5 VEHICLE MAKE AND MODEL RECOGNITION
The objective of vehicle make and model recognition is to identify the make (e.g., Toyota) and model (e.g., Camry) of vehicle images captured by vision sensors. Although this problemmay seem simple, there are several challenges particular to VMMR, as we shall describe below. In this section, we provide a systematic review of VMMR works according to the breakdown of AVC systems presented in Figure 2. We believe it will help the readers focus on methods to solve the broken-down problems, rather than the entire problem. The main modules in VMMR are the Features Extraction and Global Representation module (Section 5.1) and the Classification module (Section 5.2).
车辆品牌和型号识别的目标是识别由视觉传感器捕获的车辆图像的品牌(例如丰田)和型号(例如凯美瑞)。 虽然这个问题看起来很简单,但是VMMR特有的挑战还是有的,我们将在下面描述。 在本节中,我们根据图2所示的AVC系统的故障提供了对VMMR工作的系统评估。我们认为这将有助于读者关注解决故障问题的方法,而不是整个问题。 VMMR中的主要模块是特征提取和全局表示模块(第5.1节)和分类模块(第5.2节)。
An important requirement for testing and evaluating VMMR approaches in real-world scenarios is to have a comprehensive dataset that represents real-world conditions (occlusions, varying weather and lighting), multiplicity, ambiguity issues, and so on. In Section 8, we review and compare the different datasets used in representative VMMR works.
在真实场景中测试和评估VMMR方法的一个重要要求是拥有一个代表真实世界条件(遮挡,变化的天气和照明),多样性,模糊性问题等的综合数据集。 在第8节中,我们回顾并比较了代表性VMMR作品中使用的不同数据集。
The problem of vision-based automated VMMR can be considered as a challenging multi-class image classification problem, in which a class is defined as a particular make and model of vehicle. However, VMMR presents a more diverse and challenging set of issues than in other image classification problems. The various challenges in VMMR include Ambiguity and Multiplicity, as initially presented by Hsieh et al. (2014). Other issues (as presented in Section 1) include diversity of vehicle types, lighting, or environmental conditions, occlusions (e.g., by pedestrians or other vehicles), or customized vehicle design or appearance. In the context of VMMR, multiplicity and ambiguity issues are described as follows.
基于视觉的自动化VMMR的问题可以被认为是具有挑战性的多类图像分类问题,其中一类被定义为车辆的特定品牌和型号。 但是,与其他图像分类问题相比,VMMR呈现出更多元化和更具挑战性的问题。 VMMR中的各种挑战包括Hsieh等人最初提出的歧义和多重性(2014)。 其他问题(如第1部分所述)包括车辆类型,照明或环境条件的多样性,遮挡(例如行人或其他车辆),或定制车辆设计或外观。 在VMMR的背景下,多重性和模糊性问题描述如下。
—Ambiguity: With regards to VMMR, we classify the ambiguity problem into two kinds: (a) Inter-Make Ambiguity and (b) Intra-Make Ambiguity. The former ambiguity refers to the issue of vehicles (models) of different companies (makes) having visually similar shape or appearance, that is, two different make-model classes have similar front or rear views. For example, “Toyota Camry 2005” and “Nissan Cefiro 1999” are similar in visual appearance (see Figure 4). The latter kind of ambiguity results when different vehicles (models) of the same company (make) are similar in shape or appearance. For example, the “Altis” and “Camry” models of the “Toyota” make have similar front faces (see Figure 5). The similarity may not necessarily be in a visual sense only, but could also be in the feature space used to describe their images.
—歧义:关于VMMR,我们将歧义问题分为两类:(a)交互歧义和(b)内部歧义。 以前的模糊性是指不同公司(制造商)的车辆(模型)具有视觉上相似的形状或外观的问题,也就是说,两种不同的制造模型类别具有相似的前视图或后视图。 例如,“Toyota Camry 2005”和“Nissan Cefiro 1999”在视觉外观上相似(见图4)。 当同一公司(品牌)的不同车辆(型号)在形状或外观上相似时,会导致后一种模糊性。 例如,“丰田”车型的“阿尔蒂斯”和“凯美瑞”车型具有相似的正面(见图5)。 相似性不一定只在视觉上,而可能在用于描述其图像的特征空间中。
—Multiplicity: This problem occurs when a vehicle model (of the same make) has different shapes, designs or appearances. Figure 6 shows some examples of the multiplicity problem in NTOU-MMR Dataset (Hsieh et al. 2014).
—多重性:当(同一品牌的)车辆模型具有不同的形状,设计或外观时,会出现此问题。 图6显示了NTOU-MMR数据集中多重性问题的一些例子(Hsieh et al.2014)。

5.1 Features Extraction & Global Features Representation
To describe the vehicle makes and models, various local features are extracted from the vehicle ROIs (i.e., Features Extraction). While a few works use the local features directly (Dlagnekov 2005), most others embed or encode them into Global Features Representations. Moreover, recent works have started to exploit CNNs to generate image features representations for the VMMR problem (Sochor et al. 2016).
为了描述车辆品牌和型号,从车辆ROI中提取各种局部特征(即特征提取)。 尽管一些作品直接使用局部特征(Dlagnekov 2005),但大多数作品将其嵌入或编码为全局特征表示。 此外,最近的作品已经开始利用CNN为VMMR问题生成图像特征表示(Sochor et al.2016)。
Works such as Dlagnekov (2005) have used raw image features like SIFT (Lowe 1999) to describe and match make-model instances. Prokaj and Medioni (2009) used HOG- and SIFT-like features from 2D test images to be compared with those from 2D projections of 3D vehicle models. Psyllos et al. (2011) adopted a hierarchical approach in which Phase Congruency Calculation between images is first used to recognize the make, and SIFT features are then used to recognize the model. Some works such as Llorca et al. (2014) used the positions and sizes of car emblems and HOG features of emblem regions to classify vehicle models, assuming the make was known. Car emblems such as model symbol and trim level were considered. However, it is unclear if their approach could achieve both make and model recognition.
诸如Dlagnekov(2005)等作品曾使用SIFT(Lowe 1999)等原始图像特征来描述和匹配生成模型实例。 Prokaj和Medioni(2009)使用2D测试图像中的HOG和SIFT特征与3D车辆模型的2D投影进行比较。 Psyllos等人 (2011)采用了一种分层方法,其中图像之间的相位一致性计算首先用于识别制作,然后使用SIFT特征识别模型。 一些作品,如Llorca等 (2014)使用汽车标志的位置和大小和HOG特征的位置和大小来对车辆模型进行分类,假定品牌是已知的。 考虑了诸如模型符号和修剪水平等汽车标志。 但是,目前还不清楚他们的方法是否能够实现品牌和型号的识别。
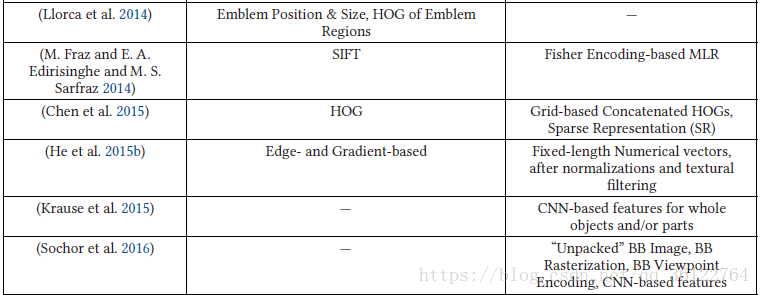
In most VMMR approaches, the raw features are embedded into global representations of vehicle makes and models. The quality of a global features representation technique is assessed by its processing speed, computational complexity in forming the holistic representations, and the VMMR accuracy, which reflects its discriminative capacity in representing the different makes and models, while generalizing over the multiplicity issues within a make-model class. As summarized in Table 3, different techniques have been proposed to integrate the raw image features into holistic global representations.
在大多数VMMR方法中,原始特征被嵌入到车辆制造和模型的全局表示中。 全局特征表示技术的质量通过其处理速度,形成整体表示的计算复杂性和VMMR准确性来评估,该准确度反映了它在表示不同制造商和模型时的区别能力,同时推广了制造中的多重性问题模型类。 如表3所总结的,已经提出了不同的技术将原始图像特征整合到整体全局表示中。
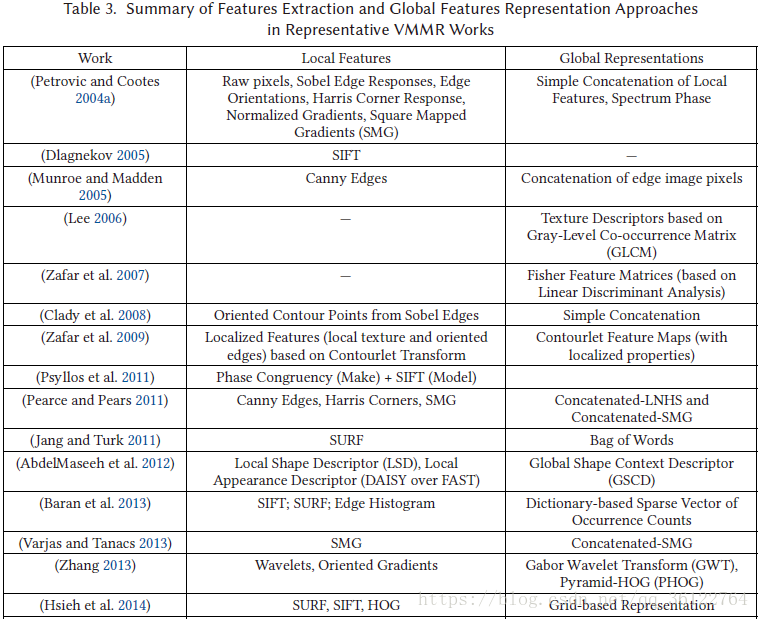
A straightforward way of building a global representation from local features is simple concatenation. This approach is followed by Petrovic and Cootes (2004a), who concatenate local features such as Sobel edge responses, edge orientations, Harris corner responses, Normalized Gradients, and Square Mapped Gradients (SMG). They also used the Spectrum Phase of vehicle face images as global representations. Out of these, the concatenated SMG yielded acceptable accuracies. Munroe and Madden (2005) also explored using simple concatenation of edge image pixels into a fixedlength feature vector for VMMR.
从局部特征构建全局表示的直接方法是简单的连接。 Petrovic和Cootes(2004a)采用了这种方法,他们连接了诸如索贝尔边缘响应,边缘方位,哈里斯角落响应,归一化梯度和平方映射梯度(SMG)等局部特征。 他们还将车辆脸部图像的光谱相位用作全局表示。 其中,SMG级联产生了可接受的精度。 Munroe和Madden(2005)也探讨了使用简单的边缘图像像素连接到VMMR的固定长度特征向量。
To explore texture descriptors for VMMR, Lee (2006) used Gray Level Co-occurrence Matrices (GLCMs) of vehicle face images. A GLCM quantifies texture based on the spatial relationships of pixels. For each kind of spatial relationship (East, West, South-East, and North-West), a different GLCM is computed. From each GLCM, four texture descriptors are derived, namely Contrast, Homogeneity, Entropy, and Momentum. This gives 16 texture descriptors for a given image. Since a GLCM is based on comparing pixel intensity levels, the technique is sensitive to changes in lighting conditions, shadows, and occlusions.
