Intel486 Architecture Overview
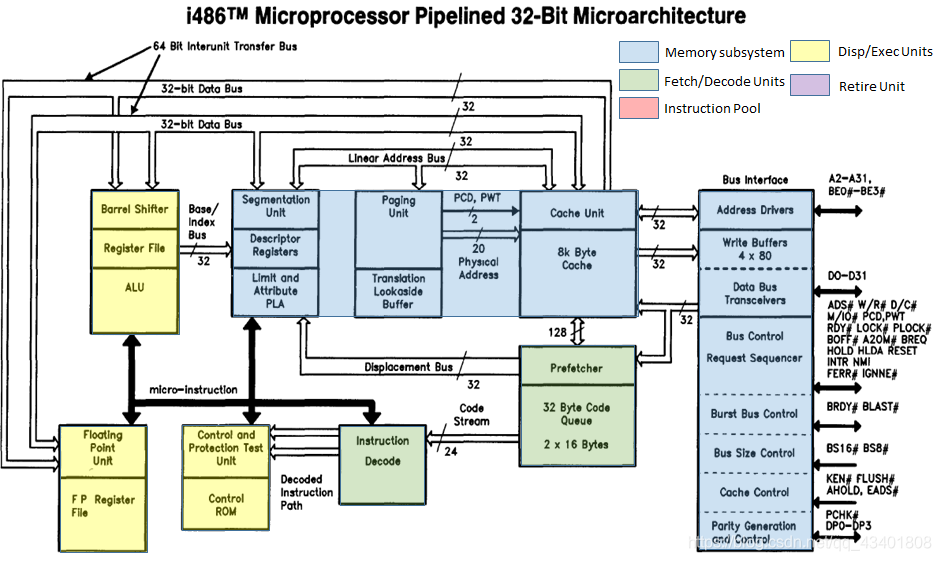
80486相比80386新增了几个功能单元,包括高速缓存单元(即片上的一级缓存),逻辑上的两级译码单元,浮点单元也集成到处理器执行核内部。

8K字节大小的片上一级高速缓存可以存储代码和数据,缓存行大小16字节,采用4路组相联结构,伪最近最少使用算法(pseudo-LRU)缓存行替换策略。
8K = 8192 / 4-way / 16 cache line size = 128 (index)

片上的浮点单元借助整型指令流水线进行数据访问。从下图中可以看到两条32位的内部数据总线,在一起协作相当于一条64位的内部单元间的数据总线。 在一个时钟周期内,内部总线可以将8字节的数据从一级缓存传输到浮点单元。处理器内部浮点计算和整型计算可以并发执行。
Intel486 Instruction Pipeline Details
Intel486™处理器有一条完整的整型指令流水线,理想条件下,峰值处理能力可以达到每个周期执行一条指令。相比80386,486使用了5级流水线:取指,译码阶段1,译码阶段2,执行,执行结果回写。

下面详细的介绍整型流水线的每一级
5级流水线由以下构成:
- 取指 (PF) – 从一级缓存中读取16字节指令流(即一个缓存行大小),存储在指令队列中。这个指令队列由两个16字节的缓存构成,共32字节。取指单元会选择其中一个缓存存储指令流。
- 第一级译码 (D1) – 带有前缀的指令会在D1中停留2个周期
- 第二级译码(D2)- 也叫地址生成阶段,该阶段并行地计算出有效地址和线性地址。
- 执行(E) - 指令的执行阶段。对于简单指令(只需要一次机器计算的指令)可以在1个时钟周期内完成,这样可以达到每个周期完成一条指令的吞吐量。复杂的指令必须要消耗多个时钟周期。
- 回写(WB) - 回写阶段更新参与运算的寄存器。
注意:执行阶段的数据访问操作比指令预取阶段的指令预取操作具有更高的优先级。换句话,指令预取只有在预取指令队列有空位,同时执行单元没有数据访问请求的时候,才会利用空闲的总线周期进行指令预取。
下图是80486的指令流水线执行示意图。

注意CPU芯片上有一个特别设计的逻辑电路可以在某些情况下避过回写阶段。例如,如果当前指令在执行阶段计算出来的结果会被下一条指令使用的话,则下一条指令不用等待当前指令回写阶段完成就可以直接开始执行。这种情形被称为回写旁路writeback bypass。

Optimization Consideration
Addressing operands
对于汇编程序员和编译器开发人员来说,需要注意的是索引寻址模式会消耗两个时钟周期用于地址计算。其他的寻址模式通常可以在一个时钟周期内完成。
Branching code
同时也要注意分支跳转(taken branch)会导致2个时钟周期的性能损失,因为译码后的指令(D1和D2阶段)会被废弃(flushed)。是分支指令但没有发生跳转则不会影响指令流的执行,因为下一条要执行的指令已经译码完毕可以直接进入执行阶段。
| 在C语言层面上,如果经常发生exec_2,则应该把exec_2直接写在if语句下面,即颠倒一下exec_1和exec_2。 If (test_condition) { exec_1; // not-frequently happen } else { exec_2; // frequently happen} |
FPU Instruction Selection
Intel486处理器的执行核被设计为最高效的执行“最常用指令”。因此,精心地选择指令顺序可以获得更高的执行性能。另外,避免流水线僵死的代码也可以提升程序性能。
| Q: 什么是pipeline stall? A: 根据wikipedia https://en.wikipedia.org/wiki/Pipeline_stall Pipeline stall是为了应对一些可能的危害(hazard), 对下一条要执行的指令进行延迟。 关于hazard,https://en.wikipedia.org/wiki/Hazard_(computer_architecture) |