7.15 7.15 7.15 前还在搞文化课,错过了前两场,现在回来补qwq。
然而很多题并不会。
文章目录
A. B-Suffix Array
给出一个字符串,定义一个字符串 s 1 s_1 s1 ~ s m s_m sm 对应的 B 1 B_1 B1 ~ B m B_m Bm 满足 B i = min 1 ≤ j < i , s j = s i { i − j } B_i=\min_{1\leq j < i,s_j=s_i}\{i-j\} Bi=min1≤j<i,sj=si{ i−j},如果不存在这样的 j j j,那么 B i = 0 B_i=0 Bi=0,现在要求将 s s s 的所有后缀按照其对应的 B B B 序列的字典序排列。
牛客那篇似乎是唯一的题解就是我发的qwq
题解很神,用到一个神仙结论直接切飞,原文为(为了好看些,我自己稍微加了点 LaTeX 元素):
Let C i = m i n i < j ≤ n , s j = s i { j − i } C_i = min_{i<j\leq n,s_j=s_i} \{j-i\} Ci=mini<j≤n,sj=si{ j−i}
The B-Suffix Array is equivalent to the suffix array of C 1 C 2 . . . C n C_1~C_2~...~C_n C1 C2 ... Cn
有了这个结论,加一点代码实现细节,就可以 A C AC AC 这题。
这里先讲做法,再讲证明。
对于不存在这样的 j j j 的 C i C_i Ci,我们要让他比其他 C i C_i Ci 都大,设为 C i = n C_i=n Ci=n,然后最后再放一个 n + 1 n+1 n+1 在 C C C 的末尾,最后求出 C C C 的后缀数组,去掉最后一位倒着输出就是答案。
代码如下:
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
#define maxn 1000010
int n,s[maxn];char S[maxn];
int fir[maxn],sec[maxn],sa[maxn],c[maxn];
void get_SA()
{
int m=n;
for(int i=1;i<=n;i++)c[fir[i]=s[i]]++;
for(int i=2;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i>=1;i--)sa[c[fir[i]]--]=i;
for(int k=1,tot;k<n;k<<=1)
{
tot=0;
for(int i=n-k+1;i<=n;i++)sec[++tot]=i;
for(int i=1;i<=n;i++)if(sa[i]>k)sec[++tot]=sa[i]-k;
for(int i=1;i<=m;i++)c[i]=0;
for(int i=1;i<=n;i++)c[fir[i]]++;
for(int i=2;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i>=1;i--)sa[c[fir[sec[i]]]--]=sec[i];
for(int i=1;i<=n;i++)swap(fir[i],sec[i]);
fir[sa[1]]=tot=1;
for(int i=2;i<=n;i++)
if(sec[sa[i]]==sec[sa[i-1]]&&sec[sa[i]+k]==sec[sa[i-1]+k])fir[sa[i]]=tot;
else fir[sa[i]]=++tot;
if(tot==n)break; m=tot;
}
}
int main()
{
while(~scanf("%d",&n))
{
scanf("%s",S+1);
for(int i=1;i<=n;i++){
for(int j=i+1;j<=n;j++)if(S[j]==S[i]){
s[i]=j-i;break;}
if(!s[i])s[i]=n;
}
n++;s[n]=n;get_SA();
for(int i=n-1;i>=1;i--)printf("%d ",sa[i]);printf("\n");
for(int i=1;i<=n;i++)s[i]=fir[i]=sec[i]=sa[i]=c[i]=0;
}
}
证明:
首先对 B B B 和 C C C 要有一点感性的认识, B i B_i Bi 相当于前面最近的一个与 s i s_i si 相同的字符到 i i i 的距离,而 C i C_i Ci 相当于后面的最近的与 s i s_i si 相同的字符到 i i i 的距离。
对于第 i i i 个位置,假设位置 j j j 是后面的最近的相同字符,那么可以发现, B j = C i B_j=C_i Bj=Ci,也就是说,将 B B B 左移一位 就能得到 C C C,这里的左移一位就是将 B i B_i Bi 放到上一个与 s i s_i si 字符相同的位置。
考虑一个特殊的情况。
对于一个后缀,考虑 B B B 数组开头的一段,肯定是这样的:
0 1 1 1 0 . . . 0~1~1~1~0~... 0 1 1 1 0 ...
