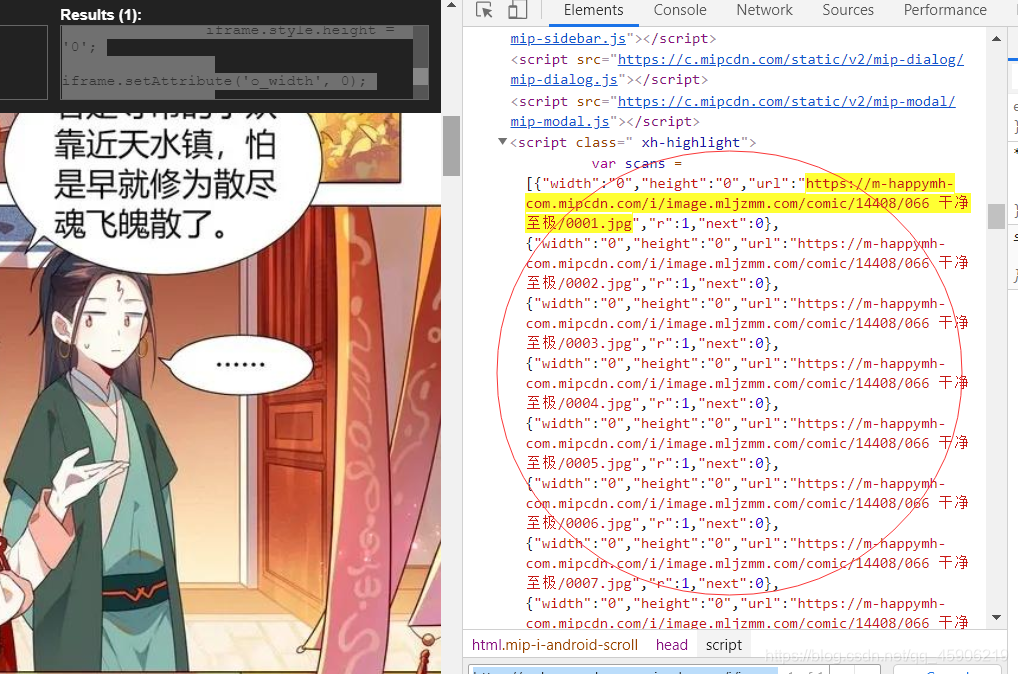
正则匹配方式:
title = re.search(r'.*?<title>(.*)</title>', r.text, re.S).groups(1)
title = '-'.join(list(title)[0].split('-')[:2])
img_urls = re.findall(r'{"width":"0","height":"0","url":"(.*?)","r":1,"next":0}', r.text, re.S
关于章节出现重名的点:
一般情况下,是不可能会出现章节同名的错误, 但结果我爬的这个文章,居然出现了这样的低级错误, 我的天啊, 这个前端人员是怎么写代码的, 好在,一山更比一山高,我可以搞你。

我是给了一个初始技术,也是用最笨的方式, 字符判定, 如果出现了这个章节, 那么就在后面 加 数字 123—这样的,如果我们不修改标题的名称, 那么就会出现文件夹重名, 文件夹重名是直接覆盖的方式的, 前面下载的文件就会丢失, 被重现掩盖掉, 所以这个点也需要注意,
self.count = 0
# 刚看到这只鸡有三个一样的章节, 在这里调试一下
if '媪姬篇' in title:
title += str(self.count)
self.count += 1
其他的点,我看起来就无关紧要了, 我的爬虫博客不会那么简单, 也不会那么复杂, 太简单的爬虫在我看来,没什么用处的, 只有文章有一定的难度,这样学习才有 动力, 才能获取知识,而不是按部就班, 墨守成规!
下面就是全部的代码, 看到这里, 觉得有用的朋友, 关注, 点赞, 支持一下, 多谢!!!
代码:
# -*- coding : utf-8 -*-
# @Time : 2020/7/21 21:18
# @author : 沙漏在下雨
# @Software : PyCharm
# @CSDN : https://me.csdn.net/qq_45906219
import requests
from lxml import etree
from selenium import webdriver
import time
import os
import re
class Cartoon_BYP(object):
"""
利用普通方式 搭配selenium去抓取该漫画
后续 使用scrapy框架去搭配使用
"""
def __init__(self):
self.count = 1
self.url = "https://m.happymh.com/manga/baiyaopu"
self.params = {
"Host": "m.happymh.com",
"Referer": "https://cn.bing.com/",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
" AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/81.0.4044.129 Safari/537.36"
}
# 设置 selenium 浏览器
self.browser = webdriver.Chrome()
self.start()
def start(self):
"""
进行主页面的解析, 让浏览器自动点击 显示全部 这个按钮
"""
try:
self.browser.get(self.url)
get_all = self.browser.find_element_by_xpath('//*[@id="expandButton"]')
# 有多个节点掩盖 该 按钮 使用如下js方式 可以避免
self.browser.execute_script("arguments[0].click();", get_all)
time.sleep(0.5)
print("按钮已经点击, 可以获得全部章节")
html = self.browser.page_source
for url in self.parse_home(html):
title, img_urls = self.parse_chapter(url)
self.down_img(title, img_urls)
print('百妖谱全部下载完成!')
except Exception as e:
print('点击错误', e)
def down_img(self, title, img_urls):
"""
开始下载图片, 根据标题 和 网址
"""
# 创建总目录
path = r'D:/百妖谱/'
if not os.path.exists(path):
os.mkdir(path)
# 创建章节目录
os.chdir(path)
# 刚看到这只鸡有三个一样的章节, 在这里调试一下
if '媪姬篇' in title:
title += str(self.count)
self.count += 1
if not os.path.exists(os.path.join(path, title)):
os.mkdir(os.path.join(path, title))
os.chdir(os.path.join(path, title))
else:
os.chdir(os.path.join(path, title))
# 开始下载图片
for _ in img_urls:
time.sleep(1.2)
r = requests.get(_, params=self.params)
if r.status_code == 200:
name = _.split('/')[-1]
with open(name, 'wb') as fw:
fw.write(r.content)
print(f'{title}系列下载成功 {name}')
else:
# 如果404 则一直回溯
self.down_img(title, _.split())
print(r.status_code)
# else:
# print('下载图片可能封Ip')
def parse_home(self, html):
"""解析主页, 获得全部章节的网址,
然后传给下载函数
"""
html_ = etree.HTML(html)
url = html_.xpath('//*[@id="limitList"]/div/div/a/@href')
for i in url:
yield i
def parse_chapter(self, url):
"""
解析首页
"""
r = requests.get(url, params=self.params)
if r.status_code == 200:
title = re.search(r'.*?<title>(.*)</title>', r.text, re.S).groups(1)
# title进行字符串处理 截取需要点
title = '-'.join(list(title)[0].split('-')[:2])
img_urls = re.findall(r'{"width":"0","height":"0","url":"(.*?)","r":1,"next":0}', r.text, re.S)
return title, img_urls
else:
print('可能被封ip了, 需要稍等时间')
Cartoon_BYP()