正则表达式:
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
使用目的和应用场景:
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:1. 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”);2. 可以通过正则表达式,从字符串中获取我们想要的特定部分。
应用场景:
(1)验证: 表单提交时,进行用户名密码验证。
(2)查找: 从大量信息中快速提取指定内容。在一批url中,查找指定url
(3)替换: 将指定格式的文本,进行正则匹配查找,找到之后进行特定替换,(vim文本替换等)
(4)在很多技术领域(比如,自然语言处理,数据存储等),正则表达式可以很方便的提取出我们想要的信息,所以这部分必不可少。正则表达式的基本要素分为字符类,数量限定符,位置限定符,特殊符号。
下面给出实例来对正则表达式进行分析:
正则表达式基本上是与语言无关的,那么可以结合语言,工具与正则表达式进行文本处理;
grep:grep是一款Linux下按行匹配文本的工具。通常是Linux下处理文本的第一步,带有很多有用的选项。
-E: 使用扩展正则匹配,
--color: 将匹配的到内容进行语法高。
字符类:





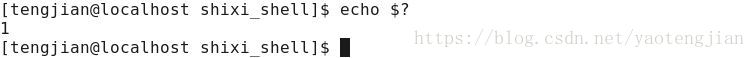

退出码:Linux提供了$?专属变量保存上一个执行的命令的退出状态码。你可以在你运行一个命令之后查看(echo $?)。
几个典型的退出状态码及其意义:
0----------------命令运行成功
1----------------通知未知错误
2----------------误用shell命令
数量限定符:


退出码的值为0,说明匹配成功;




位置限定符:
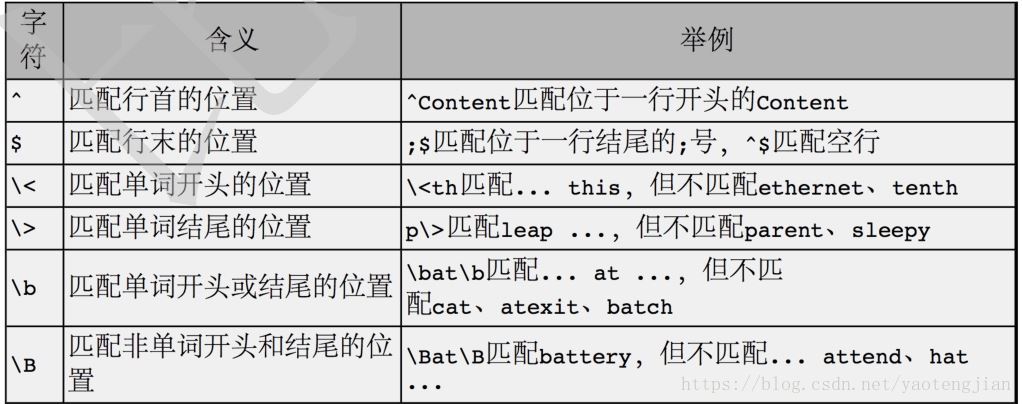
只匹配行首:

只匹配行尾:
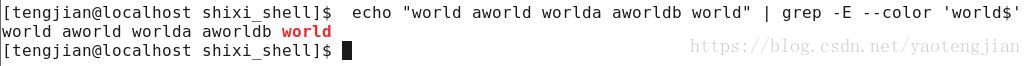
^$ 在正则表达式中,确定目标串出现的位置,我们称之为:锚点 想想,我们在哪些地方用过?(vim)严格匹配一行:

\b 用来限定是目标串中是否有以指定字符串开头的单词,我们称之为词界。 \B 称之为非词界:

特殊符号:
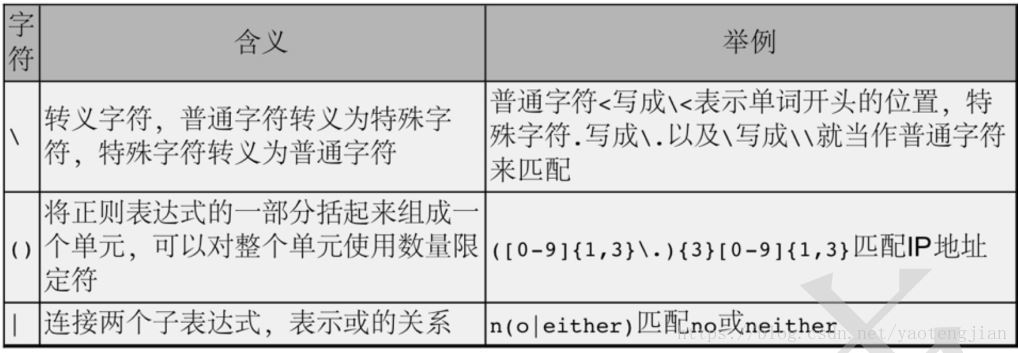

() 表示将包含的内容作为一个整体,作为一个单元,进而可以用数量限定符来进行限定。目前,我们测试 grep 工具的时候,其中有一个 -E 选项。

其它常用通用字符集及其替换:
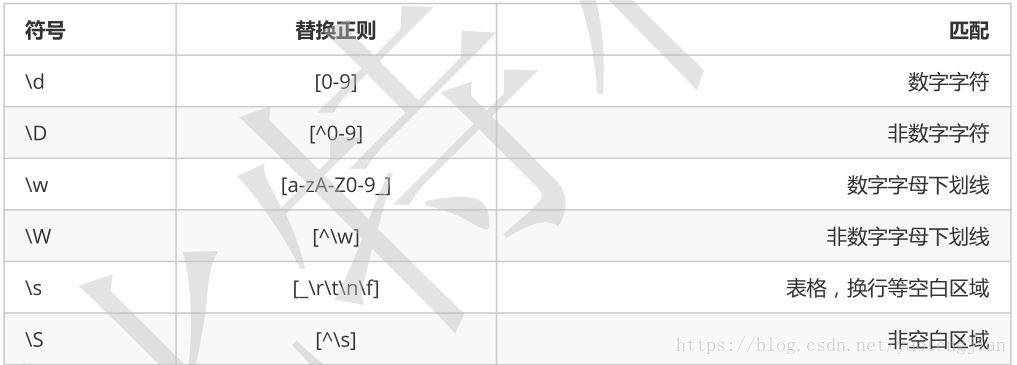
grep , egrep 正则表达式特点:
grep 支持:BREs、EREs、PREs 正则表达式
grep 指令后不跟任何参数,则表示要使用 ”BREs“
grep 指令后跟 ”-E" 参数,则表示要使用 “EREs“
grep 指令后跟 “-P" 参数,则表示要使用 “PREs"
grep 默认就是贪婪匹配,会尽量多的匹配符合条件的内容。
其它:

