文章目录
shell脚本–正则表达式
前言
正则表达式概述和用途
正则表达式又称正规表达式、常规表达式。在代码中常简写为 regex、regexp 或 RE。正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说, 是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
正则表达式对于系统管理员来说是非常重要的,系统运行过程中会产生大量的信息,这些信息有些是非常重要的,有些则仅是告知的信息。身为系统管理员如果直接看这么多的信息数据,无法快速定位到重要的信息,如“用户账号登录失败”“服务启动失败”等信息。这时可以通过正则表达式快速提取“有问题”的信息。
一、基础正则表达式
1.1基础正则表达式示例
(1)查找特定字符
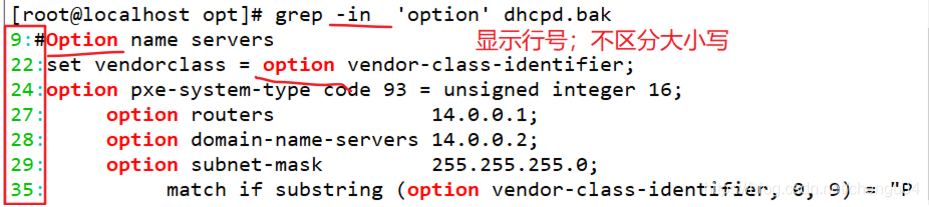
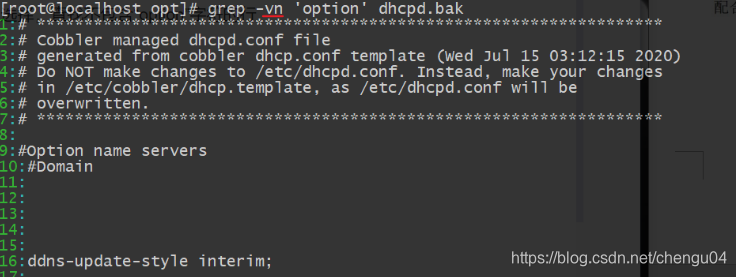
-n 表示显示行号

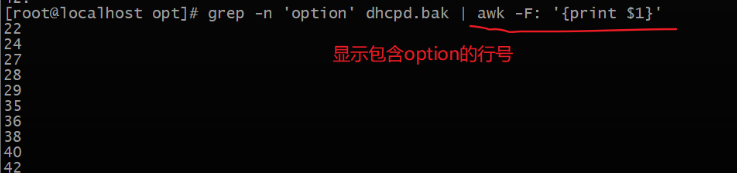
-i 表示不区分大小写
-v 反向选择,查找不包含“option”字符的行
(2)利用中括号[ ]来查找集合字符
想要查找“shirt”与“short”这两个字符时,可以发现它们均包含“sh”与“rt”。此时可以使用[]进行查找,
[ ]中无论有几个字符,都仅代表一个字符,例如[io]表示匹配i或者o

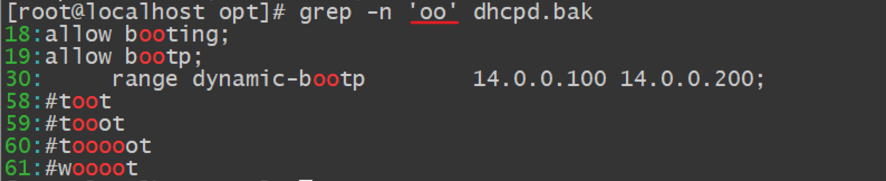
注意:若要查找包含重复单个字符“oo”时,只需要执行以下命令即可
若要查找“oo”前面不是“t”的字符串,只需集合字符的反向选择“[^]”来实现
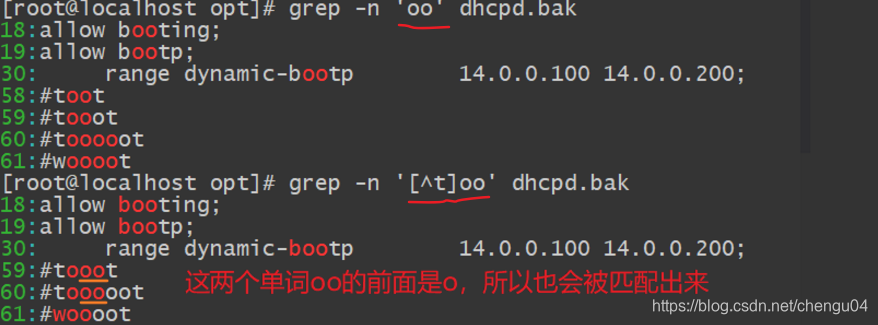
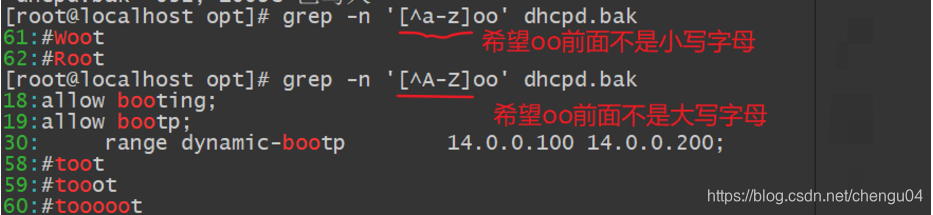
希望oo前面不是小写或者大写字母,a-z表示小写字母,A-Z表示大写字母
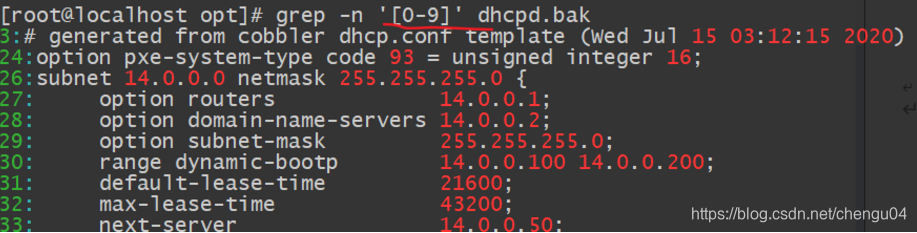
查找包含数字的行
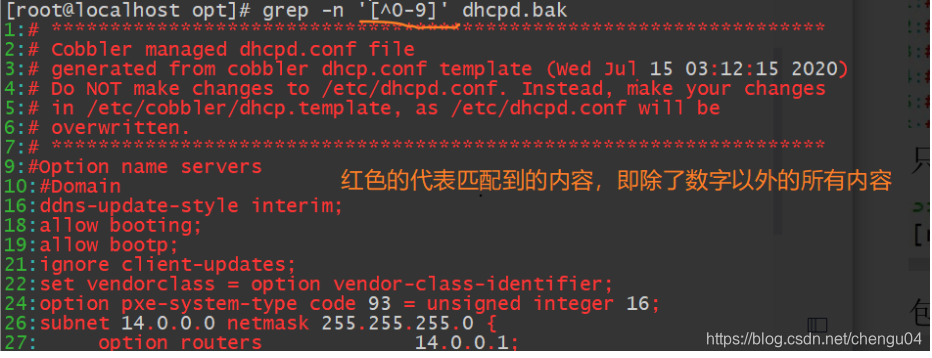
匹配除了数字以外的行,只要匹配上,就显示出来(只有这行有除了数字以外的内容,都会匹配出来)
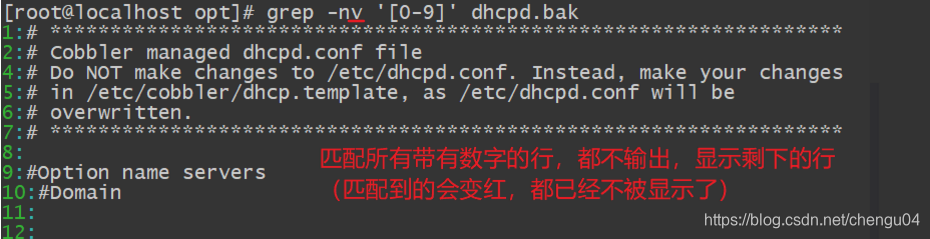
先匹配所有带有数字的行,都不输出,再显示剩下的行
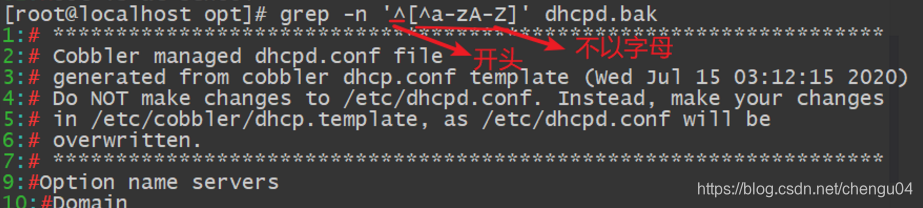
(3)查找行首“^”与行尾字符“$ ”;^ $代表空行(grep需加-E)
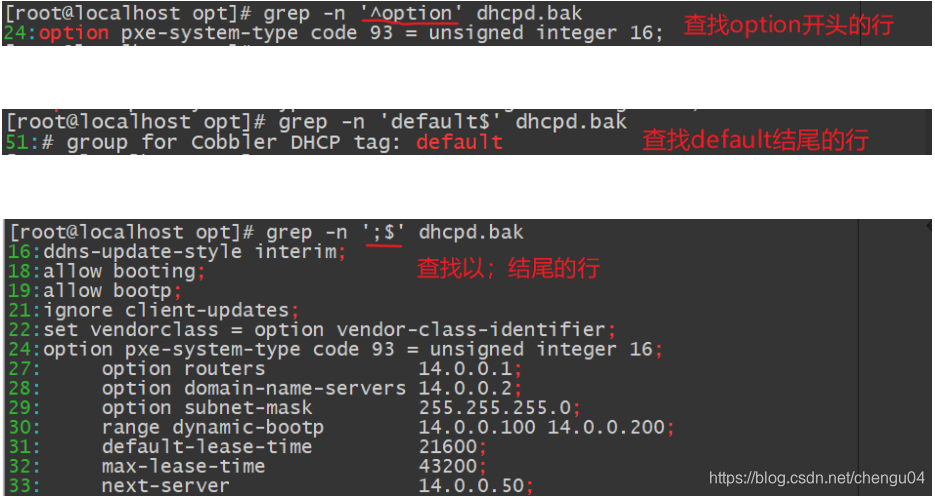
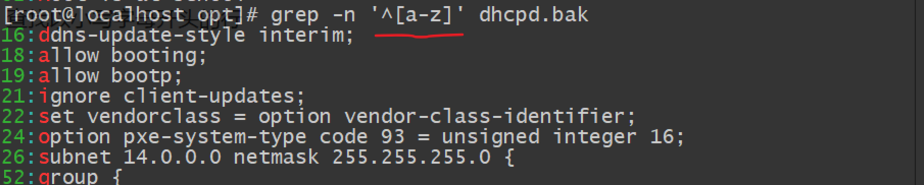
查找以小写字母开头的行
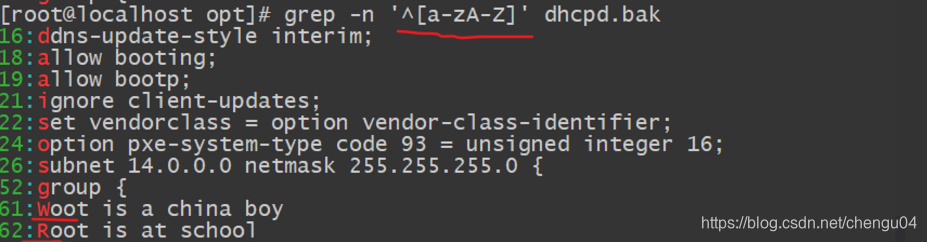
查找以大写字母开头的行

