python 环境请先自主安装哦O(∩_∩)O
前期工作
先安装 chrome driver
插件网站:chrome driver
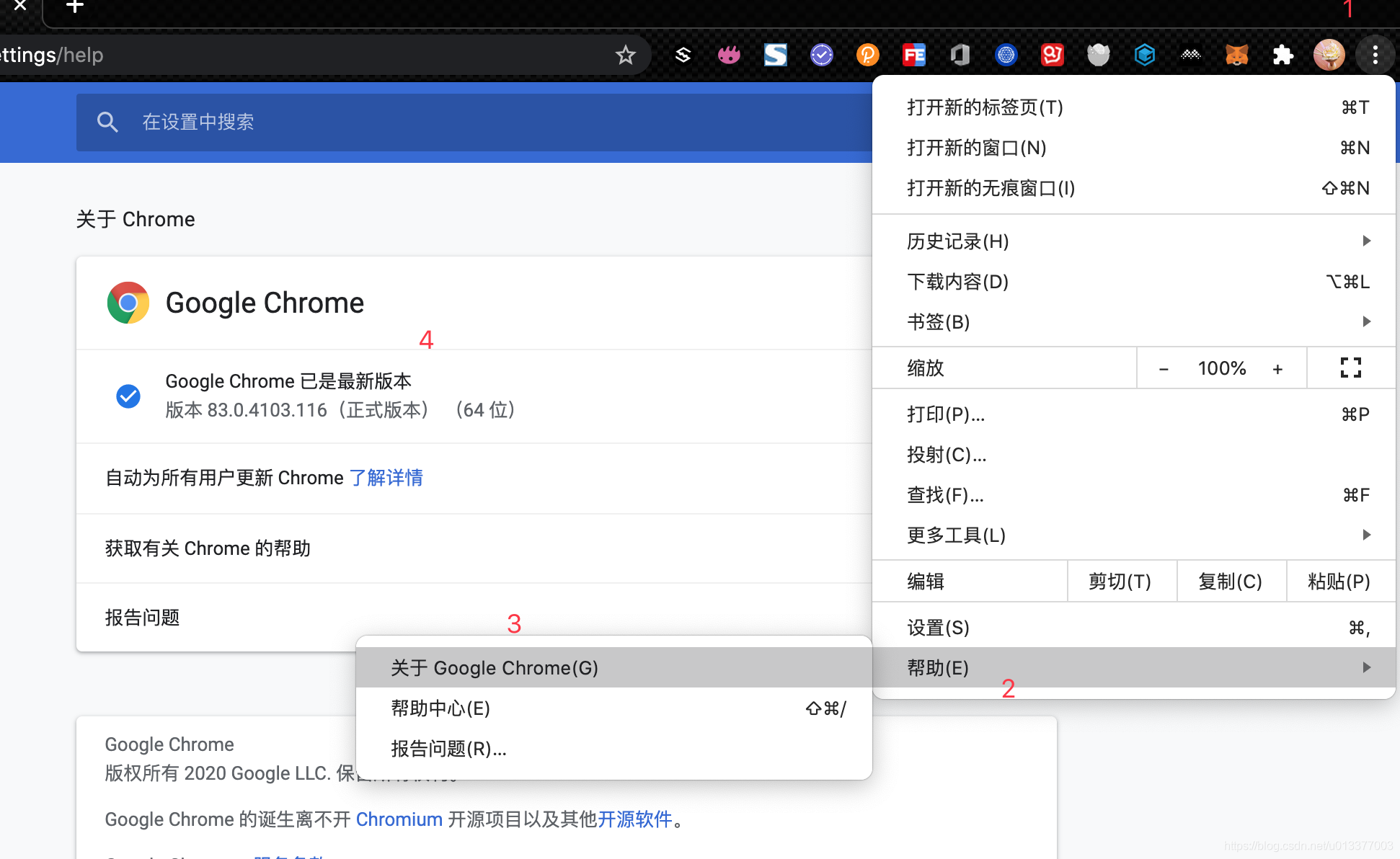
在插件网站找到对应的下载:
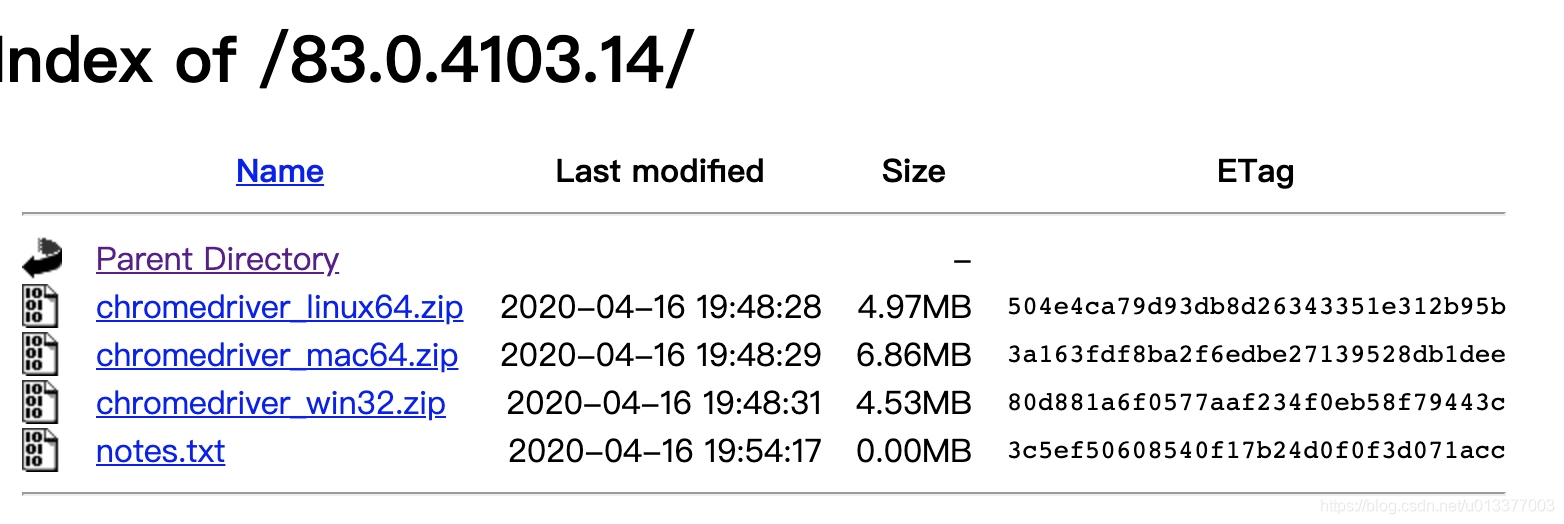
解压移动:
有版本号显示成功

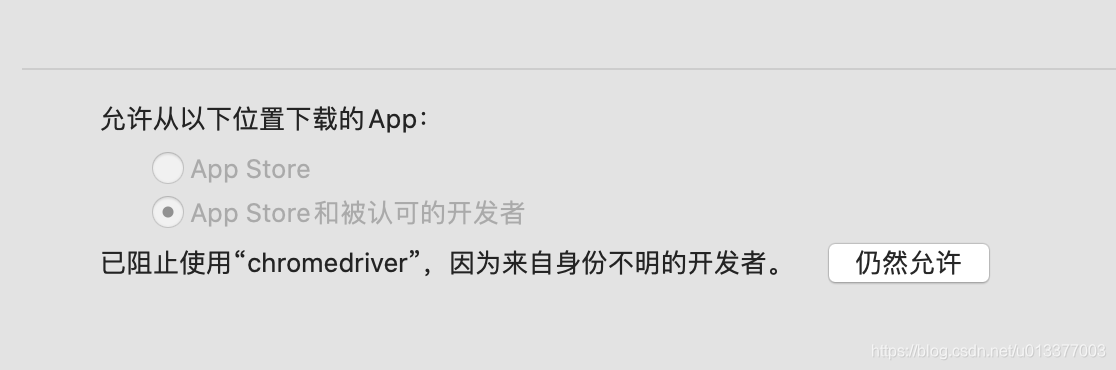
mac下记得,一定要放开权限!!!!
先上图演示结果:

只展示一部分,因为数据源太多了,最后会放出完整代码
原理就是,代码控制浏览器,异步加载数据之后,可以获取完整的网页数据
(此网站仅供参考使用,请大家测试别的数据,原理都是一样的)
必要库,记得导入
import time
from selenium import webdriver
from selenium.webdriver.common.by import By # 与下面的2个都是等待时要用到
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
登录部分:
先查看网页的数据:登录网站
网页怎么查看就不教学了
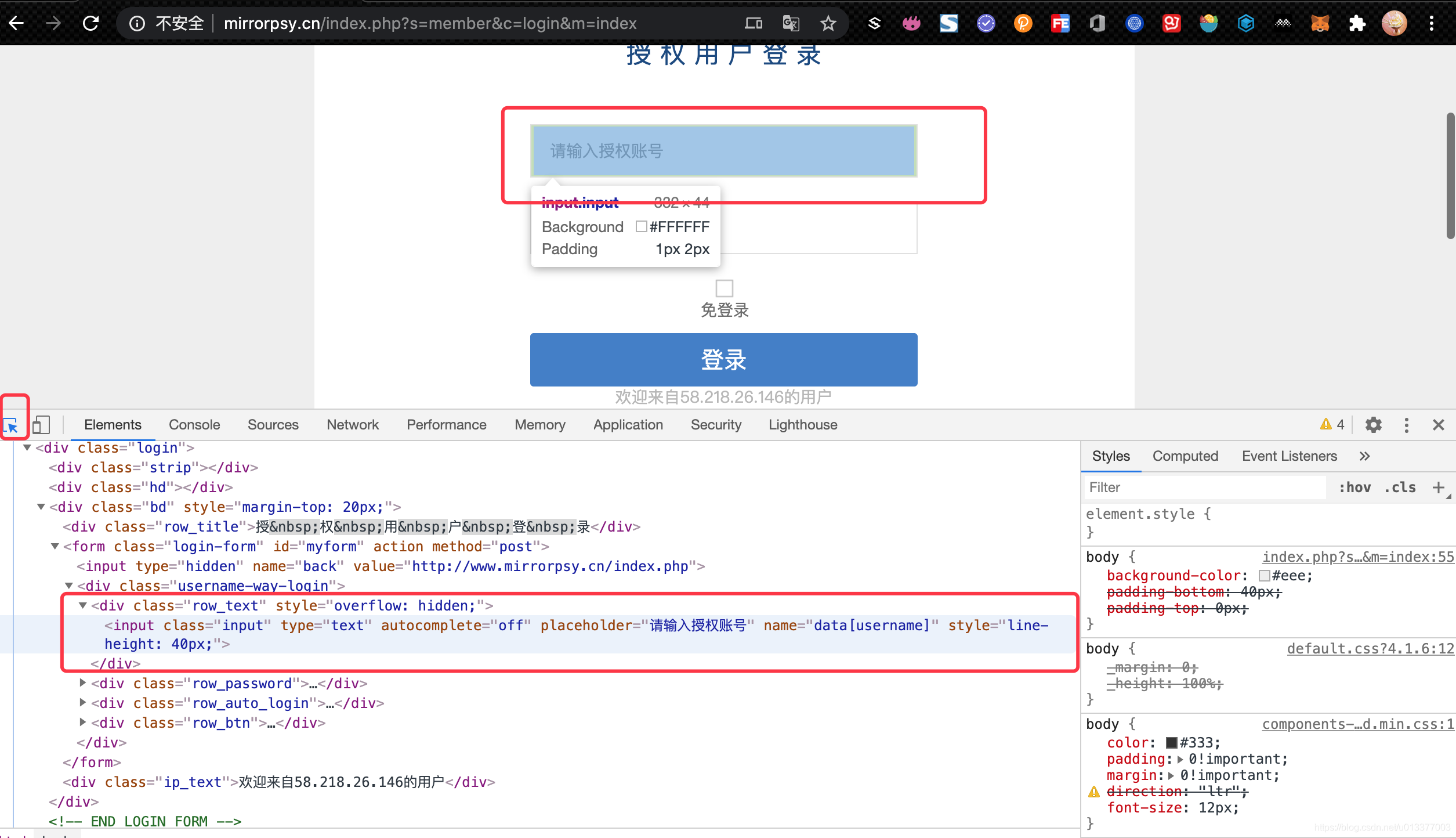
1、获取两个input的xpath
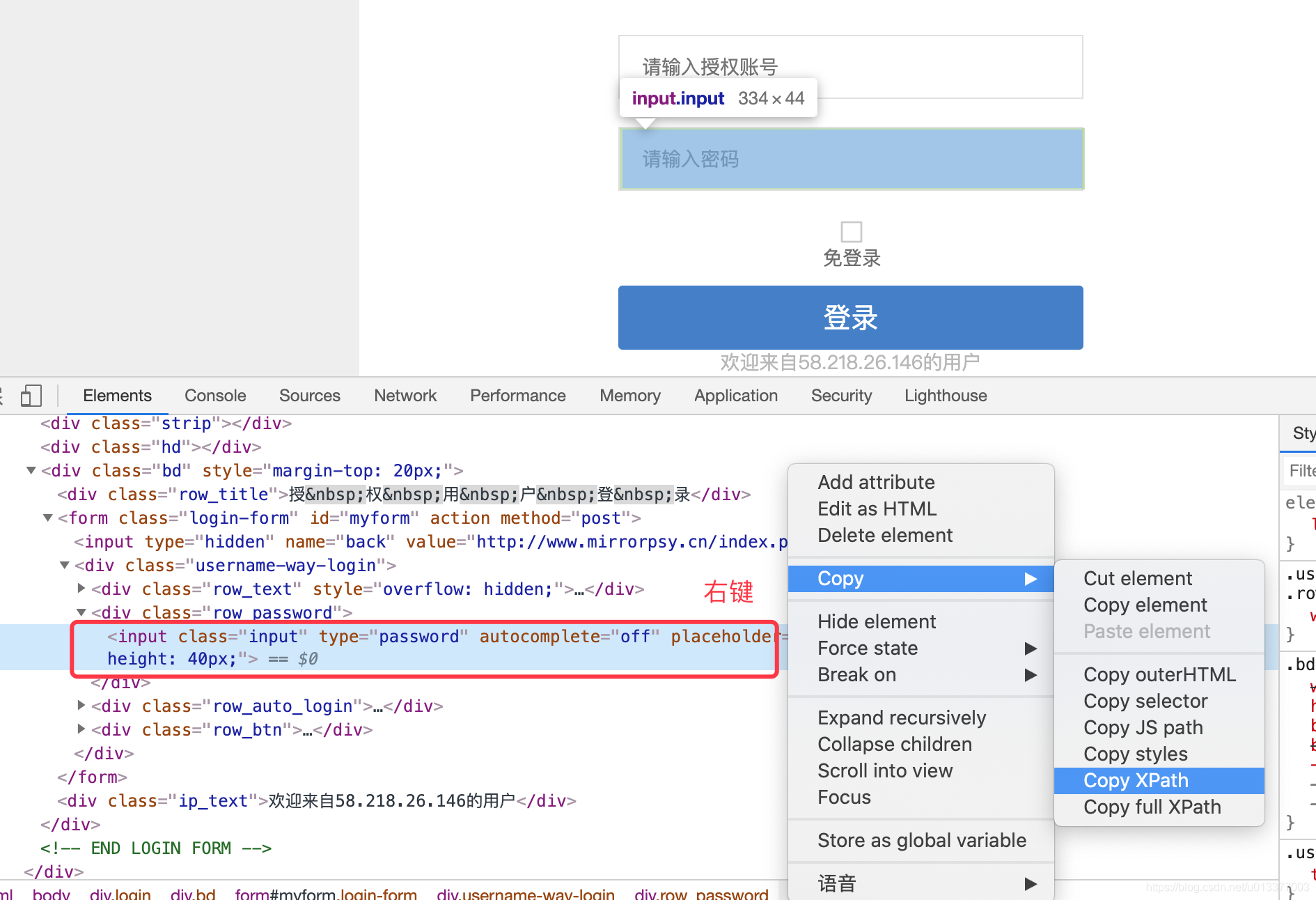
代码:填充用户名密码:
url = 'http://www.mirrorpsy.cn/index.php?s=member&c=login&m=index'
driver = webdriver.Chrome()
driver.get(url)
wait = WebDriverWait(driver, 25)
driver.maximize_window() # 窗口最大化
user = wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="myform"]/div/div[1]/input')))
user.send_keys('xxxx') # 用户密码就不暴露了
pw = wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="myform"]/div/div[2]/input')))
pw.send_keys('xxxxx')
print('login param input success')
直接运行,可看到浏览器自动启动,并且输入了用户名密码
2、登录
获取登录按钮的xpath
login = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="myform"]/div/div[4]/button'))) # 登录按钮
