Title:Feature Enhancement Based on CycleGAN for Nighttime Vehicle Detection
基于Cyclegan的特征增强用于夜间车辆检测
ABSTRACT:
Existing night vehicle detection methods mainly detect vehicles by detecting headlights or taillights. However, these features are adversely affected by the complex road lighting environment. In this paper, a cascade detection network framework FteGanOd is proposed with a feature translate-enhancement (FTE) module and the object detection (OD) module. First, the FTE module is built based on CycleGAN and multi-scale feature fusion is proposed to enhance the detection of vehicle features at night. The features of night and day are combined by fusing different convolutional layers to produce enhanced feature (EF) maps. Second, the OD module, based on the existing object detection network, is improved by cascading with the FTE module to detect vehicles on the EF maps. The proposed FteGanOd method recognizes vehicles at night with greater accuracy by improving the contrast between vehicles and the background and by suppressing interference from ambient light. The proposed FteGanOd is validated on the Berkeley Deep Drive (BDD) dataset and our private dataset. The experimental results show that our proposed method can effectively enhance vehicle features and improve the accuracy of vehicle detection at night.
摘要:
现有的夜间车辆检测方法主要通过检测前大灯或尾灯来检测车辆。然而,这些特征受到复杂道路照明环境的不利影响。本文提出了一种级联检测网络框架Fte Gan Od,包含特征平移增强( FTE )模块和目标检测( OD )模块。首先,基于CycleGAN搭建FTE模块并提出多尺度特征融合增强夜间车辆特征检测。通过融合不同的卷积层将夜间和白天的特征进行组合,生成增强特征( EF )图。其次,在现有目标检测网络的基础上,对OD模块进行改进,通过与FTE模块级联来检测EF地图上的车辆。本文提出的Fte Gan Od方法通过提高车辆与背景的对比度,抑制环境光的干扰,提高了夜间车辆的识别精度。本文提出的Fte Gan Od在Berkeley Deep Drive ( BDD )数据集和我们的私有数据集上进行了验证。实验结果表明,本文提出的方法能够有效增强车辆特征,提高夜间车辆检测的准确率。
I. INTRODUCTION
Vehicle detection is an important application in the field of target detection. More accurate vehicle detection systems for day and night conditions will facilitate the development of more reliable Automatic Driving System (ADS) and Driver Assistance System (DAS) in the future. In night (lowlight) condition, the probability of traffic accidents is increased [1] because less visual information about vehicles and the complex lighting environment is available. (a) Less visual information about vehicles. The contrast between the vehicle and the background is reduced at night, making vehicle features less obvious. (b) Complex lighting environment. Interference from various other lights is confused with vehicle headlights and taillights, which leads to a high rate of false vehicle detection and presents significant challenges for vision-based vehicle detection at night.
一、引言
车辆检测是目标检测领域的一个重要应用。更精确的昼夜工况车辆检测系统将有利于未来开发更可靠的自动驾驶系统( Automatic Driver System,ADS )和辅助驾驶系统( Driver Assistance System,DAS )。在夜间(低照度)条件下,由于车辆的视觉信息较少,且光照环境复杂,增加了交通事故发生的概率[ 1 ]。( a )车辆的视觉信息较少。夜间车辆与背景的对比度降低,使得车辆特征不明显。( b )复杂的照明环境。各种其他灯光的干扰与车辆前照灯和尾灯混淆,导致车辆误检率较高,对基于视觉的夜间车辆检测提出了重大挑战。
Most existing vehicle detection methods use the headlights and taillights as the primary nighttime vehicle detection features. Traditional detection methods that are not based on convolutional neural networks (CNNs) used the headlights and taillight to locate vehicles [4]–[11]. Taillights were localized by segmenting the image, and vehicle bounding boxes were predicted by assuming the typical width of the vehicle [4], [5]. Region proposals were firstly obtained by paired taillights of vehicles, next the vehicles whether in these region proposals were determined [6], [7].In [10], a detection-by-tracking method was proposed to detect multiple vehicles by tracking headlights/taillights. These traditional non-CNN vehicle detection methods have two disadvantages. (1) Vehicle detection is susceptible errors due to the complex lighting conditions in urban areas, including vehicle lights, streetlights, building lights, and the reflected lights from vehicles, which increases the false positive rate. (2) Vehicle lights are sometimes obscured when the vehicle is occluded or only the side of the vehicle is photographed, which increases the missed detection rate.
现有的车辆检测方法大多采用前大灯和尾灯作为夜间车辆检测的主要特征。传统的非基于卷积神经网络( CNNs )的检测方法利用前大灯和尾灯来定位车辆[ 4 ] - [ 11 ]。通过分割图像定位尾灯,并假设车辆的典型宽度预测车辆边界框[ 4 ] [ 5 ]。区域建议首先通过车辆的配对尾灯获得,然后确定车辆是否在这些区域建议中[ 6 ],[ 7 ]。文献[ 10 ]提出了一种跟踪检测方法,通过跟踪前照灯/尾灯来检测多个车辆。这些传统的非CNN车辆检测方法存在两个缺点。( 1 )由于城市区域光照条件复杂,包括车灯、路灯、建筑灯、车辆反射光等,车辆检测容易出现错误,增加了误检率。( 2 )当车辆被遮挡或仅拍摄车辆侧面时,车灯有时会被遮挡,增加了漏检率。
Vehicle detection methods based on CNN have gradually become the research focus in recent years and some CNN-based nighttime vehicle detection methods have been investigated. Lin et al. [23] proposed AugGAN to translate daylight images into night images for data augmentation, and the images were then used to train existing detection systems, improving the performance of the detector. However, only augments data processing systems in existing night vehicle detection methods. Kuang et al. [1] used a bioinspired enhancement approach to enhance night images for feature fusion and object classification in 2017. In 2019, they combined traditional features and CNN features to generate regions of interest (ROI) [2], [3]. The above methods, combining traditional machine learning methods and deep learning methods for object detecting, belong to multistage learning frameworks. However, they are not an endto-end learning framework which makes the training process cumbersome.
基于CNN的车辆检测方法近年来逐渐成为研究热点,一些基于CNN的夜间车辆检测方法得到了研究。Lin等人[ 23 ]提出了AugGAN将白天图像转化为夜间图像进行数据增强,然后将图像用于训练现有的检测系统,提高了检测器的性能。然而,现有的夜间车辆检测方法仅增加了数据处理系统。2017年,Kuang等[ 1 ]使用一种生物启发增强方法增强夜间图像,用于特征融合和物体分类。2019年,他们结合传统特征和CNN特征生成感兴趣区域[ 2 ],[ 3 ]。上述方法结合了传统机器学习方法和深度学习方法进行目标检测,属于多阶段学习框架。然而,它们并不是一个端到端的学习框架,使得训练过程繁琐。
Some object detection methods based on deep learning (Fast RCNN [29], SSD [33], etc.) can also be used for night vehicle detection. However, these methods are designed for daytime object detection and their use in nighttime conditions results in a low level of feature extraction accuracy from the network structure and a low rate of vehicle detection performance.
一些基于深度学习( Fast RCNN 、SSD 等。)的目标检测方法也可以用于夜间车辆检测。然而,这些方法都是针对白天目标检测而设计的,在夜间条件下使用,导致网络结构的特征提取精度较低,车辆检测性能较差。
In a word, low-light environment, complex lighting, and the specialized structure of nighttime detection network are three challenges in nighttime vehicle detection. A low-light environment increases the rate of missed vehicles because of the faint features of the vehicles; complex lighting leads to a higher false detection rate when dealing with more complex traffic scenes; and the specialized nighttime detection network is still incomplete. However, generative adversarial network (GAN) is a style transfer network that can translate nighttime images into daytime images. GAN uses encode modules to extract features from nighttime images and uses decode modules to restore the daytime images.
