2021年春节将至,去年受到新冠肺炎的影响,大家都只能宅在家里不能走访亲戚,与好友聚会。在全国人民众志成城的努力下,疫情在我国得到了有效的控制,大家都盼望着今年能回家过个好年,但近几天来各地又零星出现了新冠肺炎病例,随着过年的时间一天天将近,人们也越来越担忧疫情会不会随着春运及走访亲戚出现反弹。而人口的流动聚集,客观上加大了疫情传播的风险和防控的难度。为了进一步掌握人员流动聚集动向,做好紧急疫情的防控工作,针对疫情相关的重点区域开展人群聚集密度预测就显得尤为重要。
本案例基于思迈特软件的数据挖掘平台Smartbi Mining进行建模,使用逻辑回归分类算法对重点区域的人群密度进行预测,其目标如下:
(1)借助重点区域历史的人群密度,统计人流量指数和迁徙指数特征;
(2)建立模型预测重点区域未来的人群密度,掌握人员流动聚集的动向;
(3)针对人群密度较大的区域,做好紧急疫情防控工作。
本案例重点区域人群密度预测的总体流程如图1-1所示。
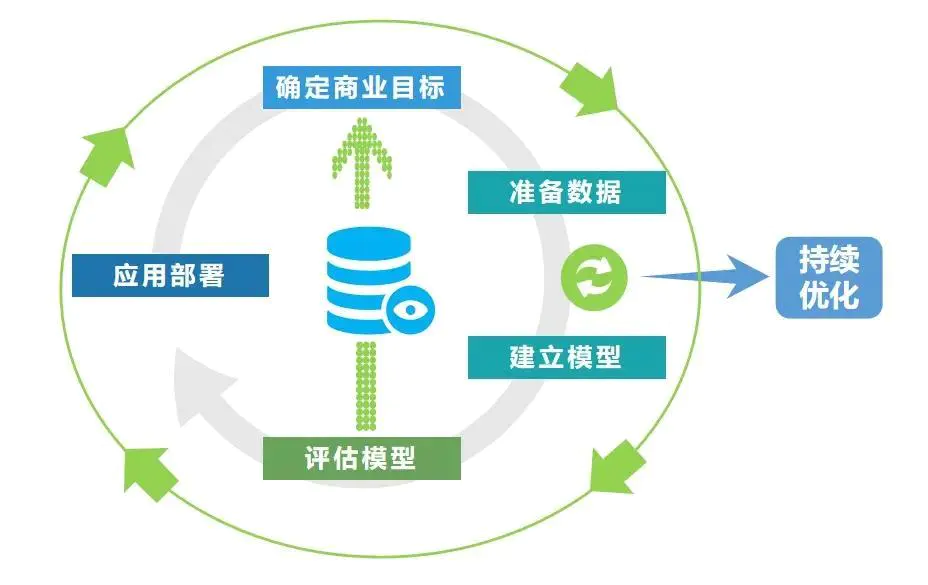
图1-1
(1)获取数据,数据来源于赛题重点区域人群密度预测数据;
(2)对获取的数据进行基本的处理操作,分组统计人流量指数和迁徙指数,作为模型的输入特征;
(3)根据统计特征数据建立重点区域人群密度预测模型;
(4)对模型结果进行评估。
实施过程
本案例共有3个数据集,为去年疫情期间20200117-20200215人流相关的数据为例,以下是每个数据集的字段说明。
表2-1 重点区域人流量情况表
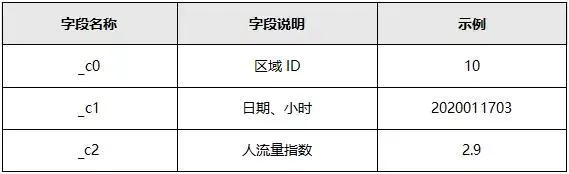
表2-2 重点区域信息表
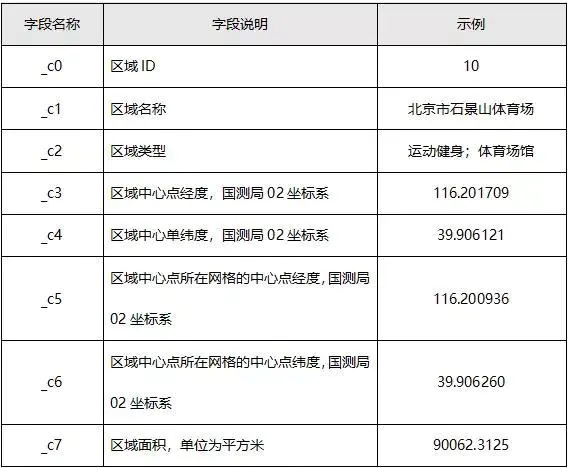
表2-3 北京市迁徙指数表
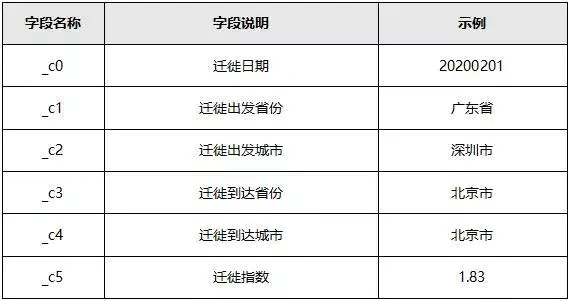