查询以大写或者小写字母开头的行
查询不以字母开头的行
注意!!!
“^”符号在元字符集合“[ ]”符号内外的作用不一样,在内表示反向选择,在外表示定位行首。
反之,若想查找以某一特定字符结尾的行则可以使用"$"定位符。
示例:查找以小数点.结尾的行

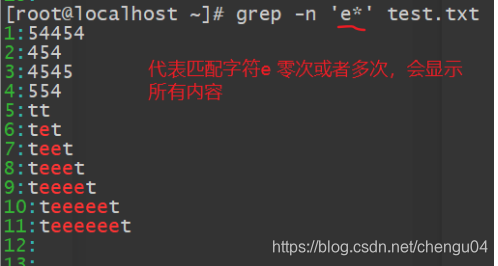
(4)查找任意一个字符“.”与重复字符“*”
?是在查找文件时使用,代表文件名中的一个字符,正则表达式中的任意一个字符是“.”

星号表示前面的一个字符出现0次或者多次
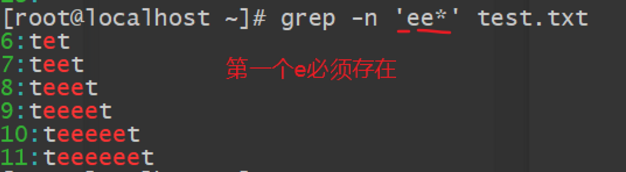
如果是“ee*”,则第一个e必须存在, 第二个 e 则是零个或多个 e,所以凡是包含e、ee、eee,等的内容都符合标准。

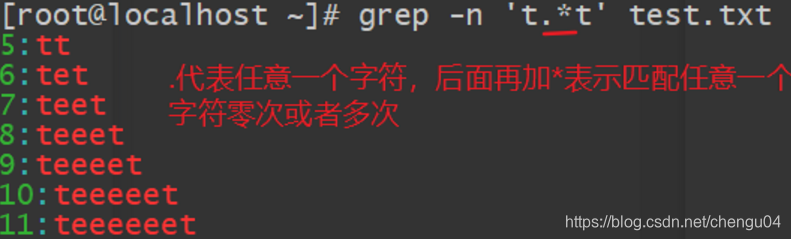
匹配以t开头,以t结尾的,中间字符可有可无(任意字符)的内容
执行以下命令即可查询任意数字所在行

注意:
如果*前面不加内容是看成普通字符
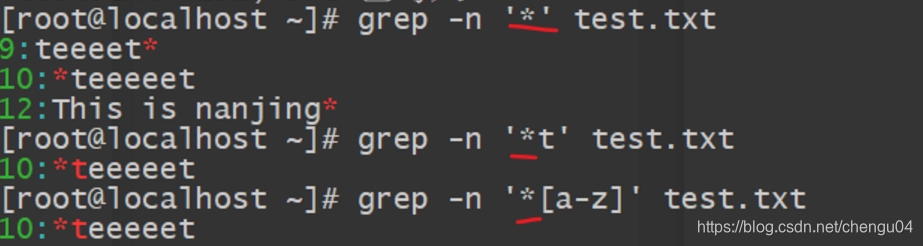
(5)查找连续字符范围 {}
使用“.”与“*”来设定零个到无限多个重复的字符,如果想要限制一个范围内的重复的字符串该如何实现呢?例如,查找三到五个 o 的连续字符,这个时候就需要使用基础正则表达式中的限定范围的字符“{}”。每个大括号前都要加转义符
1.查找两个e的字符
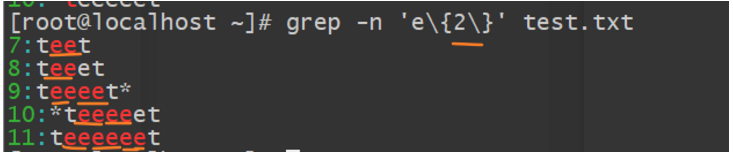
2.查询中间包含 2~5 个 e 的字符串
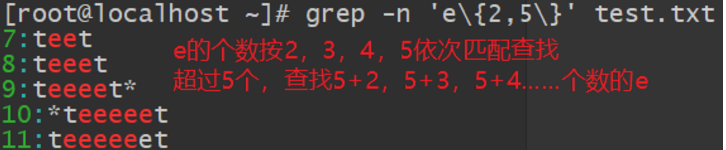
3.查询以 t 开头以 t 结尾,中间包含 2 个或 2 个以上 e 的字符串

1.2元字符总结
基础正则表达式的元字符主要包括以下几个。
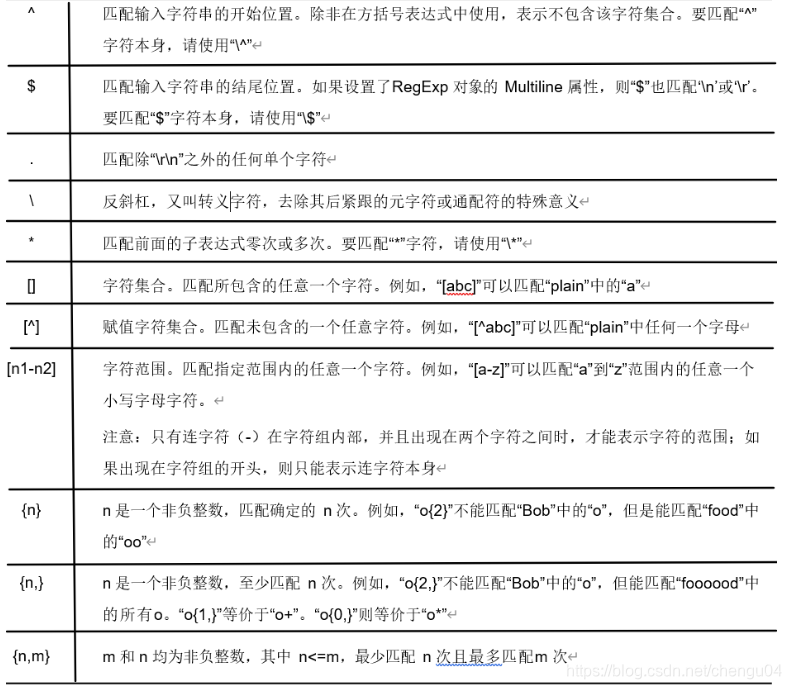
\r\n 一般一起用,用来表示键盘上的回车键,也可只用 \n
正则表达式中单双引号不做区别
shell脚本里有区别,双引号里可以用 $引其他变量,单引号不支持。
1.3扩展正则表达式
通常情况下会使用基础正则表达式就已经足够了,但有时为了简化整个指令,需要使用范围更广的扩展正则表达式。
例如,使用基础正则表达式查询除文件中空白行与行首为“#”之外的行(通常用于查看生效的配置文件),执行grep -v ‘^KaTeX parse error: Expected group after '^' at position 22: …txt | grep -v ‘^̲#’即可实现。而扩展正则表达式…|^#’ test.txt,单引号内的管道符号表示或者(or)
使用扩展正则表达式,需要使用 egrep 或 awk 命令。
扩展正则表达式常见元字符

(1)重复一个或者一个以上的前一个字符:+
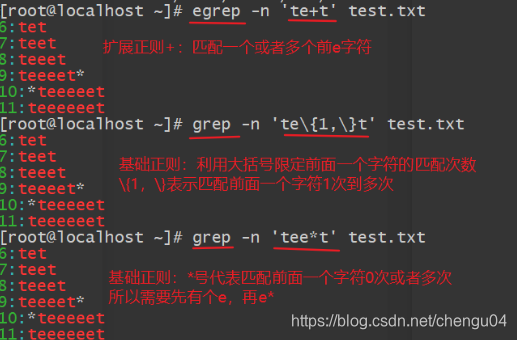
(2)零个或者一个的前一个字符:?

