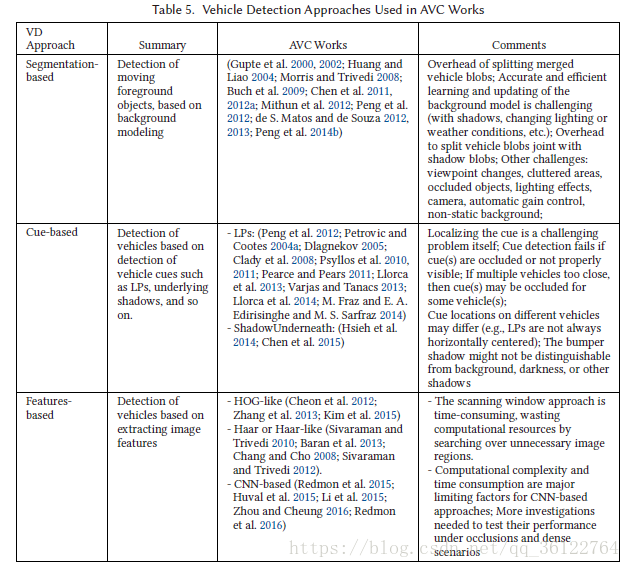
6 VEHICLE DETECTION
The advancements in imaging technology and computing platforms have enabled accurate, efficient, and fast implementations of computer vision-based approaches for vehicle detection. The objective of vision-based vehicle detection is to find a Region of Interest (ROI) over the given image, such that it outlines the vehicle (or its front/rear face) by filtering out the background regions. The AVC modules then work on these ROIs instead of the entire image, which could otherwise decrease accuracy and speed. The problem of vehicle detection in image sequences from surveillance cameras has been well investigated by many researchers. We refer the readers to the extensive surveys of vehicle detection techniques and approaches by Sivaraman and Trivedi (2013) and Mukhtar et al. (2015). For the purpose of comprehensiveness, we provide here a brief review of vehicle detection techniques utilized in AVC works and present open challenges in the area, although the focus of this article is not on vehicle detection. We propose a taxonomy of vehicle ROI detection works based on the underlying approaches: (1) Segmentation-based, (2) Cue-based, and (3) Features-based. Following this taxonomy, in Table 5, we summarize the vehicle detection approaches used in AVC works.
成像技术和计算平台的进步使得基于计算机视觉的车辆检测方法的准确,高效和快速实施成为可能。基于视觉的车辆检测是在给定图像上找到感兴趣区域(ROI),从而通过滤除背景区域来概述车辆(或其前/后脸)。然后,AVC模块将处理这些ROI而不是整个图像,否则会降低准确性和速度。许多研究人员已经很好地研究了来自监视摄像机的图像序列中的车辆检测问题。我们将引用Sivaraman和Trivedi(2013)和Mukhtar等人(2015年)对车辆检测技术和方法的广泛调查。为了全面,我们在这里简要回顾AVC作品中使用的车辆检测技术,并提出该领域的开放挑战,尽管本文的重点不在于车辆检测。我们提出了基于底层方法的车辆ROI检测工作的分类:(1)基于分割,(2)基于提示,和(3)基于特征。按照这种分类方法,在表5中,我们总结了AVC作品中使用的车辆检测方法。
6.1 Segmentation-Based Vehicle Detection
In this class of vehicle detection approaches, themoving objects are detected (as foreground) based on some learned “reference” of the background. Such approaches are popular in surveillance and monitoring systems with a static camera observing a scene. As such, it has been a very popular approach in VTR works. To detect moving objects in the scene, background modeling is usually employed. The detected background data is then used to produce refined foreground masks.
在这类车辆检测方法中,根据背景的一些学习“参考”来检测运动物体(作为前景)。 这种方法在监视和监视系统中很流行,用静态相机观察场景。 因此,它一直是VTR作品中非常流行的方法。 为了检测场景中的运动物体,通常采用背景建模。 检测到的背景数据然后用于产生精致的前景蒙板。
A simple way to model the background is time-averaging background images of the vacant scene (i.e., without any outside objects). However, the vehicular or urban traffic scenarios are characterized by the dynamic nature of scenes; because of this, a fixed background may not always be available, for example, different objects would be coming in, going out, or staying stationary in the scene for some or long time.
