由于前端如果单纯依靠视觉+imu作为里程计,效果经常不稳定。因此最近做项目的过程中,将前端转化为以里程计(码盘编码器)来进行,相对比较鲁棒。由于这个局部传感器有累计误差,因此长期运行不可靠,因此将vins-mono中回环部分脱离出来。进行独立运行。
这里假定机器人运行的环境是在一个固定,变化相对较小的环境,因此图像数据库不进行更新。即
list<keyframe*> keyframelist
这个只保留载入存储的特征图片。
在vio线程中,通过图像特征跟踪,并三角化特征点,能够得到空间中三维点云的信息。这些点,存在了关键帧的这三个类成员中:
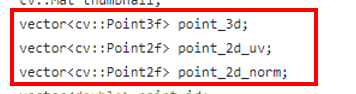
缺点:这些特征点没有描述子,并且数量比较少,大概在100个以下。因此在构建关键帧的时候,需要两个步骤:
(1)给这些关键点添加描述子信息(brief),这些特征点在这里暂时叫做窗口特征点。
(2)给该帧提取更多的特征点,用fast角点,提取非常多的特征点(500个以上),同样并给这些特征点添加描述子信息。这些特征点在这里暂时叫做姿态特征点。这些姿态特征点没有三维信息,只有像素坐标和归一化坐标两种坐标。
回环匹配分成两个步骤
(1)用bow词袋模型先找出历史的图像数据库中,历史的哪一帧与现在这一帧长得最像。
(2)找出最像的这帧图像,因此历史中这帧关键帧存有非常多的姿态特征点,因此开始进行特征点匹配。
匹配的过程是:
历史的回环候选帧的姿态特征点 与当前帧窗口特征点 两者之间的匹配。
因为姿态特征点数量远远大于窗口特征点数量,就找和当前帧窗口特征点汉明距离最近的一些姿态特征点。
为什么一个选择姿态特征点,一个选择窗口特征点?
因为至少需要一个特征点是知道3D坐标的。才可能知道当前帧相对于历史帧的位姿。
因此知道了3D坐标,知道了2D坐标的投影,就能够知道回环候选帧在当前帧为真值的情况下,回环候选帧的姿态,与实际的回环候选帧的姿态做一个姿态变换,其实就是当前帧应该做的一个姿态变换。比较饶,不过VINS-MONO确实是这样做的。
VINS-MONO支持地图的保存,保存的信息包括:
1.关键帧图片(optional)
2.关键帧姿态
3.关键帧的姿态特征点2D坐标
4.关键帧的姿态特征点2D归一化坐标
5.关键帧的姿态特征点描述子
现在一个问题是,将vins-mono中回环部分脱离出来。进行独立运行。如果还是按照上面这个思路来做的话,由于需要知道特征点的3D坐标,因此同样也是需要前端的VINS_ESTIMATOR来进行三角化的。因此脱离得不够完全。因此我们需要换一种思路。
因此我们地图保存的信息变成:
1.关键帧图片(optional)
2.关键帧姿态
3.关键帧的窗口特征点2D坐标
4.关键帧的窗口特征点3D坐标
5.关键帧的窗口特征点描述子
保存的这些信息后,现在我们还是按照这个思路
(1)用bow词袋模型先找出历史的图像数据库中,历史的哪一帧与现在这一帧长得最像。
(2)找出最像的这帧图像,因此历史中这帧关键帧存有非常多的姿态特征点,因此开始进行特征点匹配。
但是特征匹配的时候,现在我们匹配的过程是:
历史的回环候选帧的窗口特征点 与当前帧姿态特征点 两者之间的匹配。
因此知道了3D坐标,知道了2D坐标的投影,就能够知道回环候选帧姿态为真值的情况下,当前帧的姿态。
由于窗口特征点有3D坐标,当前帧只需要特征点的2D坐标,因此整个过程只需要运行一个pose_graph 包即可。
因此,整个流程应该是这样的:
1.在一个熟悉的环境,运行vins-mono完整版,采集关键帧的姿态,完成后,保存关键帧姿态。(保存的信息需要进行修改,从姿态特征点修改为窗口特征点)
2.直接运行修改后的pose_graph包,这个包订阅的消息就只有图像,不需要运行feature_tracking,以及 vins_estimator。
当然了vins-mono为了追求发论文的高精度,因此把很多阈值调的比较苛刻,才认为是回环。因此,在实际运用中,为了追求回环的高输出,我们可以把一些阈值降低,这些阈值包括:
1.词袋模型找最接近的图片,论文中认为最像的图像应该比第二像的图片可信度高一定的阈值。
2.特征点匹配过程中汉明距离的阈值。
3.PNP求解的过程,内点和外点的比例阈值。
4.PNP求解出来特征点内点的数量阈值。