总之,低光照环境、复杂光照以及夜间检测网络的专业化结构是夜间车辆检测面临的三大挑战。低光照环境由于车辆特征微弱,增加了车辆的漏检率;复杂的光照导致在处理更复杂的交通场景时误检率较高;而且专门的夜间探测网络还不完善。然而,生成对抗网络( GAN )是一种可以将夜间图像转化为白天图像的风格迁移网络。GAN使用编码模块从夜间图像中提取特征,使用解码模块恢复白天图像。
Therefore, we propose a novel nighttime vehicle detection framework named FteGanOd (feature translate-enhancement generative adversarial network for object detection) to overcome the above challenges. FteGanOd includes a feature translate-enhancement (FTE) module and an object detection (OD) module, as shown in Fig. 1. (1) FTE firstly uses CycleGAN to translate images from night to day. The multiscale features from CycleGAN are next used to fuse the encoded (nighttime) features and decoded (daytime) features to form the enhanced feature (EF) maps. Encoded features contain important information of night vehicle headlights and taillights; decoded features contain daytime features for enhancing the background brightness while suppressing most of the light sources. (2) The OD module (improved YOLO, RCNN or SSD) extracts abstract vehicle features and detects vehicles on the EF maps.
因此,本文提出了一种新颖的夜间车辆检测框架FteGanOd (用于目标检测的特征平移增强生成对抗网络)来克服上述挑战。Fte Gan Od包括特征平移增强( FTE )模块和目标检测( OD )模块,如图1所示。( 1 ) FTE首先使用CycleGAN进行夜间到白天的图像转换。然后利用CycleGAN的多尺度特征融合编码(夜间)特征和解码(白天)特征,形成增强特征( EF )图。编码后的特征包含了夜间车辆前大灯和尾灯的重要信息;解码特征包含白天特征,用于增强背景亮度,同时抑制大部分光源。( 2 ) OD模块(改进的YOLO、RCNN或SSD)在EF图上提取抽象的车辆特征并检测车辆。
The remainder of this paper is given as follows: In Section II, the methods of vehicle detection at night, detection networks based on CNN and GAN are introduced. Section III describes our night detection network FteGanOd in detail. Section IV introduces the experimental processes and discusses the experimental results. Finally, conclusions and possibilities for future work are presented in Section V.
本文余下内容安排如下:第二部分介绍夜间车辆检测方法、基于CNN和GAN的检测网络。第三节详细介绍了我们的夜间探测网络Fte Gan Od。第四部分介绍了实验过程并讨论了实验结果。最后,在第五部分给出了结论和未来工作的可能性。
II. RELATED WORK
A. NIGHTTIME VEHICLE DETECTION
The headlights/taillights are used as key information in locating vehicles for almost all nighttime vehicle detection algorithms. Searching for red or highlight lights in night images is the main technique to obtain region proposals in previous methods, which has been proven effective in most literature.
Ⅱ.相关工作
A .夜间车辆检测
几乎所有的夜间车辆检测算法都将车灯/尾灯作为车辆定位的关键信息。在夜间图像中寻找红色或高亮灯光是以往方法中获取候选区域的主要技术,这在大多数文献中被证明是有效的。
For obtaining ROIs of vehicles, the following techniques can be adopted: threshold-based segmentation methods [5], [12], [18], paired vehicle lighting-based methods [6]–[8], [14]–[16], saliency map-based methods [17], [27], and artificially designed feature-based methods [13]. After the ROIs are obtained, we need to further determine whether these candidate regions contain vehicles. X. Dai [18] used Hough transform to detect the circles of the headlights and further segment the areas to locate vehicles. Pradeep et al. [14] used red thresholding to obtain ROIs and searched for paired taillights based on the shape similarity and region size to detect vehicles. Chen et al. [27] generated ROIs based on the saliency method and applied the deformable parts model (DPM) to detect vehicles. Kosaka et al. [13] used SVM to classify vehicles after using Laplacian of Gaussian operation to detect the blobs.
对于车辆ROI的获取,可以采用以下技术:基于阈值的分割方法[ 5 ]、[ 12 ]、[ 18 ],基于配对车辆灯光的方法[ 6 ] - [ 8 ]、[ 14 ] - [ 16 ],基于显著图的方法[ 17 ]、[ 27 ],以及人工设计的基于特征的方法[ 13 ]。在得到ROI之后,我们需要进一步确定这些候选区域是否包含车辆。X. Dai [ 18 ]使用Hough变换检测前照灯的圆并进一步分割区域来定位车辆。Pra depth等[ 14 ]使用红色阈值法获得ROI,并根据形状相似性和区域大小搜索配对的尾灯来检测车辆。Chen等[ 27 ]基于显著性方法生成ROI,并应用可变形部件模型( DPM )检测车辆。Kosaka等[ 13 ]在使用高斯拉普拉斯算子检测团块后,使用SVM对车辆进行分类。
In recent years, CNN-based methods are increasingly developed in the research field of vehicle detection at night. [20]–[23] used GAN-based data augmentation methods to expand the training dataset for improving the performance of the detector. Cai et al. [19] combined visual saliency and prior information to generate ROIs and used CNN as a classifier. Kuang et al. [1] proposed a bioinspired method to enhance image contrast and brightness, and further extracted the fusion features of LBP, HOG and CNN. They also [3] proposed a feature extraction method based on tensor decomposition and feature ranking. In [2], Nakagami-image-based method and CNN feature were combined to generate ROIs. References [1]–[3] extracted different features to generate region proposals by combining traditional methods with CNN methods. Mo et al. [24] managed to solve the problem of confusion between other lights and vehicle lights by training a CNN-based highlight detector.
近年来,基于CNN的方法在夜间车辆检测的研究领域日益发展。[ 20 ] - [ 23 ]使用基于GAN的数据增强方法扩展训练数据集以提高检测器的性能。Cai等[ 19 ]结合视觉显著性和先验信息生成ROI并使用CNN作为分类器。Kuang等[ 1 ]提出了一种生物启发的方法来增强图像对比度和亮度,并进一步提取LBP、HOG和CNN的融合特征。他们还[ 3 ]提出了一种基于张量分解和特征排序的特征提取方法。文献[ 2 ]将基于中上图像的方法与CNN特征相结合生成ROI。文献[ 1 ] - [ 3 ]通过将传统方法与CNN方法相结合,提取不同特征生成候选区域。Mo等[ 24 ]通过训练一个基于CNN的高光检测器,解决了其他灯光与车辆灯光混淆的问题。
Existing nighttime vehicle detection methods with visual images mainly use vehicle lights for detection. Especially, the CNN-based methods have stronger adaptability and robustness than non-CNN methods.
现有的基于视觉图像的夜间车辆检测方法主要利用车灯进行检测。特别地,基于CNN的方法比非CNN方法具有更强的适应性和鲁棒性。
B. OBJECT DETECTION BASED ON DEEP LEARNING
The object detection methods based on deep learning can be grouped into two detection methods: two-stage detection and one-stage detection.
二、基于深度学习的目标检测
基于深度学习的目标检测方法可以分为两阶段检测和一阶段检测两种。
1) TWO-STAGE DETECTION RCNN is the first two-stage object detection network [28]. First, a selective search algorithm generates a series of region proposals; next, the proposals are input into CNN to extract features; finally, SVM is used to predict whether each region proposal contains an object. A series of improved networks based on RCNN were proposed, such as Fast RCNN [29], Faster RCNN [30], SPP-Net [31], etc. These networks use different methods to remove redundant parts in the detection network to improve detection speed and accuracy.
1 )两阶段检测RCNN是第一个两阶段目标检测网络[ 28 ]。首先,选择性搜索算法生成一系列区域提议;接下来,将提案输入CNN提取特征;最后,利用SVM预测每个区域提案是否包含对象。提出了一系列基于RCNN的改进网络,如Fast RCNN [ 29 ]、更快速的区域卷积神经网络[ 30 ]、SPP - Net [ 31 ]等。这些网络使用不同的方法去除检测网络中的冗余部分,以提高检测速度和精度。
2) ONE-STAGE DETECTION One-stage detectors, represented by SSD [33] and YOLO [34]–[36], have broken through the detection speed bottleneck of two-stage detectors. However, detection accuracy is reduced compared with two-stage methods, especially for small objects. YOLOv3 and SSD use multi-scale detection to improve small target detection performance. These detection networks have better performance in the ideal (day) environment. However, the accuracy is lower when applied to night vehicle detection. We propose adding the FTE module before the CNN-based detection framework to detect vehicles by combining features of night and day.
