Python 爬虫 Selenium 基本使用
免责声明:自本文章发布起, 本文章仅供参考,不得转载,不得复制等操作。浏览本文章的当事人如涉及到任何违反国家法律法规造成的一切后果由浏览本文章的当事人自行承担与本文章博客主无关。以及由于浏览本文章的当事人转载,复制等操作涉及到任何违反国家法律法规引起的纠纷和造成的一切后果由浏览本文章的当事人自行承担与本文章博客主无关。
1. 基础知识
Selenium单词含义为化学中 Se 硒, 人身体的微量元素. 缺少该元素易得抑郁症.
由此可见 Selenium 在爬虫中自动化搜索的重要性.
Selenium 官网:
https://www.selenium.dev/
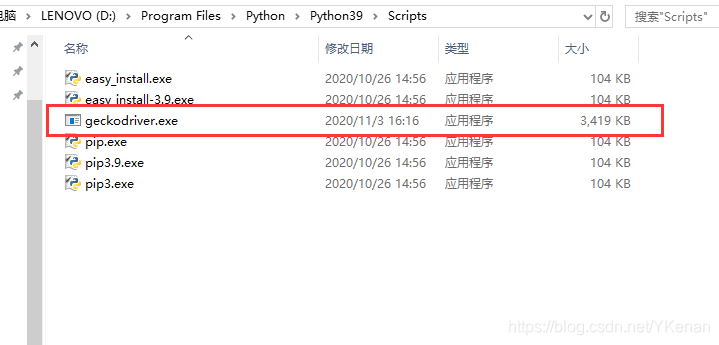
1.1 下载浏览器驱动
找到下载驱动的第一种方法

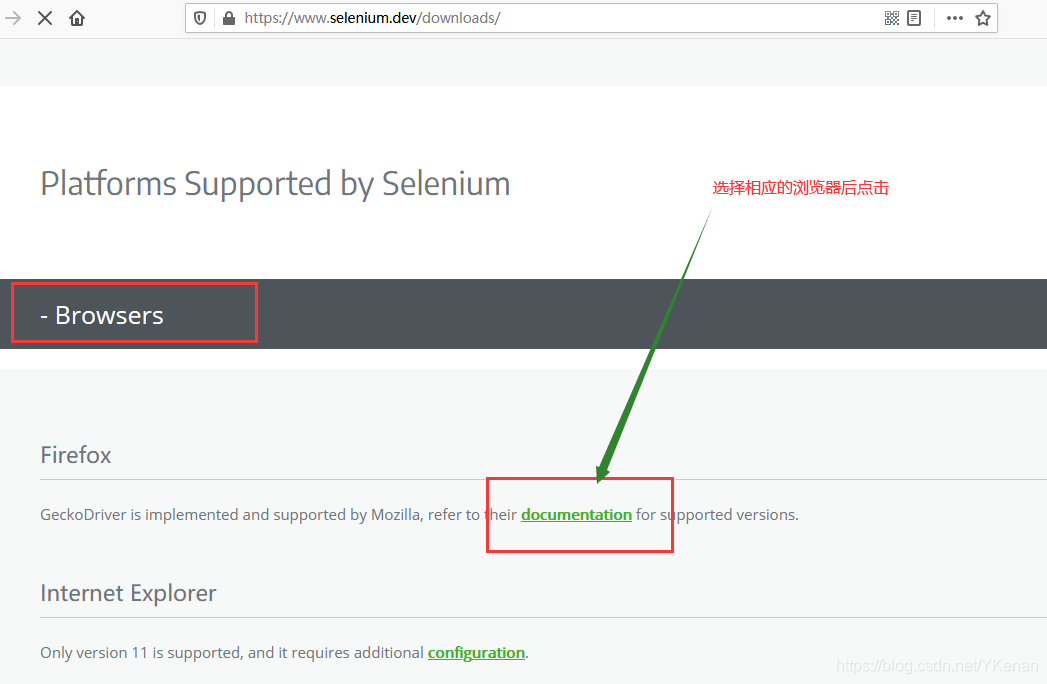
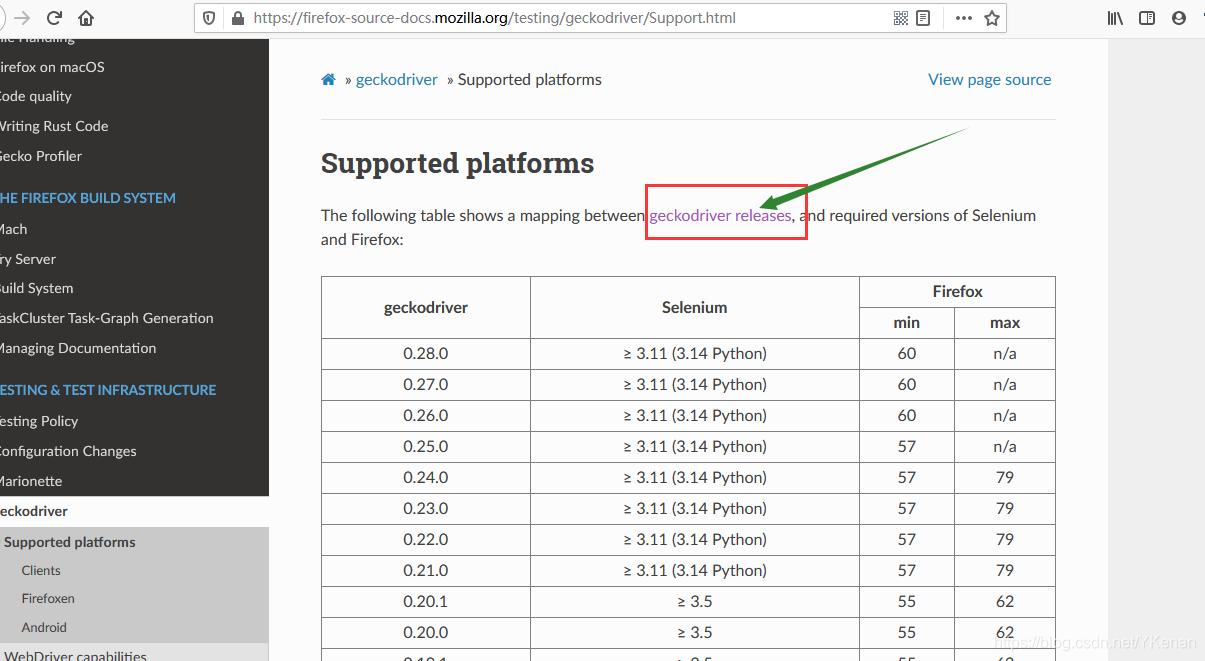
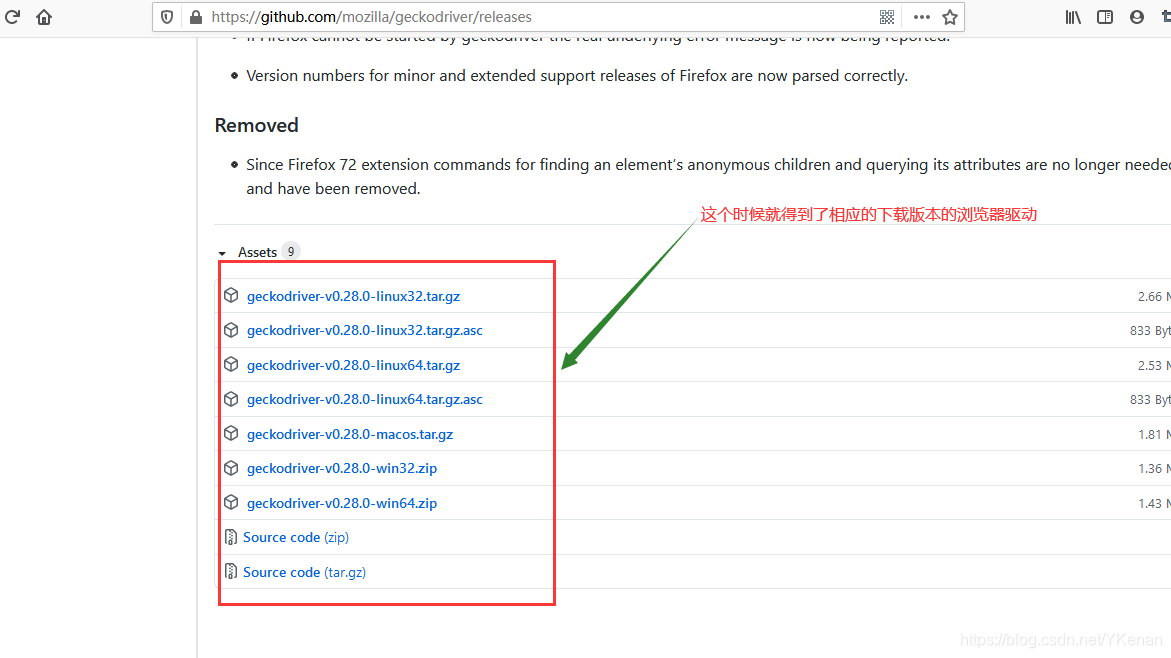
将驱动解压随便放在一个文件夹下即可.
1.2 帮助文档
