指令流水线作为计算机组成原理中一个重要的组成部分,弄清指令流水线的操作步骤对制作CPU有着很大的帮助。本文主要讲述下指令流水线的相关知识。
指令流水线是较单周期指令和多周期指令更有效率的一种方式。指令流水线并没有减少每条指令执行的时间,反而可能增加一定的时间(原因下文解释),指令流水线改变的是指令的吞吐量,从而加快指令的执行速率。对于指令流水线的介绍可分为三部分:数据通路设计、控制器设计、冒险处理。本文先以绪论为引导,再以三部分为主线,介绍指令流水线。
注:作者学习的教材是《计算机组成与系统结构(第二版)》由袁春风老师主编,清华大学出版社出版。本书中设计的指令体系结构是MIPS体系结构,本文所有内容都是围绕MIPS体系结构进行介绍。
绪论:
先介绍一下什么是流水线?
在此举一个简单的例子(一看就懂):洗衣服分为三步:洗、烘干、叠。三部分都有独立的三台机器进行操作。所谓流水线就是当第一批衣服洗完进入烘干时,可以放第二批衣服进入洗的环节。因为各个步骤相互独立,不会有影响。等到第一批衣服进入叠的环节时,第二批衣服进入烘干,第三批衣服进入洗的环节。确保了在绝大多数时间,三台机器在同时工作。提高了吞吐率,这个方法就叫做流水线。流水线的名字因三个环节叫做三级流水线。
再介绍一下为什么指令可适用于流水线?
在执行指令的过程中,可将过程拆分为5个步骤:取指、译码、取操作数、计算、写回。这五个步骤分别可有不同的部件进行实施,满足了流水线的基本要求。既然流水线可提高指令的执行速度,那何乐而不为呢?
再解释一下为什么指令流水线可能增加每条指令的执行时间?
在流水线设计中,为达到吞吐量提高的目的,在同一时间段不同部件执行不同的命令。这对部件执行的规整性提出了要求,所谓规整性就是任何部件完成任何一个操作的时间都是相同的。类似于短板效应的原理,每个阶段的时间都要选择最长的,加起来单条指令的时间就多了起来。
数据通路设计:
根据单周期指令的执行和MIPS体系结构的特点可知,在所有指令中load指令包含5个步骤,使用时间最长。故以其为基础设计五级流水线。
五级流水线数据通路基本框架如下图(以下将对此图进行介绍,以理解数据通路的设计):

对该图做一个基本的介绍:上文说过五级流水线分为五个步骤,体现在图中即为IF、ID、EX、Mem、Wr五阶段。在每两个阶段之间有长方形(例如IF/ID,ID/EX等)代表流水段寄存器,记录上阶段传入下阶段的一些数据和控制信息。本图中控制信息使用虚直线代表。为了更好的执行指令,使用时钟周期的方式统一控制,写操作发生在时钟周期的下降沿。
下面分别对五个阶段进行介绍:
1)Ifetch(IF)段:
IF段主要内容是进行取指操作,集成在取指令部件IUnit进行。指令取出后需要改变PC的值,顺序情况下PC直接加4或者加1(取决于是以字节编址还是以字编址,以字编址加1,以字节编址加4。因为一个字等于四个字节)。但在branch和jump指令中PC需要跳转,则PC加4后直接改变为跳转的地址。
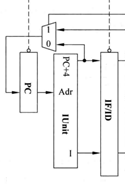
如上图,进入PC的地址由一多路选择器决定来源,正常指令使用PC+4,branch或jump使用额外指定地址。
解释IUnit通往IF/ID流水段寄存器两条线的意义:第一条线保存的是PC+4的地址,第二条线保存的是取出的指令。
在此解释一下保存PC+4的原因:在大部分情况中,beq指令用于函数调用,函数调用过后需要返回原来跳转的位置继续执行下面的内容,所以提前保存PC+4的值,保证跳转后还能回到原位置。
1) Reg/Dec(ID)段:
ID段进行指令的译码,以及取操作数。根据不同类型的指令(R型,I型,J型)对指令进行切分,从不同的位置得到操作数地址。这里的操作数地址理解为操作数所在寄存器的编号。
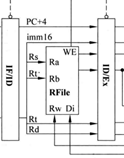
如上图,RFile代表寄存器组,在MIPS体系结构中共32个寄存器。所以Rs、Rt、Rd都是用5位表示(2^5 = 32)
解释各条线的含义:译码结束后,已知指令类型操作数位置。PC+4原因与IF段相同,imm16用于I型指令时,Rs和Rt(上面的),用于R型指令,从寄存器组中取出两个源操作数,目的地址Rd需要等指令执行完之后采用,先传入下一流水段寄存器。Rt(下面的)代表I型指令的目的寄存器,指令执行完采用,所以传入下一流水段寄存器。Rw、Di、WE是Wr阶段才用到,后面进行解释。
目前为止,ID/EX流水段寄存器中包含操作数,并且已知操作类型,下一步可进行指定操作的计算。
3) Exec(EX)段:
本段主要进行运算,不同指令操作数的源地址不同。
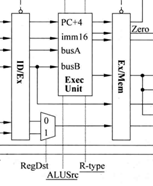
如上图,Exec Unit是运算执行部件。不单单是一个加法器(因为会支持or/and等操作)
依次解释各线的内容:(Exec Unit左,从上到下)PC+4内容与IF段相同。无论I型还是R型busA的来源是相同的(指令中的rs),但对于busB来说I型来源是imm16经过扩展和的结果,R型是之前的rt地址中取出的操作数,这个会通过多选器进行选择。RegDst是经过ALU计算后的目的地址,R型指令送到rd中,I型指令送到rt中,二者选其一放入Ex/Mem流水段寄存器。(Exec Unit右,从上到下)PC+4依旧,第二根是zero信号用于判断是否进行branch跳转。第三根是16位立即数,无论是branch跳转还是jump都需要对16位立即数做修改得到跳转地址。第四根代表ALU运算的结果。busB引出一根进入Ex/Mem流水段寄存器是为了在sw指令中,busB输出的是需要存入存储器的数据。
4)Mem段
关于Mem段是访问存储器,在MIPS中,只有sw/sh/sb/lw/lh/lb两类指令可以访问存储器,在其他类型指令中是不需要有这步的。为了规整性设计,在数据通路设计中也设计了旁路。
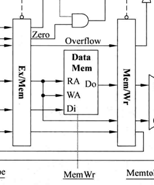
解释一下各线的内容:Data Mem左侧第一根线是写回的PC+4。下面一根Zero代表是否为零,在beq指令中,只有zero信号有效(为1)才会跳转。Overflow代表是否溢出,只有在有符号操作中才涉及是否溢出。例如在加法指令中可能存在操作数结果溢出的情况。这时需要引发异常。(对于异常的介绍不在本文的范围内)RA/WA即为ALU运算的结果,作为读/写存储器的读地址/写地址。Di是sw指令中待存的数据,Do是lw指令中待取的数据,与RA/WA相同,直接进入Mem/Wr流水段寄存器的线代表当指令是非访存存储器类型的时,ALU计算出的结果就是要写到寄存器中的内容。下面两个流水段寄存器之间的直达线代表的是上一阶段选出的目的地址。
5) Wr段
Wr段就是将得到的结果写回寄存器,两根线分别对应于写回的数据访存存储器获得还是通过ALU运算获得。
控制器设计:
带控制器通路图如下所示:

流水线的控制器设计类似于单周期。控制信号的来源是指令,所以只有在指令译码后才会产生控制信号,也即在流水线前两个阶段的时候是没有控制信号的,所有指令是通用的。控制信号在流水段寄存器中相互传递,并在合适的阶段作用于数据通路的各个模块,大多是各个模块的多选器。可以简化控制信号的传递过程如下图:
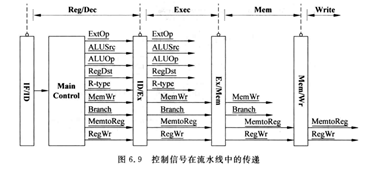
其中控制信号的全拼可在我另一篇博客中查看(网址为:https://blog.csdn.net/gls_nuaa/article/details/106200686)link
在此对各个控制信号的作用地点做一下说明:
ExtOp:当指令为I型/J型时,需要进行扩展。扩展分为两类,分别是符号扩展和零扩展。在R型指令中不需要扩展。MIPS指令中只有andi/ori/xori需要进行零扩展,其余I型指令都是符扩展。
ALUSrc:代表ALU操作数运算的来源,在R型指令中操作数来源于寄存器,I型指令中操作数来源于扩展器
ALUOp:代表ALU运算的种类(加法/减法/异或/。。。),是ALU-control模块的输出。同时ALU-control模块的来源是指令,对于I型指令来说是opcode(31:26),对于R型指令来说需要结合funcode(5:0)。
RegDst:代表结果存储的位置,R型指令存于rd,I型指令存于rt。
R-type:是否是R型指令,关乎到ALUOp等控制信号是否取决于后六位指令。
MemWr:是否需要向存储器中写,在所有指令中只有sw类指令该控制信号有效(为1),其余都是无效(为0)
Branch:Branch是由beq类信号决定,并结合zero信号,最终决定下个pc的数值。
MemToReg:该信号是决定写回寄存器数值的来源,来源分为两种:由ALU计算得到或者从存储器取得。
RegWr:该信号决定是否向寄存器中写,需要写的时候为1,不需要写的时候为0。
值得注意的是在有些指令中,部分控制信号不起到作用(选哪个都可以)。这类控制信号可记为x,但在是否写例如MemWr/ RegWr这种是必须严格决定是0或是1的。
冒险(冲突/Hazard)处理:
如果说单周期相较于流水线有优势的地方可能就是单周期不需要关注是否有冒险产生的问题。冒险可以理解为前后指令执行过程中与流水线结构所产生的冲突。大致分为三类:结构冒险、数据冒险、控制冒险。
1. 结构冒险:
所谓结构冒险就是在同一时间,不同指令处于不同阶段,但对寄存器/存储器又读又写。(寄存器一脸懵:我到底该干嘛?)。如下图所示:

解决办法:
简单的想法是:只要保证不在同一时间读写即可。可以通过优化指令的执行顺序,让指令之间在不同阶段读写即可。但没有一万,也有万一。万一无法做出这样的优化怎么办呢?所以我们需要一种更为通用的办法:将读写端口分开,在寄存器/存储器设计中加入时钟,在时钟下降沿(前半周期)写数据,上升沿(后半周期)读数据。这样就完美解决了二者之间的矛盾。而且一定要注意是先写后读。同时对于存储器中划分指令存储器和数据存储器也是为了解决结构冒险的问题。
2. 数据冒险
下面举一个例子引入数据冒险:
add $t1 $t2 $t3
sub $t4 $t1 $t2
观察这个例子,把2和3中相加,结果放到1中。再用1减去2,结果放在4中。根据我们对于流水线的简单了解可以知道,指令只有在完成五个阶段后(即Wr阶段)才可以被写回使用,但sub指令执行的时候,在Reg/Dec(第二个阶段)就需要读出1的值。在流水线中相邻指令相差的是一个阶段。如果不做处理,那么sub读出的就会是1的旧值。那计算不就是错了嘛!
问题总会有解决的办法,在MIPS中解决的办法就是使用转发/forwarding(也叫旁路/bypass)。转发就是改动数据通路,提前将结果拿出做操作。
转发的原理如下:看上面的例子,在add指令执行过程中在Exe阶段就已经算出1的新值。如果这个时候把结果移到Reg/Dec阶段去执行sub指令。刚好满足阶段相差1的流水线特性。由于要实现过程转发,就需要从硬件上解决问题。
那么接下来的问题就转移为了:什么时候使用转发,并且如何控制转发?
如下图所示,可能有两种情况需要转发(图中的两个add指令,分别是下面一条指令/两条指令发生数据冒险),这个时候我们就可以使用转发。但不同的需要阶段决定了转发的阶段也不同。在绿色中ALU以后需要转发,在红色中可以ALU隔一个阶段再转发。
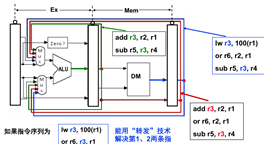
以上解释了转发的两种可能性,那么数据通路的设计就需要适应两种可能性。当检测到满足转发条件的时候,通过以上两条通路进行转发。
那么问题来了:**转发条件是什么呢?**下面一起来看看吧,对以上图做以下标注(C1(a)/C1(b)/C2(a)/C2(b))。如下图所示:
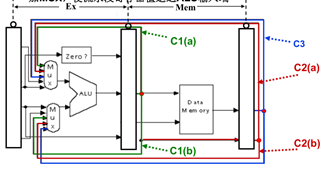
对于转发检测,可简单做以下规定:
如果本条指令源操作数和只上条指令的目的寄存器一样,而与其他指令间无冒险关系,则有以下公式:

如果本条指令源操作数和上条指令的目的寄存器一样,且和上上条指令也有数据冒险冲突,则不转发上上条指令的结果,那么有如下公式:

但转发是万能的吗?看看下面这个例子:
转发的克星:load-use冒险
lw r3,100(r1)
or r6,r3,r1
lw的目的寄存器是or操作的操作数寄存器。但lw指令中r3只有在mem阶段(第四阶段)之后才会得到。但or指令第二阶段就需要。由前面的转发可知转发最多提前一个阶段,所以在这种情况中光靠转发是不行的。这种情况就叫Load-use冒险。解决的方法就是中间再引入一个阻塞(no
operation/bubble)来延迟一个周期再使用转发。
3. 控制冒险
所谓控制冒险是指在beq/jump等跳转指令或异常指令中,在第四阶段才能够知道是否跳转。不跳的话一切正常,跳的话后两条指令都已经被读入。需要被清空以执行跳转后的指令。最简单的方法是直接清空前面的流水段寄存器。(但是简单的方法必定没有效率)。由于控制冒险只发生在转移指令中,所以可以通过分支预测的方法来判断下一条指令是否是跳转指令。如果符合跳转指令则按照直接清空的方法处理。既然是预测,那么结果就会有两种:预测正确和预测错误。
分支预测分为两种:静态分支预测(也叫简单分支预测)和动态分支预测。
静态分支预测:类似于转发的思想,讲分支指令提前。在译码阶段的时候就直接判断是否转移,原因是此时已经知道指令是什么并结合运算可决定是否转移。这样降低了损失(3条指令减低为1条指令)。
动态分支预测:记录预测的结果,并结合之前的记录和当前的指令预测结果改变预测下条指令的结果(类似于算法中动态规划的填表思想,当前的操作受之前的结果影响)。
动态分支预测可分为一位和两位(当然还有多位,不过课本上只介绍了比较简单的)
一位分支预测是假定开始预测指令不转移,如果预测正确则下条指令继续保持该预测,若预测错误则下条指令预测相反的结果。对于预测失败的指令,则从失败的下条指令开始预测相反结果。状态转移图如下:
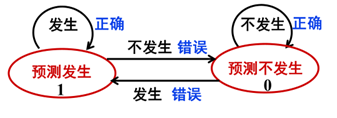
两位分支预测是给两次机会。错了一次(第一次)先不变状态,看再下一次(第二次)的情况,如果第二次仍是错的那么就改变状态,第二次是对的就恢复第一次的状态。状态转移图如下:
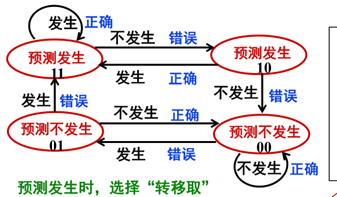
在现实应用中,动态预测精度更高,得到更广阔的应用。但不同处理器可能使用不同的动态预测方法(预测位数不同,如Pentium 4使用4位预测位)
流水线的学习就告一段落,但学到的大多都是理想情况。关于各种特殊情况的处理,希望在以后的学习过程中慢慢完善。
ACKNOWLEAGEMENTS:
The author would like to thank Prof. Xiangping Bryce Zhai,a teacher of computer composition principles, for his careful teaching and Prof. Chunfeng Yuan for compiling excellent textbooks to enhance understanding.
本文作者水平有限,如有不足之处,请在下方评论区指正,谢谢!