背景建模的一种简单方法是对空白场景的背景图像进行时间平均(即没有任何外部物体)。 然而,车辆或城市交通场景的特点是场景的动态性, 因此,固定的背景可能并不总是可用的,例如,不同的对象会进入,出去或在场景中停留一段或很长时间。
To tackle these issues, many background modeling techniques have been proposed, which have used a statistical model to describe the state of each pixel of the background regions. To this end, Stauffer and Grimson (1999, 2000) proposed a Gaussian Mixture Model (GMM) composed of K Gaussian distributions built for every pixel, based on its recent history of values. As time proceeds, pixel values vary due to changes in the scene. The new data was integrated into the model through an online K-means approximation. Whenever a new pixel value was encountered, the K Gaussian distributions were checked against it to find a match. The match occurred when a pixel value fell within 2.5 standard deviations of a distribution. If a match was not found, then the distribution with the least probability was replaced with a new distribution based on the new observation. The mixture model’s parameters were then updated according to certain criteria. The mixture model for a pixel was then ordered in such a way that distributions with a higher probability of representing the background were on top. Out of this ordered list, the top B distributions were taken as the background model. Based on the background models, foreground pixels were identified. A connected components algorithm (Horn 1986) was then used to segment the foreground regions. However, their algorithm was based on the assumption that the background model’s variance was relatively narrow, and that the foreground was less frequently visible than the background.
为了解决这些问题,已经提出了许多背景建模技术,其使用统计模型来描述背景区域的每个像素的状态。为此,Stauffer和Grimson(1999,2000)提出了一种高斯混合模型(Gaussian Mixture Model,GMM),该模型由K个高斯分布组成,基于其近期的历史数据为每个像素建立。随着时间的推移,像素值由于场景的变化而变化。通过在线K-means近似将新数据整合到模型中。无论何时遇到新的像素值,都会检查K个高斯分布以找到匹配。匹配发生在像素值落入分布的2.5个标准差内。如果没有找到匹配,那么基于新的观察结果将具有最小概率的分布替换为新的分布。然后根据一定的标准更新混合模型的参数。然后对像素的混合模型进行排序,使得表示背景的可能性较高的分布处于最佳状态。在这个有序列表中,顶级B分布被当作背景模型。基于背景模型,识别前景像素。然后使用连接组件算法(Horn 1986)来分割前景区域。然而,他们的算法是基于背景模型的方差相对较窄并且前景比背景更不明显的假设。
Instead of having a fixed number of Gaussian distributions in the GMMs, Zivkovic and van der Heijden (2006) proposed a model selection criterion (from a Bayesian perspective) for the online selection of an appropriate number of Gaussian distributions per pixel. This resulted in a model that automatically adapted to the scene. Moreover, they used a recursive computation to constantly update the GMM parameters. On the other hand, Chen et al. (2012b) proposed a self-adaptive GMM; instead of using a fixed learning rate of adaptation, they employed an online dynamic learning rate of adaptation (Chen and Ellis 2011). To deal with unwanted motions associated with camera vibration or swaying trees, they used Multi-Dimensional Gaussian Kernel density Transform (MDGKT) (Chen et al. 2009). The shadow pixels were eliminated from the detected moving object in the image by using brightness- and chromacity-based thresholds. The final foreground mask was used to produce a refined foreground region, with shadow regions removed.
Zivkovic和van der Heijden(2006)提出了一个模型选择标准(从贝叶斯的角度来看),用于在线选择每个像素的适当数量的高斯分布,而不是在GMM中具有固定数量的高斯分布。这导致了一个自动适应现场的模型。此外,他们使用递归计算来不断更新GMM参数。另一方面,陈等人 (2012b)提出了一种自适应GMM;他们没有使用固定的适应性学习率,而是采用了在线动态学习适应率(Chen and Ellis 2011)。为了处理与摄像机振动或摇曳树木相关的不需要的运动,他们使用了多维高斯核密度变换(MDGKT)(Chen et al.2009)。通过使用基于亮度和基于色度的阈值,从图像中检测到的运动对象中消除阴影像素。最后的前景蒙版被用来产生一个精炼的前景区域,去除阴影区域。
The major challenges involved in achieving a robust foreground segmentation system are found in learning and updating or adapting the background model accurately and efficiently, while dealing with shadows, changing lighting or weather conditions, and so on. Other issues to overcome include viewpoint changes, cluttered areas, occluded objects, lighting effects (e.g., shadows, overcast shadows, clouds covering sun), camera automatic gain control, non-static background (e.g., due to camera motion or vibration, swaying trees, snow or rain). In addition, the system must be installable and operable in any scene. Another major problem encountered by segmentation-based vehicle ROI detection approaches is shadow cast underneath the vehicles from different lighting or weather conditions. Most segmentation methods result in vehicle blobs joint with shadow blobs. Therefore, further steps have been incorporated to remove the shadow regions from the foreground.
