MCNN(简单理解):
三列卷积神经网络,分别为大中小三种不同尺度的卷积核,其目的来适应不同尺度的人头大小,最后将三列卷积神经网络进行合并
CSRNet 网络可以理解高度拥挤的场景并执行准确的计数估计以及呈现高质量密度图
1.CSRnet网络结构
CSRnet网络模型主要分为前端和后端网络,采用剔除了全连接层的VGG-16作为CSRnet的前端网络,输出图像的大小为原始输入图像的1/8。卷积层的数量增加会导致输出的图像变小,从而增加生成密度图的难度。所以本文采用空洞卷积神经网络作为后端网络,在保持分辨率的同时扩大感知域, 生成高质量的人群分布密度图。
1.1网络结构
采用剔除了全连接层的VGG-16网络,并且采用3×3的卷积核。研究表明,对于相同大小的感知域,卷积核越小,卷积层数越多的模型要优于那些有着更大卷积核且卷积层数较少的模型。为了平衡准确性和资源开销,这里的VGG-16网络采用10层卷积层和3层池化层的组合。后端网络采用六层空洞卷积层,空洞率相同。最后采用一层1×1的普通卷积层输出结果。网络结构如下:
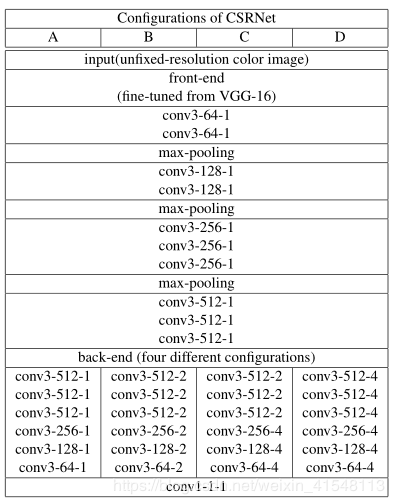
其中所有的卷积层均被填充保持原来大小。表中显示的卷积层的参数被表示成“conv-(卷积核大小)-(通道数)-(空洞率)”,其中最大池化层大小为2×2,步数为2。
1.2空洞卷积
CSRnet中最重要的部分是后端网络中的空洞卷积神经网络。定义一个二维的空洞卷积如下:
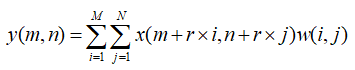
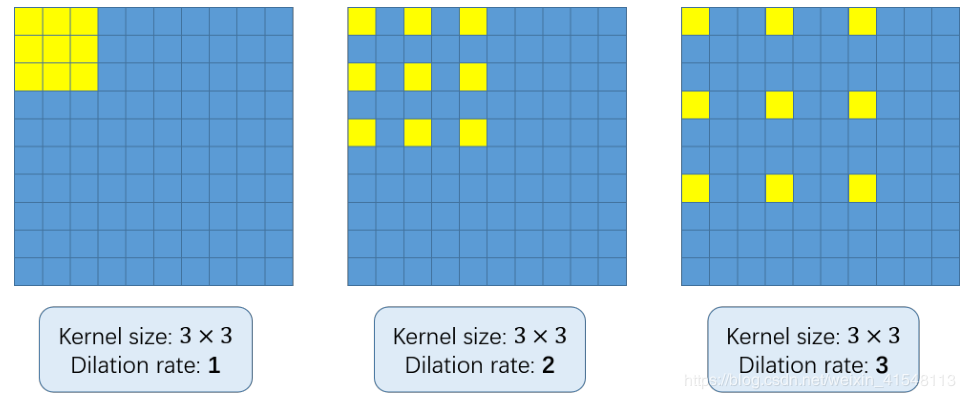
x(m,n)是长宽分别为M和N的输入图像信息,经过卷积核w(i,j)得到空洞卷积的输出y(m,n),其中参数r表示空洞率。如果r=1则空洞卷积就是普通卷积。实验证明,空洞卷积利用稀疏的卷积核,实现交替卷积和池化操作,在没有增加网络参数和计算规模的前提下增大了感知域,更适合人群密度估计任务。而普通的卷积操作需要增加卷积层数才能获得更大的感知域,而且也增加了更多的数据操作。空洞率为r 的空洞卷积操作,K x K的卷积核会被扩大为K+(K-1)(r-1)。图1中卷积核大小为3×3的感知域分别被扩大为5×5和7×7。
2.训练过程
2.1生成密度图
通俗理解:根据josn文件中的标注,对训练集中每张图片生成密度图,原理为先生成一个与图片大小相同的全0矩阵,然后将人头坐标位置设为1,其他位置设为0,然后根据高斯核函数生成的矩阵保存在.Xls文件中作为密度图,即为label。
2.2损失函数
作为端到端网络的CSRnet,采用最直接的方法进行模型训练即可。前端网络中10个卷积层来自已经训练好的VGG-16,所以只需要进行微调训练。对于其他卷积层的参数采用0.01的标准偏差的高斯初始化。在训练期间,随机梯度下降的学习率固定为1e-6。采用欧氏距离测量我们生成的密度图与真实值的距离。损失函数定义如下:
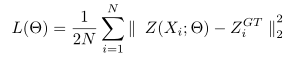
N表示batch size,Z表示生成的密度图,ZGT表示密度图ground truth
3实验结果
3.1评估标准
采用普遍被研究人员采用的均方误差(MSE)和平均绝对误差(MAE),MSE用来描述模型的准确度,MSE越小则准确度越高,MAE能反映出预测值的误差情况。

N表示一次测试序列中图片的数量,Ci表示对图片Xi的预测人数(得到的密度图求和即可),CiGT表示真实人数
参考:https://blog.csdn.net/weixin_41548113/article/details/85912714