回环检测回环校正(一):回环检测原理
一、回环检测回环校正的意义
参考:
[1]徐宽. 融合IMU信息的双目视觉SLAM研究[D].哈尔滨工业大学,2018.
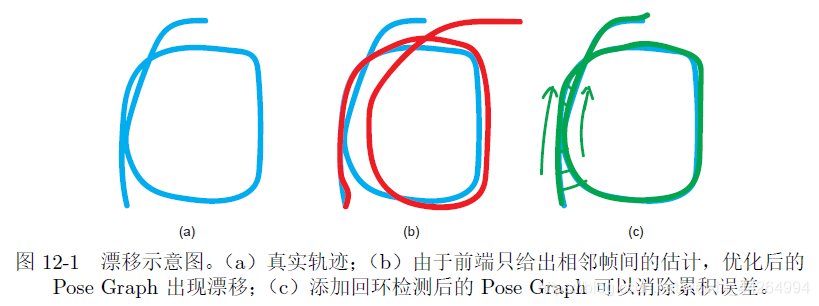
我们在进行运动估计之后,当固定了第一帧图像的初始位姿,理论上便可以递推出后续各帧的位姿,但是这样会造成累计误差的产生(对相邻两帧估计的位姿误差会累加到下一帧上致使误差越来越大)。或者说,我们无法构建全局一致的轨迹和地图。
因此,我们需要进行回环检测来消除这个累积误差。
为了消除这个误差,可以这样做:当系统两次经过同一个地点时,由于累计误差的影响,递推得到的位姿会差别很大,但是我们可以强制使这两次的位姿相同,然后校正其它帧的位姿,以此来降低累计误差的影响。
为实现这一思想,我们需要做两件事:
1、如何准确地识别到系统两次经过了相同的地方(回环检测)
2、如何利用回环信息校正其它帧的位姿(回环校正)
二、回环检测
第一件事主要是如何准确地识别到系统两次经过了相同的地方
1、词袋模型
概述
摘自《SLAM十四讲》


2、字典
a、字典的创建:K-means聚类

b、字典的表示及查找:k叉树


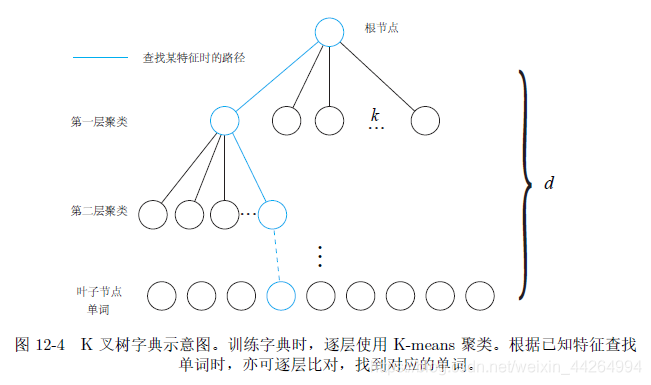
有了视觉字典树,词袋模型构建如下:
1、对待处理的一帧图像进行特征点的提取和描述子的生成
2、对每一个特征点,在字典树上查询其位置,获得其单词描述。这样,每个特征点都能够用一个视觉字典中的单词代替
3、把该帧图像的所有单词用一个直方图去统计,便可以获得一个描述该帧图像包含单词情况的一个向量
c、TF-IDF
在上述做法中,我们对所有的单词都是“一视同仁”的,即在统计直方图时,单词有就是有,没有就是没有。但是,不同单词在区分性上的重要性并不相同。因此,我们希望对单词的区分性或重要性加以评估,给它们不同的权值以起到更好的效果。如何计算权值呢?
单词权重的计算我们采用TF-IDF的方法计算,又称频率-逆文档频率(词频-逆文件频率),TF部分的思想是:某单词在一个图像中经常出现,它的区分度就越高;IDF部分的思想是:某单词在字典中出现的频率越低,则分类图像时区分度越高
具体计算过程如下:


d、相似度的计算(两个图像)

e、顺序索引和逆序索引
在字典树上,会添加顺序索引和逆序索引:
逆序索引,就是对于视觉字典树的每个叶子节点,都会维持一个列表,该列表保存了包含该单词的图像以及此单词在该帧图像中的权重,单词的权重使用TF-IDF;
顺序索引,存储了图像的特征点和特征点在视觉字典树某一层所在的
节点。顺序索引可以用来加速特征点的匹配,当需要匹配两帧图像的特征点的时候,可以只匹配位于同一节点的特征点,从而降低了需要匹配的特征点对数。
3、回环验证
参考:[1]卢亚兵. 基于双目视觉的实时定位与建图方法研究[D].哈尔滨工业大学,2018.
回环验证的必要性
之前所述回环检测算法根据图像帧之间的相似度得到回环检测结果,这种情形下还会有可能误检,所以应进一步通过连续性校验及几何校验得到最终回环检测结果
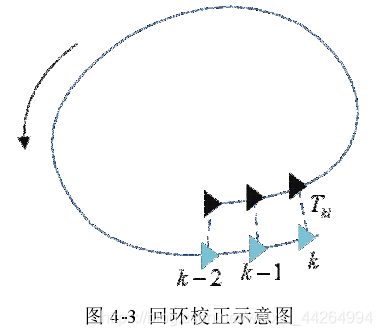
连续性校验
连续性校验是指连续几个关键帧经回环检测算法得到的候选回环关键帧同样连续。如下图所示,在图中所示三个时刻对应的回环帧具有共同观测,所以它们在共视图中相互连接。
几何校验
几何校验是指根据当前帧和回环检测得到的关键帧之间的位姿信息计算得到两个关键帧之间位姿变换。
4、实现回环检测
假设目前已经有一个建好的视觉字典树,以及从初始时刻到现在的图像建立起来的顺序索引和逆序索引:
对于当前时刻的图像进行如下操作(检验是否之前到达过,构成了回环):
1、提取当前帧的特征点,计算相应的特征描述子,得到描述该帧图像的词袋向量;
2、在视觉字典树上利用逆序索引找到与当前图像拥有相同单词的一系列图像作为回环检测的候选图像;
3、计算当前图像与候选图像(之前的图像)的相似度,将相似度最高的作为回环对;
4、对于得到的回环对进行验证,检验是否为正确的回环。