(3)使用或者(or)的方式找出多个字符 |
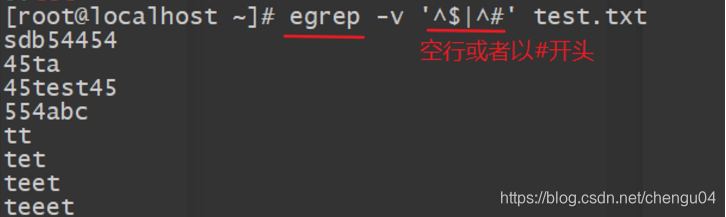
(4)查找“组”字符串 (e|a|i)同基础正则中的t[eai]t

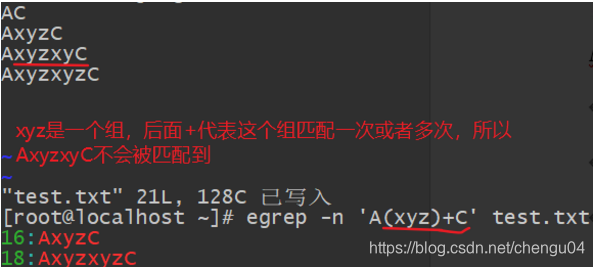
(5)辨别多个重复的组 ()+
示例:“egrep -n ‘A(xyz)+C’ test.txt”。该命令是查询开头的"A"结尾是"C",中间有一个以上的"xyz"字符串的意思
二、文本处理器
在Linux/UNIX 系统中包含很多种类的文本处理器或文本编辑器,其中包括我们之前学习过的VIM 编辑器与grep 等。而 grep,sed,awk 更是Shell 编程中经常用到的文本处理工具, 被称之为Shell 编程三剑客。
2.1sed 工具
sed(Stream EDitor)是一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑(删除、替换、添加、移动等),最后输出所有行或者仅输出处理的某些行。sed 也可以在无交互的情况下实现相当复杂的文本处理操作,被广泛应用于 Shell 脚本中,用以完成各种自动化处理任务。
sed 的工作流程主要包括读取、执行和显示三个过程。
读取:sed 从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)。
执行:默认情况下,所有的 sed 命令都在缓冲区中顺序地执行,除非指定了行的地址,否则 sed 命令将会在所有的行上依次执行。
显示:发送修改后的内容到输出流。在发送数据后,缓冲区将会被清空。
在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容被处理完。
注意:默认情况下所有的 sed 命令都是在缓冲区内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出。
1.sed 命令常见用法
通常情况下调用 sed 命令有两种格式,如下所示。其中,“参数”是指操作的目标文件, 当存在多个操作对象时用,文件之间用逗号“,”分隔;而 scriptfile 表示脚本文件,需要用“-f” 选项指定,当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标文件。
sed [选项] '操作' 参数
sed [选项] -f scriptfile 参数
常见的 sed 命令选项主要包含以下几种。
-e 或--expression=:表示用指定命令或者脚本来处理输入的文本文件。
-f 或--file=:表示用指定的脚本文件来处理输入的文本文件。
-h 或--help:显示帮助。
-n、--quiet 或 silent:表示仅显示处理后的结果。
-i:直接编辑文本文件。(需要慎用)
“操作”用于指定对文件操作的动作行为,也就是 sed 的命令。通常情况下是采用的“[n1[,n2]]”操作参数的格式。n1、n2 是可选的,代表选择进行操作的行数,如操作需要在 5~ 20 行之间进行,则表示为“5,20 动作行为”。常见的操作包括以下几种。
a:增加,在当前行下面增加一行指定内容。
c:替换,将选定行替换为指定内容。
d:删除,删除选定的行。
i:插入,在选定行上面插入一行指定内容。
p:打印(print),如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以 ASCII 码输出。其通常与“-n”选项一起使用。
s:替换,替换指定字符。
y:字符转换。
2.用法举例
(1).输出符合条件的文本(p 表示正常输出)
[root@localhost ~]# sed -n 'p' test.txt ##输出所有内容,等同于cat test.txt
sdb54454
45ta
45test45
554abc
tt
tet
tat
[root@localhost ~]# sed -n '3p' test.txt ##输出第3行
45test45
[root@localhost ~]# sed -n '3,5p' test.txt ##输出第3-5行(结尾行是$)
45test45
554abc
tt
[root@localhost ~]# sed -n 'p;n' test.txt ##print代表读取,next代表读取下一行(读取奇数行)
sdb54454
45test45
tt
tat
teet
[root@localhost ~]# sed -n 'n;p' tet1.txt ##相当于读取偶数行
2
4
6
8
10
bbb
指定行数输出奇数行或者偶数行:
[root@localhost ~]# sed -n '1,5{p;n}' tet1.txt ##输出第1-5行中的奇数行
1
3
5
[root@localhost ~]# sed -n '1,5{n;p}' tet1.txt ##输出第1-5行中的偶数行
2
4
6 注意:{n;p}格式如果范围内最后一行是n,会继续输出下一行(除非到结尾了)
[root@localhost ~]# sed -n '1,6{n;p}' tet1.txt
2
4
6
[root@localhost ~]# sed -n '3,${n;p}' tet1.txt ##输出3-结尾中的偶数行
4
6
8
10
bbb
以上是 sed 命令的基本用法,sed 命令结合正则表达式时,格式略有不同,正则表达式以“/”包围。例如,以下操作是 sed 命令与正则表达式结合使用的示例。
[root@localhost conf]# sed -n '/the/p' httpd.bak ##输出包含the的行
#This is the main Apache HTTP server configuration file. It contains the
#configuration directives that give the server its instructions.
