一、Firefox 上插件安装
1.XPath Checker:一个交互式编辑XPath表达式,在网页中选择 'View XPath' 可看到XPath路径,
2.Firebug:Firebug 为你的 Firefox 集成了浏览网页的同时随手可得的丰富开发工具。
你可以对任何网页的 CSS、HTML 和 JavaScript 进行实时编辑、调试和监控。
只要有火狐浏览器,下载好xpi文件直接拖到浏览器安装即可,若出现如下图的错误:
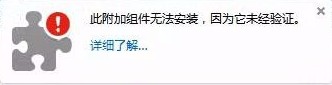
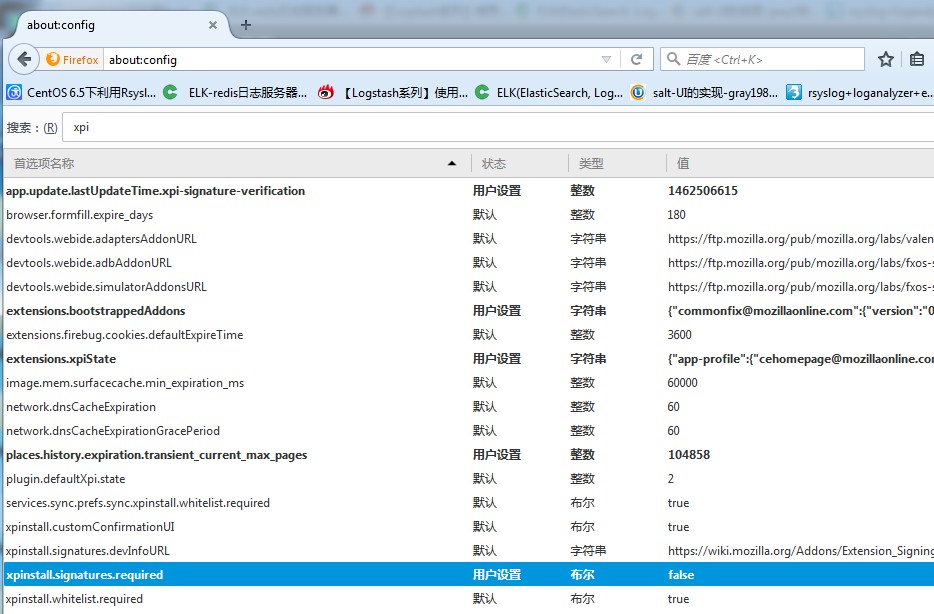
若出现此错误,则在浏览器内输入:about:config,双击蓝色选框值变成false即可。
二、python selenium
这里有篇文章关于selenium详细的介绍:一定先要看下这个文章
http://www.cnblogs.com/fnng/p/3160606.html
2.1 selenium的安装
OS:Centos6.4
Python:2.7.3
用Centos6.4自带的python2.6.6会版本不兼容。
所以需要升级下python:
#python -V
Python 2.6.#wget http://python.org/ftp/python/2.7.3/Python-2.7.3.tar.bz2 #下载python
#tar -jxvf Python-2.7.3.tar.bz2 #解压
#cd Python-2.7.3 #更改工作目录
##编译及安装:
#./configure
#make all
#make install
#make clean
#make distclean
#/usr/local/bin/python2.7 -V #查看新安装的版本信息
##建立软连接(就是快捷方式),是系统默认指向2.7python
#mv /usr/bin/python /usr/bin/python2.6.6
#python -V
Python 2.7.3
#vim /usr/bin/yum #解决系统Python软链接指向Python2.7版本后,因为yum是不兼容Python2.7的,所以yum不能正常工作,我们需要指定 yum 的Python版本</span></span>
