今天我们来学习一下Shell的正则表达式。
正则表达式的概念:
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、以及这些特定字符的组合,责成一个“规定字符串”,这个“规定字符串”用来表达对字符串的一种过滤逻辑。规定这些特殊语法表示字符类、数量限定符和位置限定符,然后用这些特殊的语法和普通的字符一起表示一个模式,这就是正则表达式。正则表达式是用于描述一组字符串特征的模式,用来匹配特定的字符串。通过特殊字符+普通字符来进行模式描述,从而达到文字匹配目的工具。
正则表达式的分类:
基本的正则表达式(Basic Regular Expression又叫Basic RegEx简称BREs)
扩展的正则表达式(Extended Regular Expression又叫Extended RegEx 简称EREs)
Perl的正则表达式(Perl Regular Expression 又叫Perl RegEx简称PREs)
应用场景:
验证:表单提交时,进行用户的密码验证。
查找:从大量的信息中快速提取指定内容,在一批url中,查找指定的url
替换:将制格式的文本,进行正则匹配查找,找到之后进行特定替换

小小的场景:
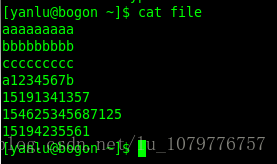
我们如果想按照行进行查找,找到指定的行是有效电话号码的行。分析可以知道,要描述“特定行是电话号码”,我们需要知道三个信息:
- 电话号码的符号组成 -数字 - 字符类
- 电话号码的符号个数 -11- 数量限定符
- 当前只有一个电话号码,也就是以电话号码开头,以电话号码结尾。 - 位置限定符
所以根据以上的描述我们可以知道正则表达式的基本要素是:
- 字符类
- 数量限定符
- 位置限定符
- 特殊符号
字符类:
| 字符 | 含义 | 举例 |
| . | 匹配任意一个字符 | abc.可以匹配abcd,abc9等 |
| [ ] | 匹配括号中的任意一个字符 | [abc]d可以匹配aad,bd,cd |
| - | 在括号内表示字符范围 | [0-9a-fA-F]可以匹配任意一个十六进制数字 |
| ^ | 位于[]括号内的开头,匹配除括号中的字符外的任意一个字符 | [^xy]匹配除xy之外的任意一个字符,[^xy]1,可以匹配a1,b1,但不能匹配x1,y1 |
| [[:xxx:] | grep工具预定义的一些命名字符类 | [[:alpha:]]匹配一个字母 [[:didit:]]匹配一个数字 |
举例:
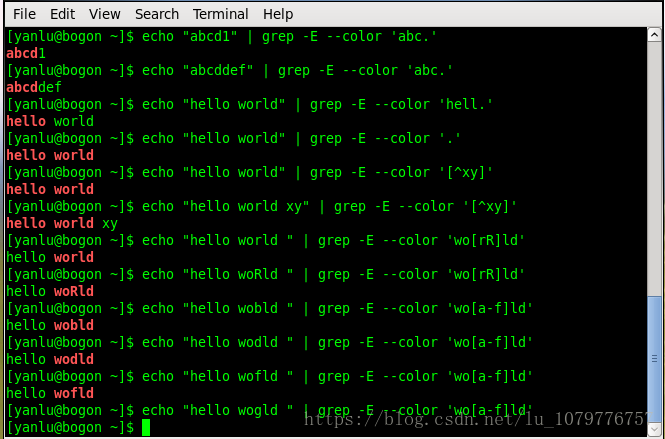
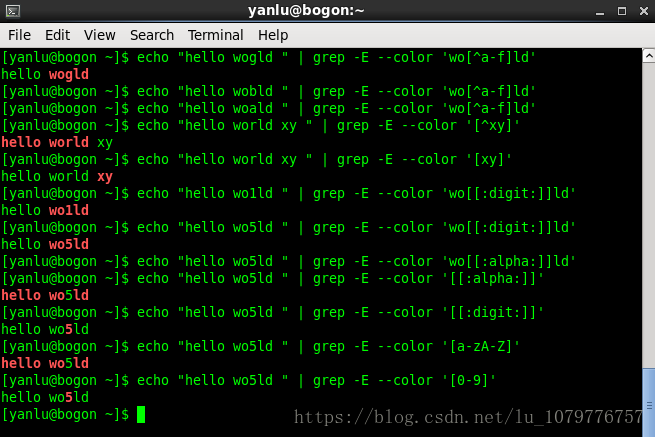
我们可以发现匹配字母和匹配数字不仅可以用
[[:digit:]] [[:alpha:]]也可以使用
[0-9] [a-zA-Z]用 --color 选项可以将匹配到的字符串设置颜色
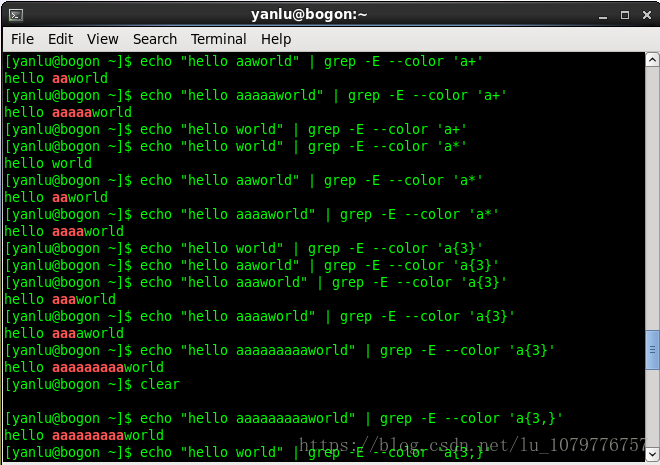
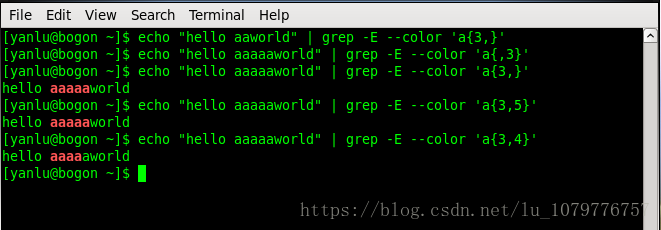
数量限定符:
| 字符 | 含义 | 举例 |
| ? | 紧跟在它前面的单元应匹配零次或一次 | [0-9]?\.[0-9]匹配0.0、2.3、.5等,由于.在正则表达式中是一个特殊字符,所以需要用\转义字符转转义一下,取字面值 |
| + | 紧跟在它前面的单元应匹配一次或多次 | [a-zA-Z0-9_.-]+@[a-zA-Z0-9_.-]+\.[a-zA-Z0-9_.-]+匹配email地址 |
| * | 紧跟在它前面的单元应匹配零次或多次 | [0-9][0-9]*匹配至少一位数字,等价于[0-9]+,[a-zA-Z_]+[a-zA-Z_0-9]*匹配C语言的标识符 |
| {N} | 紧跟在它前面的单元精确匹配N次 | [1-9][0-9]{2}匹配从100-999的整数 |
| {N,} | 紧跟在它前面的单元至少匹配N次 | [1-9][0-9]{2,}匹配三位以上(含三位)的整数 |
| {,N} | 紧跟在它前面的单元最多匹配N次 | [0-9]{,1} 相当于[0-9]? |
| {N,M} | 紧跟在它前面的单元至少匹配N次,最多匹配M次 | [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}匹配IP地址 |
位置限定符:
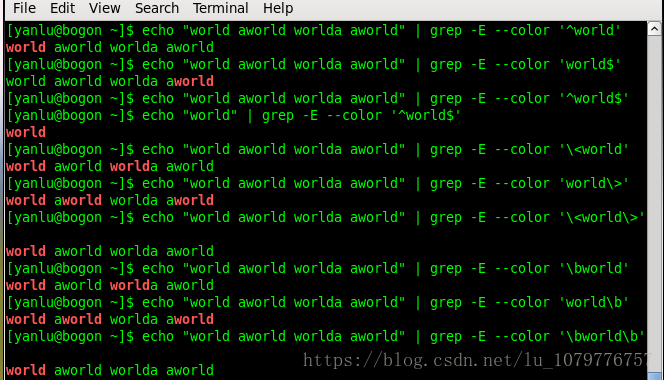
| 字符 | 含义 | 举例 |
| ^ | 匹配当前行首的位置 | ^content匹配位于一行开头有的位置 |
| $ | 匹配当前行末的位置 | ;$匹配位于一行结尾的位置 |
| \< | 匹配单词开头的位置 | \<th匹配...this,但不匹配tenth |
| \> | 匹配单词结尾的位置 | p\>匹配leap ... 但不匹配parent |
| \b | 匹配单词开头或结尾的位置 | \bat\b匹配 ... at ... 但不匹配cat ?atexit |
| \B | 匹配非单词开头和结尾的位置 | \Bat\B 匹配battery 但不匹配 attend |
举例:

特殊符号:
| 字符 | 含义 | 举例 |
| \ | 转义字符,普通字符转义为特殊字符,特殊字符转义为普通字符 | 普通字符<写成\<表示单一开头的位置,特殊字符.写成\.以及\写成\\就当做普通字符来匹配 |
| () | 将正则表达式的一部分括起来组成一个单元,可以对整得单元使用数量限定符 | ([0-9]{1,3}\.){3}[0-9]{1,3}pipei IP地址 |
| | | 连接两个子表达式,表示或的关系 | n(o|either)匹配no或neither |
举例:
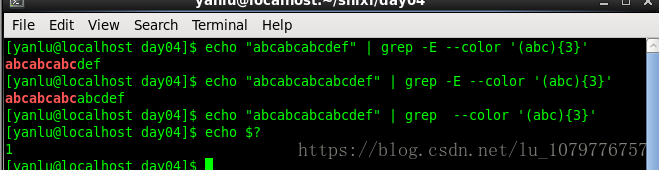
我们发现,当去除 -E 选项时,并没有匹配到任何字符,原因是什么呢?这就要引入一个知识点了,其实在本文开篇已经提到过了,那就是正则表达式的分类。
正则表达式的分类:
基本的正则表达式(Basic Regular Expression又叫Basic RegEx简称BREs)
扩展的正则表达式(Extended Regular Expression又叫Extended RegEx 简称EREs)
现在我们根据上一个例子,来看一下他们之间的区别:正则表达式的Extended规范和Basic规范基本相同。只是在Basic规范下,有些字符比如说 ?() {} | + 这些字符会被当做普通字符处理,因此要表示特殊含义的话就要在它们之前加上 \ 转义字符。而且在Extended规范下,?() {} | +应该被理解为特殊含义,取字面值,因此还是需要加上 \ 转义字符。所以 grep 工具带上 -E 选项,表示使用扩展正则来匹配,若没有,则采用基准正则匹配。