为了探索VMMR的纹理描述符,Lee(2006)使用车辆脸部图像的灰度共生矩阵(GLCMs)。 GLCM基于像素的空间关系量化纹理。 对于每种空间关系(东,西,东南和西北),计算不同的GLCM。 从每个GLCM导出四个纹理描述符,即对比度,均匀性,熵和动量。 这为给定图像提供了16个纹理描述符。 由于GLCM基于比较像素强度水平,因此该技术对照明条件,阴影和遮挡的变化很敏感。
Zafar et al. (2007) proposed appearance-based features known as Fisher Feature Matrices, computed based on 2D-LDA, to deal with the occlusion problem. However, the occlusions were artificially inserted onto the images as blank ellipses, which do not represent real-world occlusions such as those by pedestrians or other vehicles. An attempt to deal with minor real-world occlusions was made by Clady et al. (2008) in which vehicles were occluded by toll-gates. They extracted stable Oriented-Contour Points (OCPs) from a number of samples for each class.
Zafar等人 (2007)提出了基于外形的特征,称为Fisher特征矩阵,基于2D-LDA计算,以处理遮挡问题。 然而,这些遮挡被人为地插入到图像上作为空白椭圆,这并不代表真实世界的遮挡,例如行人或其他车辆的遮挡。 Clady等人(2008年)尝试处理微小的现实世界的遮挡, 其中车辆被关卡堵塞。 他们从每个类的大量样本中提取稳定的Oriented-Contour Points(OCP)。
Zafar et al. (2009) proposed an approach combining local texture and oriented edges in Contourlet Transform (CT) domain. Through CT, they decomposed vehicle images into a Laplacian Pyramid (LP) of L + 1 equi-size scale levels (which includes a coarse-level image and L bandpass images). Each of the L scale levels is further decomposed into D directional sub-bands through a directional filter bank. Finally, these L · D directional bands are used to extract the D Contourlet Feature Maps, which are then used for classification.
Zafar等人 (2009)提出了在Contourlet变换(CT)域中结合局部纹理和定向边缘的方法。 通过CT,他们将车辆图像分解成L + 1等尺度的拉普拉斯金字塔(LP)(包括粗糙图像和L带通图像)。 通过方向滤波器组将L个比例级别中的每一个进一步分解为D个方向子带。 最后,这些L·D方向带被用来提取D Contourlet特征图,然后用于分类。
Pearce and Pears (2011) evaluated multiple edge-features-based global representations: concatenated pixels of Canny edge images, concatenated SMGs, concatenated Harris corner responses, and concatenated Locally Normalized Harris Strengths (LNHS). Amongst these, concatenated LNHS were found to be more effective for VMMR in terms of accuracy and speed. Saravi and Edirisinghe (2013) proposed Local Energy Shape Histogram (LESH) features with temporal processing. The ROI is partitioned into 16 sub-regions. From each sub-region, a local histogram is generated based on a local energy model. The concatenation of local histograms is termed as the LESH feature of the image. However, since all these approaches need the whole vehicle ROI, they are all sensitive to occlusions. Concatenated SMGs were also used by Varjas and Tanacs (2013). He et al. (2015b) concatenated local edges and gradient features into a fixed-length numerical vector, after applying a Difference-of-Gaussian (DoG)-based bandpass filter and smoothing filter. The bandpass filter was designed to eliminate high spatial frequencies to reduce noise, and to eliminate low spatial frequencies corresponding to in-discriminative regions of car hoods and headlamps. Before extracting edges or gradients, they proposed using lighting balancing and multi-scale retinex (MSR) to unhide the details in regions that are dark or covered by shadows. Baran et al. (2013) found that by combining edge-based MPEG-7 descriptors, namely Edge Histograms (Salembier and Sikora 2002; Park et al. 2000) with SIFT and SURF descriptors through a weighted combination rule, the accuracy of VMMR improved. A major limitation of most edges- and gradients-based techniques is the requirement of well-aligned ROIs, strictly frontal views, or planar projection of skewed views onto frontal-like views.However, an acceptableVMMRsystem should operate under a broad range of viewpoints (or vehicle orientations) without requiring projection onto perfectly frontal views.
Pearce和Pears(2011)评估了多种基于边缘特征的全局表示法:Canny边缘图像的连接像素,连接的SMG,连接的Harris角点响应和连接的局部标准化Harris强度(LNHS)。其中,级联的LNHS在准确性和速度方面对VMMR更为有效。 Saravi和Edirisinghe(2013)提出了局部能量形状直方图(LESH)特征与时间处理。感兴趣区域划分为16个子区域。从每个子区域,基于局部能量模型生成局部直方图。局部直方图的拼接被称为图像的LESH特征。但是,由于所有这些方法都需要整车ROI,因此它们都对遮挡敏感。 Varjas和Tanacs也使用连锁SMGs(2013)。He等人 (2015b)在应用基于高斯差分(DoG)的带通滤波器和平滑滤波器之后,将局部边缘和梯度特征串联成固定长度的数值向量。带通滤波器旨在消除高空间频率以降低噪音,并消除与汽车引擎盖和前照灯的区分区域相对应的低空间频率。在提取边缘或渐变之前,他们提出使用光照平衡和多尺度retinex(MSR)来取消隐藏深色或阴影覆盖区域的细节。 Baran等人(2013)发现,通过加权组合规则将边缘直方图(即边缘直方图(Salembier和Sikora,2002; Park等,2000))与SIFT和SURF描述符相结合,可以提高VMMR的准确性。大多数基于边缘和渐变的技术的一个主要局限是需要完全一致的ROI,严格的正面视图,或倾斜视图到正面视图的平面投影。然而,可接受的VMMR系统应该在广泛的视点或车辆方向)而不需要投影到完美的正面视图上。
An approach of combining shape and appearance descriptors has been proposed by Abdel-Maseeh et al. (2012). While global shape descriptors were used to correspond between visually discriminative parts of query images and manually-annotated parts of database images, local shape and appearance descriptors were used to describe these extracted discriminative parts. They used the Global Shape Context Descriptor (GSCD) (Belongie et al. 2002), Local Shape Descriptors (LSDs) (representing the pairwise distances and orientations of points in a local part), and Local Appearance Descriptor (LAD) (which is basically the application of DAISY descriptors (Winder et al. 2009)over FAST keypoints (Rosten et al. 2010)). The reliability of their approach is unclear, as they have used only sedan type vehicles and an unrealistic dataset in their experiments.
Abdel-Maseeh等人提出了一种结合形状和外观描述符的方法。(2012年)。 尽管使用全局形状描述符来对应查询图像的视觉区分部分和数据库图像的手动注释部分,但局部形状和外观描述符被用于描述这些提取的区分性部分。 他们使用了全局形状上下文描述符(GSCD)(Belongie等人2002),局部形状描述符(LSD)(表示局部部分中点的成对距离和方向)和局部外观描述符(LAD)(基本上 DAISY描述符(Winder et al.2009)在FAST关键点上的应用(Rosten et al。2010))。 他们的方法的可靠性尚不清楚,因为他们在实验中只使用轿车型车辆和不切实际的数据集。
The local features such as SURF have been used by Jang and Turk (2011) and Baran et al. (2013) to build a dictionary, which was then used to represent vehicle images by sparse vectors of occurrence counts of the dictionary words. M. Fraz and E. A. Edirisinghe and M. S. Sarfraz (2014) formed a lexicon composed of all the training images’ features as words. The words of the lexicon were computed based on Fisher Encoded Mid-Level-Representation (MLR) of image features such as SIFT. Their MLR construction was computationally expensive, reported to consume about 0.4s per image, and hence unsuitable for real-time VMMR. In contrast from these works, Siddiqui et al. (2015, 2016) proposed and investigated optimized dictionaries in the context of VMMR challenges, where the dictionary is learned by retaining only the dominant features of training images as codewords, and not all the features.
Jang and Turk(2011)和Baran等人(2013)使用SURF等局部特征去建立一个字典,然后用字典词的出现次数的稀疏向量表示车辆图像。 M. Fraz和E. A. Edirisinghe和M. S. Sarfraz(2014)构成了一个由所有训练图像的特征组成的词汇组成的词汇。 基于Fisher编码的中等表示(MLR)图像特征(例如SIFT)来计算词典的词语。 他们的MLR构造计算成本很高,据报道每个图像消耗大约0.4s,因此不适用于实时VMMR。 与这些作品相反,Siddiqui等人 (2015,2016)在VMMR挑战的背景下提出并研究了优化字典,其中字典是通过仅保留训练图像的主要特征作为码字来学习的,而不是所有的特征。
A grid-based global representation of features was proposed by Hsieh et al. (2014), in which the local features (SIFT or SURF) extracted from frontal vehicle faces were grouped in a grid-wise fashion. In their later work, Chen et al. (2015) proposed grid-based concatenation of HOG features from the vehicle images into a global ensemble representation. The grid-based schemes assume a fixed camera, and are prone to failures in cases where the camera height, pitch or yawmay change, resulting in different vehicle views (and hence different grid coverages) for which the system might not be trained. Zhang (2013) used Pyramid-HOG (PHOG) (Bosch et al. 2007) and Gabor wavelet transform to describe vehicle images. PHOG is an extension to HOG for encoding spatial information of an object’s image, following a spatial pyramid scheme to build a concatenated histogram as its global representation. On the other hand, a set of Gabor filters are applied on an image, the responses of which are used to build the image’s global representation vector to be used for classification. These Gabor filters are designed with different orientations and spatial frequencies, appropriately covering the spatial frequency domain.
Hsieh等人(2014)提出了基于网格的全局特征表示。 其中从正面车辆表面提取的局部特征(SIFT或SURF)以网格方式分组。在他们以后的工作中,Chen等人(2015)提出了基于网格的HOG特征从车辆图像连接成全局集合表示。基于网格的方案假定固定摄像机,并且在摄像机高度,俯仰或偏航可能改变的情况下容易出现故障,从而导致系统可能不被训练的不同车辆视图(并且因此不同的网格覆盖范围)。 Zhang(2013)使用Pyramid-HOG(PHOG)(Bosch et al.2007)和Gabor小波变换来描述车辆图像。 PHOG是HOG的扩展,用于编码对象图像的空间信息,遵循空间金字塔方案来构建连接直方图作为其全局表示。另一方面,在图像上应用一组Gabor滤波器,其中的响应用于构建图像的全局表示矢量以用于分类。这些Gabor滤波器设计有不同的方向和空间频率,适当覆盖空间频率域。
In recent years, researchers have initiated investigating deep learning and CNNs to address the VMMR problem. Instead of using hand-designed features, they leverage CNN to learn useful features. One such work is of Sochor et al. (2016) who proposed some modifications to the inputs fed into the net for enhanced accuracies in comparison to traditional CNN. Initially, a 3D bounding box enclosing the vehicle is detected in the 2D camera image, representing three faces: front/rear, side, and roof. The image regions within the 3D bounding box faces are “unpacked” onto a 2D planar image. The unpacked image is fed into the net early on as input. Another input is the encoded viewpoint, derived from the 3d bounding box orientation. The viewpoint is encoded by three 2D vectors, each connecting the bounding box’s center to the respective face’s center. In addition, the viewpoint encoding is done through bounding box rasterization, where each face is rasterized in a separate color channel (R/G/B). The rasterized bounding box and viewpoint encodings are fed into the net after the convolution layers.
近年来,研究人员开始研究基于深度学习和CNNs来解决VMMR问题。他们利用CNN学习有用的特征而不是人为设计特征。其中Sochor等人 (2016)采用了这种方式,与传统的CNN相比,他提出了一些修改输入到网络中的输入以提高精度。最初,在2D摄像机图像中检测到包围车辆的3D边界框,表示三个面:前/后,侧面和屋顶。 3D边界框面内的图像区域被“解包”到2D平面图像上。解压后的图像作为输入提前输入网络。另一个输入是来自三维边界框方向的编码视点。视点由三个2D矢量编码,每个2D矢量将边界框的中心连接到相应的脸部中心。另外,视点编码是通过边界框光栅化完成的,其中每个面在单独的颜色通道(R / G / B)中被光栅化。光栅化的边界框和视点编码在卷积层之后被送入网络。
Their experiments with different combinations of above-mentioned additional inputs revealed different levels of accuracy improvements in comparison to a baseline CNN. Best results were achieved with the following modifications to the baseline CNN: (1) unpacked image as input, without feeding in the rasterized bounding box and viewpoint encodings; and (2) unpacked image as input along with the rasterized bounding box and viewpoint encodings. Other modifications included adding rasterized bounding boxes (without viewpoint encodings) or adding viewpoint encodings (without rasterized bounding box), with the original vehicle image or with the unpacked image as input. Besides VMMR, the authors also achieved fine-grained classification and verification of vehicles’ sub-model and year.
他们对上述额外输入的不同组合进行的实验显示,与基线CNN相比,准确性提高程度不同。 通过对基线CNN进行以下修改,可以取得最佳效果:(1)将未打包的图像作为输入,不需要馈入栅格化边界框和视点编码; (2)作为输入的解压缩图像以及栅格化边界框和视点编码。 其他修改包括添加栅格化边界框(无视点编码)或添加视点编码(无栅格化边界框),原始车辆图像或未打包图像作为输入。 除VMMR外,作者还对车辆的子模型和年份进行了细粒度的分类和验证。
In a fine-grained classification problem such as VMMR, alignment of same class objects and discrimination between different classes is greatly aided by learning objects’ critical parts (Krause et al. 2015). To this end, Krause et al. (2015) propose an approach to learn a discriminative mixture of parts without depending on part annotations. A CNN is employed to extract features from the parts. Upon comparing two CNN architectures (CaffeNet (Jia et al. 2014) and VGGNet (Simonyan and Zisserman 2014)), they observed VGGNet yielding best results on the Cars-196 dataset (Krause et al. 2013).
在像VMMR这样的细粒度分类问题中,学习对象的关键部分极大地辅助了相同类对象的对齐和不同类别之间的区分(Krause等,2015)。 为此,Krause等人 (2015)提出了一种方法来学习不依赖于部分注释的有区别的混合部分。 CNN被用来从部件中提取特征。 通过比较两个CNN架构(CaffeNet(Jia et al。2014)和VGGNet(Simonyan and Zisserman 2014)),他们观察到VGGNet在Cars-196数据集上获得了最佳结果(Krause et al。2013)。
Another deep-learning framework is proposed by Xie et al. (2015). It employs attributes-based (Farhadi et al. 2009; Lampert et al. 2009; Wang and Mori 2010) and multi-task learning (Caruana 1997) combined with information sharing. They proposed a data augmentation method to address the issue of data scarcity, to avoid overfitting problems in training deep CNNs. The fine-grained data is augmented by a large number of hyper-class labelled auxiliary images. The “inherent attributes of fine-grained data,” which are easy to annotate, are taken as the hyper-class labels. One hyper-class label considered is the super-type of the classes (e.g., “cars”). The other hyper-class considered is related to the vehicle’s pose (or viewpoint) in the image, referred to as “factor-type hyper-class,” since pose is a hidden-factor of an image.
Xie等人(2015年)提出了另一种深度学习框架。 它采用基于属性的方法(Farhadi et al。2009; Lampert et al。2009; Wang and Mori 2010)和多任务学习(Caruana 1997)并结合信息共享。 他们提出了一种数据增强方法来解决数据稀缺问题,以避免在深度CNN训练中出现过拟合问题。 细粒度数据通过大量超级标记的辅助图像进行增强。 “细粒度数据的固有属性”易于注释,被视为超类标签。 考虑的一个超类标签是类的超类型(例如“汽车”)。 考虑到的另一个超级类别与图像中的车辆姿态(或视点)有关,称为“因子型超级”,因为姿态是图像的隐藏因子。
Although CNN-based approaches seem to be a promising direction to investigate further, especially with regards to achieving extremely fine-grained classification (make +model + sub-model + year), they are computationally very expensive and challenging to tune. Further investigations are needed to enhance their performance under challenging conditions of occlusions, weather, and so on. Table 3 summarizes the features extraction and global representation techniques used in representative VMMR works.
虽然基于CNN的方法似乎是进一步研究的一个有希望的方向,尤其是在实现极细粒度分类(make + model + sub-model + year)方面,它们在计算上非常昂贵并且难以调整。 需要进一步调查,以在闭塞,天气等挑战性条件下提高其性能。 表3总结了代表性VMMR作品中使用的特征提取和全局表示技术。
5.2 Classification Approaches
In the literature, various classification approaches have been proposed for VMMR using the local features, global features representations of the make-model classes, or both. A summary of classifiers used in the most representative of such works is given in Table 4 (the feature extraction and global representation approaches used in these works have previously been given in Table 3). Many works, such as Petrovic and Cootes (2004b), Munroe and Madden (2005), Dlagnekov (2005), Zafar et al. (2007), Clady et al. (2008), Zafar et al. (2009), Pearce and Pears (2011), AbdelMaseeh et al. (2012), and He et al. (2015b), explored NN classifiers based on a simple brute-force matching scheme using local features, or their global representations, to match query images to the gallery images. A k-NN-based classification scheme was also used by Varjas and Tanacs (2013), but with a correlation-based distance metric. The brute-force pattern matching approach is very time consuming, and hence not suitable for real-time VMMR. In addition to NN, Munroe and Madden (2005) also used machine learning algorithms such as C4.5 Decision Trees and Feed-forward Neural Networks as classifiers for VMMR. Other works that used Neural Networks include (Lee 2006; Psyllos et al. 2011). He et al. (2015b) built an ensemble of neural networks for classification. However, such approaches based on edges from images suffer severely in cases of occlusions, and hence are not applicable to real-life scenarios.
在文献中,已经针对使用局部特征,制造模型类的全局特征表示或两者的VMMR提出了各种分类方法。表4中给出了最具代表性的这类作品中使用的分类器的总结(这些作品中使用的特征提取和全局表示方法以前已在表3中给出)。许多作品,如Petrovic和Cootes(2004b),Munroe和Madden(2005),Dlagnekov(2005),Zafar等人。 (2007),Clady等人(2008),Zafar等人(2009年),Pearce和Pears(2011年),AbdelMaseeh等人(2012)和He等人(2015b),基于使用局部特征或其全局表示的简单蛮力匹配方案探索NN分类器,以将查询图像匹配到图库图像。 Varjas和Tanacs(2013)也使用基于k-NN的分类方案,但是采用基于相关的距离度量。蛮力模式匹配方法非常耗时,因此不适用于实时VMMR。除NN之外,Munroe和Madden(2005)还使用机器学习算法,如C4.5决策树和前馈神经网络作为VMMR的分类器。其他使用神经网络的作品包括(Lee 2006; Psyllos et al.2011)。He等人 (2015b)建立了用于分类的神经网络集合。然而,基于图像边缘的这种方法在遮挡情况下受到严重影响,因此不适用于真实场景。
In Pearce and Pears (2011), Naive Bayes classifiers were tested with a variety of features. In their approach, the accuracy could degrade when ROIs are even slightly different than ground truth ROIs. The classification scheme adopted by M. Fraz et al. (2014) included matching a probe image’s words with the gallery of lexicons in a brute-force manner, assigning the best matching lexicon’s class as the predicted class. Such an exhaustive matching scheme rendered their approach inapplicable to real-time VMMR systems. A 2-stage cascade classifier ensemble was proposed in Zhang (2013). In the first ensemble, classifiers such as k-NN, Multi-Layer Perceptron (MLP), Random Forest (RF), and SVM were employed. The second ensemble employed a Rotation Forest of MLPs. However, incorporating so many classifiers greatly decreased the processing speed, making the methods inapplicable to real-time VMMR systems.
在Pearce和Pears(2011)中,朴素贝叶斯分类器测试了各种功能。 在他们的方法中,当感兴趣区域甚至与实际感兴趣区域略有不同时,准确性可能会降低。 M.Fraz等人采用的分类方案 (2014年)包括以蛮力的方式将探索图像的词语与词典库匹配,将最佳匹配词典的类别指定为预测类别。 这种详尽的匹配方案使其不适用于实时VMMR系统。 Zhang(2013)提出了一个2级级联分类器集成。 在第一个集合中,采用了诸如k-NN,多层感知器(MLP),随机森林(RF)和SVM等分类器。 第二个乐团采用了MLP的旋转森林。 然而,纳入如此多的分类器大大降低了处理速度,使得该方法不适用于实时VMMR系统。
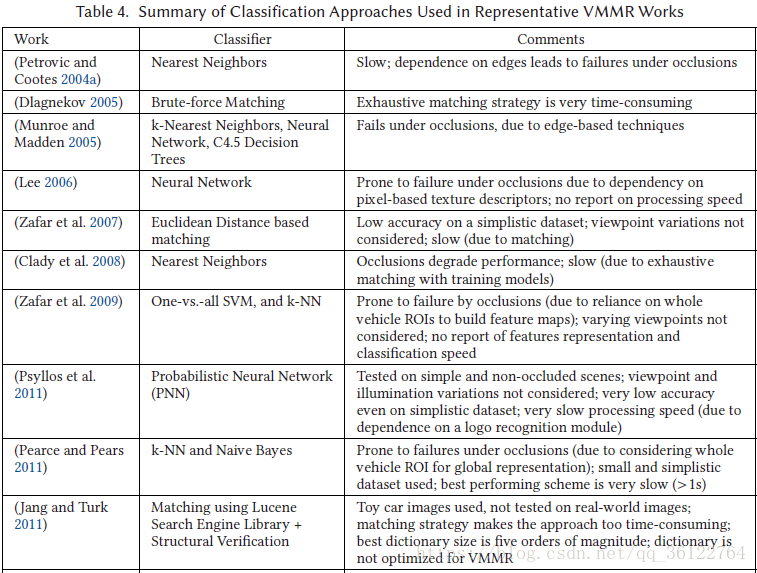
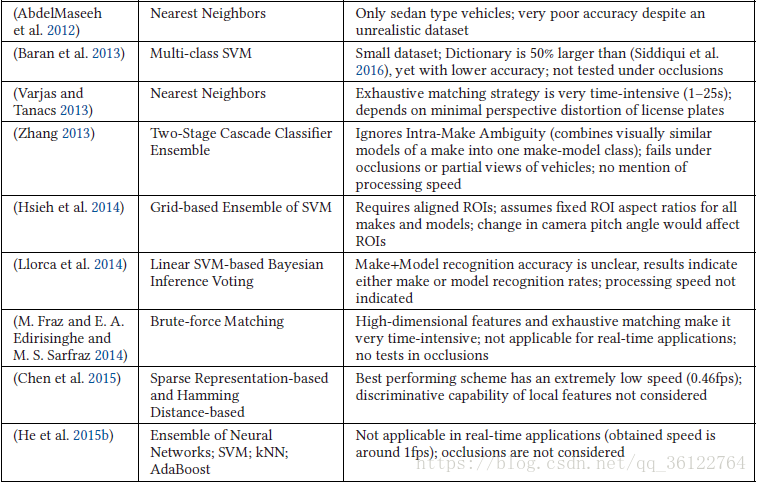
Baran et al. (2013) utilized a simple multi-class SVM trained over the sparse occurrence vectors. However, they did not investigate optimizing the dictionaries for VMMR as did (Siddiqui 2015), who achieved higher accuracy rates with a dictionary that was half the size. On the other hand, Jang and Turk (2011) applied an image retrieval approach using the Lucene Search Engine library to retrieve matching vehicle images, followed by Structural Verification to narrow down the list of matched images. Unlike them, Siddiqui et al. (2016) proposed a global representation for VMMR based on the Bag-of-Features paradigm (Sivic and Zisserman 2003; Csurka et al. 2004) with optimized dictionaries and two SVM-based classification schemes that were designed to solve VMMR issues. Hsieh et al. (2014) employ a grid-wise ensemble of SVM classifiers, each of which is trained over SURF features from a specific grid-block over frontal vehicle faces. Other works using SVMbased classifiers include (Zafar et al. 2009; He et al. 2015b). In Llorca et al. (2014), Bayesian Inference Voting was used based on linear SVM. AdaBoost was also tested in the context of VMMR in He et al. (2015b). An ensemble of classifiers was also proposed by Boonsim and Prakoonwit (2016) who employed geometrical and shape features based on tail-lights and LPs (e.g., aspect ratios between each tail-light’s width and LP’s width, tail-light shape grid, etc.). Their ensemble consisted of oneclass SVM, Decision Tree, and kNN classifiers with majority voting. On the other hand, Chen et al. (2013, 2015) proposed a classification approach for VMMR, based on Sparse Representation and Hamming Distance.
Baran等人(2013)利用简单的多类SVM对稀疏发生向量进行训练。然而,他们并没有像对待VMMR字典那样进行优化(Siddiqui 2015),他们使用的字典大小只有一半,从而实现了更高的准确率。另一方面,Jang和Turk(2011)应用了使用Lucene搜索引擎库的图像检索方法来检索匹配的车辆图像,然后使用结构验证来缩小匹配图像的列表。与他们不同,Siddiqui等人(2016)提出了基于袋特征范例(Sivic和Zisserman 2003; Csurka等人2004)的VMMR的全球代表,其中包含优化词典和两个基于SVM的分类方案,这些分类方案旨在解决VMMR问题。 Hsieh等人(2014)采用SVM分类器的网格方式集成,每个分类器都通过正面车辆面上的特定网格块对SURF特征进行训练。其他使用基于SVM的分类器的工作包括(Zafar等,2009; He等,2015b)。Llorca等人(2014)基于线性SVM使用贝叶斯推理投票。 AdaBoost也在He等人(2015B)的VMMR中进行了测试。 Boonsim和Prakoonwit(2016)也提出了一系列分类器,他们使用基于尾灯和LP的几何和形状特征(例如,每个尾灯宽度与LP宽度,尾灯形状网格等之间的高宽比)。它们的集合由一类支持向量机,决策树和多数投票的kNN分类器组成。另一方面,陈等人(2013,2015)提出了一种基于稀疏表示和汉明距离的VMMR分类方法。
In the CNN-based works, Xie et al. (2015) proposed a deep CNN model to address the high intraclass variance and low inter-class variance (ambiguity) issues. The key difference of their learning approach is the utilization of hyper-class augmented data and regularization between hyper-class classifiers and fine-grained classifiers. The authors obtained better accuracies with their Hyperclass Augmented CNN (HA-CNN) and Hyperclass Augmented Regularized CNN (HAR-CNN) models (which were trained from scratch on the relatively small-scale target data) in comparison to CNN-based works, which employ nets pre-trained on other large-scale generic dataset. This indicates that features learned from generic large-scale datasets (such as ImageNet (Russakovsky et al. 2015)) may not always be suitable for a specific fine-grained classification task such as VMMR. Moreover, even better accuracies were achieved when the HA-CNN and HAR-CNN models were not trained from scratch, but used a pre-trained model followed by fine-tuning on target data. Other works such as Krause et al. (2015) built a classifier based on the max-margin template selection scheme of Chen et al. (2014). In Sochor et al. (2016), while the CNN model was directly used for classification, they employed a cosine distance-based method for vehicle “verification.”
在CNN的作品中,Xie等人(2015)提出了一个深度的CNN模型来解决高的组内差异和低的组间差异(模糊性)问题。他们的学习方法的主要区别在于利用超类增广数据和超类分类器与细粒度分类器之间的正则化。作者使用超级增强型CNN(HA-CNN)和超级增强型正则化CNN(HAR-CNN)模型(相对较小规模的目标数据从零开始进行了培训)获得了更高的精度,与CNN作品相比,使用在其他大型通用数据集上预先训练的网络。这表明从通用大规模数据集(如ImageNet(Russakovsky et al。2015))获得的特征可能并不总是适用于特定的细粒度分类任务,如VMMR。此外,HA-CNN和HAR-CNN模型不是从头开始培训,而是使用预先训练的模型,然后对目标数据进行微调,甚至可以获得更高的精度。其他作品,如克劳斯等人 (2015)基于Chen等人(2014)的最大边缘模板选择方案构建了一个分类器。 Sochor等人(2016)用CNN模型直接用于分类,他们采用基于余弦距离的方法进行车辆“验证”。
While most works discussed above present their results by testing classifiers on dataset(s) of limited number of known classes (i.e., classes that have been seen in training), it is important to observe how an AVC system would deal with vehicles of classes not included in training. To this end, a few works such as Kafai and Bhanu (2012) and Chen et al. (2012a) have incorporated a “null” or “unknown” class. A rejection option such as one from Li and Jain (2005) is applied in works such as Saravi and Edirisinghe (2013) and Chen et al. (2015) to reject a classifier prediction if it doesn’t meet certain criteria and to assign the test image to “unknown” class. The idea is not only to see how well a classifier can classify known vehicle classes, but also to see how well it is able to distinguish unknown vehicle classes from those that it has seen in training.
虽然上面讨论的大部分工作都是通过对有限数量的已知类别(即在培训中已经看到的类别)的数据集测试分类器来得出结果,但重要的是要观察AVC系统如何处理类别的车辆 包括在培训中。 为此,一些作品如Kafai和Bhanu(2012)和Chen等人 (2012a)已纳入“空”或“未知”类。 诸如来自Li和Jain(2005)的拒绝选项被应用于诸如Saravi和Edirisinghe(2013)和Chen等人的作品中。 (2015)拒绝分类器预测,如果它不符合某些标准并且将测试图像分配给“未知”类。 这个想法不仅仅是要看分类器能够对已知的车辆类别进行分类,还能够看到它能够将未知的车辆类别与它在训练中看到的类别区分开来。
Instead of having a separate class for “unknown” vehicles, some works employ an additional module of “Vehicle Verification” besides the classification module. Vehicle verification finds its use in tracking vehicles in multi-camera networks, as a complement to license-plate-based systems. Moreover, it can be applied in retrieval of similar vehicles from recorded footage or images, for example, in post-event investigations. An example of vehicle verification works is Sochor et al. (2016). Given a pair of vehicle images, the verification module compares their features and decides if they belong to the same class or different ones. The authors have collected a dataset of pairs of vehicle images such that one of the images in a pair is from a class that was not considered in training. Another work in this regard is by Yang et al. (2015), which uses CNN-based features with two classifiers: (i) Joint Bayesian and (ii) SVM. The former was found to yield better results than the latter. However, there still remains a lot of room for improvement of accuracies in vehicle verification. Although vehicle verification is an interesting and challenging problem, it has been an under-researched direction, unlike human face verification (Sun et al. 2014).
除了分类模块之外,有些工程不使用“未知”车辆的单独类别,而是使用“车辆验证”的附加模块。车辆验证可用于跟踪多摄像机网络中的车辆,作为对基于车牌的系统的补充。此外,它可以应用于从记录的镜头或图像中检索类似的车辆,例如在事件后调查中。车辆验证工作的一个例子是Sochor等人 (2016)。给定一对车辆图像,验证模块比较它们的特征并确定它们是属于同一类还是不同类。作者收集了一对车辆图像的数据集,以便一对图像中的一幅来自未经过训练考虑的类别。杨等人在这方面的另一项工作。 (2015),它使用基于CNN的特征和两个分类器:(i)联合贝叶斯和(ii)SVM。前者被发现比后者产生更好的结果。但是,车辆验证的准确性仍有很大提高空间。虽然车辆验证是一个有趣且具有挑战性的问题,但与人脸验证不同,它一直是一个研究不足的方向(Sun et al.2014)。
Although several works have been published on the theme of VMMR, there are several challenges and issues yet to be addressed. Most of the prior works were based on datasets that failed to fairly represent multiplicity and ambiguity issues. A majority of the works hardly meet realtime constraints. The multiplicity and ambiguity problems need to be tackled, perhaps through more representative and discriminative global features representations and enhanced classification techniques. The limitations of VMMR works reviewed in this section are summarized in the third column of Table 4.
尽管已经发表了几篇关于VMMR主题的文章,但还有几个挑战和问题需要解决。 以前的大部分作品都是基于不能很好地表示多重性和模糊性问题的数据集。 大部分作品难以满足实时限制。 需要解决多重性和模糊性问题,可能是通过更具代表性和区别性的全局特征表示和增强的分类技术。 表4的第三列总结了本节回顾的VMMR工作的局限性。