#将文件头部的:
#!/usr/bin/python
#改成:
#!/usr/bin/python2.6.6
Selenium安装:
#wget https://bootstrap.pypa.io/get-pip.py --no-check-certificate #下载pip
#python get-pip.py #安装pip
#pip install selenium #安装Selenium
以上,基础环境解决了。。下面开始正文开发的过程。。。。
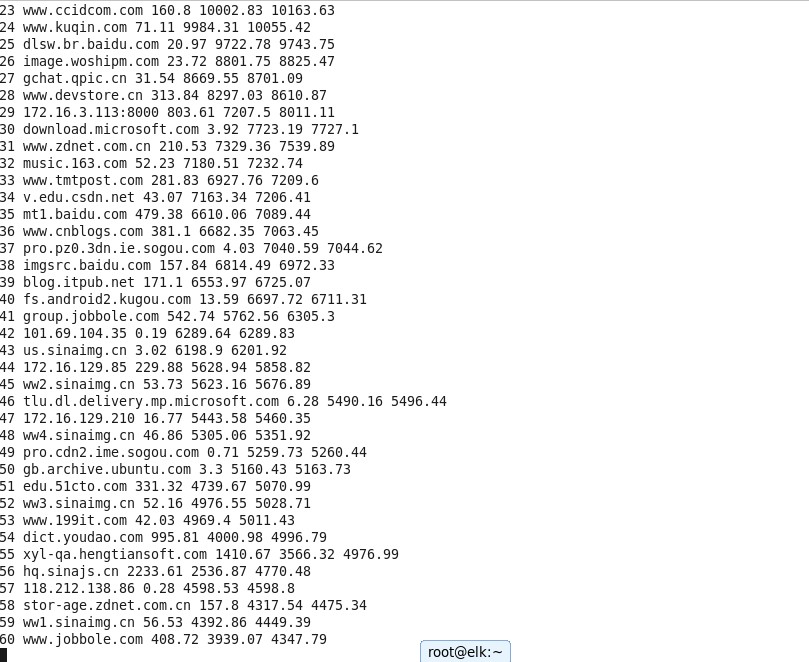
目的:右下角的网站报表生成功能是烂的。。烂的。。不能用啊,但是要获取前100页也就是流量排名前2000的网站。
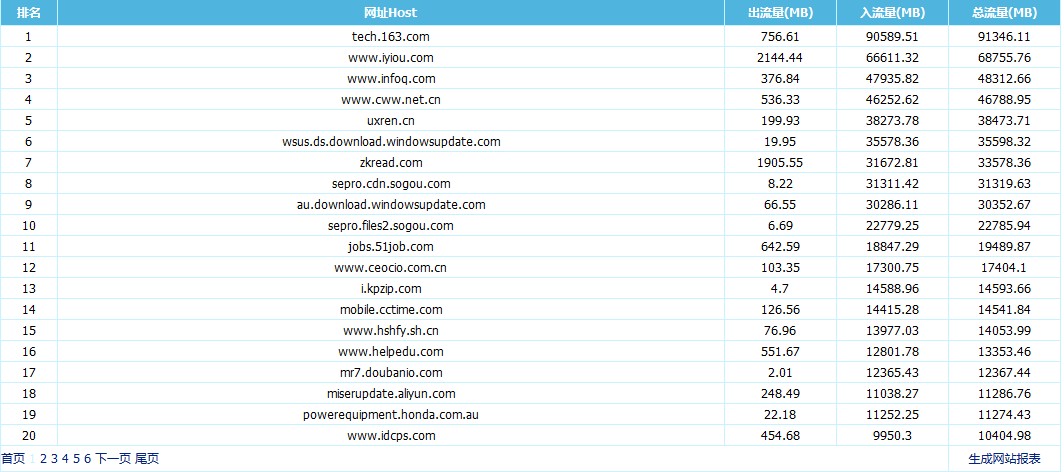
没办法了,这么多总不能一个一个复制吧,只能自己开撸了:
看过了开头所说的文章后,想必对Selenium的用法有了一定的了解,那么开始:
导入各种需要的库,有些暂时用不到,因为脚本里还有其他内容,这里删掉了,
先导进去,以后可能会有用。。。。我知道我很low。。。
from selenium import webdriver
import HTMLParser
import urlparse
import urllib
import urllib2
import cookielib
import string
import re
import sys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
import time
browser = webdriver.Firefox() #打开火狐浏览器,可以自己试下效果,就是自己动打开了firefox浏览器啦~~
browser.get(hosturl) #上面打开浏览器,然后当然是要输入url了,和我们一样,打开浏览器,输入url
到了这里我们接下来就要输入用户名密码,怎么做呢?当然先要定位name,password及登陆按钮,然后填写相应的用户名密码啊!!