login.click()
print('login success')
time.sleep(10)
睡10s为了使网页完全加载
3、cookies
有些网站会用到cookies,但是这个网站【没有用到】,把获取cookies的贴出来
扫描二维码关注公众号,回复:
14793636 查看本文章

cookies = driver.get_cookies()
cookie_list = []
for dict in cookies:
cookie = dict['name'] + '=' + dict['value']
cookie_list.append(cookie)
cookie = ';'.join(cookie_list)
print('cookie' + cookie)
4、正式爬取数据,获取图片链接
这一段就是需要的图片列表(分页过会讲)
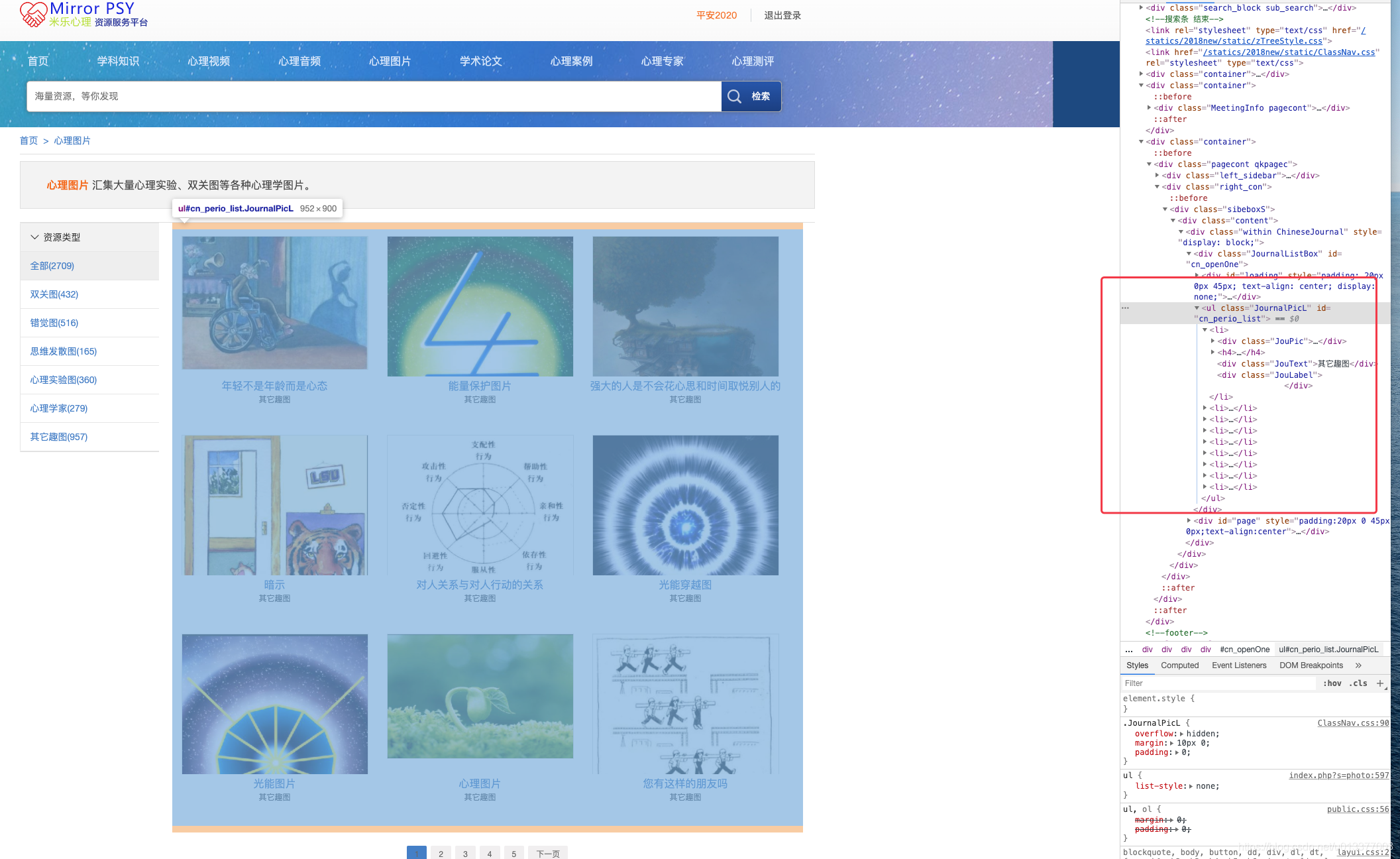
直接查看 ul 标签的xpath(这里就不教了,上面有查看的方法)
//*[@id=“cn_perio_list”]
获取后拿到 ul 下面的标签li:
items = driver.find_element_by_xpath('//*[@id="cn_perio_list"]')
lis = items.find_elements_by_xpath('li')
获取的 li 是个集合,遍历获取子标签 a,并获取 a 的属性 src
for li in lis:
imgs = li.find_element_by_tag_name('img')
print(imgs)
print(imgs.get_attribute('src'))
image_list.append(imgs.get_attribute('src'))
这样,一页的数据就好了
分页
下面有分页标签,但是此网站比较特殊,动态加载页数的,最后一页的内容一直变

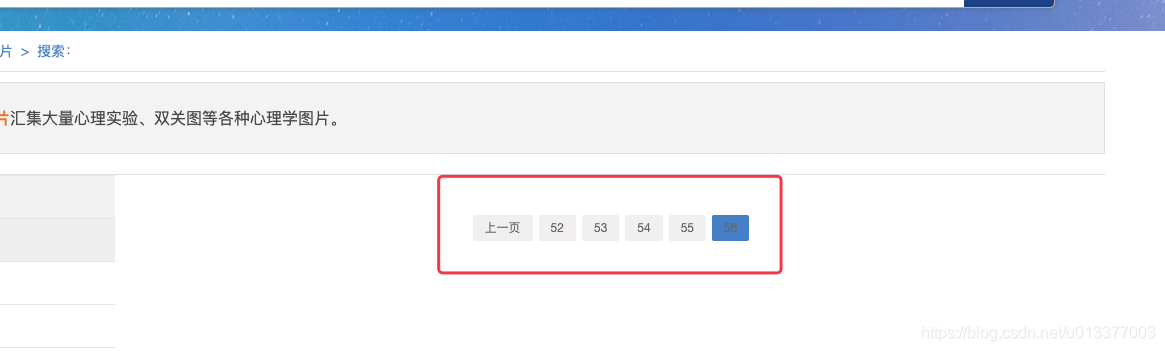
所以直接采用下一页的方式,若ul中没有li了,就跳出死循环即可:
当然页数怎么获取,也提供出来(但是没用)
# 本来想做页数解析的,但是他的页数动态改变,所以页数就不用了
pages = driver.find_element_by_xpath('//*[@id="laypage_1"]')
a = pages.find_elements_by_xpath('a')
pageEle = pages.find_element_by_xpath('//*[@id="laypage_1"]/a[' + str(len(a) - 1) + ']')
print('page:' + str(pageEle.text))
page = int(pageEle.text)
以上就完成了爬取

完整代码:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By # 与下面的2个都是等待时要用到
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
if __name__ == "__main__":
url = 'http://www.mirrorpsy.cn/index.php?s=member&c=login&m=index'
driver = webdriver.Chrome()
driver.get(url)
wait = WebDriverWait(driver, 25)
driver.maximize_window() # 窗口最大化
user = wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="myform"]/div/div[1]/input')))
user.send_keys('xxx') #想要测试可留言
pw = wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="myform"]/div/div[2]/input')))
pw.send_keys('xxxx')
print('login param input success')
login = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="myform"]/div/div[4]/button'))) # 登录按钮
login.click()
print('login success')
time.sleep(10)
cookies = driver.get_cookies()
cookie_list = []
for dict in cookies:
cookie = dict['name'] + '=' + dict['value']
cookie_list.append(cookie)
cookie = ';'.join(cookie_list)
print('cookie' + cookie)
print('get knowledge')
# 学科知识
url_knowledge = 'http://www.mirrorpsy.cn/index.php?s=xkzs'
# 心理视频
url_video = 'http://www.mirrorpsy.cn/index.php?s=video'
# 心理音频
url_jyxl = 'http://www.mirrorpsy.cn/index.php?s=jyxl'
# 心理图片
url_photo = 'http://www.mirrorpsy.cn/index.php?s=photo'
# 学术论文
url_xslw = 'http://www.mirrorpsy.cn/index.php?s=xslw'
# 心理案例
url_xlal = 'http://www.mirrorpsy.cn/index.php?s=xlal'
# 心理专家
url_news = 'http://www.mirrorpsy.cn/index.php?s=news'
# driver.get(url_photo)
# 本来想做页数解析的,但是他的页数动态改变,所以页数就不用了
# pages = driver.find_element_by_xpath('//*[@id="laypage_1"]')
# a = pages.find_elements_by_xpath('a')
# pageEle = pages.find_element_by_xpath('//*[@id="laypage_1"]/a[' + str(len(a) - 1) + ']')
# print('page:' + str(pageEle.text))
# page = int(pageEle.text)
image_list = []
pageWeb = 0
while True:
print('get page:' + str(pageWeb))
url_pic = 'http://www.mirrorpsy.cn/index.php?s=photo&c=search&page=' + str(pageWeb + 1)
driver.get(url_pic)
items = driver.find_element_by_xpath('//*[@id="cn_perio_list"]')
lis = items.find_elements_by_xpath('li')
print('len:' + str(len(lis)))
if len(lis) == 0:
break
for li in lis:
imgs = li.find_element_by_tag_name('img')
print(imgs)
print(imgs.get_attribute('src'))
image_list.append(imgs.get_attribute('src'))
time.sleep(5)
pageWeb = pageWeb + 1
# pages = driver.find_element_by_xpath('//*[@id="laypage_1"]')
# a = pages.find_elements_by_xpath('a')
# pageEle = pages.find_element_by_xpath('//*[@id="laypage_1"]/a[' + str(len(a) - 1) + ']')
# page = int(pageEle.text)
print('图片爬取结束')
print('图片集合结果:' + str(image_list))
time.sleep(500000)
谢谢啦,关注一波吧,以后每周不定期更新