找到下载驱动的第二个方法就是通过帮助文档
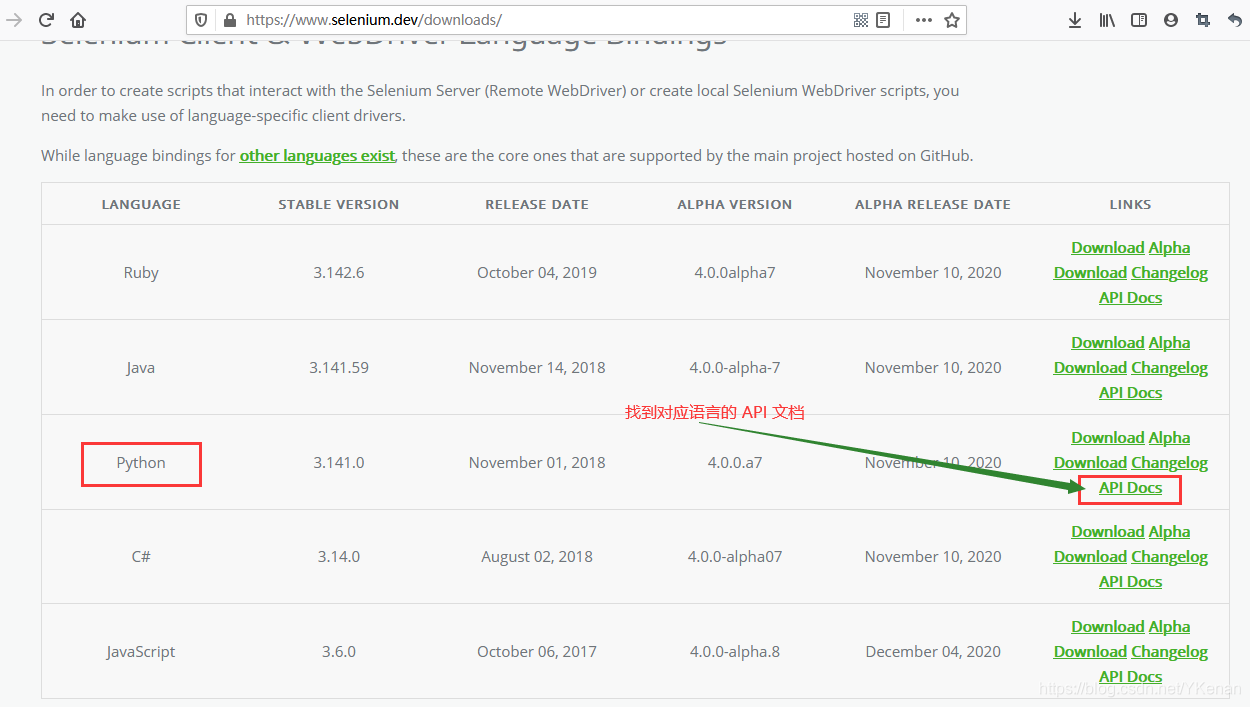
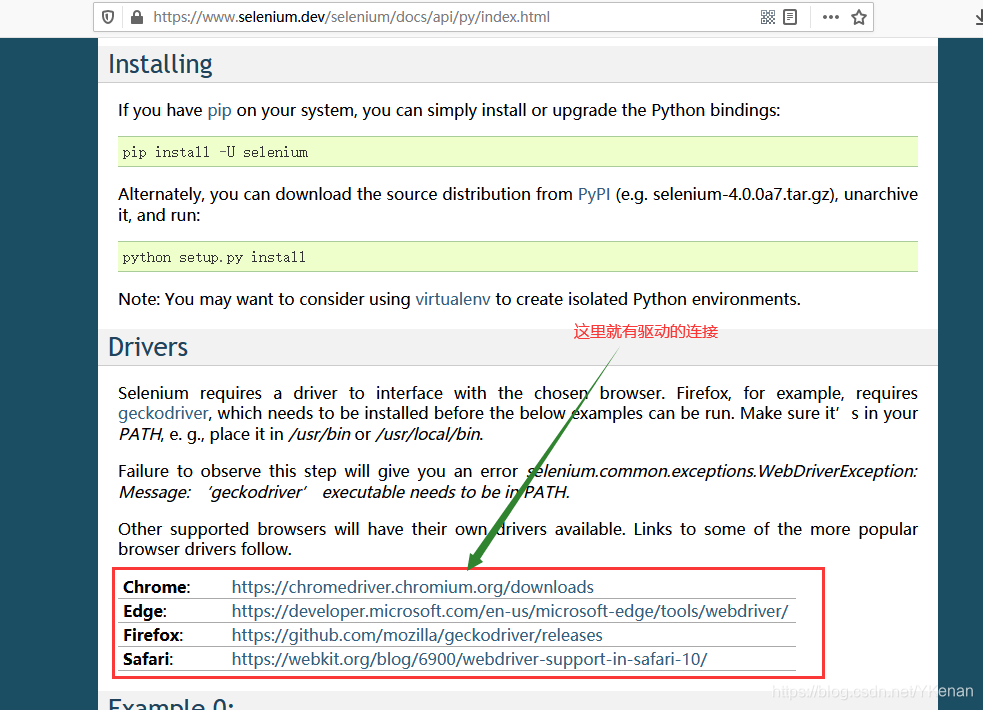
全面的帮助文档
导入下面需要的所有模块.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.alert import Alert
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
2. 浏览器操作
加载驱动, 实例化对象
executable_path: 指定 geckodriver.exe 文件的绝对路径.
#实例化浏览器对象
driver = webdriver.Firefox(executable_path=r"D:\Program Files\Python\Python39\Scripts\geckodriver.exe")
2.1 浏览器导航
# 发送请求
driver.get("https://selenium.dev")
# 得到当前的 URL
print(driver.current_url)