那两个 0 0 0 就是第一次出现的 a a a 和 b b b 字符,因为他们没有上一个相同的字符。
考虑两个 0 0 0 中间 1 1 1 序列的长度,他的长度越长,字典序就会越大,例如这两个 B B B 数组:
0 1 1 1 0 . . . 0 1 1 0 . . . 0~1~1~1~0~...\\ 0~1~1~0~...~~~ 0 1 1 1 0 ...0 1 1 0 ...
显然下面那个字典序要大,因为第四位它是 0 0 0 而上面那个是 1 1 1。
然后考虑他们对应的 C C C 数组,是长这样的:
1 1 1 x 1 . . . 1 1 y 1 . . . 1~1~1~x~1~...\\ 1~1~y~1~...~~~ 1 1 1 x 1 ...1 1 y 1 ...
其中, x , y x,y x,y 都大于 1 1 1。
此时可以发现,上面那个的字典序反而要小了。
也就是说,对于开头的一段 1 1 1 长度不同的两个后缀,如果 X X X 的 B B B 比 Y Y Y 的 B B B 字典序要小,那么 X X X 的 C C C 一定比 Y Y Y 的 C C C 的字典序要大。
再考虑一般情况。
假设两个后缀 X , Y X,Y X,Y 的 B B B 序列有一段前缀是相同的,那么 X , Y X,Y X,Y 的这一段前缀肯定也是相同的,不妨设这段前缀以若干个 a a a 结尾,那么对于第一个不同的位,肯定满足一个后缀的这一位是 a a a,另一个后缀的这一位是 b b b,像这样:
. . . a a a a b . . . . . . a a b . . . ...aaaab...\\ ...aab...~~~~ ...aaaab......aab...
第一个不同的位是这一段中的第三位,然后他们对应的 B B B 序列就是:
. . . a a a a b . . . . . . 1111 x . . . . . . a a b . . . . . . 11 y . . . ...aaaab...\\ ...1111x...\\ ...aab...~~~~\\ ...11y...~~~~ ...aaaab......1111x......aab... ...11y...
第三位的 1 1 1 比 y y y 小,所以后缀 X X X 的 B B B 的字典序比后缀 Y Y Y 的 B B B 的字典序要小。
再考虑他们的 C C C 序列,也就是将 B B B 左移一位,由于他们 B B B 序列的前面部分都是相同的,所以上一个 b b b 出现的位置是相同的,左移一位后 x x x 和 y y y 就会同时移到那个位置,像这样:
b b b a a . . . 11 x 11... b b b a a . . . 11 y 11... bbbaa...\\ 11x11...\\ bbbaa...\\ 11y11... bbbaa...11x11...bbbaa...11y11...
然后你可以发现,在 x , y x,y x,y 之前的位都是相同的,也就是说, x , y x,y x,y 之间的大小比较决定了这两个后缀的字典序。
观察一开始 x , y x,y x,y 的位置,可以发现 x x x 那个位置离上一个 b b b 要更远一些,即满足 x > y x>y x>y,所以此时 X X X 的 C C C 的字典序比 Y Y Y 的 C C C 的字典序要大。
综合上述两种情况,可以知道,对于两个后缀 X , Y X,Y X,Y,假如 X X X 的 B B B 的字典序比 Y Y Y 的 B B B 的字典序要小,那么总有 X X X 的 C C C 的字典序比 Y Y Y 的 C C C 的字典序要大。
所以,求出 C C C 的后缀数组再反过来就是答案。
证毕。
仔细思考,可以发现这个 C C C 相对于 B B B 的优越性就在于:一个后缀的 C C C 一定是 整个序列的 C C C 的 一段后缀,并且这两个后缀的位置是相对应的,所以将 C C C 求出后缀数组,就相当于将原字符串的后缀进行排序了。而 B B B 不一样,对于每个后缀,他的 B B B 不一定是 整个序列的 B B B 的 一段后缀,所以不能直接上后缀排序。
再讲一个细节,就是为什么末尾要放一个 n + 1 n+1 n+1。
假如末尾是 a b ab ab 的话,就对应两个后缀: a b ab ab 和 b b b,他们的 B B B 数组分别为 00 00 00 和 0 0 0,所以 b b b 的 B B B 的字典序比 a b ab ab 的小,那么 b b b 应该排在 a b ab ab 前面。
而注意到我们最后是要将 C C C 的 s a sa sa 数组反过来的,也就是说,反过来之前, b b b 的 C C C 应该比 a b ab ab 的要大。
但是事实上他们的 C C C 分别为 n n n 和 n n nn nn, b b b 的 C C C 是要比 a b ab ab 的 C C C 小的,而在末尾加一个 n + 1 n+1 n+1 就可以避免这个问题,具体可以结合样例的第三组数据理解。