接下来就要开始分析html了:
点到需要填写用户名的框,然后点击查看元素:
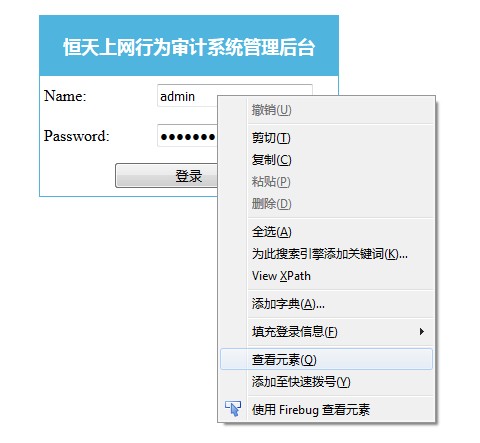
下面的标蓝部分,当然就是这个文本框的html代码啦:
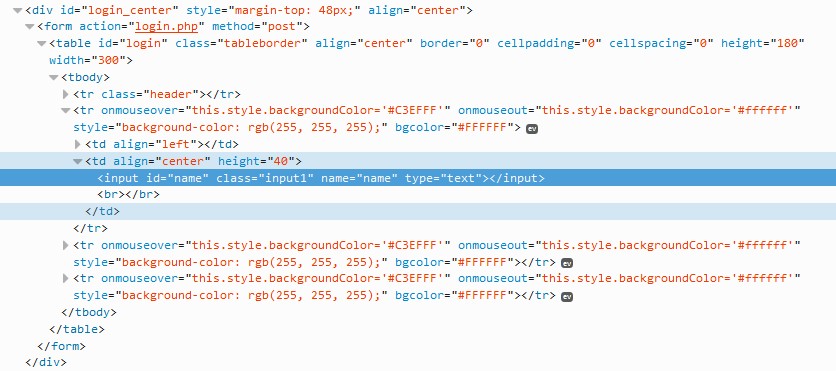
我们看到这个文本框的'id'是'name',那么我们可以这样定位到它:
name = browser.find_element_by_name("name") #定位这个文本框并将它赋值给name变量
passwd = browser.find_element_by_name("password") #下面就不赘述了,都是一样的步骤,
submit = browser.find_element_by_name("login")
name.send_keys("admin") #定位到这个文本框之后当然要输入账号密码了,也可以通过缓存获取,这个这里先不说
passwd.send_keys("eb7bfb8a211ab7980191da0dcfaf5e00") #因为网站密码用MD5进行加密了,所以可以用MD5工具将密码转换下。
submit.submit() #这相当于提交
#嘿嘿,成功登陆了,离我们获取排名数据的目标很近了
browser.implicitly_wait(3) #等个3秒,万一刷的慢呢,,你懂的。
#登陆之后我们再看下主页面的html代码,如何获取流量排名数据
#如下图:我们看到网站访问流量统计是一个href(超链接),而且这里的内容在一个iframe(一种web框架)里面
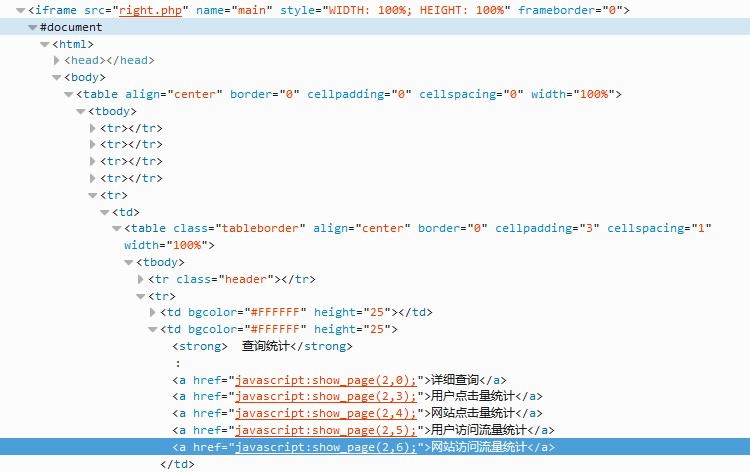
既然如此,那么我们要做的是先要找到这个iframe,然后点击’网站访问流量统计‘这个超链接
#我们看到iframe的name是'main',那么就先进入这个iframe吧:
browser.switch_to_frame("main")
#然后我们点击'网站访问流量'这个超链接
browser.find_element_by_partial_link_text("网站访问流量统计").click()
#总结下,大概思路就是这样,首先定位到要操作的元素,然后执行想要执行的操作,一般就是输入内容啦、点击啦、提交啦、、
接下来就是最终的目的了,就是把排名给爬下来,继续分析下html:
以第一名的这个网站为例:
用我们之前安装的XPath工具,我们可以看到排名字段 ’1‘ 这个XPath路径如下图:

依次查看,发现 ’ 网址host‘这个字段的XPath:id('top_table')/x:table/x:tbody/x:tr[2]/x:td[2],发现规律了吧。。后面就是3、4、5。。。啦
然后再看’排名‘第二的:id('top_table')/x:table/x:tbody/x:tr[3]/x:td[1] ,因此规律也类似。。’排名‘第3的,就tr[4]啦。。是不是很简单,,,,
接下来我们就是写个循环,把数据都搞下来就好啦!!!
def get():
i = 2
while i < 22:
paiming = browser.find_element_by_xpath("//div[@id='top_table']/table/tbody/tr[%s]/td[1]" %i).text
host = browser.find_element_by_xpath("//div[@id='top_table']/table/tbody/tr[%s]/td[2]" %i).text
outl = browser.find_element_by_xpath("//div[@id='top_table']/table/tbody/tr[%s]/td[3]" %i).text
inl = browser.find_element_by_xpath("//div[@id='top_table']/table/tbody/tr[%s]/td[4]" %i).text
total = browser.find_element_by_xpath("//div[@id='top_table']/table/tbody/tr[%s]/td[5]" %i).text
tt = paiming + ' '+ host + ' ' + outl + ' ' + inl + ' ' + total
print tt
i += 1
#这个函数就是把第一页的数据给弄出来,并打印到屏幕,因为要前100页,所以还要写个循环,去遍历这个100页,但是每页的操作都一样:
def next_page():
browser.find_element_by_partial_link_text("下一页").click()
#这里的变量命名比较乱,随意定的,大家别介意,主要是了解如何去工作的就好了- -~!以后会注意规范的。。。
j = 1
while j < 100:
get()
next_page()
j += 1#因为只是用来学习,为了实现功能,所以没有判断什么异常,其实很不规范。。
#!/usr/bin/python
#encoding=utf-8
hosturl = 'http://172.16.5.248'
browser = webdriver.Firefox()
browser.get(hosturl)
name = browser.find_element_by_name("name")
passwd = browser.find_element_by_name("password")
submit = browser.find_element_by_name("login")
name.send_keys("admin")
passwd.send_keys("eb7bfb8a211ab7980191da0dcfaf5e00")
submit.submit()
browser.implicitly_wait(3)
browser.switch_to_frame("main")
browser.find_element_by_partial_link_text("网站访问流量统计").click()
#这个函数主要就是将数据写入文件,上面没有介绍。。
def write(data):
f = open('paiming' , 'a')
f.write(data)
f.write('\n')
f.close()
def get():
i = 2
while i < 22:
paiming = browser.find_element_by_xpath("//div[@id='top_table']/table/tbody/tr[%s]/td[1]" %i).text
host = browser.find_element_by_xpath("//div[@id='top_table']/table/tbody/tr[%s]/td[2]" %i).text
outl = browser.find_element_by_xpath("//div[@id='top_table']/table/tbody/tr[%s]/td[3]" %i).text
inl = browser.find_element_by_xpath("//div[@id='top_table']/table/tbody/tr[%s]/td[4]" %i).text
total = browser.find_element_by_xpath("//div[@id='top_table']/table/tbody/tr[%s]/td[5]" %i).text
tt = paiming + ' '+ host + ' ' + outl + ' ' + inl + ' ' + total
write(tt)
i += 1
def next_page():
browser.find_element_by_partial_link_text("下一页").click()
j = 1
while j < 100:
get()
next_page()
j += 1
#好啦,就这样了,实现大概功能的代码其实不难,因为之前没什么研发功底,所以还是搞了很久,,
#ps。。坚持就能搞定。。。下面看下最后的成果:执行脚本,然后将数据存到文件