数据说明:
●重点区域人流量情况表中,人流量指数指与某天某小时内该区域内出现的人数成正比。A区域的人流量指数越大,表示A区域出现的人越多,反之越少。
●北京市迁徙指数表中,迁徙指数指与某天北京市与其他城市之间的人群流动量成正比。A城市到B城市的迁徙指数越大,表示从A城市迁徙到B城市的人数越多,反之越少。
2.1.数据接入
在实验中添加数据源节点,将上述3张表的数据读取进来,部分数据如图2-1所示。
图2-1
为了便于理解字段含义,让字段看起来更加直观,使用元数据编辑节点,添加中文字段别名,更改后的输出如图2-2所示,流程图如图2-3所示。
图2-2
图2-3
2.2.数据探索
本案例的探索分析是对数据进行缺失值分析与数据分布分析,分析出数据的缺失和分布情况。通过对数据观察发现重点区域人流量情况表和北京市迁徙指数表中日期时间字段格式不一致(如图2-4和图2-5),会对表合并有影响,因此需统一两张表的日期时间格式。
图2-4 重点区域人流量情况表
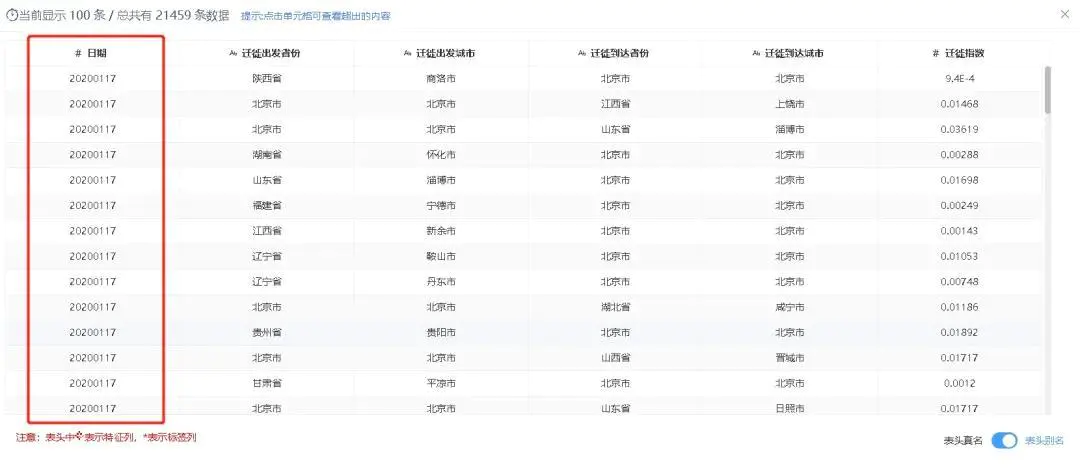
图2-5 北京市迁徙指数表
为了查看整个数据集数值型数据的情况,接入一个全表统计节点,选中所有数值型字段如图2-6,输出结果如图2-7所示,可以看到所有数据均不存在缺失值。
图2-6 选取所有数值型字段
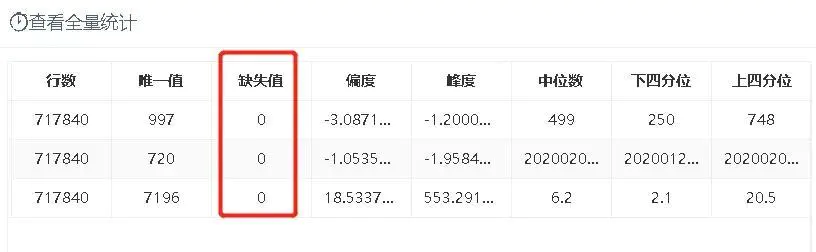
图2-7 数据缺失情况
2.3.数据预处理
本案例主要采用特征衍生和数据变换的预处理方法。
2.3.1. 特征衍生
通过数据探索分析,发现2张数据表中字段格式不统一无法合并,因此需统一字段格式。具体处理方法:对两张表均接入一个派生列节点,截取出日期时间字段的年月日信息,统一字段格式。接入一个派生列节点,派生列配置如图2-8所示。
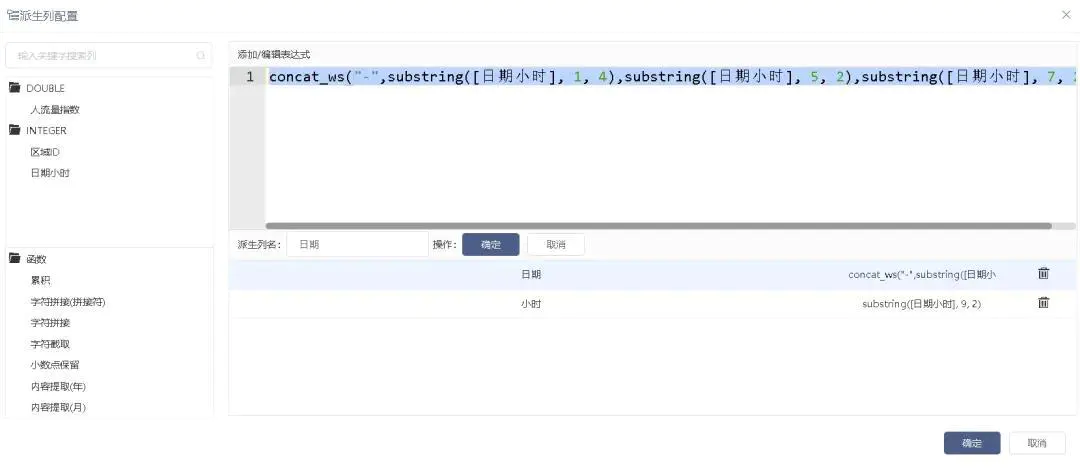
图2-8 派生列配置
派生列后结果如图2-9
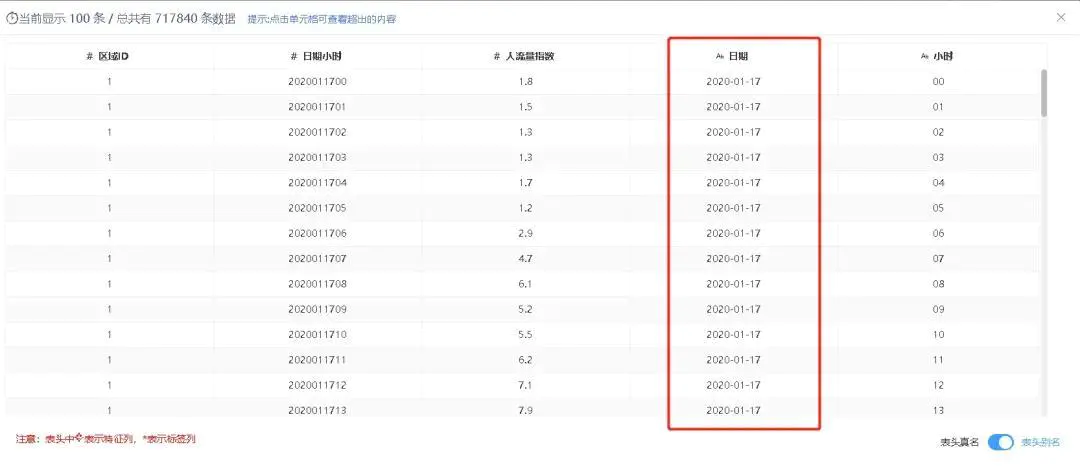
图2-9 转换后的日期时间格式
根据转换后的日期时间格式可以衍生字段“weekday”,表示当天属于一周中的第几天,接入一个派生列节点,派生列配置如图2-10所示。
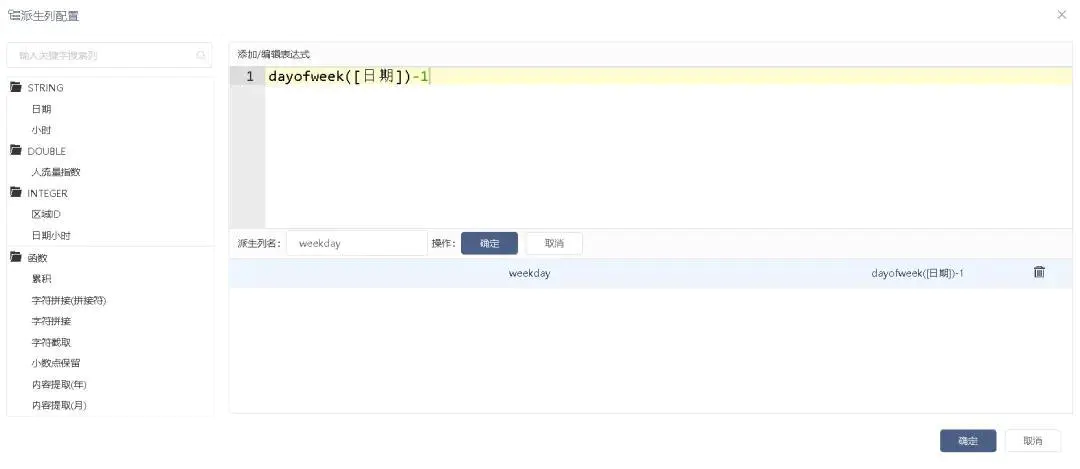
图2-10 派生列配置
“weekday”字段衍生后结果如图2-11。
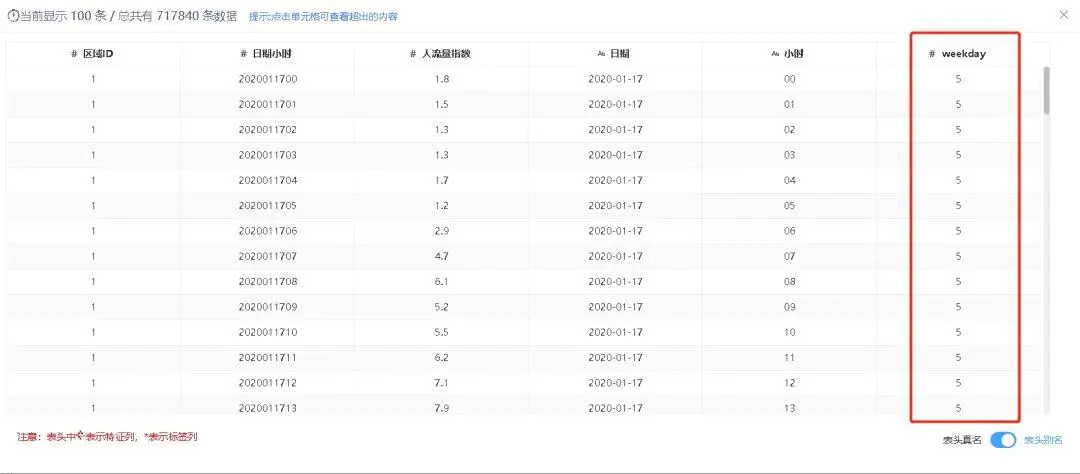
图2-11 weekday字段
2.3.2. 数据变化
由于原始的重点区域人群密度表只提供了历史20200117-20200215的每天分小时人流量,要做回归预测,需给该目标值构造特征,具体构造特征方法为:利用日期、小时、weekday、区域和区域类型的人流量指数和迁徙指数统计值聚合特征,如最小值、最大值、均值、总和等;
接入聚合节点,对日期、小时、weekday、区域、区域类型分别作Group操作,人流量指数、迁徙指数作Min、Max、Avg、Sum操作,如图2-12、2-13、2-14、2-15、2-16。
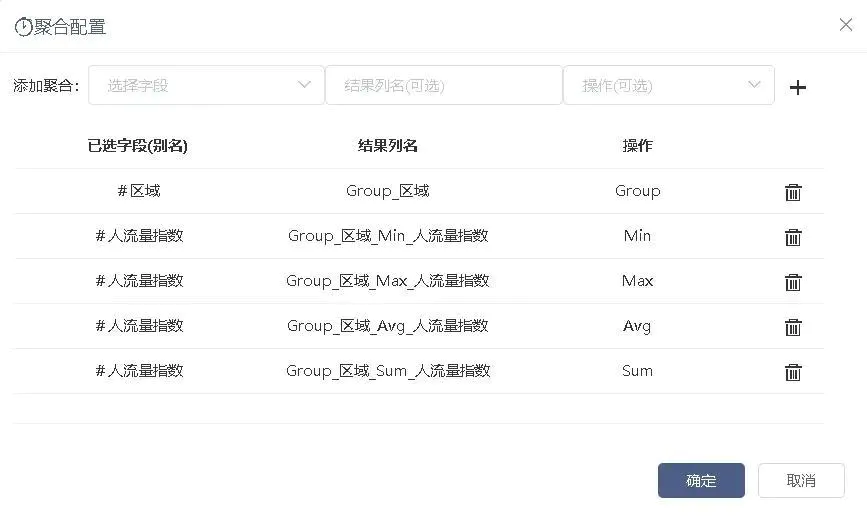
图2-12 根据区域聚合人流量指数
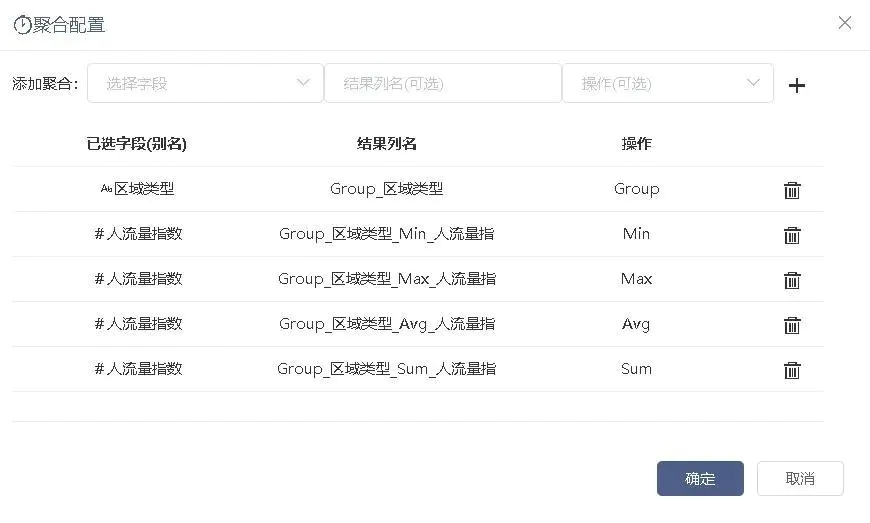
图2-13 根据区域类型聚合人流量指数
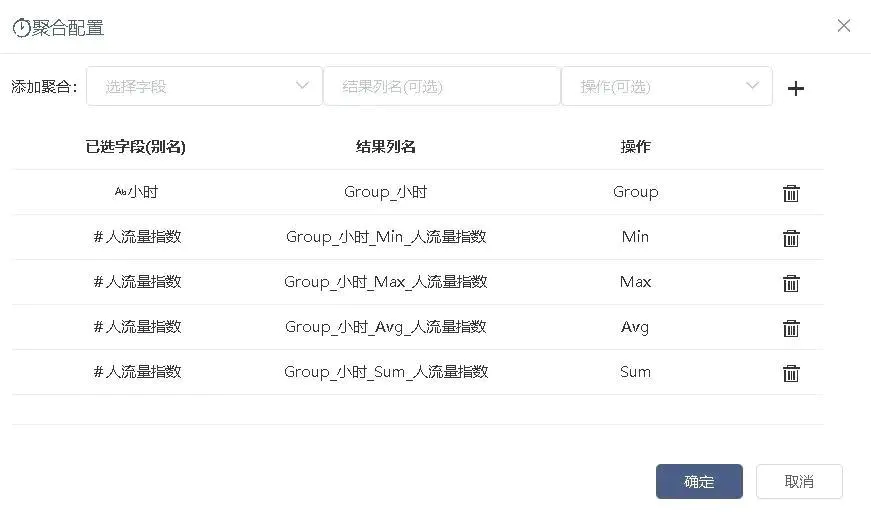
图2-14 根据小时聚合人流量指数
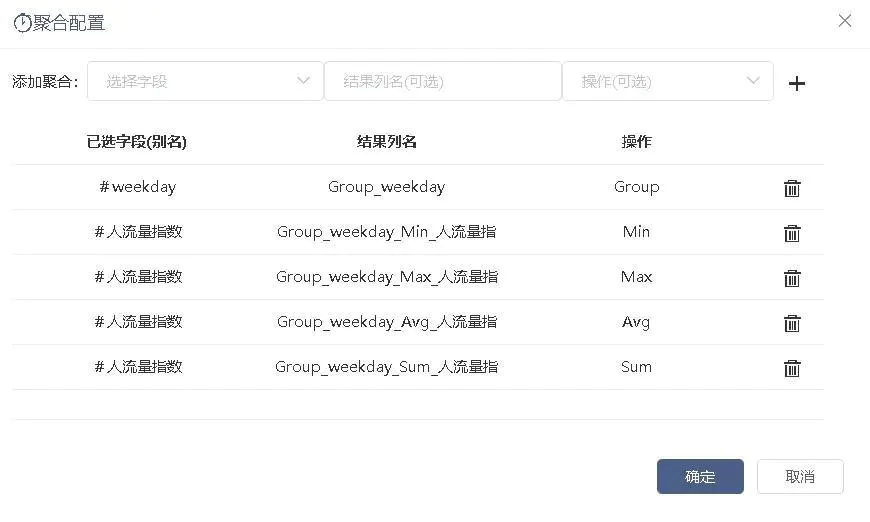
图2-15 根据weekday聚合人流量指数
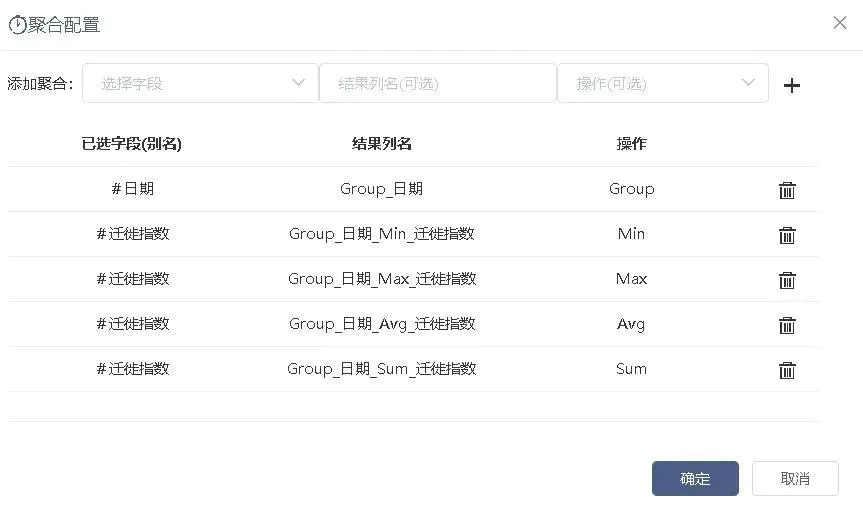
图2-16 根据日期聚合迁徙指数
对聚合后的特征使用JOIN节点进行合并,合并后可接入全表统计节点查看所有特征字段的分布情况,如图2-17所示。
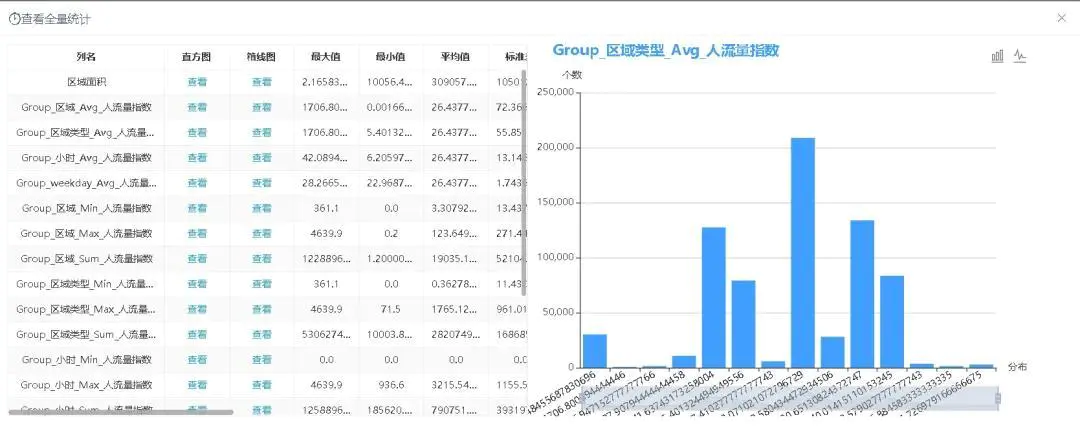
图2-17 指标数值分布情况
2.3.3. 预处理流程图
整个预处理流程图如图2-18所示。
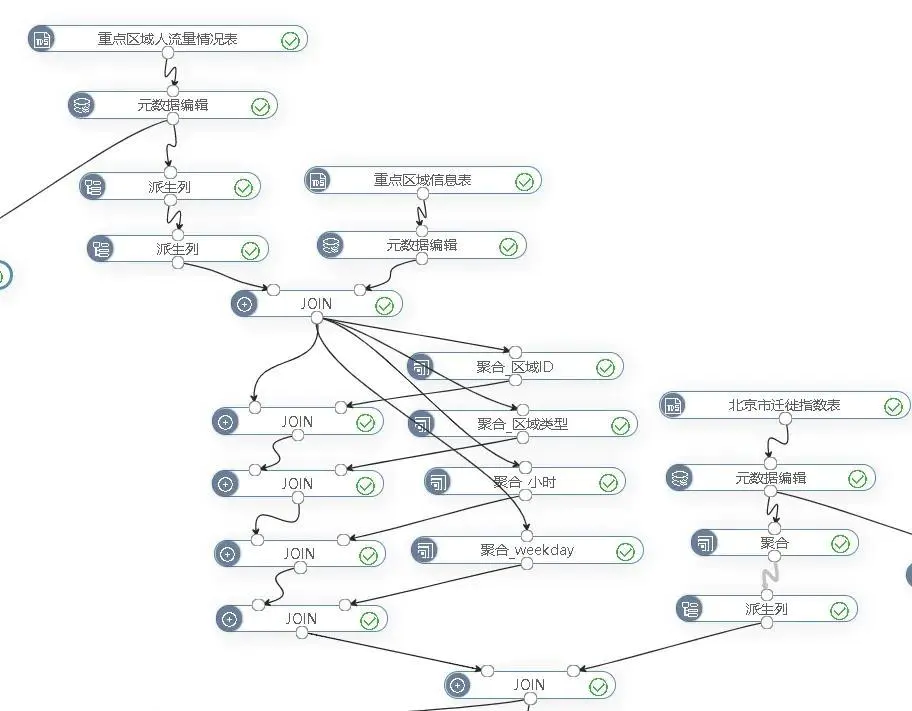
图2-18
2.4.建立模型
我们使用一个回归算法,这里选用梯度提升回归树算法。整体的实验流程如图2-19所示。
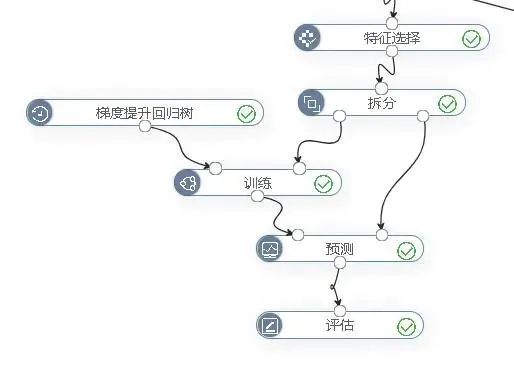
图2-19 人群密度回归预测模型
特征选择节点,特征列选择数据变换步骤输出的聚合特征,如图2-20。
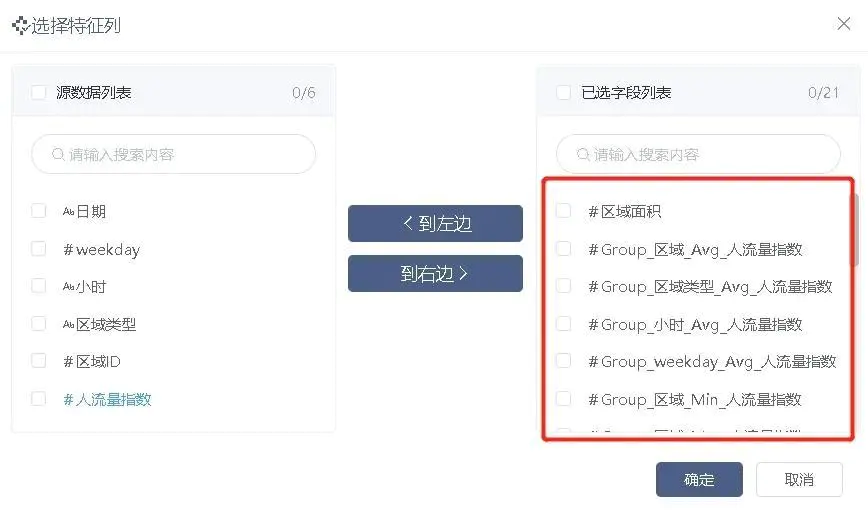
图2-20 特征选择特征列
特征选择的目标列选择人流量指数,如图2-21。
图2-21 选择目标列
拆分节点使用默认参数配置,训练集与测试集的占比为7:3;
梯度提升回归树的参数配置如图2-21所示。
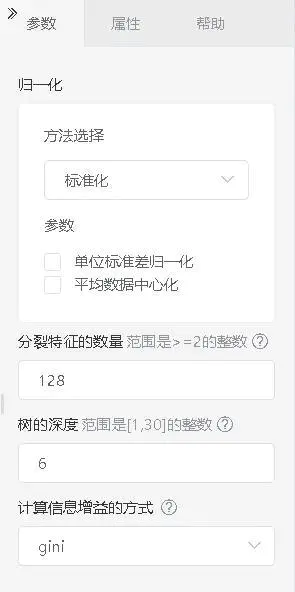
图2-21 梯度提升回归树的参数配置
评估节点的输出结果如图2-22所示,R2大概为0.96。
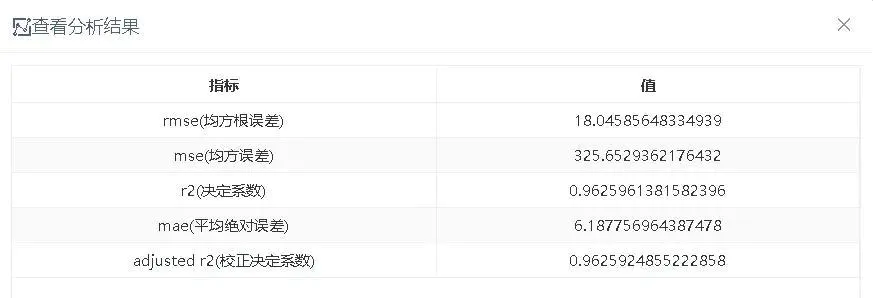
图2-22 模型评估结果
本案例结合疫情期间重点区域人流量密度预测案例,重点介绍了回归预测分析在实际案例中的应用。本案例借助重点区域历史的人群密度,统计人流量指数和迁徙指数特征;建立模型预测重点区域未来的人群密度,掌握人员流动聚集的动向;针对人群密度较大的区域,做好紧急疫情防控工作。