2 )单阶段检测
以SSD [ 33 ]和YOLO [ 34 ] ~ [ 36 ]为代表的单阶段检测器突破了两级检测器的检测速度瓶颈。然而,与两阶段方法相比,检测精度有所降低,尤其是对于小目标。YOLOv3和SSD使用多尺度检测来提高小目标检测性能。这些检测网络在理想(白天)环境下具有更好的性能。但应用于夜间车辆检测时,准确率较低。我们提出在基于CNN的检测框架之前加入FTE模块,通过结合夜间和白天的特征来检测车辆。
C. GAN: GENERATIVE ADVERSARIAL NETWORKS GAN, with a generator and a discriminator, has achieved sound results in some applications such as superresolution [37] and de-raining [38]. Most of these applications involve with image generation by GAN to augment training data, which can be used to generate a ‘‘false’’ image similar to real image samples.
C. GAN:GENERATIVE ADVERSARIAL NETWORKS
GAN,具有生成器和判别器,在超分辨率[ 37 ]、去雨[ 38 ]等应用中取得了不错的效果。这些应用大多涉及通过GAN生成图像来增加训练数据,从而生成与真实图像样本相似的"假"图像。
GAN-based image-to-image translation refers to the task of converting images from one scene to another different scene. Pix2pix [39], [40] uses paired images as supervision to achieve image-to-image translation. However, it is difficult to obtain pairs of both day and night image samples in fixed places because the vehicle move too much to capture traffic images. To solve the problem of inputting day and night paired images, CycleGAN [26] is firstly proposed with cycle consistency loss to realize image translation with unpaired images. Image translation realizes the conversion of the object features in an image. For example, after the image is translated from night to day, the background brightness of the image becomes brighter and the vehicles are easier to be recognized.
基于GAN的图像到图像转换是指将图像从一个场景转换到另一个不同场景的任务。Pix2pix [ 39 ],[ 40 ]使用成对图像作为监督,实现图像到图像的转换。然而,由于车辆移动太多,无法拍摄交通图像,因此很难在固定地点获得白天和夜间图像样本对。针对输入昼夜配对图像的问题,CycleGAN [ 26 ]首先提出了具有循环一致性损失的CycleGAN,实现了与未配对图像的图像平移。图像翻译实现了图像中物体特征的转换。例如,将图像从夜间平移到白天后,图像的背景亮度变亮,车辆更容易被识别。
CycleGAN only needs images of different domains during training rather than expensive ground-truth paired image data, which is of great significance for practical applications. Therefore, we will use the structure of CycleGAN for feature translation at night.
CycleGAN在训练时只需要不同域的图像,而不需要昂贵的真假图像配对数据,这对于实际应用具有重要意义。因此,我们将在夜间使用CycleGAN的结构进行特征翻译。
III. PROPOSED METHOD
In this section, we elaborate on the proposed method for vehicle detection at night. To resolve the effect of weak environmental light or complex vehicle’s light at night, we propose a feature cascade network structure FteGanOd to enhance vehicle features and improve vehicle detection accuracy. FteGanOd consists of two modules: feature translateenhancement (FTE) module and object detection (OD) module. The FTE module adopts CycleGAN as the basic network to realize the translation of scenes from night to day by learning on unpaired input data. The OD module cascades with the FTE module to extract fused and enhanced daytime features and detect vehicles with higher detection accuracy.
三.建议的方法
在本节中,我们详细阐述了所提出的夜间车辆检测方法。为了解决夜间弱环境光或复杂车辆光照的影响,本文提出一种特征级联网络结构Fte Gan Od来增强车辆特征,提高车辆检测精度。Fte Gan Od包括两个模块:特征平移增强( FTE )模块和目标检测( OD )模块。FTE模块采用CycleGAN作为基础网络,通过对未配对的输入数据进行学习,实现场景从夜间到白天的平移。OD模块与FTE模块级联,提取融合增强的日间特征,以更高的检测精度检测车辆。
A. PROPOSED FTEGANOD NETWORK
The ability to train with unpaired images as input is a typical advantage of CycleGAN for adapting different traffic scenes. The disadvantage of CycleGAN is that it cannot learn the category and position of the vehicle object when mapping the nighttime image to daytime image. Therefore, we conducted an in-depth study on this and realize the translation of local vehicle features and global scene features from night to day. We propose an FTE module based on CycleGAN and the feature cascaded OD module to overcome the disadvantage of CycleGAN and improve the detection accuracy. Unlike other training methods, here we train the FTE and OD modules together to guide FTE optimization in a direction that makes the vehicle features more prominent.
A.提出的FTEGANOD网络
以未配对图像作为输入进行训练的能力是CycleGAN适应不同交通场景的典型优势。CycleGAN的缺点是在将夜间图像映射到白天图像时,无法学习车辆对象的类别和位置。因此,我们对此进行了深入研究,实现了夜间到白天的局部车辆特征和全局场景特征的翻译。我们提出了一种基于CycleGAN的FTE模块和特征级联OD模块来克服CycleGAN的缺点,提高检测精度。与其他训练方式不同的是,这里我们将FTE和OD模块一起训练,引导FTE优化朝着使车辆特征更加突出的方向进行。
Fig. 2 shows the feature cascade structure of the proposed FteGanOd network, which is composed of four parts (A), (B), (C) and (D). (A) + (B) is the FTE module, where (A) is the generator based on CycleGAN that translate the image from night to day, (B) is the enhancement part that fuses the night and day multi-scale features map from (A) to enhance the vehicle features and finally generate the enhanced feature EF map as input for Part (C). Part (C) is the OD module based on the existing detector structure (such as YOLOv3, etc.). Part (D) is for generating daytime images x_fake in training process.
图2所示为所提Fte Gan Od网络的特征级联结构,由( A )、( B )、( C )、( D )四部分组成。( A ) + ( B )为FTE模块,其中( A )为基于CycleGAN的生成器,将图像从夜间平移到白天,( B )为增强部分,将( A )中的夜间和白天多尺度特征图进行融合,增强车辆特征,最后生成增强特征EF图作为( C )部分的输入。( C )部分是基于现有探测器结构(如YOLOv3等。)的OD模块。( D )部分是在训练过程中生成白天图像x _ false。
B. FTE MODULE
1) IMAGE TRANSLATION
The proposed FTE module is based on the CycleGAN network as shown in Fig. 2. Suppose the feature map fi at layer i with dimension hi × wi × ci, i ∈ N. Let Ei be a generic function which acts as the basic generator block, which in our implementation consists of a convolution layer followed by an instance normalization and an activation function. Ei encode is the operation of encoding the input image as multi-scale feature maps.
2 . FTE模块
1 )图像传输
本文提出的FTE模块基于Cycle GAN网络,如图2所示。假设第i层的特征图fi的维数为hi × wi × ci,i∈N。设Ei是一个泛型函数,作为基本的生成器块,在我们的实现中,它由一个卷积层、一个实例归一化和一个激活函数组成。Ei编码是将输入图像编码为多尺度特征图的操作。
where f0 is the input night image of the network with a size of N × N , let N = 416. The dimension of the feature map Rw×h×c contains [h × w × c] dimensional activations, c is the number of channels in the intermediate activations of the generator, c = 2b+1+i, here we let b = 4. Ei decode is the operation of decoding the translated daytime features to the final output restored image.
其中f0是网络的输入夜间图像,大小为N × N,令N = 416。特征图Rw × h × c的维度包含[ h × w × c]维激活,c为生成器中间激活的通道数,c = 2b + 1 + i,这里令b = 4。Ei解码是将平移后的白天特征解码为最终输出的复原图像的操作。
The final output fake daytime image x_fake is f8.
最终输出的假日图像x _ false为f8。
After the proposed FteGanOd network was trained, the encoded and decoded feature maps were obtained and some of them are shown in Fig. 3. The input nighttime image x is gradually encoded by several convolution layers to form the feature map f1 to f3. The vehicle features and contours in the feature map f1 of the first convolution layer are not obvious due to the low-light background at night, as marked in the red boxes. Compared with f1, the noise of feature map f2 has been aggravated, but we can still see the basic shapes of the vehicles through the position of the road. After further encoding f2 to form the high-level semantic feature map f3, which represents the feature vector of the vehicles and the background in the night domain, we can still see the faint features of the vehicle in the little differences from image contrast. Subsequently, a converter composed of 9 Resnet blocks maps the night domain feature vector f3 into the day domain feature vector f5 through f4. Resnet blocks complete the mapping of nighttime features to daytime features by keeping the similar features in both domains and by converting different features.
对提出的Fte Gan Od网络进行训练后,得到编码和解码后的特征图,部分特征图如图3所示。输入的夜间图像x通过多个卷积层逐步编码形成特征图f1到f3。第一个卷积层的特征图f1中的车辆特征和轮廓由于夜间低光背景不明显,如红色方框中标注。与f1相比,特征图f2的噪声有所加剧,但是我们仍然可以通过道路的位置看到车辆的基本形状。进一步对f2进行 编码,形成高层语义特征图f3,表示车辆和背景在夜间域的特征向量,在与图像对比度相差不大的情况下,仍然可以看到车辆微弱的 特征。随后,由9个Resnet块组成的转换器将夜间域特征向量f3通过f4映射到白天域特征向量f5。Resnet块通过保留两个域中相似的特征,并通过转换不同的特征,完成夜间特征到白天特征的映射。
Next, the decoder translates the feature f5 of the daytime domain into low-level feature f6. It can be seen from f5 that it already has a clearer vehicle shape and some details. In f6, the contrast between the vehicle and the background is further improved and the daytime style is salient. Compared with f1, the noises on vehicles and roads in feature map f7 are significantly reduced and the vehicle details are greatly exhibited, which helps the detector to recognize the vehicle, even for distant vehicles. Finally, the daytime image x_fake is generated with clearer shapes and details than the input image x. Although some small areas have an unnatural appearance, the vehicles have been clearly distinguished from the background.
接下来,解码器将白天域的特征f5转化为低层特征f6。从f5可以看出它已经有了较为清晰的车辆外形和一些细节。在f6中,车辆与背景的对比度进一步提高,白天风格凸显。与f1相比,特征图f7中车辆和道路上的噪声明显减少,车辆细节得到了极大的展现,这有助于检测器识别车辆,即使对于距离较远的车辆也是如此。最后生成比输入图像x形状和细节更清晰的白天图像x _ false。虽然一些小区域有不自然的外观,但车辆已经与背景明显区分。
2) MULTI-SCALE FEATURE FUSION AND ENHANCEMENT
In Fig. 3, if the daytime images x_fake is used directly to detect vehicles, the relevant night information (vehicle lights and reflections) of the image x would be lost to some extent. Therefore, nighttime features should be adopted to enhance the vehicle features. As shown in part (B) of Fig. 2, we propose multi-scale feature fusion to fuse features of fi (nighttime) and f2b−i (daytime) to enhance vehicle features and further improve the detection accuracy of vehicles.
2 )多尺度特征融合与增强
在图3中,如果直接使用白天图像x _ false进行车辆检测,会在一定程度上丢失图像x的相关夜间信息(车辆灯光与反射)。因此,应采用夜间特征来增强车辆特征。如图2 ( B )所示,我们提出多尺度特征融合来融合fi (夜间)和f2b - i (白天)的特征来增强车辆特征,进一步提高车辆的检测精度。
Fusion of multi-scale features may cause aliasing effects [32] and high feature dimension. To solve this problem, before we fuse the different scales of nighttime features and daytime features, every feature map is first passed through a convolutional kernel to reduce the aliasing effect, reduce the dimensions of the features, and resize the features of different scales into the same scale. Choosing an EF scale of half the size of the input image (208 × 208) can reduce the network complexity. If the EF scale size is 416 × 416, the calculations in part (B) of Fig. 2 will increase exponentially, and even will double the computational complexity of the detection network.
多尺度特征的融合会导致混叠效应[ 32 ]和特征维度过高。针对这一问题,在对夜间特征和白天特征的不同尺度进行融合之前,首先将每一个特征图通过一个卷积核来减少混叠效应,降低特征的维度,将不同尺度的特征调整为同一尺度。选择EF尺度为输入图像( 208 × 208)大小的一半可以降低网络复杂度。如果EF尺度大小为416 × 416,图2中( B )部分的计算量将成倍增加,甚至会使检测网络的计算复杂度翻倍。
Denote Fconv, Fdeconv, and Fconcat as the convolution, deconvolution, and concatenate operation separately. The feature fusion unit follows the operations, as described in (3)–(7). Fconv means the feature map through a kCBL_n_s convolution kernel with size n × n and stride s, as shown in Fig. 2.
将Fconv、Fdeconv和Fconcat分别表示为卷积、反卷积和级联操作。特征融合单元按照式( 3 ) ~式( 7 )进行操作。Fconv表示通过一个大小为n × n,步幅为s的kCBL _ n _ s卷积核得到的特征图,如图2所示。
The feature fi is first adjusted through a convolution layer with learnable weights for scale matching and dimensionality reduction. This step is designed to adjust the size hi × wi to N /2×N /2 and reduce the number of channels by half to ci/2.
首先通过具有可学习权重的卷积层调整特征fi,进行尺度匹配和降维。该步骤的设计目的是将尺寸hi × wi调整为N / 2 × N / 2,将通道数减少一半至ci / 2。

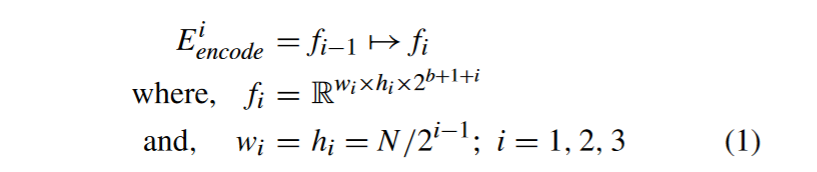
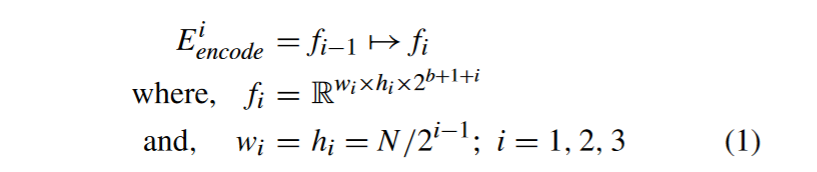
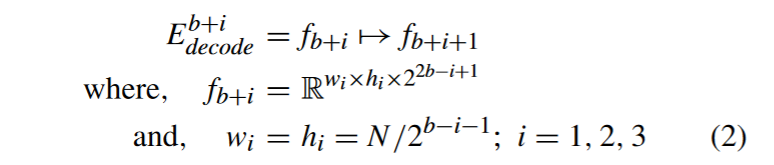


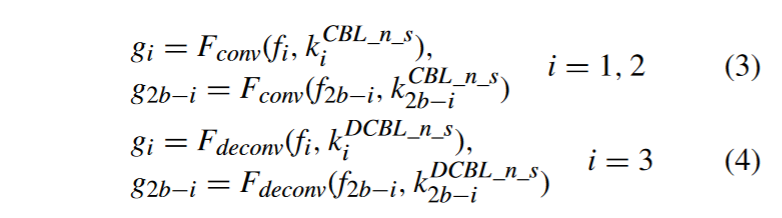

C. OD MODULE
After nighttime features and daytime features are fused in Section B, here the detection module OD is proposed to extract vehicle features and detect them on the enhanced fusion features EF.
The traditional detection methods use the daytime RGB image x_fake as the input for the detection module, which is a two-period network, and further introduces more parameters and computation complexity. In order to solve these problems, we propose a detection module OD, which is cascaded with the FTE module through EF to form a one-period network. The enhanced fusion features from FTE are directly used as the input of OD instead of RGB images to realize the end-to-end training and detection of the whole network and to reduce the network layers and parameters.
C. OD MODULE
在B部分将夜间特征和白天特征进行融合后,这里提出检测模块OD来提取车辆特征并在增强的融合特征EF上进行检测。
传统的检测方法将白天的RGB图像x _ false作为检测模块的输入,这是一个两周期的网络,进一步引入了更多的参数和计算复杂度。为了解决这些问题,我们提出了检测模块OD,通过EF与FTE模块级联,构成一个单周期网络。将FTE增强后的融合特征直接作为OD的输入代替RGB图像,实现整个网络的端到端训练和检测,减少网络层数和参数。
It can be seen from Fig. 2 that part (C) is the OD module, which can be selected as YOLOv3, SSD, Faster-RCNN, or other networks. Here we take the YOLOv3 framework as an example to illustrate our detection module OD. This example can also be applied to other detectors. As shown in Fig. 4, the upper part is the original structure of YOLOv3 using a 416 × 416 RGB image as the input. YOLOv3 adopts Darknet-53 for feature extraction and has the minimum feature scale of 13 × 13, which is 1/32 of the input size. Since the EF size is half (208 × 208) of the original input of YOLOv3, the scale of the feature map after ×32 down-sampling will be reduced to 7 × 7 if the traditional structure of YOLOv3 is used. Small-scale objects will not be detected when the feature map’s resolution is reduced by half. In order to maintain the resolution of the feature scale, we take the network structure of Layer2 - Layer7 of YOLOv3 as our OD module to avoid the lower detection of small targets, as shown in the bottom part of Fig. 4, which removes the largest scale convolution layers in Darknet-53, reduces one down-sampling operation, and replaces the RGB image with EF module.
从图2可以看出,部分( C )为OD模块,可以选择YOLOv3、SSD、Faster - RCNN等网络。这里我们以YOLOv3框架为例说明我们的检测模块OD。这个例子也可以应用于其他探测器。如图4所示,上半部分是YOLOv3以416 × 416的RGB图像作为输入的原始结构。YOLOv3采用darknet- 53进行特征提取,最小特征尺度为13 × 13,为输入尺寸的1 / 32。由于EF大小为YOLOv3原始输入的一半( 208 × 208),如果使用YOLOv3的传统结构,则经过× 32降采样后的特征图的规模将减小到7 × 7。当特征图分辨率降低一半时,小尺度物体将无法被检测到。为了保持特征尺度的分辨率,我们将YOLOv3的Layer2 - Layer7的网络结构作为OD模块,避免了对小目标的较低检测,如图4底部所示,去除了darknet- 53中最大尺度的卷积层,减少了一次下采样操作,并将RGB图像替换为EF模块。
In order to verify the effectiveness of the proposed OD module, we use three detection networks (YOLOv3, SSD and Faster RCNN) including both one-stage and two-stage methods as detection modules.
为了验证所提出的OD模块的有效性,我们使用包含一阶段和两阶段方法的3个检测网络( YOLOv3、SSD和更快速的区域卷积神经网络)作为检测模块。
D. LOSS AND TRAINING
In this section, we detail the loss of the FteGanOd network and the joint training of the FTE module and OD module.
Fig. 5 shows the training framework of our FteGanOd, the green route corresponds to the green route in Fig. 2, the red route parts of Fig. 5 are the structures used for training. Referring to the CycleGAN network [26], FTE contains two generators (Gday and Gnight) and two discriminators (Dday and Dnight). Gday is the generator that translates images from day to night. On the contrary, Gnight is the generator that translates images from night to day. The Day-fake (shown as the blue circle in Fig. 5) output from Gday is the fake daytime image data, and Day-real is the practical real daytime image data. Dnight and Dday are used to judge whether an image is real or fake in the nighttime and daytime image data, respectively. Here only the part of training of Gday is described.
D.损失与训练
本节详细介绍Fte Gan Od网络的损失以及FTE模块和OD模块的联合训练。
图5所示为本文Fte Gan Od的训练框架,绿色路线对应图2中的绿色路线,图5中红色路线部分为用于训练的结构。参考CycleGAN网络[ 26 ],FTE包含2个生成器( Gday和Gnight)和2个判别器( Dday和Dnight)。Gday是将图像从白天翻译到夜晚的生成器。相反,Gnight是将图像从夜晚翻译到白天的生成器。Gday输出的Day - false (如图5中蓝色圆圈所示)为伪白天图像数据,Day - real为实际真实白天图像数据。Dnight和Dday分别用于在夜间和白天的图像数据中判断一幅图像是真是假。这里仅对Gday的训练部分进行说明。
The loss of the OD module (LDet) includes bounding box regression loss (Lloc) and classification loss (Lcls). The loss of FTE module consists of three terms: the cycle consistent loss (Lcyc_night), the discrimination loss (LD_night) and the detection loss (LDet).
For image x of night domain, the image translation cycle should be able to bring x back to the original image, i.e., x → Gday(x) → Gnight(Gday(x)) ≈ x. This is called forward cycle consistency, the cycle consistency loss defined as:
OD模块的损失( LDet )包括边界框回归损失( Lloc )和分类损失( Lcls )。FTE模块的损耗由3项组成:循环一致性损耗( Lcyc _night )、鉴别力损耗( LD _night )和探测损耗( LDet )。
对于夜晚域的图像x,图像的平移循环应该能够将x带回原图像,即x→Gday ( x )→Gnight ( Gday ( x ) )≈x。这称为前向循环一致性,循环一致性损失定义为:
Loss LDet is added to the loss function of the FTE module, which is an important part of optimization allowing it to focus on enhancing the fused features of the target region and the vehicle. The loss Lcls in LDet is for the recognition of target features. It has more effect on feature fusion enhancement than Lloc, so different weights are applied to Lcls and Lloc. The loss of the FTE module is:
在FTE模块的损失函数中加入Loss LDet,这是优化的重要部分,使其能够专注于增强目标区域和车辆的融合特征。LDet中的损失Lcls用于目标特征的识别。它比Lloc对特征融合增强效果更好,因此对Lcls和Lloc采用不同的权重。FTE模块的损耗为:

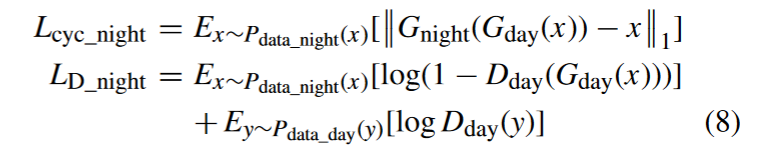

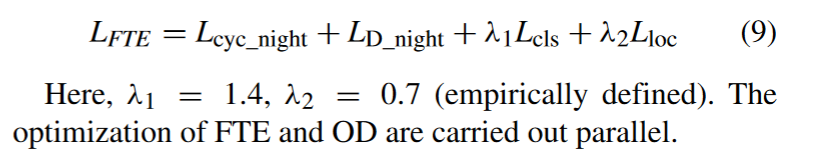
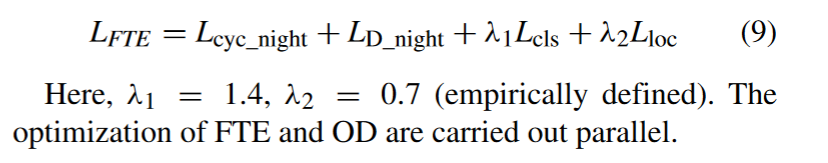
IV. EXPERIMENTAL METHODOLOGY
The experiments on the FteGanOd network are described conducted in this section. We first introduce the datasets used for training and testing, following with the evaluation method, the experimental process and the training method of our proposed FteGanOd network. Finally, the results of our experiments are analyzed and discussed.
Ⅳ.实验方法
本节介绍在Fte Gan Od网络上进行的实验。首先介绍用于训练和测试的数据集,然后介绍本文提出的Fte Gan Od网络的评估方法、实验过程和训练方法。最后对实验结果进行了分析和讨论。
A. DATASET
Public dataset and private dataset are adopted to evaluate the proposed FteGanOd network. The public dataset, Berkeley Deep Drive (BDD) dataset1 [25], has 100,000 real driving scene images, including training set (70,000), test set (20,000), and validation dataset (10,000). It is currently the large-scale, diverse and complex driving dataset with annotations. The labels of the images include 10 categories (bus, truck, car, person, train, etc.), different weather (sunny, rainy, etc.), multiple types of scenes (roads, city streets, etc.), time (dawn/dusk, day, night).
A. DATASET
公共数据集和私有数据集用于评估提出的Fte Gan Od网络。公开数据集Berkeley Deep Drive ( BDD )数据集1 [ 25 ]有10万张真实驾驶场景图像,包括训练集( 7万)、测试集(两万)和验证集(万)。它是目前具有标注的大规模、多样性和复杂性的驾驶数据集。图像的标签包括10类(公交车、货车、汽车、人、火车等。),不同天气(晴天、雨天等。),多类型场景(道路、城市街道等。),时间(黎明/黄昏,白天,黑夜)。
We selected all the night images from the BDD based on the time labels and further modified the label category. We defined vehicle category as dataset containing only bus, truck and car. Our training dataset (25,338 images) were selected from the BDD training set with more than 260,000 vehicle targets; our validation dataset (3526 night images) was selected from BDD validation dataset with more than 37,000 vehicle targets. Our training and validation dataset, referred as DATASET1 (hard), contain various weather, scenes, occluded and truncated targets, i.e., many difficult-to-recognize targets. DATASET1 (hard) is also a high-density dataset with an average of about 10 vehicles per image. Therefore, we carefully selected 3000 images (2000 for training and 1000 for testing) from the DATASET1 (hard). A vehicle with the bounding box less than 25 pixels and the vehicle that were difficult to distinguish were removed after the image was resized to 416 × 416 to form a low-density (average 5 vehicles per image) dataset, called DATASET1(easy).
我们根据时间标签从BDD中选择所有的夜间图像,并进一步修改标签类别。我们将车辆类别定义为只包含公交车、卡车和汽车的数据集。我们的训练数据集( 25338张图像)是从包含超过26万车辆目标的BDD训练集中选取的;我们的验证数据集( 3526张夜间图像)从包含超过37,000个车辆目标的BDD验证数据集中选取。我们的训练和验证数据集DATASET1 ( hard )包含各种天气、场景、遮挡和截断目标,即许多难以识别的目标。数据SET1 ( hard )也是一个高密度数据集,平均每幅图像约10辆车。因此,我们从DATASET1 ( hard )中精心挑选了3000张图像( 2000用于训练, 1000用于测试)。将图像调整为416 × 416大小后去除包围盒小于25像素的车辆和难以区分的车辆,形成低密度的(平均每幅图像5辆车)数据集,称为DATASET1 ( easy )。
Our private dataset was obtained by using the monocular camera on our intelligent driving car in urban areas from Changchun and Shenzhen cities in China. We selected 20,877 frames from the private dataset as DATASET2 dataset, 80% of which (16,700 frames) were used for training and 20% (4177 frames) for verification. The category of the vehicle was defined as the same way as DATASET1. The original image resolution of DATASET1 and DATASET2 is 1280 × 720 pixels, which was resized to 416 × 416 or 300 × 300 for our experiments. Fig. 6 shows some samples of the datasets of DATASET1 and DATASET2. It can be seen that the multi-lane, high-density traffic that increase the environmental complexity and detection difficulty. TABLE 1 is the detail explanation about the datasets.
我们的私有数据集是通过在我们的智能驾驶汽车上使用单目摄像头从中国的长春和深圳城市地区获得的。我们从私有数据集中选取了20877帧作为DATASET2数据集,其中80 %的( 16700帧)用于训练,20 % ( 4177帧)用于验证。车型类别定义同DATASET1。DATASET1和DATASET2的原始图像分辨率为1280 × 720像素,实验中将其调整为416 × 416或300 × 300像素。图6展示了DATASET1和DATASET2数据集的部分样本。可见,多车道、高密度的交通增加了环境复杂度和检测难度。表1是对数据集的详细说明。
B. PERFORMANCE EVALUATION
Based on the OD module, we used three networks frames YOLOv3, SSD and Faster RCNN as the detection model to compare with the state-of-the-art object detection methods. These networks were verified on DATASET1 and DATASET2.
B.性能评估
在OD模块的基础上,使用YOLOv3、SSD和更快速的区域卷积神经网络三个网络帧作为检测模型,与现有的目标检测方法进行对比。这些网络在DATASET1和DATASET2上得到验证。
1) EVALUATION METHOD In order to evaluate the experimental results, we use the following commonly used indicators for vehicle detection. (1) Precision-Recall (PR) curve is used to describe the relationship between precision and recall. False detection rate (FDR) can be computed as FDR = 1 - precision. Recall is also called true positive rate (TPR), and the miss rate can be presented as Miss Rate = 1 - recall. (2) The established mean average precision (mAP) is widely used to evaluate the performance of object detection algorithms. Average precision (AP) is proportional to the area under the PR curve. Since there is only one category in this experiment, AP is equivalent to mAP. (3) We employ the frames per second (FPS) to quantitatively evaluate the detection speed of different networks. Moreover, the intersection over union (IOU) higher than 0.5 of the prediction bounding box and the ground truth box is considered to be assigned a positive label.
1 )评价方法
为了评价实验结果,我们使用以下常用的指标进行车辆检测。( 1 )精确率-召回率( PR )曲线用于描述精确率和召回率之间的关系。误检率( false detection rate,FDR )可计算为FDR = 1 -精确率。召回率也称为真阳性率( TPR ),漏检率可以表示为漏检率= 1 -召回率。( 2 )建立的 平均精度( mean average precision,mAP )被广泛用于评价目标检测算法的性能。平均精度( AP )与PR曲线下面积成正比。由于本实验中只有一类,因此AP等价于mAP。( 3 )采用每秒帧数( FPS )来定量评估不同网络的检测速度。此外,预测边界框与真实框的交并比( IOU )大于0.5被认为是正标签。
2) TRAIN CYCLEGAN
CycleGAN is the basic network of the FTE module, the source code of CycleGAN is publicly available.2 The trained CycleGAN model was used as the pre-training model for the FTE, which helped to improve the stability and convergence speed during training FTE. The training parameters use the default settings. The training was finished when the average loss per 10 batches stabilized.
2)将训练好的CycleGAN模型作为FTE的预训练模型,有助于提高训练FTE时的稳定性和收敛速度。训练参数使用默认设置。当每10批次平均损失趋于稳定时结束训练。
3) TRAIN DETECTORS
We adopt YOLOv3, SSD300 and Faster RCNN networks as the detectors.3 The input image resolution of YOLOv3 and Faster RCNN is 416 × 416, while SSD300 is 300 × 300. The best model was saved and used as a pre-trained model for our detection module OD.
3 )交通检测器采用YOLOv3、SSD300和更快速的区域卷积神经网络网络作为检测器。3 . YOLOv3和更快速的区域卷积神经网络网络的输入图像分辨率为416 × 416,SSD300网络的输入图像分辨率为300 × 300。保存最佳模型并作为我们检测模块OD的预训练模型。
4) TRAINING OUR NETWORK
We used three object detection networks as the structure of the OD module, and cascaded those with the FTE module to get three different nighttime detection networks. The detailed training steps are as follows.
4 )训练我们的网络
我们使用三个目标检测网络作为OD模块的结构,并与FTE模块级联得到三个不同的夜间检测网络。具体训练步骤如下。
The training process and loss are shown in Fig. 5. We used pre-trained models and fine-tuning network parameters to reduce training time. The generator of FTE was initialized using CycleGAN trained network weights, fine-tuning the generator parameters with a smaller learning rate (we set the learning rate to 0.00001 - 0.0001). Similarly, we used the weights trained by the detector in 3) to initialize OD and fine-tuned with a smaller learning rate. We randomly initialized the weight of the feature fusion of FTE and set a large initial learning rate (0.001 - 0.01). The input image resolution was set to 416 × 416 (including the network with the SSD300-based structure as the detection module). Image preprocessing mainly included random brightness, color jittering and random mirror.