# 获取当前页面内容
print(driver.page_source)
# 读取当前页面标题
print(driver.title)
# 按浏览器的后退按钮
driver.back()
# 按浏览器的前进按钮
driver.forward()
# 刷新当前页面
driver.refresh()
2.2 窗口和选项卡
#获取当前窗口
current_window = driver.current_window_handle
# 获取前一个窗口
window_before = driver.window_handles[0]
# 获取后一个窗口
window_after = driver.window_handles[1]
# 获取所有窗口
handles = driver.window_handles
# 切换到最开始打开的窗口
driver.switch_to.window(handles[0])
# 切换到最新打开的窗口
driver.switch_to.window(handles[-1])
# 创建新窗口并切换
driver.switch_to.new_window('new_window')
# 关闭当前窗口
driver.close()
# 切换回旧窗口 original_window 为之前获取过的当前窗口
driver.switch_to.window(original_window)
# 切换回旧的会话窗口或者结束窗口退出浏览器
driver.quit()
2.3 Frames and Iframes
iframe 标签内进行操作
2.3.1 通过元素切换
# 获取 iframe
iframe = driver.find_element(By.CSS_SELECTOR, "#modal > iframe")
# 切换到 iframe
driver.switch_to.frame(iframe)
# 对 iframe 内部标签进行操作
driver.find_element(By.TAG_NAME, 'button').click()
2.3.2 通过 name 或 id 属性切换
# 通过 name 或者 id 直接切换到 iframe 中
driver.switch_to.frame('iframe')
# 对 iframe 内部标签进行操作
driver.find_element(By.TAG_NAME, 'button').click()