B. Infinite Tree
令 m i n d i v ( i ) mindiv(i) mindiv(i) 为 i i i 的最小值因子,让点 i i i 与点 i m i n d i v ( i ) \frac i {mindiv(i)} mindiv(i)i 连边,设 δ ( i , j ) \delta(i,j) δ(i,j) 为树中 i , j i,j i,j 两点间的距离,现在要你找到一个 u u u,使 ∑ i = 1 n w i δ ( u , i ! ) \sum_{i=1}^n w_i \delta(u,i!) ∑i=1nwiδ(u,i!) 最小。
显然,我们不需要造出整棵树,只需要造出与 1 ! , 2 ! , 3 ! , . . . , n ! 1!,2!,3!,...,n! 1!,2!,3!,...,n! 相关的部分即可。
先不管怎么造这棵树,假设我们现在有这棵树。
先令 u = 1 u=1 u=1,然后逐步往下走。设 s u m i sum_i sumi 为子树内所有点的 w w w 之和,假如往儿子 v v v 走更优,即令 u = v u=v u=v 更优,需要满足 s u m 1 − s u m v < s u m v sum_1-sum_v<sum_v sum1−sumv<sumv,因为从 u u u 走到 v v v 时, v v v 子树内的点到 u u u 的距离减少了 1 1 1,而其他点到 u u u 的距离增加了 1 1 1,要使得走了这步后更优,就需要满足上面的不等式,即 s u m 1 − 2 s u m v < 0 sum_1-2sum_v<0 sum1−2sumv<0。
显然,对于点 u u u,他只有至多一个儿子能满足这个不等式,因为这个不等式等价于 s u m v > s u m 1 2 sum_v>\dfrac {sum_1} 2 sumv>2sum1,显然不可能有两个儿子同时满足,所以从点 1 1 1 出发,往下走的路径是唯一的。
然后就是要考虑怎么造这棵树,我们注意到,树上有很多点,他们不等于任意一个 i ! i! i!,只是在某个 i ! i! i! 到根节点的路径上,假如某个这种点只有一个儿子,那么这个点其实是对决策没有贡献的,所以,可以考虑建出它的虚树,然后在虚树上跑上面的过程。
考虑 i ! i! i! 和 ( i + 1 ) ! (i+1)! (i+1)! 的 l c a lca lca 是谁。对于一条 i i i 与 i m i n d i v ( i ) \frac i {mindiv(i)} mindiv(i)i 的边,假如将 m i n d i v ( i ) mindiv(i) mindiv(i) 作为权值放到边上,观察根节点 1 ! 1! 1! 到点 i ! i! i! 的路径,经过的边权是严格不上升的,也就是会先经过 i ! i! i! 的较大的质因子。而 ( i + 1 ) ! (i+1)! (i+1)! 比 i ! i! i! 多乘了个 i i i,也就是说, i + 1 i+1 i+1 的最大的质因子会使得 1 ! 1! 1! 到 i ! i! i! 和 ( i + 1 ) ! (i+1)! (i+1)! 的路径分叉,而这个分叉点就是要求的 l c a lca lca。
于是可以用树状数组维护之前 i ! i! i! 的各个质因子的出现次数,然后统计不小于 i + 1 i+1 i+1 的最大质因子的质因子个数,就能得到 l c a lca lca 的深度,然后就可以建虚树了。
代码如下:
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
#define maxn 200010
#define ll long long
int n,w[maxn];ll ans=0;
int mindiv[maxn];void work(){
for(int i=2;i<=maxn-10;i++)
for(int j=i;j<=maxn-10;j+=i)
if(!mindiv[j])mindiv[j]=i;
}
int d[maxn],lcad[maxn],zhan[maxn],t=0;
struct edge{
int y,next;}e[maxn<<1];
int first[maxn],len=0,tr[maxn];
void buildroad(int x,int y){
e[++len]=(edge){
y,first[x]};first[x]=len;}
void add(int x){
for(;x<=n;x+=(x&-x))tr[x]++;}
int sum(int x){
int re=0;for(;x>=1;x-=(x&-x))re+=tr[x];return re;}
void buildtree()
{
for(int i=2;i<=n;i++)
{
d[i]=d[i-1]+1;int j=i;
for(;j!=mindiv[j];j/=mindiv[j])d[i]++;
lcad[i]=sum(n)-sum(j-1);
