80386 Architecture Overview
80386是Intel的第一代32位x86架构处理器,内部32位的数据通路,外部32位的数据总线与地址总线,标志着32位程序设计时代的到来。硬件层面上的特权级指令,多任务,32位保护模式,虚拟内存管理等机制为32位的多用户多任务操作系统提供了原生支持,具有划时代的意义。
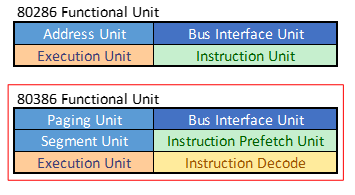
80386架构主要有以下主要的单元构成:总线接口单元,指令预取单元,指令译码单元,内存管理单元(包括段管理单元和分管理单元),以及执行单元。相比起80286,386新增了独立指令译码单元。286的地址单元扩张成了内存管理单元,由独立的段管理单元和页管理单元构成,所以有时也称386的内存管理是段页式管理机制。
下图是一个较为详细的Intel386™ DX处理器的功能模块图。对该图的详细讲解会放在其他章节里,这里供读者参考。

80386 Instruction Pipeline Details
80386依然使用了类似于286的3级流水线:取指,译码和执行。

需要注意的是,从下图中可以看出在某些情况下,下一条指令的地址计算可以和当前指令的执行并行进行,在某种程度上增加了并行度,提升了指令的吞吐量。但是地址计算并不是80386指令流水线中独立的一级。

Instruction Prefetcher
指令预取单元从外部存储器中读取指令流。预取到的指令临时存储在4-deep,4-byte-wide的预取缓存中(TODO: 是不是意味着指令缓存是4x4=16字节?)。这些指令接下来将会由指令译码器处理。
注:由于x86指令属于变长指令格式,预取缓存中的指令并没有划分出指令边界,所以我们称之为指令流。
Instruction decoder
指令译码器将译码后的指令存储在一个3-deep(TODO: 意味着可以保存3条已译码的指令)的先入先出队列中,这个队列被称为已译码指令队列。指令译码器将指令预取单元和处理器执行核解耦合,与两者都有各自的通信协议。
Execution Core
处理器执行核(即前两代产品中执行单元EU)一次执行一条指令。在某些条件下,当前指令的最后一个时钟周期可以与下一条指令的有效地址计算重叠在一起执行,参看下图中的MMU部分(以红线标出)。

Optimization Consideration
从编译器开发人员的角度来看,指令预取/译码/执行3阶段 的解耦合, 执行核的顺序执行特征,这两点几乎都没有对指令的调度提出太多需求。在计算有效地址时避免使用索引寄存器可以节省一个时钟周期。 最好的优化方法就是非常小心的选择指令使得执行时间最小化。