Hadoop的两个部分:
- YARN集群(MapReduce2)——管理调度任务资源
- HDFS——分布式文件系统,解决海量数据存储
集群规划
| 服务器 | hdfs角色 | yarn角色 |
|---|---|---|
| Master | NameNode | ResourceManager |
| Slave1 | SecondaryNamenode, DataNode | NodeManager |
| Slave2 | DataNode | NodeManager |
安装步骤
环境预处理
- 设置节点的hostname——master和slaves:
修改 /etc/sysconfig/network,并执行命令使修改立即生效:
hostname 节点名- 设置节点间免密登录
ssh-keygen
ssh-copy-id- 添加ip地址和主机名之间的映射关系(节点自身的也要添加)

- 关闭防火墙 systemctl stop firewalld
- 添加hadoop用户并添加sudo权限
useradd hadoop
passwd hadoop
chmod u+w /etc/sudoers # 添加写权限
vi /etc/sudoers
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL #添加此行
:wq
chmod u-w /etc/sudoers #撤销写权限一、安装jdk
每个节点都需要
二、安装Hadoop2.7.2
直接解压安装包,放到/usr/local/hadoop目录下
三、修改Hadoop配置文件
先配置master节点上的,再将配置文件scp到其他节点
主要配置的文件有:core文件、hdfs文件、mapreduce文件、yarn文件等
hadoop配置文件都在 hadoop-2.7.2/etc/hadoop 目录下
(1) hadoop-env.sh

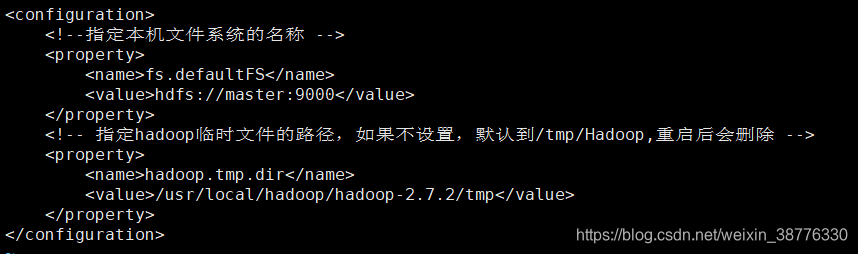
(2) core-site.xml
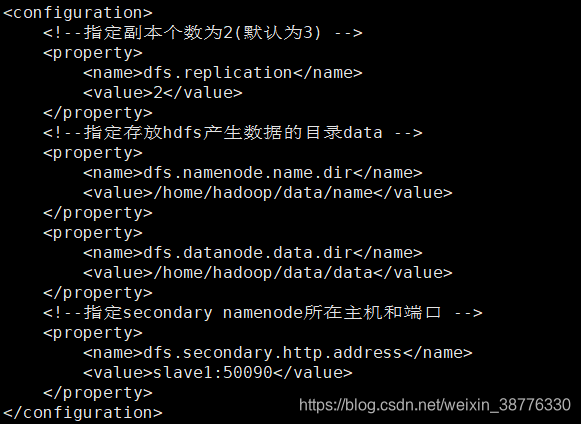
(3) hdfs-site.xml
在用户目录下(/home/hadoop)创建一个data目录,用来存放HDFS产生的数据。然后对hdfs-site.xml进行配置
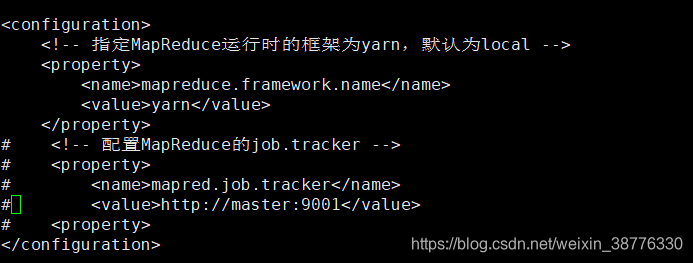
(4) mapred-site.xml

(5) yarn
- yarn-env.sh
添加export JAVA_HOME=/usr/local/java/jdk1.8.0_171 - yarn-site.xml