2.3.3 通过索引进行切换
# 切换到第 n + 1 个 iframe, 索引从 0 开始.
driver.switch_to.frame(n)
2.3.4 离开 iframe
# 离开 iframe 切换回原来的内容
driver.switchTo().defaultContent();
2.4 窗口管理
# 获取窗口大小
size = driver.get_window_size()
print(size.get("width"))
print(size.get("height"))
# 设置窗口大小
driver.set_window_size(1024, 768)
# 获取窗口的维度
position = driver.get_window_position()
print(position.get('x'))
print(position.get('y'))
# 设置窗口的维度
driver.set_window_position(0, 0)
# 窗口设置最小化 (最小化窗口通常将窗口隐藏在系统托盘中)
driver.minimize_window()
# 窗口设置最大化 (对于大多数操作系统, 窗口将填满屏幕, 而不会阻塞操作系统自己的菜单和工具栏)
driver.maximize_window()
# 设置全屏窗口 (填充整个屏幕, 类似于在大多数浏览器中按 F11 键)
driver.fullscreen_window()
# 截图并保存
driver.save_screenshot('./image.png')
# 捕获元素进行截图
ele = driver.find_element(By.CSS_SELECTOR, 'h1')
ele.screenshot('./image.png')
3. 等待操作
爬取过程中, 需要等待浏览器反应或者等待代码的条件传递, 浏览器再响应.
3.1 显式等待
设置标签内或窗口等出现, 存在, 为真则可以通过.
# 创建等待对象, 超时不设置为全部时间.
wait = WebDriverWait(driver, timeout=20)
# 直到找到 id="button" 什么时候才可以通过或者超时报错, d 代表的就是 上面传入的 driver 对象
wait.until(lambda d: d.find_element_by_id("button"))
3.2 隐式等待
当网页上的某些元素不能立即使用并且需要一些时间来加载时, 这会很有用.
默认情况下, 隐式等待元素出现是禁用的, 并且需要在每个会话的基础上手动启用.
注意: 隐式和显式等待不建议混合用, 这样做会导致不可预知的等待时间.
# 隐式等待
driver.implicitly_wait(10)
# 发送请求
driver.get("https://www.baidu.com")
# 查看该元素隐式等待的时间
my_dynamic_element = driver.find_element(By.ID, "button")
3.3 流畅等待
定义等待条件的最长时间, 以及检查条件的频率.
用户可以将 wait 配置为在等待时忽略特定类型的异常.
这样也就降低的精度, 保障了流畅度.
# 忽略了元素找不到的异常, 没有该元素也可以通过, 只是加长了尝试该元素的等待时间.
wait = WebDriverWait(driver, 10, poll_frequency=1, ignored_exceptions=[ElementNotVisibleException, ElementNotSelectableException])
element = wait.until(EC.element_to_be_clickable((By.XPATH, "//div")))
4. JS 的 alerts, 提示和确认
alerts: 是最简单的弹出框. 取消和确定是一样的.
# 点击页面中 alert 的按钮
driver.find_element(By.LINK_TEXT, "See an example alert").click()
# 设置等待
wait = WebDriverWait(driver, 10)
# 等待这个按钮的出现
alert = wait.until(EC.alert_is_present())
# 获取 alert 的内容
text = alert.text
# 确定 alert
alert.accept()
confirm: 类似于 alert, 只是用户也可以选择取消消息.