训练过程及损失如图5所示。我们使用预训练模型和微调网络参数来减少训练时间。利用CycleGAN训练的网络权值初始化FTE的生成器,以较小的学习速率(我们将学习率设置为0.00001 - 0.0001)微调生成器参数。类似地,我们使用3 )中检测器训练的权重初始化OD,并用较小的学习率进行微调。随机初始化FTE的特征融合权重,设置较大的初始学习率( 0.001 ~ 0.01)。输入图像分辨率设置为416 × 416 (包括以SSD300为主结构的网络作为检测模块)。图像预处理主要包括随机亮度、颜色抖动和随机镜像。
To ensure that each method got the best results, we trained each network for 50 epochs. The validation phase was performed during the training period, and the best model was saved. Due to the different parameters of each network, the training time were different. The training time for YOLOv3, SSD, Faster RCNN, and our method were about 52 hours, 20 hours, 46 hours and 63 hours, respectively.
为了保证每种方法都能得到最好的结果,我们对每个网络进行了50个历元的训练。在训练期间进行验证阶段,保存最佳模型。由于每个网络的参数不同,训练时间也不同。YOLOv3、SSD、更快速的区域卷积神经网络和本文方法的训练时间分别约为52小时、20小时、46小时和63小时。
5) EXPERIMENTAL PLATFORM AND COMPUTATIONAL PERFORMANCE
The proposed network was implemented with the pytorch framework running on a PC with Intel(R) Xeon(R) E5-2650V4 CPU 2.2GHz and NVIDA GTX1080Ti GPU. The machine was running Linux Ubuntu 16.04 with NVIDA CUDA 9.0 and cuDNN 7.0.
5 )实验平台与计算性能
本文网络采用pytorch框架实现,运行在Intel ( R ) Xeon ( R ) E5-2650V4 CPU 2.2GHz,NVIDA GTX1080Ti GPU的PC机上。机器运行Linux Ubuntu 16.04,NVIDA CUDA 9.0,cuDNN 7.0。
C. RESULTS AND DISCUSSIONS
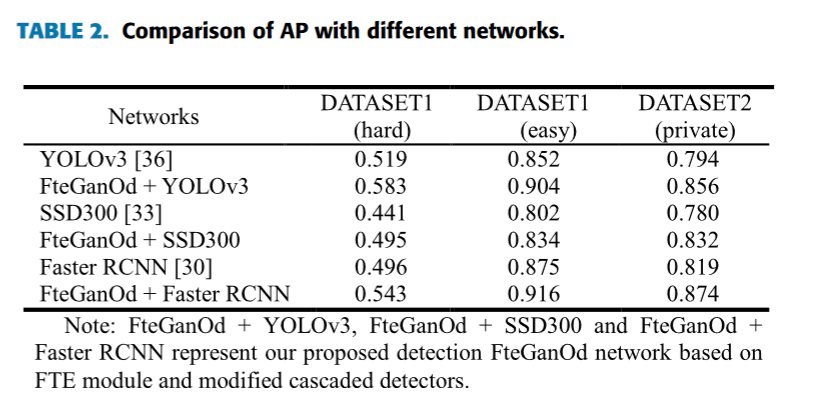
The experimental results are presented and discussed in this section. The proposed method was validated on different datasets as shown in TABLE 2.
On DATASET1 (hard), the AP of FteGanOd + YOLOv3 improve by 6.4% compared with YOLOv3, the AP of FteGanOd + SSD improve 5.4% compared with SSD, and FteGanOd + Faster RCNN improve 4.7% compared with Faster RCNN. On DATASET1 (easy) and DATASET2, the APs of the cascaded networks increase by about 6%.
三、结果与讨论
本部分给出了实验结果并进行了讨论。所提出的方法在不同的数据集上进行了验证,如表2所示。
在DATASET1 ( hard )上,Fte GanOd + YOLOv3的AP比YOLOv3提高了6.4 %,Fte GanOd + SSD的AP比SSD提高了5.4 %,Fte GanOd +更快速的区域卷积神经网络比更快速的区域卷积神经网络提高了4.7 %。在DATASET1 ( easy )和DATASET2上,级联网络的AP增加了约6 %。
Fig. 7 shows the comparison of the translation, fusion and enhancement results between traditional CycleGAN (Fig. 7 (b)) and our proposed FteGanOd (Fig. 7 (c)) testing on DATASET1 (hard). The results from traditional CycleGAN (Fig. 7 (b)) are quite different from the real daytime images because lots of detail textures are lost, such as the blurred contour of cars and weak taillights, which decreases the accuracy of the vehicle detection. Fig. 7 (c) shows the fused and enhanced results of our proposed FteGanOd with sharp vehicle contours and clear taillights compared with CycleGAN from the enlarged parts. This increased detail helps to distinguish the vehicles in the low-light environment and reduces the interference from streetlights, leading to higher accurate vehicle detection.
图7为DATASET1 ( hard )上传统CycleGAN (图7 ( b )) )和本文提出的Fte Gan (图7 ( c )) )测试的平移、融合和增强结果对比。传统CycleGAN (图7 ( b )) )的结果与真实白天图像有较大差异,丢失了大量的细节纹理,如汽车轮廓模糊、尾灯微弱等,降低了车辆检测的准确性。图7 ( c )显示了我们提出的FteGanOd与CycleGAN相比,从放大的部分融合和增强的结果,车辆轮廓清晰,尾灯清晰。这种增加的细节有助于区分低照度环境中的车辆, 减少了路灯的干扰,从而提高了车辆检测的准确性。
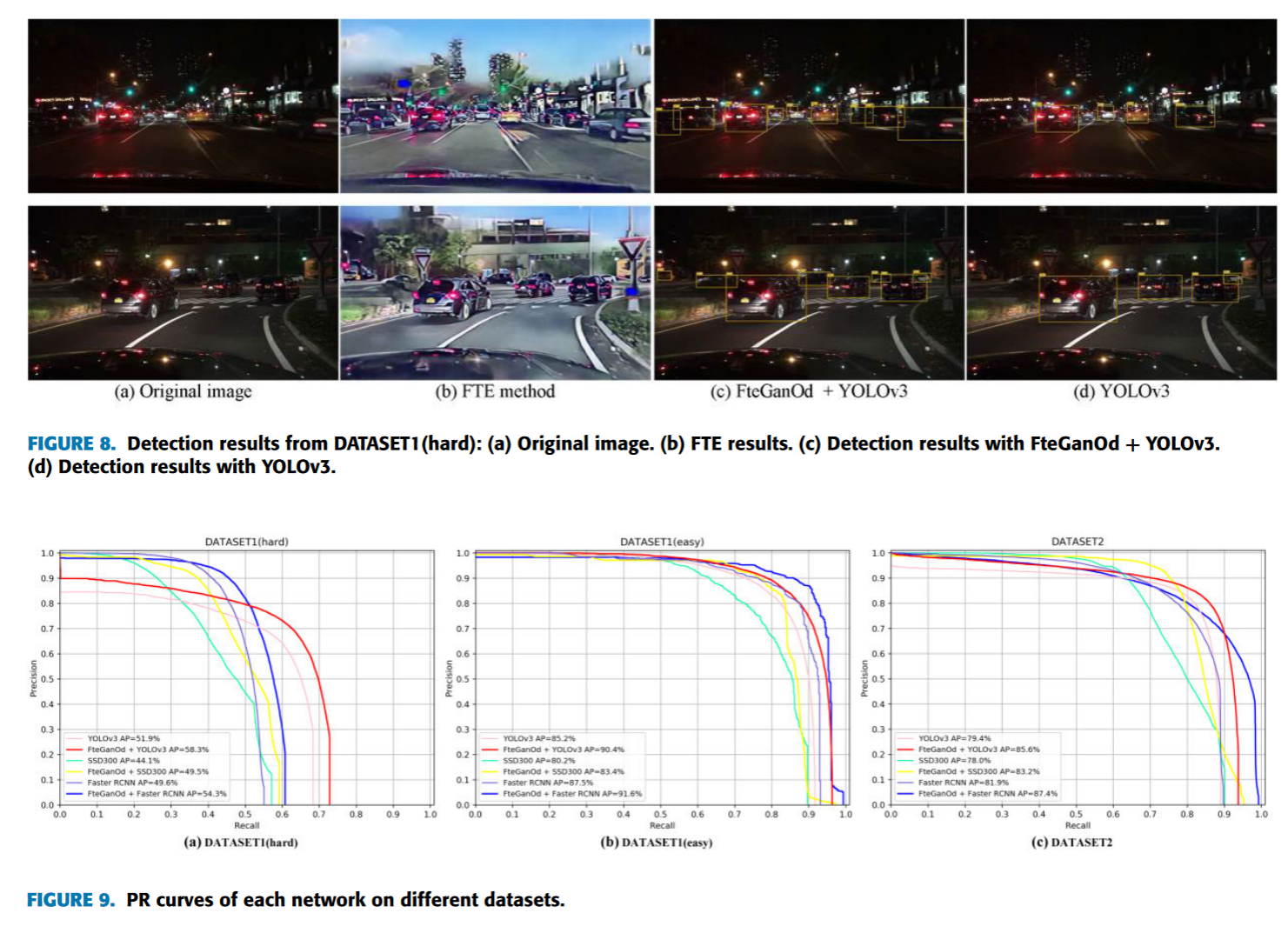
Fig. 8 shows the comparison of vehicle detection results between YOLOv3 and our proposed FteGanOd method on dataset DATASET1 (hard). It can be seen that FteGanOd detects more vehicles than YOLOv3 in lowlight condition. Therefore, the proposed FteGanOd with FTE and OD modules significantly reduces the number of false positive detection.
Fig. 9 shows the PR curve of each network tested on different datasets. It can be seen that our proposed method achieved higher precision at the same recall rate. It can be seen from Fig. 9(a) that at recall = 0.5, the precision of FteGanOd + Faster RCNN is 0.824, Faster RCNN is 0.633, representing an improvement of about 19%. When the precision is fixed at 0.8, the recall of FteGanOd + Faster RCNN is 0.519, compared to 0.451 for Faster RCNN, an improvement of about 7% Therefore, our proposed FteGanOd method has higher precision and recall than other methods.
图8为YOLOv3与本文提出的Fte Gan Od方法在数据集DATASET1 ( hard )上的车辆检测结果对比。可以看出,在低光照条件下,Fte Gan Od比YOLOv3检测到更多的车辆。因此,本文提出的带有FTE和OD模块的Fte Gan Od显著降低了假阳性检测的数量。
图9展示了各个网络在不同数据集上测试的PR曲线。可以看出,我们提出的方法在相同的召回率下取得了更高的准确率。从图9 ( a )可以看出,在召回率= 0.5时,FteGanOd +更快速的区域卷积神经网络的准确率为0.824,更快速的区域卷积神经网络的准确率为0.633,提高了约19 %。当查准率固定为0.8时,Fte Gan Od +更快速的区域卷积神经网络的查全率为0.519,相比更快速的区域卷积神经网络的查全率0.451,提高了约7 %。
TABLE 3 shows the detection speed and parameters of each network with input batch size = 1 using the same testing dataset.
After adding our proposed FTE module, the detection speed decreases. FteGanOd + YOLOv3 achieves the detection speed of 16.2 FPS, and the average inference time for an image is about 0.061 s.
表3展示了使用相同的测试数据集,输入批大小为1的每个网络的检测速度和参数。
加入我们提出的FTE模块后,检测速度有所下降。FteGanOd + YOLOv3实现了16.2 FPS的检测速度,图像平均推理时间约为0.061 s。
D. COMPARISON WITH EXISTING METHODS
Most recent studies on nighttime vehicle detection validate their methods on their own private datasets, which are not available in public. It is difficult for us to compare our method with them as we have no benchmark dataset for night vehicle detection. Due to different scenes, there are great differences between these datasets. Fig. 10 shows some sample images from other datasets published in related papers. They used different density and complexity datasets. Therefore, we cannot directly compare our experimental results with theirs.
D .与现有方法的比较
最近关于夜间车辆检测的研究在他们自己的私人数据集上验证了他们的方法,而这些数据并不公开。由于我们没有夜间车辆检测的基准数据集,我们很难将我们的方法与他们进行比较。由于场景不同,这些数据集之间存在较大差异。图10展示了相关文献中发表的其他数据集的部分样本图像。他们使用了不同密度和复杂度的数据集。因此,我们无法直接将我们的实验结果与他们的实验结果进行比较。
However, we can analyze the different results from other perspectives. TABLE 4 lists the detection accuracy from other literature. Fig. 10 shows the corresponding sample images published in their papers. Most methods were evaluated using low-density traffic conditions and low-complexity backgrounds. The datasets we used (DATASET1 (easy) and DATASET2) contain an average of 5 target vehicles per image, and are more complex than those private datasets [1], [13]–[15], [24], [22]. Our method can adapt to different light conditions under natural driving conditions. It can be seen that our method (e.g. FteGanOd + Faster RCNN) either outperforms or achieves similar detection rates on more complex datasets compared with existing methods on lower complexity datasets. The method of [22] achieved a precision of 97.1% and a recall of 55.0%. Our method (FteGanOd + Faster RCNN) achieve a higher precision of 97.8% at the same recall.
但是,我们可以从其他角度来分析不同的结果。表4列出了其他文献的检测准确率。图10给出了他们论文中发表的相应样本图像。大多数方法使用低密度交通条件和低复杂度背景进行评估。我们使用的数据集( DATASET1 ( easy )和DATASET2 )平均每张图像包含5辆目标车辆,比私有数据集[ 1 ],[ 13 ] - [ 15 ],[ 24 ],[ 22 ]更复杂。我们的方法能够适应自然驾驶条件下不同的光照条件。可以看出,与现有方法相比,我们的方法(例如FteGanOd +更快速的区域卷积神经网络)在更复杂的数据集上要么优于现有方法,要么在更低复杂度的数据集上达到相似的检测率。文献[ 22 ]的方法取得了97.1 %的准确率和55.0 %的召回率。我们的方法( FteGanOd +更快速的区域卷积神经网络)在相同召回率下达到了97.8 %的较高准确率。




V. CONCLUSION
In this paper, we propose an effective night detection method called FteGanOd that cascades the feature translate- enhancement FTE module and the object detection OD module. This method is designed to solve the problem of low detection of vehicles at night on city roads with weak/complex lighting environment and dense traffic flow. The proposed FTE module uses unpaired input image and CycleGAN to translate the nighttime images into daytime images, and further fuses multi-scale feature to enhance the vehicle features at night. The enhanced features retain the important information of vehicle lights at night and augment the vehicle features during the day. Our experimental results show that the proposed method effectively enhances the features of nighttime vehicles and suppresses the interference from other lights. It is helpful to improve the detection accuracy and reduce the false/missed detection rate. In addition, we found that there are some small targets in the remote distance in DATASET1 (hard) were missed after passing through the FTE module. This likely occurred because small targets were weakened and recognized as part of the background. To improve the detection rate for remote small targets at night is the important work we need to study in the future.
五、结论
本文提出了一种将特征平移增强FTE模块和目标检测OD模块级联的有效夜间检测方法Fte Gan Od。该方法旨在解决在光照环境弱/复杂、车流量密集的城市道路上夜间车辆检测率低的问题。提出的FTE模块使用未配对的输入图像和CycleGAN将夜间图像转化为白天图像,并进一步融合多尺度特征来增强夜间的车辆特征。增强后的特征保留了夜间车灯的重要信息,增强了白天的车辆特征。实验结果表明,该方法有效地增强了夜间车辆的特征,抑制了其他灯光的干扰。有利于提高检测精度,降低误检/漏检率。此外,我们发现在经过FTE模块后,DATASET1 ( hard )中有一些远距离的小目标被漏检。这可能是因为小目标被削弱并被识别为背景的一部分。提高对夜间远距离小目标的检测率是我们今后需要研究的重要工作。