Instruction Pipeline
关于Pentium Pro的指令流水线,我从4个来源看到3种不同的说法:11级,12级和14级(没有13级说,不大吉利吧)。其实大同小异,不用纠结到底是多少级,掌握每级的功能和用途才是学习的重点。分别摘录如下:
1. Mindshare的Pentium Pro and Pentium II System Architecture书中说是11级,并且对每一级进行了非常详细的讲解,很值得参考。

2. Wikepedia中说Pentium Pro是14级流水线,但是对每一级未有说明。
| The Pentium Pro incorporated a new microarchitecture in a departure from the Pentium x86 architecture. It has a decoupled, 14-stage superpipelined architecture which used an instruction pool.
Pentium Pro处理器集成了一套不同于Pentium架构的全新微架构(注:即P6微架构)。该微架构是一套解耦合的14级超流水线架构,同时还引入了微指令池。 |
3. 在Performance Characterization of the Pentium® Pro Processor论文中,提到了Pentium Pro有14级流水线,同时极简单的说有序前端是8级,乱序执行核是3级,以及终了逻辑是3级。
| The Pentium Pro processor implements a 14-stage pipeline capable of decoding 3 instructions per clock cycle. The in-order front end has 8 stages. The out-of-order core has 3 stages, and the in-order retirement logic has 3 stages. |
4. Pentium Pro的SDM卷2,第2-5页中说,Pentium Pro的流水线是12级,未有详细说明。
| To handle this level of instruction throughput, the Pentium Pro processor uses a decoupled, 12-stage superpipeline that supports out-of-order instruction execution. |
P6微架构的指令流水线使用了动态执行机制,揉合了乱序执行和预测式执行(由硬件级别的寄存器重命名和分支预测提供支持)。 处理器有一个有序的发射流水线,这个流水线将Intel386格式的x86指令分解(即翻译,或转换)成相对简单的微指令,然后这些微指令会被分发给一个超标量乱序执行核执行。处理器的乱序执行核实现了多个流水线,可以同时处理整型,跳转,浮点和内存访问操作。若干执行单元也可能会集成在单个流水线中实现,例如整型算术逻辑单元ALU和几个浮点执行单元(加法器,乘法器和除法器)可以共享某单个流水线。通过交错机制,数据高速缓存可以实现伪双端口(pseudo-dual ported)操作,其中一个端口专用于读取,另一个端口专用于存储。大多数简单运算(整型ALU,浮点加法,甚至浮点乘法)可以流水线化,达到每个时钟周期1至2运算的吞吐量。浮点数除法无法流水线化。高延迟的操作可以和低延迟的操作并发执行。
![]()
In-order Pipeline
有序流水线执行分支预测,指令地址翻译,指令预取,指令译码,以及寄存器重命名。代码生成器(例如编译器或者汇编程序员)对于这几个阶段都要有性能方面的考量。只要BTB分支预测成功,有序流水线的这几个阶段通常都不会影响程序执行性能。当分支预测失败时,这几个阶段就可能会产生一些延迟,用来获取将要执行的新指令。
Out-of-order Core
乱序执行团(OOO Cluster)解决数据依赖,分发微指令到对应的执行单元,缓存微指令的执行结果知道该指令之前的所有操作都完成,使得处理器的状态可以按照x86指令的顺序正确地得到更新。
Caches
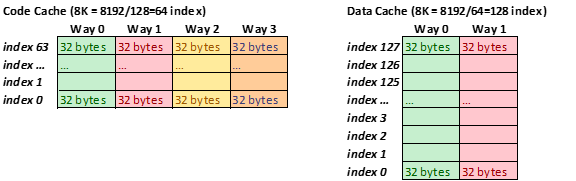
片上的L1 Caches包括了1) 8K字节,4-way set associative指令cache,和2) 8K字节,2-way set associative数据cache。Cache Line大小都是32字节。 L1 Cache miss也未必会招致完全的读内存延迟。L2 cache makes the full latency caused by a L1 cache miss。 L1和L2都miss的最小延迟是14个时钟周期。
Branch Target Buffer
Pentium Pro处理器使用了一个类似于Pentium的分支预测算法。通过BTB缓存,先前看见过的分支可以动态的被预测。以前未看见过的分支只能使用一个静态预测算法来预测。BTB存储着先前看见过的分支的历史记录和对应的目标地址。当遇见一个分支语句时,BTB直接将目标地址交给指令预取单元。一旦分支被执行,BTB将更新成目标地址。
很难确定分支语句消耗的时钟周期。Pentium Pro有多个级别的分支支持,可以按时钟周期数来量化:
未跳转分支(not-taken branch)不会引发性能损失。 未跳转分支包括以下两种情形:
- BTB预测不会发生跳转的分支
- 不在BTB中(默认被预测为不跳转)的向前分支(forward branch)。
| 注: 由于分支预测失败,处理器需要获取正确的跳转后指令才能继续执行,因此产生程序的性能损失(penalty)。Intel文档将性能损失分为几档
详细情形见下 |
被BTB正确地预测,且发生跳转的分支会有1个时钟周期的性能损失。指令获取将被挂起1一个时钟周期。在这1一个周期内,指令译码单元没有指令可以翻译,因为导致小于4个微指令的分发。这种类型的微性能损失包括先前见过的无条件跳转分支(即在BTB中)。对于正确预测的跳转分支,这种小性能损失是1个周期不做指令获取,再加上跳转之后没有微指令发射。这种损失通常会与处理器的其他操作重叠。
预测失败的分支会引发大性能损失。
分支预测失败至少导致9个时钟周期(有序发射流水线的长度)的损失,包括无法获取指令,加上额外的等待时间,这些时间用于等待the mispredicted branch instruction to become the oldest instruction in the machine and retire。这种性能损失是不可预测的,主要依赖于执行环境,但是实验表明会有大约10-15周期的损失。
Decoder Shortstop
没有在BTB中的分支,但是如果被decoder shortstop branch predication机制正确地预测了,会发生小性能损失(大约5-6周期)。这类情形包括以前没有出现过(没有在BTB中)的无条件直接分支。译码器总是可以正确的预测这种分支。
负偏移的条件分支(conditional branches w/ negative displacement),例如闭循环分支(loop-closing branch),会被shortstop机制预测为发生跳转(taken)。这种分支的第一次跳转会是小性能损失,随后的第二次跳转则是微性能损失,由BTB正确地预测。
不再BTB中但是由译码器正确预测的分支导致的小损失大约是5个周期,相比之下,预测失败的分支或者根本没有预测的分支会导致10-15个周期的大损失。
Instruction Prefetcher
指令预取单元会激进地按直线顺序预取指令。很明显,如果设计代码没有循环分支而是顺序执行能充分利用这种优势。而且,将不常执行的代码隔离到过程的底部或者程序的结尾处,这样也可以避免不必要的预取而提升指令预取的效率。
注意指令预取总是以16字节对齐。就像Intel486处理器一样,Pentium Pro对齐在16字节边界处预取指令。因此,如果一条分支指令的目标地址(例如汇编程序中某个标签的地址)等于14 mod 16处,在第一个周期内只会有2个字节的指令被预取到。
目标地址布局示例图。 Target address % 16 = 14,即target address = n * 16 + 14。

要获得最佳性能,可以把JUMP/CALL/RET指令的目标地址对齐在16字节处。但是这样可能会增大代码段的长度,而且会花额外的周期数来译码NOP指令,处理cache miss等。对于分支跳转对齐与代码长度的折中考虑是很敏感的,只有“重要的分支目标”才需要对齐。有性能剖析和反馈能力的编译器可以提供分支指令的动态频率,这样可以更好的指导目标地址的对齐策略。