首个深度学习web应用,基于Flask和Keras
缘起
随着疫情缓解,在家自学TF、看看论文然后混吃喝的happy日子被迫结束T T。前往一家互联网公司的web开发组实习。期间,接触到了很多之前完全不了解的方方面面,促使我从程序员职业的角度开始思考自己的未来,这部分另有博客分析。这里主要介绍我利用摸鱼时间把学到的web开发内容和机器学习结合起来,完成的我的第一个web应用!
功能隐约眼熟?
如果看了后面的界面和功能,眼尖的人一定会发现,没错,本应用在结构上参考了塞巴斯蒂安的Python Machine Learning第九章。主要区别有:
- 我使用的keras预训练模型进行fine tuning,书中使用的scikit;
- 我使用图片上传,返回图片分类和分类概率,书中是电影评论的情感分析;
- 我使用了多线程来降低更新模型的等待时间;
- 我没有使用SQL数据库,而是在文件夹中保存图片。
为什么使用Flask和keras?
使用keras是因为其提供了预训练的MobileNet权重,非常适合拿来迁移学习做fine tunning。这样在CPU上做推理的时候,假设中的用户不会等的想砸电脑。不过我也没有实际去探究哪些预训练的模型做推理效率高。
其实,python进行web开发实在是小众,实习中后端还是用的Java+Spring MVC,前端用的js+VUE。但是Flask作为轻量级的后端框架,最大的好处就是python的后端代码和keras的模型训练等语法可以无缝衔接。并且小白一个人开发整个应用,并不会JS,所以flask的模板引擎jinja2提供了很简易(但丑)的前端,只需掌握基本的html语法就能写出前端。
功能和界面
参考Python Machine Learning第九章,用户使用的流程是
光秃秃的选择文件表单和上传按钮0.0
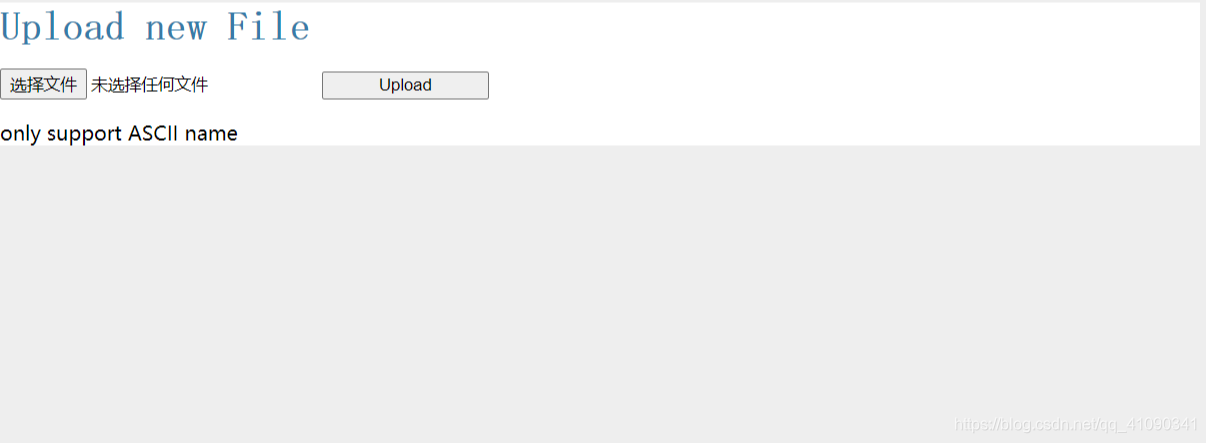
因为后面代码中secure_filename()的存在,这里偷懒,只支持英文命名的JPG和PNG格式图片,后缀不区分大小写。如果上传中文,会显示“only support ASCII name”。

这一步
- 图片上传至
./uploads保存; - 从
./uploads取出图片放入./static/images,并用保存的MobileNet权重对图片进行推理; - 前端显示上传图片、分类和分类概率;
用户可以根据自己的判断选择应用分类的正确或者错误,用于给图片打标签,后续扩充训练集,更新模型权重。

- 点击确认后,如果存在同名文件会提示"File already exists or has the same name";
- 否则根据用户选择的
Correct或Incorrect将新图片移入./static/image/Cat或者./static/image/Dog。相当于将确认图片打上标签,扩充训练集,用于更新模型权重。 - 模型权重更新需要重新训练,耗时较长,故使用子线程后台运行,先返回前端,再完成更新。
Note: 上文中的相对路径都是相对于app.py的。
项目结构和代码
目录结构
│ app.py
│ repredict.py 加载权重用于预测
│ TryMobile.py 更新权重
├─static
│ │ cats_dog_mobileNet.h5 用于预测的权重
│ │ files_cat.npy
│ │ files_dog.npy 保存新增标签图片path的numpy数组
│ │ style.css 从flask教程白嫖来的样式表
│ └─images
│ │ 存放用户未提供反馈,没打标签的图片
│ ├─Cat
│ │ 存放标签为猫的图片
│ └─Dog
├─templates
│ show.html
│ thanks.html
│ upload.html
└─uploads 保存所有上传图片
代码
请见我的github仓库 MobileNet_Flask_Web_Application 欢迎各位大佬来star、提issue,共同学习~

Fine-tunning
使用Keras自带的Mobilenet在ImageNet上训练的.h5文件,去掉其分类器部分:最后的GAP层和Softmax层,替换为两层FC分类器
x = Dense(1024, activation='relu')(x)
#添加类别分类器,只有两类
classifier = Dense(1, activation='sigmoid')(x)
最后一层的激活函数使用sigmoid,用于二分类(原来是1000类)。使用2000张猫和狗的图片作为训练集,1000张做验证集,在CPU上用了约20分钟5轮将验证集精度达到90%以上。
总结
整个项目的功能到实现都是我拍脑袋想的,而且我是零web开发基础,所以和实际应用肯定有很多不符之处,还要很多可以改进之处,这里略举几例:
- 用户恶意打标签可以让权重崩坏
- 图片似乎保存太多次,占空间,而且IO操作拖慢速度
- 最后的更新权重线程还是要结束之后才能重新用于预测
实习期间的收获有:
- 学习SQL基础,对数据库和后端的关系有了基本了解,不过在这个项目中并没有用上;
- 学习Flask框架,并用于开发博客、AI应用,实践了将keras模型嵌入到web应用中;
- 学习html基础,能根据手册大致读懂文件;