for(j=i;j>1;j/=mindiv[j])add(mindiv[j]);
}
zhan[t=1]=1;for(int i=2,tot=n;i<=n;i++){
while(t>1&&d[zhan[t-1]]>=lcad[i])buildroad(zhan[t-1],zhan[t]),t--;
if(d[zhan[t]]!=lcad[i])d[++tot]=lcad[i],buildroad(tot,zhan[t]),zhan[t]=tot;
zhan[++t]=i;
}
while(t>1)buildroad(zhan[t-1],zhan[t]),t--;
}
void dfs1(int x){
ans+=1ll*w[x]*d[x];
for(int i=first[x];i;i=e[i].next)
dfs1(e[i].y),w[x]+=w[e[i].y];
}
void dfs2(int x){
for(int i=first[x];i;i=e[i].next)
if(2*w[e[i].y]>w[1])ans+=1ll*(w[1]-2*w[e[i].y])*(d[e[i].y]-d[x]),dfs2(e[i].y);
}
void init(){
len=ans=0;for(int i=1;i<=2*n;i++)first[i]=d[i]=lcad[i]=w[i]=tr[i]=0;}
int main()
{
work();while(~scanf("%d",&n)){
for(int i=1;i<=n;i++)scanf("%d",&w[i]);
buildtree();dfs1(1);dfs2(1);
printf("%lld\n",ans);init();
}
}
G. BaXianGuoHai,GeXianShenTong
给出 n n n 个三维向量 s s s,现在重新定义向量的乘法: x ⃗ ( a 1 , a 2 , a 3 ) × y ⃗ ( b 1 , b 2 , b 3 ) = ( ( a 1 b 1 + a 2 b 3 + a 3 b 2 ) , ( a 2 b 1 + a 3 b 3 + a 1 b 2 ) , ( a 3 b 1 + a 2 b 3 + a 1 b 2 ) ) \vec x(a_1,a_2,a_3)\times \vec y(b_1,b_2,b_3)=(~(a_1b_1+a_2b_3+a_3b_2)~,~(a_2b_1+a_3b_3+a_1b_2)~,~(a_3b_1+a_2b_3+a_1b_2)~) x(a1,a2,a3)×y(b1,b2,b3)=( (a1b1+a2b3+a3b2) , (a2b1+a3b3+a1b2) , (a3b1+a2b3+a1b2) ),现在有 q q q 次询问,第 i i i 次询问询问给出 e i , 1 e_{i,1} ei,1 ~ e i , n e_{i,n} ei,n,求出 s 1 e i , 1 × s 2 e i , 2 × . . . × s n e i , n s_1^{e_{i,1}}\times s_2^{e_{i,2}}\times ...\times s_n^{e_{i,n}} s1ei,1×s2ei,2×...×snei,n。
仔细观察,发现这个乘法是满足结合律的,证明如下(其实就是暴力算):
设 x ⃗ ( a 1 , a 2 , a 3 ) , y ⃗ ( b 1 , b 2 , b 3 ) , z ⃗ ( c 1 , c 2 , c 3 ) \vec x(a_1,a_2,a_3),\vec y(b_1,b_2,b_3),\vec z(c_1,c_2,c_3) x(a1,a2,a3),y(b1,b2,b3),z(c1,c2,c3),假如按顺序计算,就有:
x ⃗ × y ⃗ = ( ( a 1 b 1 + a 2 b 3 + a 3 b 2 ) , ( a 2 b 1 + a 3 b 3 + a 1 b 2 ) , ( a 3 b 1 + a 1 b 3 + a 2 b 2 ) ) \vec x\times \vec y=(~(a_1b_1+a_2b_3+a_3b_2)~,~(a_2b_1+a_3b_3+a_1b_2)~,~(a_3b_1+a_1b_3+a_2b_2)~) x×y=( (a1b1+a2b3+a3b2) , (a2b1+a3b3+a1b2) , (a3b1+a1b3+a2b2) )
( x ⃗ × y ⃗ ) × z ⃗ = ( (\vec x\times \vec y)\times \vec z=( (x×y)×z=(
( a 1 b 1 c 1 + a 2 b 3 c 1 + a 3 b 2 c 1 + a 2 b 1 c 3 + a 3 b 3 c 3 + a 1 b 2 c 3 + a 3 b 1 c 2 + a 1 b 3 c 2 + a 2 b 2 c 2 ) , (a_1b_1c_1+a_2b_3c_1+a_3b_2c_1+a_2b_1c_3+a_3b_3c_3+a_1b_2c_3+a_3b_1c_2+a_1b_3c_2+a_2b_2c_2), (a1b1c1+a2b3c1+a3b2c1+a2b1c3+a3b3c3+a1b2c3+a3b1c2+a1b3c2+a2b2c2),
( a 2 b 1 c 1 + a 3 b 3 c 1 + a 1 b 2 c 1 + a 3 b 1 c 3 + a 1 b 3 c 3 + a 2 b 2 c 3 + a 1 b 1 c 2 + a 2 b 3 c 2 + a 3 b 2 c 2 ) , (a_2b_1c_1+a_3b_3c_1+a_1b_2c_1+a_3b_1c_3+a_1b_3c_3+a_2b_2c_3+a_1b_1c_2+a_2b_3c_2+a_3b_2c_2), (a2b1c1+a3b3c1+a1b2c1+a3b1c3+a1b3c3+a2b2c3+a1b1c2+a2b3c2+a3b2c2),
( a 3 b 1 c 1 + a 1 b 3 c 1 + a 2 b 2 c 1 + a 1 b 1 c 3 + a 2 b 3 c 3 + a 3 b 2 c 3 + a 2 b 1 c 2 + a 3 b 3 c 2 + a 1 b 2 c 2 ) ) (a_3b_1c_1+a_1b_3c_1+a_2b_2c_1+a_1b_1c_3+a_2b_3c_3+a_3b_2c_3+a_2b_1c_2+a_3b_3c_2+a_1b_2c_2)) (a3b1c1+a1b3c1+a2b2c1+a1b1c3+a2b3c3+a3b2c3+a2b1c2+a3b3c2+a1b2c2))
先计算后两者,则有:
y ⃗ × z ⃗ = ( ( b 1 c 1 + b 2 c 3 + b 3 c 2 ) , ( b 2 c 1 + b 3 c 3 + b 1 c 2 ) , ( b 3 c 1 + b 1 c 3 + b 2 c 2 ) ) \vec y\times \vec z=(~(b_1c_1+b_2c_3+b_3c_2)~,~(b_2c_1+b_3c_3+b_1c_2)~,~(b_3c_1+b_1c_3+b_2c_2)~) y×z=( (b1c1+b2c3+b3c2) , (b2c1+b3c3+b1c2) , (b3c1+b1c3+b2c2) )
x ⃗ × ( y ⃗ × z ⃗ ) = ( \vec x\times (\vec y \times \vec z)=( x×(y×z)=(
( a 1 b 1 c 1 + a 1 b 2 c 3 + a 1 b 3 c 2 + a 2 b 3 c 1 + a 2 b 1 c 3 + a 2 b 2 c 2 + a 3 b 2 c 1 + a 3 b 3 c 3 + a 3 b 1 c 2 ) , (a_1b_1c_1+a_1b_2c_3+a_1b_3c_2+a_2b_3c_1+a_2b_1c_3+a_2b_2c_2+a_3b_2c_1+a_3b_3c_3+a_3b_1c_2), (a1b1c1+a1b2c3+a1b3c2+a2b3c1+a2b1c3+a2b2c2+a3b2c1+a3b3c3+a3b1c2),
( a 2 b 1 c 1 + a 2 b 2 c 3 + a 2 b 3 c 2 + a 3 b 3 c 1 + a 3 b 1 c 3 + a 3 b 2 c 2 + a 1 b 2 c 1 + a 1 b 3 c 3 + a 1 b 1 c 2 ) , (a_2b_1c_1+a_2b_2c_3+a_2b_3c_2+a_3b_3c_1+a_3b_1c_3+a_3b_2c_2+a_1b_2c_1+a_1b_3c_3+a_1b_1c_2), (a2b1c1+a2b2c3+a2b3c2+a3b3c1+a3b1c3+a3b2c2+a1b2c1+a1b3c3+a1b1c2),
( a 3 b 1 c 1 + a 3 b 2 c 3 + a 3 b 3 c 2 + a 1 b 3 c 1 + a 1 b 1 c 3 + a 1 b 2 c 2 + a 2 b 2 c 1 + a 2 b 3 c 3 + a 2 b 1 c 2 ) ) (a_3b_1c_1+a_3b_2c_3+a_3b_3c_2+a_1b_3c_1+a_1b_1c_3+a_1b_2c_2+a_2b_2c_1+a_2b_3c_3+a_2b_1c_2)) (a3b1c1+a3b2c3+a3b3c2+a1b3c1+a1b1c3+a1b2c2+a2b2c1+a2b3c3+a2b1c2))
计算完后,经过 9 2 × 3 9^2\times 3 92×3 次的人工对比,上下两个向量是相等的。你可以试试,很有趣
得证。
于是每个询问用快速幂搞一搞就好了,而且这个题可以预处理很多东西来加速,但是由于我比较懒所以我并没有写qwq。
代码如下:
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
#define maxn 100010
#define ll long long
#define mod 998244353
int n,m,q;ll z,a,b;
struct vec{
int s[3];void init(){
s[0]=1;s[1]=s[2]=0;}
vec operator *(const vec &B){
return (vec){
(int)((1ll*s[0]*B.s[0]%mod+1ll*s[1]*B.s[2]%mod+1ll*s[2]*B.s[1]%mod)%mod),
(int)((1ll*s[1]*B.s[0]%mod+1ll*s[2]*B.s[2]%mod+1ll*s[0]*B.s[1]%mod)%mod),
(int)((1ll*s[2]*B.s[0]%mod+1ll*s[0]*B.s[2]%mod+1ll*s[1]*B.s[1]%mod)%mod)};
}
}v[maxn],ans;
__int128 e[21][maxn],bin[maxn];
const __int128 mod2=(__int128)mod*mod-1;
const ll mod3=1ll<<32;
vec ksm(vec x,__int128 y)
{
vec re;re.init();
while(y)
{
if(y&1)re=re*x;
x=x*x;y>>=1;
}
return re;
}
int main()
{
scanf("%d %d %d %lld %lld %lld",&n,&m,&q,&z,&a,&b);
for(int i=1;i<=n;i++)for(int j=0;j<=2;j++)z=(z*a+b)%mod3,v[i].s[j]=z%mod;
bin[0]=1;for(int i=1;i<=1000;i++)bin[i]=bin[i-1]*2%mod2;
for(int k=1;k<=q;k++)for(int i=1;i<=n;i++){
e[k][i]=0;for(int j=0;j<m;j++)
z=(z*a+b)%mod3,e[k][i]=(__int128)(e[k][i]+bin[32*j]*z)%mod2;
}
for(int i=1;i<=q;i++){
ans.init();
for(int j=1;j<=n;j++)ans=ans*ksm(v[j],e[i][j]);
printf("%d %d %d\n",ans.s[0],ans.s[1],ans.s[2]);
}
}
F. Infinite String Comparision
给出两个字符串 A , B A,B A,B,定义 x ∞ x^{\infty} x∞ 表示将 x x x 复制无限次得到的字符串,现在要你比较 A ∞ A^{\infty} A∞ 和 B ∞ B^{\infty} B∞ 的字典序大小。
假设他们的长度分别为 n , m n,m n,m,不妨令 n > m n>m n>m,那么其实我们只需要比较前 n + m − gcd ( n , m ) n+m-\gcd(n,m) n+m−gcd(n,m) 位即可,假如前 n + m − gcd ( n , m ) n+m-\gcd(n,m) n+m−gcd(n,m) 位都相同,那么有 A ∞ = B ∞ A^{\infty}=B^{\infty} A∞=B∞
可以发现,如果 A ∞ = B ∞ A^{\infty}=B^{\infty} A∞=B∞,那么循环节长度肯定是 gcd ( n , m ) \gcd(n,m) gcd(n,m),这里用到一个引理——Periodicity Lemma:如果 p , q p,q p,q 是 S S S 的循环节,并且 p + q ≤ ∣ S ∣ + gcd ( p , q ) p+q\leq |S|+\gcd(p,q) p+q≤∣S∣+gcd(p,q),那么 gcd ( p , q ) \gcd(p,q) gcd(p,q) 也是 S S S 的循环节。
证明:
分类讨论一下:假如 m = gcd ( n , m ) m=\gcd(n,m) m=gcd(n,m),那么显然满足。
假如 m ≠ gcd ( n , m ) m\neq \gcd(n,m) m=gcd(n,m),并且 A ∞ , B ∞ A^{\infty},B^{\infty} A∞,B∞ 的前 n + m − gcd ( n , m ) n+m-\gcd(n,m) n+m−gcd(n,m) 位相同的话,可以发现这样的规律:
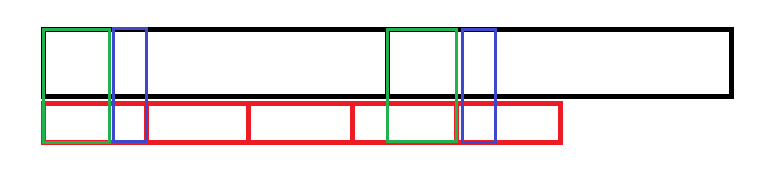
绿色部分和蓝色部分是相同的,可以发现,蓝色部分长度为 n m o d m n\bmod m nmodm,则绿色部分长度为 m − n m o d m m-n\bmod m m−nmodm,分别设为 a , b a,b a,b,那么 B B B 的前后 a a a 位是相同的,前后 b b b 位也是相同的。
类似的,又可以得到 B B B 的前后 m m o d a m\bmod a mmoda 位是相同的。
那么重复这个过程,相当于在做辗转相除法,最后就得到了 B B B 的前后 gcd ( n , m ) \gcd(n,m) gcd(n,m) 位是相同的,稍微再搞一搞就变成了每 gcd ( n , m ) \gcd(n,m) gcd(n,m) 位都相同。
H. Minimum-cost Flow
给出一张网络,边带费用,每次询问给出 u , v u,v u,v,表示每条边的流量为 u v \dfrac u v vu,问从 1 1 1 往 n n n 流 1 1 1 个单位的流量需要的最小费用。
不妨将所有流量除乘以 v u \dfrac v u uv,那么网络中每条边的流量就是 1 1 1,需要的流量就是 v u \dfrac v u uv。
由于网络中每条边的流量固定了,即不会因询问而改变,所以我们可以先跑一次费用流,求出所有路径的费用,然后每次从小的开始取知道流量满足 v u \dfrac v u uv 即可。
一个教训:分数类的运算很慢,可以避免的话还是不要写的好。
代码如下:
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
#define maxn 10010
#define ll long long
int n,m,k;
struct edge{
int x,y,z,cost,next;}e[maxn<<1];
int first[maxn],len;
void buildroad(int x,int y,int z,int cost){
e[++len]=(edge){
x,y,z,cost,first[x]};first[x]=len;}
int q[maxn],st,ed,fa[maxn],dis[maxn],t;ll road[maxn];
bool v[maxn];
bool SPFA()
{
memset(fa,0,(n+1)<<2);
memset(dis,63,(n+1)<<2);
st=1,ed=2;q[st]=1;dis[1]=0;
while(st!=ed)
{
int x=q[st++];st=st>n?1:st;v[x]=false;
for(int i=first[x];i;i=e[i].next)
{
int y=e[i].y;
if(e[i].z&&dis[y]>dis[x]+e[i].cost){
dis[y]=dis[x]+e[i].cost;fa[y]=i;
if(!v[y])v[q[ed++]=y]=true,ed=ed>n?1:ed;
}
}
}
return fa[n];
}
ll ans1,ans2;
ll gcd(ll x,ll y){
return !y?x:gcd(y,x%y);}
int main()
{
while(~scanf("%d %d",&n,&m))
{
memset(first,0,(n+1)<<2);len=1;t=0;
for(int i=1,x,y,z;i<=m;i++)scanf("%d %d %d",&x,&y,&z),
buildroad(x,y,1,z),buildroad(y,x,0,-z);
while(SPFA()){
road[++t]=0;
for(int i=fa[n];i;i=fa[e[i].x])
road[t]+=e[i].cost,e[i].z--,e[i^1].z++;
}
scanf("%d",&k);
for(int i=1,x,y;i<=k;i++)
{
scanf("%d %d",&x,&y);ans1=0,ans2=1;
if((ll)t*x<(ll)y){
printf("NaN\n");continue;};
int now=1,xx=x,yy=y,vk=0;//vk是一个优化,可以防止ans1爆long long
while(y>=x)ans1=ans1+road[now++],y-=x;
if(y)ans1=ans1*x+y*road[now],vk=1;
int p=gcd(ans1,ans2);ans1/=p,ans2/=p;
if(!vk)ans1*=xx;ans2*=yy;
p=gcd(ans1,ans2);ans1/=p,ans2/=p;
printf("%lld/%lld\n",ans1,ans2);
}
}
}
I. 1 or 2
给出一张图,询问是否存在一个满足要求的子图,其中点 i i i 的度为 d [ i ] d[i] d[i]。
因为 d [ i ] d[i] d[i] 只能为 1 1 1 或 2 2 2,假如全部都是 1 1 1,那么就是个带花树板子了。
假如是 2 2 2 的话,也就是说这个点可以匹配两次,那么可以将这个点 x x x 拆成两个点 x 1 , x 2 x_1,x_2 x1,x2。
而对于一条边,假如他连接的两个点 x , y x,y x,y 的 d d d 都是 2 2 2,那么不能单纯将 x 1 , x 2 x_1,x_2 x1,x2 与 y 1 , y 2 y_1,y_2 y1,y2 连边,这样连边可能出现 ( x 1 , y 1 ) , ( x 2 , y 2 ) (x_1,y_1),(x_2,y_2) (x1,y1),(x2,y2) 这样的配对,相当于将原边用了两次。
为了让原边只用一次,考虑像网络流一样拆开这条边,新建两个点,分别为左点和右点,在这两个点之间连边,然后 x 1 , x 2 x_1,x_2 x1,x2 向左点连边, y 1 , y 2 y_1,y_2 y1,y2 向右点连边。
然后跑一下带花树,假如能够完美匹配,就说明存在满足要求的子图。
为什么能这样拆边?
假如跑带花树时, x 1 , x 2 x_1,x_2 x1,x2 其中一个和左点匹配了,那么为了完美匹配,右点肯定和 y 1 , y 2 y_1,y_2 y1,y2 其中一个匹配了,那么这种情况就相当于将原边放入了最终的子图。
假如左点和右点匹配了,那么原边就没有对任何点做出贡献,即不在子图中。
代码如下:
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
#define maxn 100010
int n,m,d[maxn],ans;
struct edge{
int y,next;}e[maxn<<1];
int first[maxn],len;
void buildroad(int x,int y){
e[++len]=(edge){
y,first[x]};first[x]=len;}
void ins(int x,int y){
buildroad(x,y);buildroad(y,x);}
int mat[maxn],col[maxn],pre[maxn],fa[maxn];
int findfa(int x){
return x==fa[x]?x:fa[x]=findfa(fa[x]);}
int q[maxn<<1],st,ed,dfn[maxn],id=0;
int lca(int x,int y){
for(id++;x=findfa(x),dfn[x]!=id;swap(x,y))
if(x)dfn[x]=id,x=pre[mat[x]]; return x;
}
void blossom(int x,int y,int z)
{
while(findfa(x)!=z)
{
pre[x]=y;y=mat[x];
if(col[y]==2)col[y]=1,q[++ed]=y;
fa[x]=fa[y]=z;x=pre[y];
}
}
bool bfs(int S)//带花树板子
{
for(int i=1;i<=2*n+2*m;i++)fa[i]=i;
memset(pre,0,(2*n+2*m+1)<<2);
memset(col,0,(2*n+2*m+1)<<2);
col[q[st=ed=1]=S]=1;
for(int x=q[st];st<=ed;x=q[++st])
for(int i=first[x];i;i=e[i].next)
{
int y=e[i].y;if(col[y]==2||findfa(x)==findfa(y))continue;
if(col[y]==1){
int LCA=lca(x,y);blossom(x,y,LCA);blossom(y,x,LCA);}
else if(!col[y]){
col[y]=2;pre[y]=x;
if(!mat[y]){
for(int j,to;y;y=to)j=pre[y],to=mat[j],mat[y]=j,mat[j]=y;
return true;
} col[mat[y]]=1;q[++ed]=mat[y];
}
}
return false;
}
int main()
{
while(~scanf("%d %d",&n,&m))
{
memset(first,0,(2*n+2*m+1)<<2);len=0;
memset(mat,0,(2*n+2*m+1)<<2);
ans=0;for(int i=1;i<=n;i++)scanf("%d",&d[i]),ans+=d[i];//ans统计总点数
for(int i=1,x,y;i<=m;i++)
{
scanf("%d %d",&x,&y);
if(d[x]==d[y]&&d[x]==1)ins(x,y);
else if(d[y]==1)ins(x,y),ins(x+n,y);
else if(d[x]==1)ins(x,y),ins(x,y+n);
else ins(x,i+2*n),ins(x+n,i+2*n),ins(y,i+2*n+m),ins(y+n,i+2*n+m),ins(i+2*n,i+2*n+m),ans+=2;
}
for(int i=1;i<=2*n+2*m;i++)ans-=(!mat[i]&&bfs(i))*2;
if(!ans)printf("Yes\n");else printf("No\n");
}
}