上面的例子就是对于基准正则表达式和扩展正则表达式进行了对比。结果一目了然。
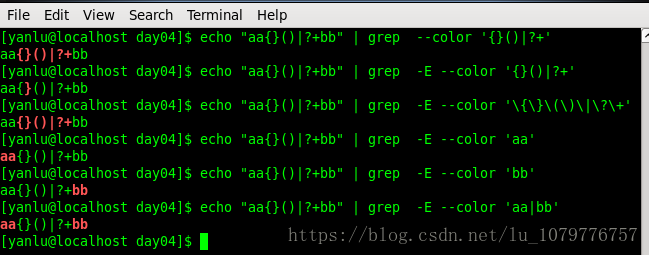
| 用来级联多个条件,只要有任意一个匹配,即可匹配,表示或者的关系,称之为析取符
其他常用通用字符集及其替换
| 符号 | 替换正则 | 匹配 |
| \d | [0-9] | 数字字符 |
| \D | [^0-9] | 非数字字符 |
| \w | [a-zA-Z0-9_] | 数字字母下划线 |
| \W | [^\w] | 非数字字母下划线 |
| \s | [\r\t\n\f] | 表格换行等空白区域 |
| \S | [^\s] | 非空白区域 |
举例:
我们在验证时出现了问题,并没有像我们所想象的结果进行匹配,这时就要印日另一个概念了,grep 和 egrep 正则表达式的特点。
grep支持:BREs,EREs,PREs正则表达式
- grep指令后不跟任何参数,则表示要使用“BREs”
- grep指令后跟“-E”参数,则表示要使用“EREs”
- grep指令后跟“-P”参数,则表示要使用“PREs”
所以要解决上述问题,必须使用-P选项
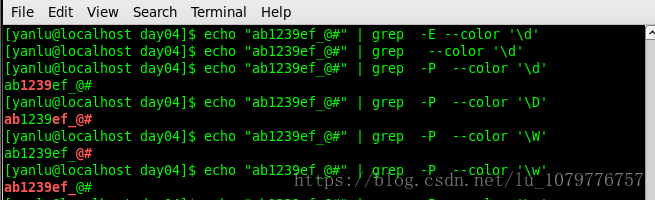
加了 “-P”选项后,我们发现,正是我们所想匹配的内容。
贪婪模式与非贪婪模式
贪婪模式
正则表达式在匹配时,会尽量多的匹配符合条件的内容。
非贪婪模式
正则表达式在匹配时,会尽量少的匹配符合条件的内容。
零宽断言
断言是用来声明一个应该为真的事实。正则表达式中只有当断言为真时,才会继续进行匹配,用于查找之前或者之后的内容,(但不包含本身),也就是像 \b,^,$这样用于指定一个位置,这个位置应该满足一定的条件,因此它们也被称为零宽断言。
(?=exp)

(?<=exp)
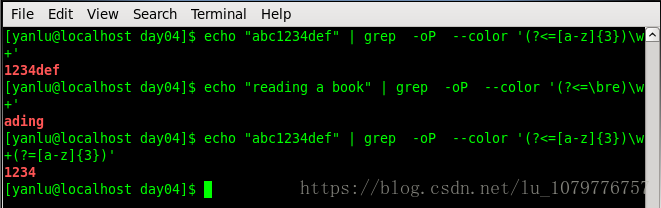
小练习
手机号码
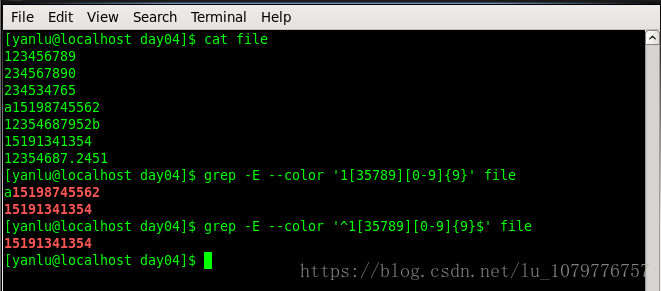
非零整数

由数字和26个英文字母组成的字符串