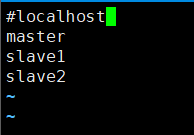
(6) slaves
添加从节点主机名,作为datanode
至此,主机master上的环境配置完毕,将所有文件夹拷贝到其他节点。
scp -r /usr/local/hadoop/hadoop-2.7.2/ slave2:/usr/local/hadoop所有机器配置完毕。
四、添加环境变量
将hadoop添加到环境变量并source (每个服务器都需要)
五、启动集群
在主节点上启动,其他服务器会被主节点通过免密登录自动启动的
- 格式化文件系统
hadoop namenode –format - 启动hdfs,jps命令查看进程
start-dfs.sh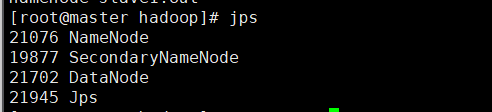
- 启动yarn
start-yarn.sh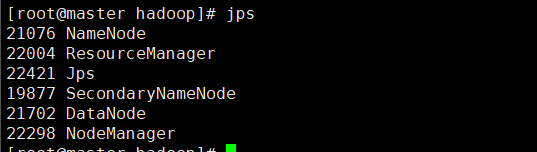
- 也可以同时启动hdfs和yarn:
start-all.sh
六、浏览器访问集群
HDFS http://13.10.61.2:50070
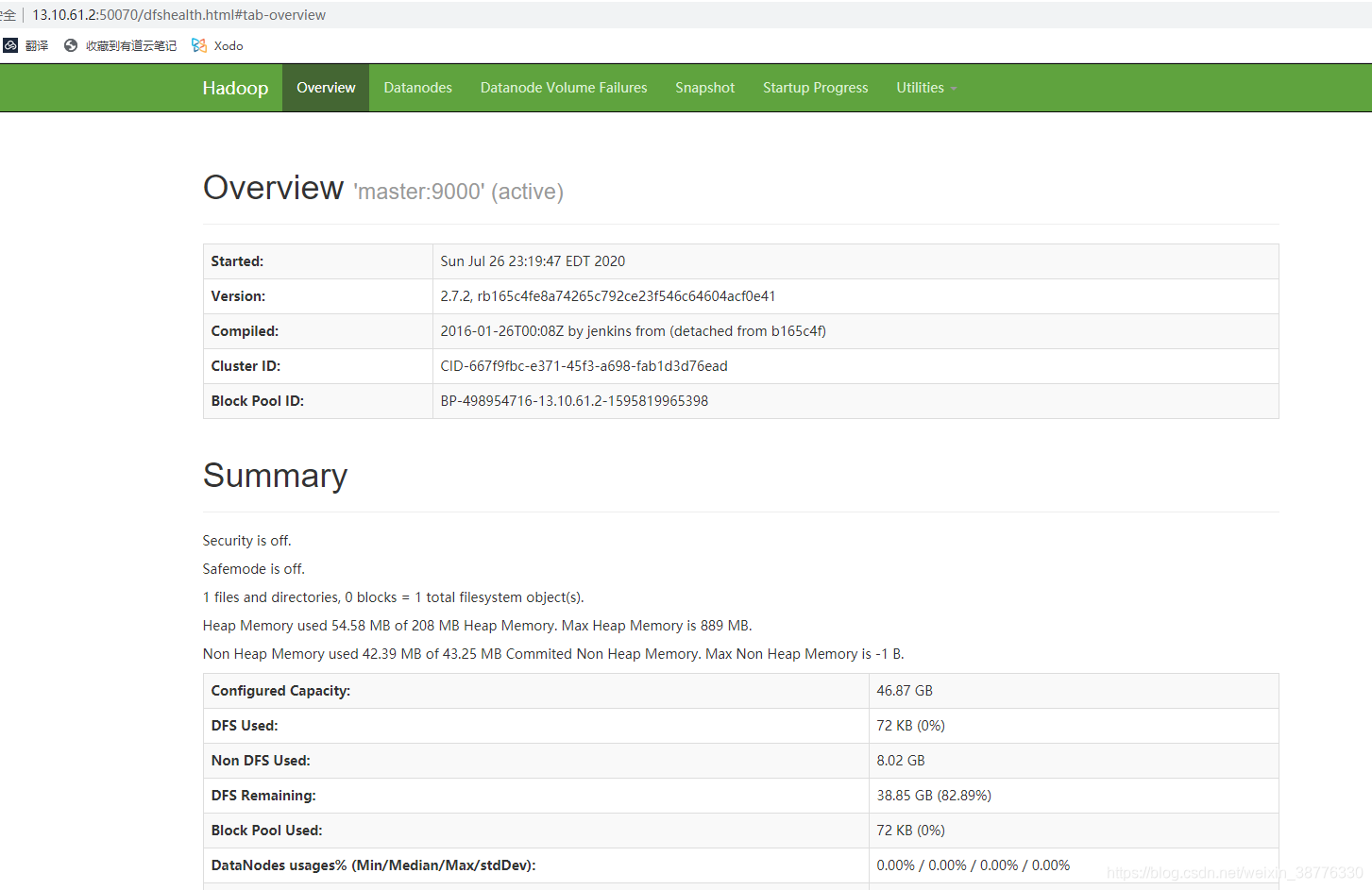
MapReduce http://13.10.61.2:8088/

七、停止集群
stop-dfs.sh
stop-yarn.sh