#Do NOT simply read the instructions in here without understanding
#what they do. They're here only as hints or reminders. If you are unsure
[root@localhost conf]# sed -n '4,/the/p' httpd.bak ##输出从第四行起第一个包含the的行
#See <URL:http://httpd.apache.org/docs/2.4/> for detailed information.
#for a discussion of each configuration directive.
#Do NOT simply read the instructions in here without understanding
[root@localhost ~]# sed -n '/the/=' httpd.bak ##输出所有包含the的行的行号,=用来输出行号
2
3
9
10
11
13
14
[root@localhost conf]# sed -n '/^# The/p' httpd.bak ##输出以# The开头的行
#The directives in this section set up the values used by the 'main'
#The following lines prevent .htaccess and .htpasswd files from being
[root@localhost conf]# sed -n '/[0-9]$/p' httpd.bak ##输出以数字结尾的行
#Listen 12.34.56.78:80
Listen 80
/ServerName www.cg.com:80
AddDefaultCharset UTF-8
[root@localhost conf]# sed -n '/\<ServerName\>/p' httpd.bak ##输出包含ServerName的行,(精确匹配ServerName单词的行)
#ServerName gives the name and port that the server uses to identify itself.
/ServerName www.cg.com:80
(2) 删除符合条件的文本(d)
注意:不加-i只删除缓存区的内容
nl 命令用于计算文件的行数,结合该命令可以更加直观地查看到命令执行的结果。(numberline)
[root@localhost ~]# nl tet1.txt |sed '3d' ##删除第三行
1 1
2 2
4 4
5 5
6 6
[root@localhost ~]# nl tet1.txt |sed '6,8d' ##删除第6-8行
1 1
2 2
3 3
4 4
5 5
9 9
[root@localhost ~]# nl tet1.txt |sed '/aaa/d' ##删除包含aaa的行
7 7
8 8
9 9
10 10
12 bbb
13 ccc
[root@localhost ~]# nl tet1.txt |sed '/ccc/!d' ##包含ccc的行不删除,即没有ccc的行都删除
13 ccc
注意:查找或者删除关键词的要加//
[root@localhost ~]# sed '/^[a-z]/d' test.txt ##删除以小写字母开头的行
45ta
45test45
554abc
*teeeeet
[root@localhost ~]# sed '/\.$/d' test.txt ##删除以点为结尾的行(加转义符)
554abc
tt
tet
tat
[root@localhost ~]# sed '/^$/d' test.txt ##删除空行
若 是 删 除 重 复 的 空行 , 即 连 续 的 空 行 只 保 留 一 个,执行
“sed -e ‘/^$/{n;/^$/d}’ test.txt” 命令即可实现。其效果与“cat -s test.txt”相同,n 表示读下一行数据。
(3)替换符合条件的文本
在使用 sed 命令进行替换操作时需要用到 s(字符串替换)、c(整行/整块替换)、y
(字符转换)命令选项,常见的用法如下所示。
[root@localhost ~]# sed 's/the/THE/' test.txt ##将每行中的第一个the替换为THE
sdb54454.
THE
45ta.
THE45test45. the
[root@localhost ~]# sed 's/i/I/2' test.txt ##将每行中的第二个i替换为I
45ta.
the45test45. the
this thIs
[root@localhost ~]# sed 's/the/THE/g' test.txt ##将所有的the替换为THE
sdb54454.
THE
45ta.
THE45test45. THE
[root@localhost ~]# sed 's/h//g' test.txt ##将所有的h删除(即替换为空字符)
sdb54454.
te
45ta.
te45test45. te
[root@localhost ~]# sed 's/^/#/' test.txt ##在每行行首插入#
#sdb54454.
#the
#45ta.
#the45test45. the
[root@localhost ~]# sed '/the/s/^/#/' test.txt ##在包含the的行的行首插入#
sdb54454.
#the
45ta.
#the45test45. the
this this
[root@localhost ~]# sed 's/$/ EOF/' test.txt ##在每行行尾插入 EOF
sdb54454. EOF
the EOF
45ta. EOF
the45test45. the EOF
[root@localhost ~]# sed '1,3s/the/THE/g' test.txt ##将1-3行中的所有the替换为THE
sdb54454.
THE
45ta.
the45test45. the
[root@localhost ~]# sed '/the/s/e/E/g' test.txt ##将包含the的行中所有e替换为E
sdb54454.
thE
45ta.
thE45tEst45. thE
(4)迁移符合条件的文本
常用以下参数:
H:复制到剪切板
g、G:将剪切板中的数据覆盖/追加到指定行
w:保存为文件
r:读取指定文件
a:追加指定内容
迁移过去的时候默认上面会有空行;可以再删除空行
sed '/the/{H;d};$G' test.txt ##将包含the的行迁移至文件末尾,{;}用于多个操作
sed '1,5{H;d};17G' test.txt ##将第1-5行内容迁移至17行后
sed '/the/w out.file' test.txt ##将包含the的行另存为文件out.file
sed '/the/r /etc/hostame' test.txt ##将文件/etc/hostname中的内容添加到包含the的每行以后
sed '3aNEW' test.txt ##在第三行后插入一个新行,内容为NEW
sed '/the/aNEW' test.txt ##在包含the的每行后插入一个新行,内容为NEW
sed '3aNEW1\nNEW2\nNEW3' test.txt ##在第三行后插入多行内容,\n表示换行
(5) 使用脚本编辑文件
使用 sed 脚本将多个编辑指令存放到文件中(每行一条编辑指令),通过“-f”选项来调用。例如执行以下命令即可将第 1~5 行内容转移至行尾后。
[root@localhost ~]# vim test.sh ##将1-3行内容剪切、删除、追加到行尾
1,3H
1,3d
$G
[root@localhost ~]# sed -f test.sh test.txt ##使用-f调用脚本
2.2awk 工具
2.2.1awk 常见用法
awk 选项 '模式或条件 {编辑指令}' 文件 1 文件 2 …
##过滤并输出文件中符合条件的内容
awk -f 脚本文件 文件 1 文件 2 … ##从脚本中调用编辑指令,过滤并输出内容
sed 命令常用于一整行的处理,而 awk 比较倾向于将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。在使用 awk 命令的过程中,可以使用逻辑操作符“&&”表示“与”、“||” 表示“或”、“!”表示“非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
awk处理文件原理:
awk 从输入文件或者标准输入中读入信息,与 sed 一样,信息的读入也是逐行读取的。不同的是 awk 将文本文件中的一行视为一个记录,而将一行中的某一部分(列)作为记录中的一个字段(域)。为了操作这些不同的字段,awk 借用 shell 中类似于位置变量的方法, 用$1、$2、$3…顺序地表示行(记录)中的不同字段。另外 awk 用$0 表示整个行(记录)。不同的字段之间是通过指定的字符分隔。awk 默认的分隔符是空格。awk 允许在命令行中用“-F 分隔符”的形式来指定分隔符
awk 包含几个特殊的内建变量(可直接用):
FS:指定每行文本的字段分隔符,默认为空格或制表位(等于-F)
NF:当前处理的行的字段个数
NR:当前处理的行的行号(序数)
$0:当前处理的行的整行内容
$n:当前处理行的第n个字段(第n列)
FILENAME:被处理的文件名
RS:数据记录分隔,默认为\n,即每行为一条记录
2.2.2用法举例
1.按行输出文本
{print}大括号外面的往往都是对行操作
BEGIN后面肯定会跟大括号
awk '{print}' test.txt ##输出所有内容,等同于cat
awk '{print $0}' test.txt ##输出所有内容,等同于cat test.txt
[root@localhost ~]# awk 'NR==1,NR==3{print}' test.txt ##输出第1-3行内容
sdb54454.
the
45ta.
[root@localhost ~]# awk '(NR>=1)&&(NR<=3){print}' test.txt ##输出第1-3行内容
sdb54454.
the
45ta.
[root@localhost ~]# awk 'NR==1||NR==3{print}' test.txt ##输出第1行和第3行内容
sdb54454.
45ta.
[root@localhost ~]# awk '(NR%2)==1{print}' test.txt ##输出所有奇数行内容
[root@localhost ~]# awk '(NR%2)==0{print}' test.txt ##输出所有偶数行内容
[root@localhost ~]# awk '/^the/{print}' test.txt ##输出the开头的行
the
the45test45. the
[root@localhost ~]# awk '/the$/{print}' test.txt ##输出the结尾的行
the
the45test45. the
[root@localhost ~]# awk '/nologin$/{print}' /etc/passwd ##输出以nologin结尾的行
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
root@localhost ~]# awk '/^root/{print}' /etc/passwd ##输出以root开头的行
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# awk 'BEGIN{x=0};/\/bin\/bash$/{x++};END{print x}' /etc/passwd
6 ##统计以/bin/bash结尾的行的行数,等同于grep -c "/bin/bash$" /etc/passwd
[root@localhost ~]# awk 'BEGIN{x=0};/\/sbin\/nologin$/{x++};END{print x}' /etc/passwd
41 ##统计以/sbin/nologin结尾的行的行数
[root@localhost ~]# awk 'BEGIN{RS=""};END{print NR}' test.txt
4 ##统计以空行分割的文本段落数
2.按字段输出文本
[root@localhost ~]# awk '{print $1,$7}' /etc/passwd ##输出每行(以空位或制表位分割)中第1、7个字段
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@localhost ~]# awk -F ":" '$2==""{print}' /etc/shadow ##输出密码为空的用户记录
tom4::18469:0:99999:7:::
[root@localhost ~]# awk -F: '$2=="!!"{print}' /etc/shadow ##输出密码被锁定的用户记录
systemd-network:!!:18458: : : : : :
dbus:!!:18458: : : : : :
polkitd:!!:18458: : : : : :
[root@localhost ~]# awk 'BEGIN{FS=":"};$2="!!"{print}' /etc/shadow ##查看密码被锁定的用户记录
root !! 0 99999 7
bin !! 17834 0 99999 7
daemon !! 17834 0 99999 7
[root@localhost ~]# awk -F: '($7~"/bash"){print $1}' /etc/passwd ##查看第7个字段中包含/bash的行的第一个字段
root
chengu
zhangsan
[root@localhost ~]# awk '(NF==8)&&($1~"nfs"){print $1,$2}' /etc/services
##查看一共8个字段且第一个字段中包含nfs的行的第1和2字段
nfs 2049/tcp
nfs 2049/udp
nfs 2049/sctp
netconfsoaphttp 832/tcp
netconfsoaphttp 832/udp
netconfsoapbeep 833/tcp
[root@localhost ~]# awk -F: '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd
##查看第7个字段不是/bin/bash也不是/sbin/nologin的行
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
3.通过管道、双引号调用 Shell 命令
[root@localhost ~]# awk -F: '/bash$/{print | "wc -l"}' /etc/passwd
##调用wc -l命令统计使用bash的用户个数,等同于grep -c "bash$" /etc/bash
8
[root@localhost ~]# w
12:30:33 up 4:02, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 14.0.0.1 08:31 1.00s 0.67s 0.00s w
[root@localhost ~]# awk 'BEGIN{while("w" | getline)n++;{print n-2}}' ##调用w命令统计在线用户数
1
[root@localhost ~]# awk -F. 'BEGIN{"hostname" | getline;print $1}' ##调用hostname命令,输出当前主机名
localhost
三、sort工具
sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序。例如数据和字符的排序就不一样。sort 命令的语法为“sort [选项] 参数”,其中常用的选项包括以下几种。
-f:忽略大小写;
-b:忽略每行前面的空格;
-M:按照月份进行排序;
-n:按照数字进行排序;
-r:反向排序;
-u:等同于 uniq,表示相同的数据仅显示一行;
-t:指定分隔符,默认使用[Tab]键分隔;
-o <输出文件>:将排序后的结果转存至指定文件;
-k:指定排序区域。
示例1:将/etc/passwd文件中的账号进行排序
[root@localhost ~]# sort /etc/passwd ##默认以首字母进行排序
abrt:x:173:173::/etc/abrt:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
avahi:x:70:70:Avahi mDNS/DNS-SD Stack:/var/run/avahi-daemon:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
chengu:x:1000:1000:chengu:/home/chengu:/bin/bash
chrony:x:993:988::/var/lib/chrony:/sbin/nologin
colord:x:997:994:User for colord:/var/lib/colord:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
示例2:将/etc/passwd文件中的第三列进行反向排序
注意:只按第一个数字进行排序
[root@localhost ~]# sort -t: -rk 3 /etc/passwd ##只对第一个数字排
nobody:x:99:99:Nobody:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
radvd:x:75:75:radvd user:/:/sbin/nologin
示例3:将/etc/passwd文件中的第三列进行排序,并将输出内容保存在user.txt文件中
[root@localhost ~]# sort -t: -k 3 /etc/passwd -o user.txt
[root@localhost ~]# cat user.txt
root:x:0:0:root:/root:/bin/bash
chengu:x:1000:1000:chengu:/home/chengu:/bin/bash
zhangsan:x:1001:1001::/home/zhangsan:/bin/bash
四、uniq工具
sort是排序,uniq是去重;先排序再去重
uniq去重不连续的不会去掉,可以结合sort工具 sort test.txt | uniq
sort -u test.txt 推荐
Uniq 工具在 Linux 系统中通常与 sort 命令结合使用,用于报告或者忽略文件中的重复行。具体的命令语法格式为:uniq [选项] 参数。其中常用选项包括以下几种。
-c:进行计数;
-d:仅显示重复行;
-u:仅显示出现一次的行。
示例 1:删除 testfile 文件中的重复行。
[root@localhost ~]# vim tet1.txt
1
2
2
2
3
4
4
5
2
6
6
6
[root@localhost ~]# uniq tet1.txt
1
2
3
4
5
2
6
示例 2:删除 testfile 文件中的重复行,并在行首显示该行重复出现的次数。
[root@localhost ~]# uniq -c tet1.txt
1 1
3 2
1 3
2 4
3 6
示例 3:查找 testfile 文件中的重复行。
[root@localhost ~]# uniq -d tet1.txt
2
4
6
五、tr工具
tr 命令常用来对来自标准输入的字符进行替换、压缩和删除。可以将一组字符替换之后变成另一组字符,经常用来编写优美的单行命令,作用很强大。
tr 具体的命令语法格式为:
tr [选项] [参数]
其常用选项包括以下内容。
-c:取代所有不属于第一字符集的字符;
-d:删除所有属于第一字符集的字符;
-s:把连续重复的字符以单独一个字符表示;
-t:先删除第一字符集较第二字符集多出的字符。
示例 1:将输入字符由大写转换为小写。
[root@localhost ~]# echo "TEST" | tr 'A-Z' 'a-z'
test
示例 2:压缩输入中重复的字符。
[root@localhost ~]# echo "thissss is a text linnnnnnne." | tr -s 'sn'
this is a text line.
示例 3:删除字符串中某些字符。
[root@localhost ~]# echo 'hello world' | tr -d 'od'
hell wrl