2018(有代码)_CSRNet (+10次)
应用最最广泛的:e, is the most widely used while working with counting problems.
2018_CVPR——CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes
https://arxiv.org/abs/1802.10062
https://github.com/leeyeehoo/CSRNet-pytorch(https://github.com/leeyeehoo/CSRNet)
简单实现版本:https://github.com/CommissarMa/CSRNet-pytorch
优势:
(1)更大的感受野to deliver larger reception fields
(2)在不扩大网络复杂性的前提下,能够提取到高阶特征和产生更高质量的密度图It is capable of extracting high-level features and generating high quality density maps without expanding the network complexity,as shown below in the image.
(3)训练更容易,因为他是纯粹卷积的机构:easy-trained model because of its pure convolutional structure.
操作流程:
(1)抛弃了MCNN的Muti-Column架构,采用single-Column,因为(A)Multi-column CNNs训练上比较困难(B)Multi-column CNNs各个column表现基本一致,并不像设想那样不同column负责不同密集度范围,存在有很多冗余(C)类似MCNN这样的Multi-Columns方式并没有一个更深的Single-Column网络性能好
(2)在single column中引入更深的网络来提取特征,比如预训练的vgg-16。VGG-16的前10层作为front-end来提取特征,CSRNet uses VGG-16 technique on the front end,原因是【1】vgg-16的迁移学习率更快as it has faster transfer learning rate【2】灵活的模型架构用于联系密度图生成back-end flexible architecture for easily concatenating the back-end for density map generation。输出size和输入size的大小关系是1/pthThe output size that is obtained from a VGG is 1/pth size of original input size.
(3)在VGG的后6层这些back-end用空洞卷积取代,Dilated Convolutional layers are also used in the back end of CSRNet。用途:(1)卷积越多,会使得输出的size越小,进而density map的质量越差,所以要找到一种卷积,既做了卷积,最后output的size也不会变小,这样也就不需要上采样放大回去了 it avoids the need for upsampling——如果不使用空洞卷积,整个network输出的是原图的1/8The output size of this front-end network is 1/8 of the original input size.,如何你进一步叠加更多的卷积层,output size会进一步缩小,output size越小就更难生成高质量的密度图 (2)使用空洞卷积Dilated Conv来扩大感受野uses dilated kernels to deliver larger reception fields和 避免过度频繁的池化--实际上是直接不用池化了和上采样to avoid the frequent pooling and upsample——CSRNet实际上很好训练,CSRNet is an easy-trained model because of its pure convolutional structure.(3)空洞卷积更容易得到人头的边缘信息,这也是该模型能得到较高精度的重要原因。(4)扩大的kernal size但是没有增加参数量 increase the kernal size without increasing the number of parameters.
关于空洞卷积,详细讲一下——
——是什么Dilated Convolutions are a type of convolution that 被核给膨胀“inflate” the kernel by 在核的元素之间加入一些空洞inserting holes between the kernel elements.膨胀率的意思是核的元素之间要塞进去多少个空洞 An additional parameter l (dilation rate) indicates how much the kernel is widened. 在元素之间塞进去l-1个空洞There are usually l−1 spaces inserted between kernel elements.
一个k×k的卷积核被放大到 k+(k-1)(r-1)。
——这样做的好处,(1)在是的输出的size不变小的情况下,可以做一个灵活的整合多尺度的语境信息,Thus it allows flexible aggregation of the multi-scale contextual information while keeping the same resolution. (2)这样可以捕捉到更多的细节信息,the output from dilated convolution contains more detailed information (referring to the portions we zoom in on)

下图是模型结构,
前10层用的是VGG-16的前10层,也就是图中back-end(four different config)这一行以上就是这10层用的是公开的训练好的参数。之所以保留前10层,因为前10层保留了3个pooling,但是用完整的VGG-16是有个5个pooling,用pooling五个比三个的accuracy低。They kept the first ten layers of VGG-16 with only three pooling layers instead of five to suppress the detrimental effects on output accuracy caused by the pooling operation
因为三个pooling后size是输入的1/2^3=1/8,为了把输出还原回和输入一个size的Since the output (density maps) of CSRNet is smaller (1/8 of input size),,我们使用因子为8的双线性插值法来实现这一过程we choose bilinear interpolation with the factor of 8 for scaling and make sure the output shares the same resolution as the input image.

Z是密度图,N是图片数目

2017(有代码)_Switch-CNN(+9次)
2017_cite=848_CVPR_Switching convolutional neural network for crowd counting
代码:val-iisc/crowd-counting-scnn
(1)使用了三个子网络和分类的思想,让不同人群密度 级别的(人群稠密的不同等级的)的patch-图片碎片--用 最合适的 的CNN网络进行counting ,choose the best network for each image patch(人比较少的走 一个参数比较少的子网络,人比较多的走参数比较多的、更复杂的网络),则所有patch被更准确地预测,最终,所有patch的准确预测构成了原图准确的人群估计。
(2)作者在训练过程中用到了预训练的技术,首先使用所有训练数据对所有网络做了预训练,然后将每个patch通过分类网络决定进一步输入到哪个子网络。
该模型存在与MCNN同样的问题,即“到底应该选择几个子网络?”。但该方法通过网络学习来确定patch输入的路径,给patch做分类还是比较新颖的idea。
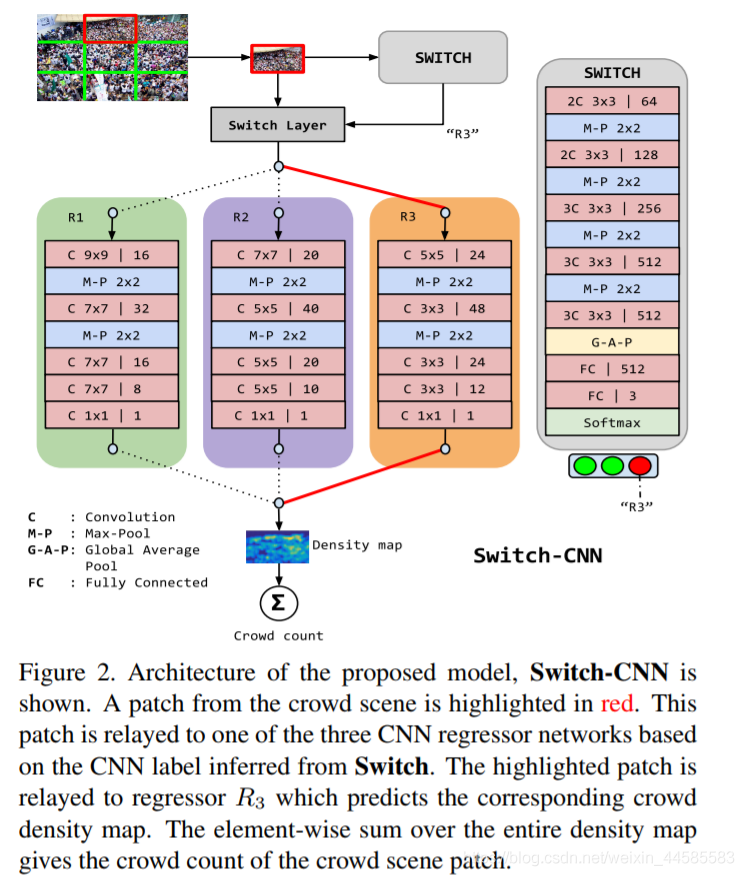
针对这个模型示意图,我特别说明一下
左上角表示,进来一张需要计数的图片。然后我把把这张图片切crop开,切成3×3,共9张小图patch。然后我们取第一行第二列这张图,这张用红色 长方框 框出的图,然后放进 Switch 这个 classifier里面,然后分类器告诉我们 这个patch应该用R3这个 regressor,R3是专门处理这种人群极度密集的场景的,他的 receptive field更smaller,小的感受野更适合识别斑点,这种高密度人群特有的抽象特点ideal for detecting blob like abstractions characteristic of patches with high crowd density.。然后我们看到一条红色的直线向右指向R3这个 regressor,最后这个regressor输出一个 density map,也就是一条红色的直线从右上到左下指的这个。
概要
文章提出了一种人群计数模型,实现了从密集人群图像到其密度分布的映射。密集人群计数问题的难点包括人头互相遮盖、人群与背景相似度高以及图像拍摄视角各不相同等,此前效果较好的人群计数网络使用了多尺寸CNN、循环网络或多列CNN特征融合的方法来处理这些问题。作者提出了“选择卷积神经网络”switching convolutional neural network(Switch-CNN)来提升人群计数的精确度,首先由几个卷积核大小不同的CNN作为密度图预测的回归器,然后再由一个经训练的选择分类器来对于每一张输入图像选取最优的CNN回归器,将其结果作为最终结果。
网络结构
——Switch-CNN包含三个结构互不相同的CNN回归器和一个选择最优回归器的分类器Switch classifier。
——对于每一张输入图片,首先将其裁剪为互不重叠的9份,the input image is divided into 9 non-overlapping patches. ,每份为原图的1/3长宽。其目的是为了使输入的小图片可以视为拥有单一的密度、规模和视角信息,作为一个选择回归器的最小单位。我们用switch分类器来确定每张图是哪种密集程度,然后将这个patch分配给特定的回归器regressor来进行counting,we use a Switch-CNN to see what kind it belongs to, and then relay分配 the patch to a particular regressor. 这个分类器switch classifier实际上就是把一个图片中的人群场景映射到不同密度maps a given crowd scene to its density.
——CNN回归器选择了CVPR2016《Single-Image Crowd Counting via Multi-Column Convolutional Neural Network》中的网络结构,每一列都包括4个卷积层和2个池化层,三列的卷积核大小各不相同。
,SWITCH这个模块,用于给输入的图片块分配标签(高密度、中密度、低密度),Switch Layer将根据这个标签将输入的图片块传入相应的CNN网络。
第二部分是用于处理不同密度图片块的CNN网络,里边用不同大小的卷积核对不同尺度密度的人群图片进行处理
——Switch classifier:分类器则使用了基于VGG-16的结构,进行三路分类。We use an adaptation of VGG16 [14] network as the switch classifier to perform 3-way classification. ,移除了最后的全连接层,The fully-connected layers in VGG16 are removed。我们用全局平均池化层global average pool(GAP)来移除空间信息、来聚合这些有判别力的特征(我表示怀疑)、We use global average pool (GAP) on Conv5 features to remove the spatial information and aggregate discriminative features.、一层较小的全连接层和一个对应三个regressor网络的的三分类的softmax分类层。softmax层的结果即需要选择的回归器。GAP is followed by a smaller fully connected layer and 3-class softmax classifier corresponding to the three regressor networks in Switch-CNN。
——Three regressor:回归器照搬MCNN的 density map的生成The generation of density map is as same as the way of MCNN.
真实密度图
数据集中标注的图像均以一个个点的形式表示,因此需要一种方法来将标注点转化为密度图像。作者使用了上文提到的CVPR2016论文中提出的几何适应核的方法,将高斯变换的参数设定为与标注点到周围k个近邻的平均距离相关。这种方法可以较好的模拟视角信息。对于密度较高的人群,作者使用了几何适应的高斯核,而对于较稀疏人群则使用固定的高斯变换。
训练
Switch-CNN的训练分为四个步骤:预训练(pretraining)、差异训练(differencial training)、switch training和集成训练(coupled training)。
(S1)在预训练阶段,三个CNN回归器首先单独进行训练,损失函数为真实密度图像和预测图像的欧几里得距离:

(S2)随后是差异训练阶段,对每一张训练图片经过训练的三个回归器得到的结果进行评估,选取总人数误差最小的回归器单独再对该图片进行一次训练。这一过程的效果是使得所有训练图片被分为了三组,每组均由一个网络进行拟合,使得测试图片在分类正确的情况下可以由更符合图片特征的回归器计算出更精确的密度图像。
接下来的步骤是训练分类器。分类器是一个基于VGG16的三类分类器,依据差异训练阶段得到的分类结果进行训练,以使得分类器能将更多的图片分给正确的回归器。为确保各类之间样本的平衡,需要对数量较少的类进行随机取样扩充训练样本。
(S3)为提升训练效果,差异训练和训练分类器的过程会交替进行,这一步骤作者称为集成训练。整个训练过程如下:
——输入:N张 训练图片的 碎片patches 和,N张 ground truth density map
——输出:三个回归器的 参数 $$\theta$$, 还有三分类器 switch的参数
——使用随机高斯权重(均值为0,标准差为1的高斯分布生成的随机数) 去初始化 三个回归器 的参数
——预训练三个回归器,用所有的数据训练 $$T_{p}$$个epoch
——(我没看懂,我猜的)Differential Training差异训练,一张图片分别丢进三个模型中,三个模型会有各自的预测的数量,根据你预测的和ground truth的数量 求损失值,向着损失值变小的方向做梯度下降、方向传播、优化参数,使得这个模型对于这张照片的效果尽可能的最好
——coupled training和switched differencial training我看着都差不多,我没看出各自要表达的东西

测试
评估标准是总人数的绝对平均误差和平方平均误差:
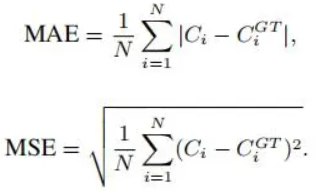
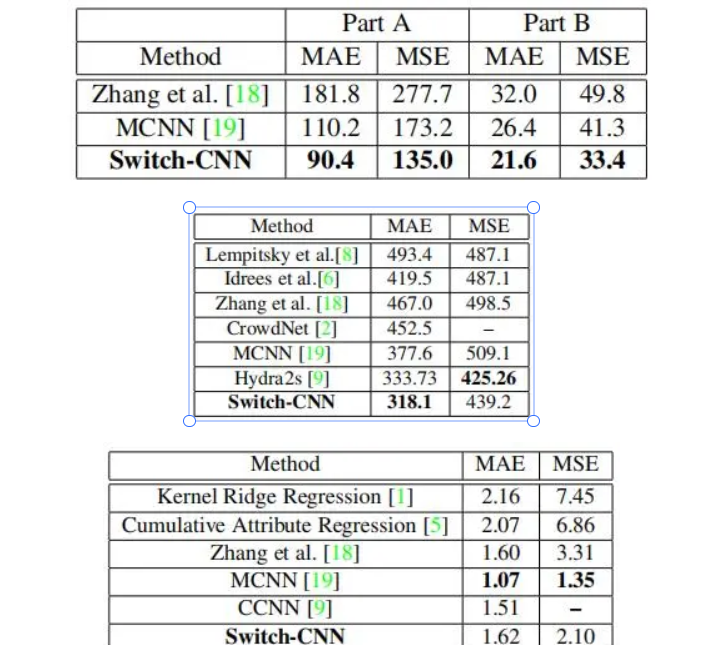
作者分别对ShanghaiTech数据集、UCF_CC_50数据集、UCSD数据集和WorldExpo’10数据集进行了测试,其结果分别为:
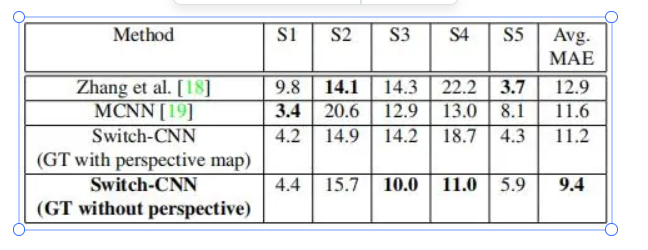
为研究不同的回归器数量对测试效果的影响,作者尝试了单独使用三个回归器以及使用两个回归器,并将其在ShanghaiTech Part A上的结果作了对比:
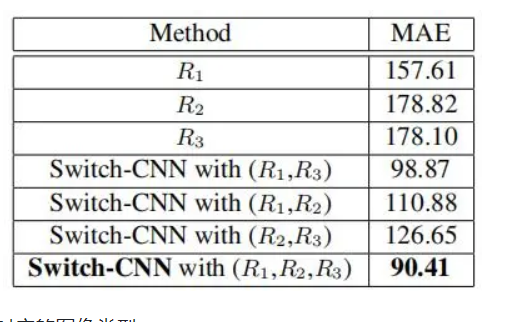
实验中三个不同的分类器分别对应的图像类型:
——低密度;中密度;极高密度