实现稳健的前景分割系统所涉及的主要挑战在学习和更新或准确有效地调整背景模型,同时处理阴影,改变照明或天气条件等方面。 其他需要克服的问题包括视点变化,混乱区域,遮挡物体,照明效果(例如阴影,阴影,覆盖太阳的云层),相机自动增益控制,非静态背景(例如由于相机运动或振动,摇摆树木 ,下雪或下雨)。 此外,该系统必须可在任何场景下安装和操作。 基于分段的车辆ROI检测方法遇到的另一个主要问题是来自不同照明或天气条件的车辆下方的阴影。 大多数分割方法导致车辆斑点与阴影斑点联合。 因此,已经采取了进一步的步骤来从前景中去除阴影区域。
6.2 Cue-Based Vehicle Detection
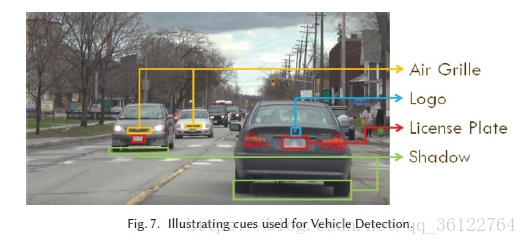
To detect vehicles in a given image, the cue-based vehicle detection approaches first look for cues such as bumper shadow, air grille, license plate, and so on. Based on these cues, candidate vehicle ROIs are constructed. Such approaches can be used in scenarios with static or dynamic cameras, that is, with stationary or mobile cameras, and are hence more applicable to diverse scenarios than Segmentation-based vehicle detection. Cue-based approaches have been popular in AVC works, as they possess faster processing speeds and lower computational complexity than other advanced vehicle detection approaches. Nonetheless, to localize the cue region in the image is itself a challenging problem. In Figure 7, we illustrate these cues in an on-road scenario, taken from an onboard camera. One can observe in this figure that in a real-world scenario such as the one depicted in the figure, detection of cues could be very challenging.
为了检测给定图像中的车辆,基于提示的车辆检测方法首先寻找诸如保险杠影子,气格栅,车牌等的提示。 基于这些线索,构建候选车辆ROI。 这种方法可以用于静态或动态摄像机的场景,也就是说,这种方法相比于基于分割的车辆检测方法适用场景更多。 基于线索的方法在AVC工作中很流行,因为它们比其他先进的车辆检测方法拥有更快的处理速度和更低的计算复杂度。 尽管如此,将图像中的提示区域本地化本身也是一个具有挑战性的问题。 在图7中,我们从道路相机中演示了这些路线情景中的线索。 在这张图中可以看到,在真实世界的场景中,如图中所示的场景,线索的检测可能非常具有挑战性。
Since most AVC systems are designed to complement license-plate-based vehicle classification systems, detected license plates are used as cues to define ROIs around them to enclose the required vehicle parts. Looking for a license-plate in the entire image spacewould be cumbersome and timeconsuming. So, some works such as Peng et al. (2012) first employed a vehicle blob segmentation step prior to license plate localization to reduce the search space. Based on the detected license plate region, an ROI is constructed with width equal to that of a vehicle blob, and height equal to 4× the LP’s height. An advantage in their approach was the use of illumination assessment to eliminate shadow regions from vehicle blobs. However, their work could not handle merged vehicle blobs or occluded vehicles. Other similar approaches of detecting vehicles based on LPs can be found in Petrovic and Cootes (2004a), Dlagnekov (2005), Clady et al. (2008), Psyllos et al. (2010, 2011), Pearce and Pears (2011), Llorca et al. (2013), Varjas and Tanacs (2013), Llorca et al. (2014), andM. Fraz et al. (2014). Many real-time and robust license plate detection techniques, such as Mammeri et al. (2014a), have been proposed in the literature. Although license plate recognition systems are prone to failure, the license plate detection techniques have been proven to be highly robust in different lighting conditions and have the advantages of faster processing speed, lower computational complexity, and minimal failure cases (Al-Ghaili et al. 2013; Tian et al. 2014; Hsu et al. 2013; Sarfraz et al. 2013).
由于大多数AVC系统设计用于补充基于牌照的车辆分类系统,所以检测到的车牌被用作线索来定义围绕它们的ROI以包围所需的车辆部件。在整个图像空间中寻找牌照将会很麻烦并且耗时。所以,一些作品,如彭等人 (2012)首先在车牌定位之前采用了车辆斑点分割步骤以减少搜索空间。基于检测到的车牌区域,构建具有与车辆斑点的宽度相等的宽度的ROI,并且高度等于4×LP的高度。他们的方法的一个优点是使用照明评估来消除车辆斑点的阴影区域。但是,他们的工作无法处理合并的车辆斑点或堵塞的车辆。在Petrovic和Cootes(2004a),Dlagnekov(2005),Clady(2008)、Psyllos等人(2010年,2011年),Pearce和Pears(2011年),Llorca等 (2013年),Varjas和Tanacs(2013年),Llorca等人(2014年)和M. Fraz等人(2014) 的文章中可以找到基于LP(license plate-车牌)检测车辆的其他类似方法。许多实时和强大的牌照检测技术,如Mammeri(2014a)等 已在文献中提出。尽管车牌识别系统容易出现故障,但车牌检测技术已被证明在不同的照明条件下具有高度的鲁棒性,并具有处理速度更快,计算复杂性更低以及故障情况最少等优点(Al-Ghaili et al。 2013; Tian等2014; Hsu等2013; Sarfraz等2013)。
Nonetheless, relying on LPs alone for vehicle ROI detection poses a great deal of limitations. First, in most works, LP detection fails if LPs are occluded or not properly visible, which in turn fails vehicle detection by producing erroneous ROIs. Second, if more than one vehicle appears in an image in such a way that they are too close, the LP of occluded vehicle may not be visible at all. Third, most works assume LPs are horizontally centrally located on the vehicle’s face. Such systems also produce erroneous vehicle ROIs when vehicle LPs are on the sides.
尽管如此,仅依靠LP(license plate-车牌)来进行车辆ROI检测会带来很大的局限性。 首先,在大多数作品中,如果LP被遮挡或不可见,则LP检测失败,这反过来导致错误的ROI检测失败。 其次,如果图像中出现多于一辆的车辆太靠近,则遮挡车辆的LP可能根本不可见。 第三,大多数作品假设LPs水平居中位于车辆的脸部。 当车辆LP位于侧面时,这样的系统也会产生错误的车辆ROI。
Based on the observation that the region underneath the vehicle’s bumper has a shadow, some researchers took a different approach and followed this cue to detect vehicles in images. For example, Hsieh et al. (2014) and Chen et al. (2015) detected the shadow region underneath bumpers through a Gaussian shadow model learned from training images. However, in night-time images, or scenes with on-road shadows from other objects, the bumper shadow might not be separable from background darkness or other shadows.
基于观察车辆保险杠下方的区域存在阴影,一些研究人员采取了不同的方法,并按照该提示检测图像中的车辆。 例如,Hsieh等人 (2014年)和陈等人(2015)通过从训练图像中学习的高斯阴影模型检测保险杠下面的阴影区域。 但是,在夜间图像或具有其他物体的道路阴影的场景中,保险杠阴影可能无法从背景黑暗或其他阴影中分离出来。
6.3 Features-Based Vehicle Detection
The vehicle detection approaches of this category are often composed of two steps: (1) Hypothesis Generation and (2) Hypothesis Verification. In the former step, cue-based methods are usually employed to generate candidate ROIs, narrowing the search space. On the other hand, some works have employed exhaustive searches through sliding scanning windows to generate hypotheses. In the Hypothesis Verification step, features are extracted from each of the candidate ROIs, which are then filtered (to eliminate false positives and false negatives) through classifiers, to produce accurate and best-fit ROIs. For features extraction, Histogram of Oriented Gradients (HOG)-based and Haar-like features have been popular in vehicle detection works, as we review below.
这类车辆检测方法通常由两个步骤组成:(1)假设生成和(2)假设验证。 在前一步中,基于线索的方法通常用于生成候选ROI,缩小搜索空间。 另一方面,一些作品通过滑动扫描窗口进行穷举搜索以产生假设。 在假设验证步骤中,从每个候选ROI中提取特征,然后通过分类器对特征进行过滤(以消除误报和漏报),以产生准确和最适合的ROI。 如下所述,对于特征提取,面向梯度的直方图(Histogram of Oriented Gradients,HOG)和Haar-like特征在车辆检测工作中很受欢迎。
The HOG features are histograms obtained by the discretization and binning of gradient orientations in different blocks of an image. The HOG features have been popularly used in various object detection works, due to their good detection performance (Dalal and Triggs 2005; Chayeb et al. 2014; Iqbal et al. 2015).
HOG特征是通过对图像的不同块中的梯度定向进行离散化和装仓而获得的直方图。 由于其良好的检测性能,HOG特征已广泛用于各种目标检测工作(Dalal和Triggs,2005; Chayeb等,2014; Iqbal等,2015)。
An interesting work based on HOG is of Cheon et al. (2012). For hypothesis generation, they used shadows underneath vehicles as cues to construct candidate ROIs. Then, in hypothesis verification, HOG and HOG-based symmetry features were used to filter out false positives (non-vehicle ROIs). Earlierworks used edges to represent symmetrical characteristics numerically [12,13].However, due to their limitations, Cheon et al. (2012) proposed using HOG vectors to extract symmetry feature vectors. A candidate ROI was divided into four blocks. The histograms from the top-left and bottom-left parts were rearranged (bins interchanging), respectively, according to a predefined pattern. Then, two symmetry features were extracted, using bin-wise similarity between (1) top-right and re-arranged top-left histograms and (2) the bottom-right and rearranged bottom-left histograms. The HOG and HOG-Symmetry features were then classified through TER-RM classifier (Toh et al. 2004; Toh and Eng 2008) with data importance.
Cheon等人 (2012年)基于HOG进行了一项有趣的工作。对于假设生成,他们使用车辆下方的阴影作为线索来构建候选ROI。然后,在假设验证中,使用基于HOG和HOG的对称特征来过滤误报(非车辆ROI)。早期的工作使用边缘来表示对称特征的数值[12,13]。然而,由于它们的局限性,Cheon等人(2012)提出使用HOG向量来提取对称特征向量。候选ROI分为四个区块。根据预定义的模式,分别重新排列来自左上角和左下角部分的直方图(箱互换)。然后,使用(1)右上和重新排列的左上直方图与(2)右下和重排左下直方图之间的二进制相似性提取两个对称特征。 HOG和HOG对称性特征然后通过TER-RM分类器(Toh等2004; Toh和Eng 2008)进行分类,具有数据重要性。
Despite the encouraging performance in terms of detection accuracy, HOG-based techniques are slow, mostly due to the use of the multi-scale scanning window-based search. The scanning window approach is time-consuming, wasting computational resources by searching over unnecessary image regions. Moreover, in building conventional HOG histograms based on edges or gradients, intensity information is ignored and position information is lost, as illustrated in Kim et al. (2015).
尽管在检测精度方面表现令人鼓舞,但基于HOG的技术很慢,主要是由于使用基于多尺度扫描窗口的搜索。 扫描窗口方法非常耗时,通过搜索不必要的图像区域来浪费计算资源。 此外,在构建基于边缘或梯度的传统HOG直方图时,强度信息被忽略并且位置信息丢失,如Kim等人的文章(2015年)。
To overcome these limitations, Kim et al. (2015) proposed an enhanced HOG-based feature called the PIHOG, which incorporates position and intensity information. They also proposed a search space reduction method to reduce computational load and enhance detection speed. The PIHOG feature vector is made up of the conventional HOG feature, position parts, and intensity parts. The position parts in a PIHOG feature are the means of x and y positions of each bin in a block (or cell) of an image. For intensity information, they first compute mean and standard deviation images from positive training images of all vehicles to find an Intensity Invariant Region (IIR) mask. They assume that pixels or regions with similar intensity values across all vehicle training images would correspond to low standard deviation values in the standard deviation image, and that intensity values in these regions (i.e., the Intensity Invariant Regions (IIRs)) could be considered unique to vehicle objects. The IIRs are split into M different IIR-masks based on dividing the values of standard deviation image intoM intervals. The intensity parts of PIHOG of an image are composed of normalized histograms of the image’s intensity values in first-n of the previously learnt IIRmasks.
为了克服这些限制,Kim等人(2015)提出了一种增强的基于HOG的特征,称为PIHOG,它包含位置和强度信息。他们还提出了一种减少搜索空间的方法,以减少计算量并提高检测速度。 PIHOG特征向量由传统的HOG特征,位置部分和强度部分组成。 PIHOG特征中的位置部分是图像块(或单元)中每个bin的x和y位置的均值。对于强度信息,他们首先从所有车辆的正面训练图像计算平均值和标准差图像,以找到强度不变区域(IIR)掩模。他们假定在所有车辆训练图像中具有相似强度值的像素或区域将对应于标准偏差图像中的低标准偏差值,并且这些区域(即,强度不变区(IIR))中的强度值可以被认为是独特的到车辆物体。基于将标准差图像的值划分为M个区间,将IIR分成M个不同的IIR掩模。图像的PIHOG的强度部分由先前学习的IIR掩模中的前n个图像的强度值的归一化直方图组成。
On the other hand, some works, such as Chang and Cho (2010) and Felzenszwalb et al. (2010), have only one step that performs an exhaustive search through sliding windows over the entire image. Another work is of Zhang et al. (2013), who extract HOG features from multi-scale scanning windows, which are then classified by cascaded SVMs. The final ROI was constructed based on the largest positive detection windowor merging of smaller, intersecting windows. A major bottleneck in their approach is the added overhead of selecting the appropriate bounding box over many positive detection windows.
另一方面,一些作品,如Chang和Cho(2010)和Felzenszwalb等人 (2010)的作品,只有一个步骤可以通过整个图像上的滑动窗口进行彻底搜索。 另一项工作是张等人 (2013)通过从多尺度扫描窗口中提取HOG特征,然后通过级联SVM对其进行分类。 最终的ROI是基于最大的正检测窗口或合并较小的交叉窗口而构建的。他们的方法中的一个主要瓶颈是在许多阳性检测窗口上选择适当的边界框需要额外开销。
The Haar features were initially introduced by Viola and Jones (2001) for object detection. Early works that employed Haar features failed to achieve high vehicle detection accuracy. Several enhanced versions of Haar features, referred to as Haar-like features, have shown encouraging results in vehicle detection (Sivaraman and Trivedi 2010; Baran et al. 2013). In addition, Haar-like features have been employed to detect vehicle parts (Chang and Cho 2008; Sivaraman and Trivedi 2012). From an image patch, sums and differences of pixel intensities in adjacent rectangles are computed to build the features. The Haar-like features use an integral image to extract rectangular features, making the technique fast and efficient.
Haar特征最初由Viola和Jones(2001)介绍用于物体检测。 采用Haar特征的早期作品未能实现较高的车辆检测精度。 Haar特征的几个增强版本被称为Haar-like特征,在车辆检测中显示出令人鼓舞的结果(Sivaraman和Trivedi 2010; Baran等2013)。 此外,Haar-like特征已被用于检测车辆部件(Chang和Cho 2008; Sivaraman和Trivedi 2012)。 从图像块中,计算相邻矩形中像素强度的总和和差异以构建特征。 Haar-like特征使用整体图像来提取矩形特征,使得该技术快速高效。
Recently, researchers have proposed CNN-based approaches for localizing vehicles in an image. For example, in Krause et al. (2015), detection of vehicles and their parts is based on the R-CNN (“Regions with CNN features”) approach of Girshick et al. (2014). In addition, a co-segmentation scheme is applied to segment the foreground vehicle. “Co-segmentation” refers to the segmentation of the object that is found in all images of a given set (Chai et al. 2011, 2012, 2013; Guillaumin et al. 2014). Similarly, Zhou and Cheung (2016) employ a fine-tuned YOLO network (Redmon et al. 2015, 2016), a CNN-based network structure, for vehicle detection. Some other works in this direction include (Huval et al. 2015; Li et al. 2015).
最近,研究人员提出了基于CNN的方法来定位图像中的车辆。 例如,Krause等人 (2015年)基于Girshick等人(2014)的R-CNN(“具有CNN特征的地区”)方法进行车辆及其零部件的检测。 另外,应用协同分割方案来分割前景车辆。 “共分割”是指在给定集合的所有图像中发现的对象的分割(Chai等2011,2012,2013; Guillaumin等,2014)。 同样,Zhou和Cheung(2016)采用了一个精细调整的YOLO网络(Redmon et al。2015,2016),这是一个基于CNN的网络结构,用于车辆检测。 这方面的其他一些工作包括(Huval等,2015; Li等,2015)。
后记:
第7节中提供了准确性和速度相关的性能指标,并讨论了他们可以用来比较和评估不同的AVC作品。在第8节中,我们提出了一个全面的AVC数据集的要求,审查和分析了针对AVC提出的各种数据集,并强调了尚待解决的数据集问题。在第9节中,我们将讨论AVC领域的公开挑战,并展示我们提升最新技术的愿景。
这些东西都不是我主要关注的 故没有翻译。
附上该文章的参考文献:













