Paper: A Survey on Malware Detection Using Data Mining Techniques
Author:
Yanfang Ye, West Virginia University, [email protected]
Tao Li, Florida International University & Nanjing University of Posts and Telecommunications, [email protected]
Donald Asjeoh, West Virginia University, [email protected]
S. Sitharama Iyengar, Florida International University, [email protected]
Press: 2017 ACM Computer Surveys
.
暂未全部整理完成……
目录
摘要
viruses, trojans, ransomware和bots等恶意软件对互联网用户造成了极大的安全威胁。
为了保护合法用户,Comodo,Kaspersky,Kingsoft和Symantec等公司提供了多种针对恶意软件的防御工具。
然而,受到巨大经济利益的驱使,新的恶意软件呈现爆炸式的增长,使得反恶意软件公司每年需要面对百万级别的潜在恶意软件样本。对高效的恶意软件检测技术的研究成为了急需。
1 引言
恶意软件包括viruses, worms, trojans, spyware, bots, rootkits 和 ransomware等,已经被用于信息犯罪,如危害计算机、盗取机密信息、发送垃圾邮件、使服务器罢工、入侵网络和破坏基础设施等。
传统的检测技术主要是基于签名的方法(signature-based method)。签名是一个较短的字节序列,其对于每一种已知的恶意软件来说都是独一无二的,因此可以使新的恶意软件以较低的错误率被正确识别。
然而新的恶意软件使用指令虚拟化、包装、多态、仿真和变形等技术的工具箱生成了大量可绕过基于签名的检测方法的恶意软件。
为了提高恶意软件检测的效率,许多公司使用基于云的检测方法。其将轻量级的基于签名的检测部署在客户端在认证有效的软件和屏蔽无效的软件,而对未知软件的预测则交给云端来处理,并将判断结果返回给客户端。
2 恶意软件和反恶意软件行业的概述
恶意软件以达到攻击者的恶意目标为目的,包括扰乱系统工作、进入计算机系统和网络资源、未经用户的许可就获取私人敏感信息。导致了主机的完整性、网络的可获取性和用户的私密性被侵犯。
恶意软件可以通过多种途径到达系统:(1)网络服务的漏洞使得恶意软件得以自动地感染系统。(2)通过利用浏览器的漏洞,恶意软件能通过被下载到受害者的电脑上并执行来完成攻击。(3)故意诱导受害者执行恶意代码。
2.1 恶意软件的分类
根据不同的目的和复制方式,恶意软件可以被大致分成以下几个类别:
- Viruses: 是一串可以插入到其他系统程序中的代码,当被执行时,被影响到的区域就收到了感染。它不能独立地运行,因为其需要被主机程序激活。
- Worms: 可以独立运行,可以复制自己并感染其他的电脑。
- Trojans: 假装是有用的软件,实际上在后台做坏事。
- Spyware: 在用户不知情下窥视,包括监视用户行为、获取键盘活动和获取敏感数据。
- Ransomware: 近些年较多的一种恶意软件,其按照在受害者的电脑上,并执行密码病毒攻击。受害者需要支付赎金给攻击者来给电脑解锁。
- Scareware: 用于诱导用户购买并下载不必要且有潜在危害的软件,如假的反恶意软件保护,对受害者产生严重的经济和隐私危害。
- Bots: 可以使得攻击者远程控制受感染的系统。典型的传播途径是利用软件的漏洞结合使用社会工程技术。一旦系统被感染,攻击者能下载worms、spyware和trojans并将系统转变为僵尸网络。僵尸网络被广泛用于发动分布式拒绝服务(Distributed Denial of Service, DDoS)攻击,用于发送垃圾邮件、 托管网络钓鱼欺诈。
- Rootkits: 一种隐身的软件,用于隐藏特定的操作或程序并能以特权身份访问计算机。其可以用于各个级别的系统调用:可以在用户模式提交API调用申请,或把操作系统的结构篡改为设备驱动程序或核心组件。
- Hybrid Malware: 包含两种及以上的恶意软件代码,形成一种新的具有更强大的攻击能力的恶意软件。
这些类型定义的恶意软件并不是完全精准且互相绝缘的,也就是说一种恶意软件可能同时属于多个恶意软件类别。
2.2 恶意软件行业的发展
Viruses是第一种恶意软件。为了躲避检测,攻击者研究出了多种隐匿的技术:(1)加密:包括加密算法、密钥、加密代码和解密算法。钥匙和解密算法用来解密恶意软件。用新生成的钥匙和加密算法可以生成大量恶意软件来逃避检测。(2)封装:加密或压缩可执行文件。去封装一般对于获取被封装的恶意软件的整个语义信息非常重要。(3)混淆:混淆用来隐藏程序的底层逻辑并防止他人获取任何和代码相关的信息。典型的混淆技术包括增加垃圾命令、不必要的跳转等。应用混淆技术,可以使得恶意软件代码及其恶意功能在被激活前都无法被获取到。(4)多态:多态指恶意软件每次复制时在保证原始代码完好无损的前提下尽可能地看起来和原来不一样。多态可以使用不限制数量的加密算法,并在每次执行时部分解密代码将改变。在每次改变时,随机生成一个加密算法,用他来加密恶意软件和密钥。(5)变形: 最复杂的一种恶意软件。恶意软件的源码自动地自我修改并与原来的完全不相似。
……
2.3 恶意软件检测的进展
2.3.1 基于签名的恶意软件检测
反恶意软件公司使用基于签名的技术来鉴别已知的威胁软件类型。
签名是一个较短的字节序列,每一个已知的恶意软件都是独一无二的,这使得新的软件能以较小的错误率被识别出来。基于签名的方法从二进制代码中找到独一无二的字符串序列。
当新的恶意软件类型被发现时,反恶意软件公司需要获取新的恶意软件样本,对其进行分析并设计新的签名,并将其部署在客户端中。
签名的基准一般都是被域名专家手工设计,更新和发布。时间和劳动力消耗较大。这使得反恶意软件工具对新的威胁反应不够快速。
2.3.2 基于启发式的恶意软件检测
通过使用加密、封装、混淆、多态、变形等技术可以轻易地绕过基于签名的检测,因此从1990s到2008年间基于启发式的方法是最重要的恶意软件检测技术。
基于启发式的检测是基于专家确定的规则或模式来区分恶意软件样本和良性的文件。这些规则或模式应该具有较好的通用性,使得其能持续地检测出相同类型的恶意软件及其变体的威胁,但是不会错分良性软件。
然而,域名专家对恶意软件样本的分析和对规则或模式的构建经常出错且非常耗时。更重要的是受到经济利益的驱使,攻击者通过自动的恶意软件生成工具不断地快速生成大量恶意软件使得基于签名和基于启发式的恶意软件检测无法跟上恶意软件飞速增加的步伐,因此急需智能的恶意软件检测技术。
2.3.3 基于云的恶意软件检测
基于云端的检测过程如下:
- 客户端的用户以不同的渠道从网络中得到了新的软件。
- 客户端的签名集首先被用于对新的软件进行扫描,如果不能被已有的签名识别则会被标为“未知”。
- 未知软件的信息会被收集起来一同发送到云服务器。
- 云端的分类器会对未知软件样本进行分类,并生成恶意或是良性的判断结果。
- 判断结果会被尽快发送回客户端。
- 基于云端的结果,客户端的会继续进行一次扫描检测。
- 根据快速的响应结合云端的反馈,客户端用户将会得到最新的解决方案。
当前的恶意软件检测大多使用基于云架构的客户端-服务器模式:在客户端屏蔽黑名单中的无效软件或认证白名单中的合法软件,在云端对未知类型的软件进行预测并快速将判断结果传回客户端。灰名单包含了未知软件及可能是良性或恶意的软件,传统的处理方法是拒绝或分析师手工判断。
3 应用数据挖掘技术来检测恶意软件的总体过程
近些年,很多研究聚焦在了基于数据挖掘技术进行恶意软件的检测。此类检测大体分成两步:特征提取 和 分类或聚类。图6显示了总体的过程。
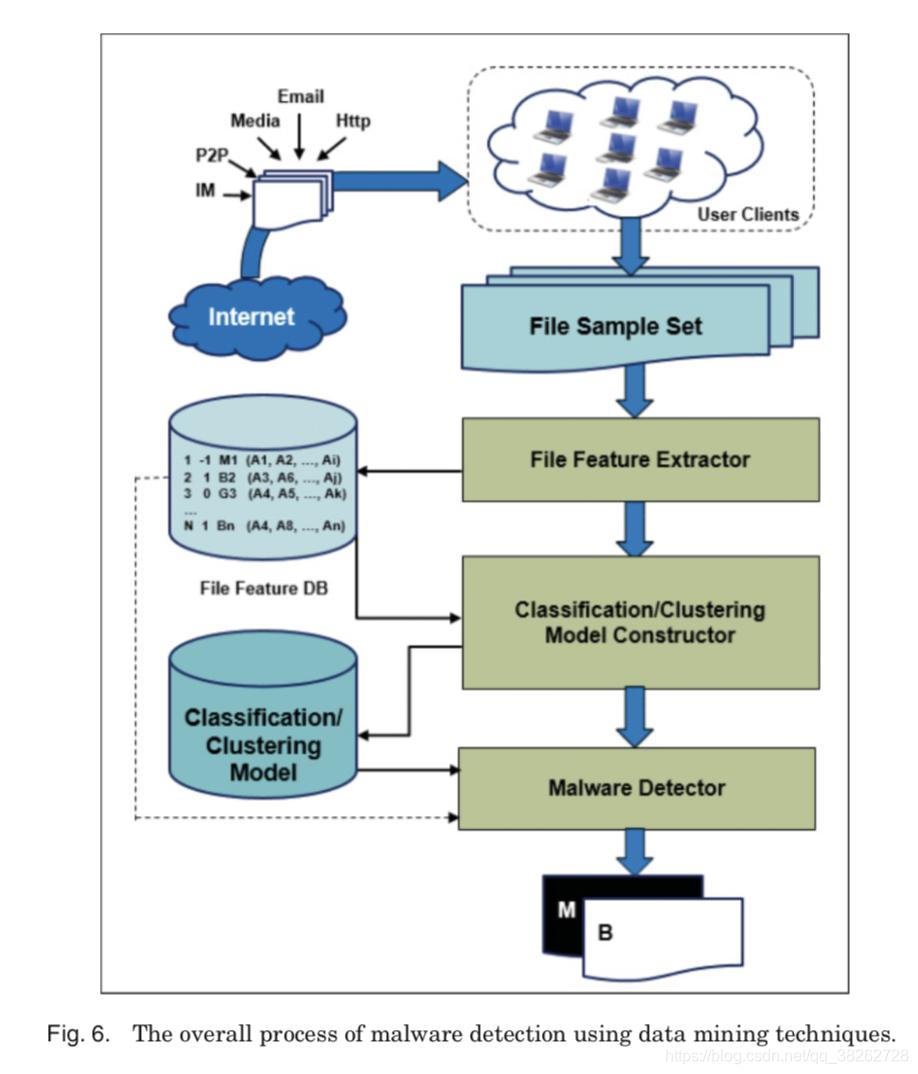 第一步,(静态、动态地)提取软件的各类特征(API调用、二进制字符串、程序的行为)。
第一步,(静态、动态地)提取软件的各类特征(API调用、二进制字符串、程序的行为)。
第二步,智能技术(分类或聚类)基于特征的表达自动地将软件分到不同的类别。
分类
模型的构建:首先,将包括恶意和良性的训练样本提交给系统。然后,将样本解析并提取出能够表征样本底层特性的特征。提取出的特征接着转换成向量成为训练集。每个样本的特征向量和类别标签一同作为输入交给分类算法(如人工神经网络ANN,决策树DT,支持向量机SVM)。通过对训练集的分析,分类算法建立了一个分类模型。
模型的使用:接着,新的未知样本使用同样的方法提取出特征向量并交给分类器进行分类。
聚类
在很多时候,只有很少的训练样本拥有标签。因此研究者提出使用聚类来自动地将恶意样本分组,根据恶意软件表现的相似性将其分入不同的组别。聚类使得自动地对恶意软件进行分类并使得基于签名的方法可用于检测。
在恶意软件检测中,恶意软件样本经常作为positive样本。
4 特征提取
5 特征选择
6 恶意软件检测的分类
7 恶意软件检测的聚类
8 其他问题与挑战
9 恶意软件的发展趋势
10 结论
参考文献
见原文