所在领域的问题
源自信息系统的事件日志支持对业务流程的全面分析。但是,日志可能包含有关参与流程执行的单个员工的敏感信息,这就存在对事件日志进行隐私泄露攻击的风险。
提出的新方法
引入了PRETSA,一种新的日志清理算法,它在k-匿名性和t-封闭性方面提供隐私保证。它避免了员工身份,事件日志中的成员身份以及他们基于敏感属性的特征的披露(如绩效信息)。
得出的新结论
通过事件日志前缀树的逐步转换,保持了对于发现性能注释的过程模型的高效用。
问题引出
随着过程挖掘潜力的展现,组织加强了对其过程的精确和精细记录的努力。然而,一旦一个过程涉及到手动处理,所产生的事件日志就可以对单个员工得出敏感的结论。
假名限制和匿名化方法【7】在某些应用环境中是不够的,他们不能防止基于频率的攻击【8】。
例如:如果知道只有某个员工可以执行特定的活动,日志中员工信息的假名就不能实现隐私保护。
因此,另一个不同的角度是对数据进行净化,来提供明确的隐私保证。
例子:k-匿名和差分隐私。两者的隐私概念都有一个参数,可以微调给定的保证强度。在隐私与效用之间存在权衡。
问题:如何净化数据,以便在给定的隐私保证下最大限度地利用数据?
分析解决方法:
由攻击模型和过程分析类型定义。攻击模型确定要考虑的隐私保证,过程分析类型确定如何评估净化日志的效用。
攻击涉及:
- 身份披露:无论事件是否与员工相关。
- 成员披露:员工的事件是否包含在日志中。
- 属性披露:是否可以通过事件的属性值来表征雇员。
过程分析:
- 过程发现:根据净化日志中发现的模型与从原始日志中发现的模型相比的变化来评估净化日志的效用。过程发现技术通常直接从图表(DFG)的关系导出,捕获了哪些活动彼此直接继承,以及以什么频率继承。为了最大限度的提高清理后日志的效用,应保证从它构建的DFG类似于原日志的DFG。 因此要努力保留尽可能多的直接遵循关系的条目。
攻击例子:
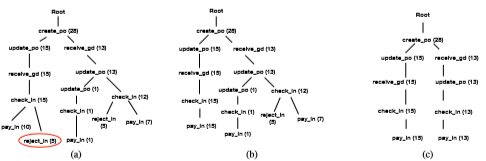
为了激发日志清理的需求,考虑订单处理流程。流程包括:创建采购订单PO,更新PO,接收货物,以及检查、支付和拒绝发票相关的活动。
对于怀有恶意的攻击者,事件的顺序信息可能足以将员工与某些事件的执行联系起来。这尤其适用于攻击者拥有组织知识的情况(比如经理)。例如,经理可能知道,对于已更新的POs,只允许四名员工检查相应的发票。通过这些背景知识与事件日志中的轨迹相结合,对手可获得敏感信息(身份披露/成员披露)。
考虑一个场景,其中一些销售订单在收货后已更新。如果对手知道苏是少数被允许随后检查相应发票的员工之一,那么对手能够高精度的识别苏执行的特定事件。这里存在一个构造成功的最大概率,如果等价类中的事件数量是8,一个员工处理的事件数量最多是4,那正确分配(成功披露)的最大概率是4/8=0.5
隐私保证:k-匿名,确保k-匿名的一个简单方法是从日志中删除出现次数少于k次的轨迹。但是这种方式隐藏了大量关于其他序列变体的存在和频率信息。
PRETSA算法:
基于前缀树的t-closure事件日志清理,k-匿名和t-closeness防止三种攻击。构建事件日志的前缀树表示(日志中观察到的一系列已执行活动的每个前缀定义了一个单独的等价类),用频率和属性值注释,通过重新定位和合并子树逐步转换该树,直到获得所需的隐私保护。事件日志的转换是细粒度的,意味着日志效用的适度损失。

- 检查隐私保证:以深度优先的方式遍历前缀树,直到它到达违反隐私保证的节点。
- 树更新:将违反的节点及其后代先于与祖先分离。
- 找到最相似的剩余迹线:用编辑距离(Leven-shtein)来考虑相似性。
- 重建树:将将修剪下的节点合并到最相似迹线中。
- 终止:迭代的转换前缀树,直到它被完全遍历二没有识别出单个违规。
实验:
- k-匿名会影响过程模型的质量。用适合度(fitness) 和 精确度(precision) 度量。
- t-closeness会影响过程模型注释(事件的执行时间:开始时间和下一个事件的开始时间的差)的准确性。
- 三条基线:
- 丢弃不满足k-匿名的迹线的事件日志。
- 丢弃不满足t-closeness的迹线(活动a的时间分布与活动a时间的总体分布统计上不同)的事件日志。
- 未经清理的事件日志。
实验结果:
- 简单的事件日志(大多数变体相当常见)受到的影响总是很小,三种方法没有太大差异。
- 复杂的事件日志(不太结构化的)可以看出不同方法之间差异很大,PRETSA取得最好的结果,说明了该算法对于不太结构化的过程特别有用。
分析
热图描述了t-接近度对执行时间注释的准确性的影响。给定特定的k和t值,该图指示了经过消毒的logL’中活动的平均执行时间与原始距离有多近原始日志中的平均值。

将原始事件日志与通过对消毒后的事件日志应用归纳挖掘器发现的过程模型进行比较时获得的日志适应度和精度。(是原始日志与模型比较)

首先使用不频繁的归纳挖掘[19]从经过消毒的事件logL’中发现一个过程模型。然后,通过确定其对原始事件logL的适应性[25]和精度[26]来量化该发现模型的质量。
【25】Conformance checking using cost-based fitness analysis
【26】Measuring precision of modeled behavior