# 点击页面中 confirm 的按钮
driver.find_element(By.LINK_TEXT, "See a sample confirm").click()
# 设置等待
wait = WebDriverWait(driver, 10)
# 等待这个按钮的出现
wait.until(EC.alert_is_present())
# 切换到弹出框中
alert = driver.switch_to.alert
# 获取弹出框中的内容
text = alert.text
# 取消弹出框
alert.dismiss()
prompt: 与 confirm 类似, 只是可以包含文本输入.
# 点击页面中 prompt 的按钮
driver.find_element(By.LINK_TEXT, "See a sample prompt").click()
# 设置等待
wait = WebDriverWait(driver, 10)
# 等待这个按钮的出现
wait.until(EC.alert_is_present())
# 将 driver 存储到 alert 中
alert = Alert(driver)
# 输入提示内容
alert.send_keys("Selenium")
# 提交即可
alert.accept()
5. 代理
# 设置代理
PROXY = "<HOST:PORT>"
webdriver.DesiredCapabilities.FIREFOX['proxy'] = {
"httpProxy": PROXY,
"ftpProxy": PROXY,
"sslProxy": PROXY,
"proxyType": "MANUAL",
}
# 实例化对象, 请求等
6. 页面加载策略
- normal: 当设置为 normal 时,Selenium WebDriver 将等待直到 load 事件激发返回. 默认为 normal.
- eager: 这将使 Selenium WebDriver 等待初始 HTML 文档完全加载和解析, 并放弃样式表, 图像和 subframes 的加载.
- none: Selenium WebDriver 只会等待初始页被下载.
# 实例化 options
options = Options()
# 设置加载类型, 三种中的一种.
options.page_load_strategy = 'normal'
driver = webdriver.Firefox(executable_path="./geckodriver.exe", options=options)
7. Web 元素
这个是 Selenium 中重要的基础内容.
7.1 Find 元素
# 查找 name="q" 的元素标签, 返回一个, 页面含有多个会报错
search_box = driver.find_element(By.NAME, "q")
# 清空标签内容
search_box.clear()
# 向标签添加内容
search_box.send_keys("webdriver")
除了 driver.find_element() 还有其他形式.
# 通过 id="q" 查找标签
driver.find_element_by_id("q")
# 通过 css 选择器查找标签
driver.find_element_by_css_selector("#q > a")
# 通过 name="q" 查找标签
driver.find_element_by_name("q")
# 通过 class="container" 查找标签
driver.find_element_by_class_name("container")
# 通过标签里的内容查找标签 (精准匹配)
driver.find_element_by_link_text("提交")
# 通过标签里的内容查找标签 (模糊匹配)
driver.find_element_by_partial_link_text("提交")
# 通过标签名称查找标签
driver.find_element_by_tag_name("input")
# 通过 xpath 数据解析查找标签
driver.find_element_by_xpath("//a[@id='q']")
上面都是对应页面找到一个的时候, 多个的时候需要将
element改为elements
# 查询到多个 p 标签
elements = driver.find_elements(By.TAG_NAME, 'p')
# 循环输出 p 标签内容
for e in elements:
print(e.text)
# 用法一样
driver.find_elements(By.NAME, "q")
driver.find_elements_by_id("q")
driver.find_elements_by_css_selector("#q > a")
driver.find_elements_by_name("q")
driver.find_elements_by_class_name("container")
driver.find_elements_by_link_text("提交")
driver.find_elements_by_partial_link_text("提交")
driver.find_elements_by_tag_name("input")
driver.find_elements_by_xpath("//a[@id='q']")
7.2 Form 元素
# 查找 form 标签
search_form = driver.find_element(By.TAG_NAME, "form")
# 查找 form 标签下的 name="q" 的标签
search_box = search_form.find_element(By.NAME, "q")
多个元素的
# Get element with tag name 'div'
element = driver.find_element(By.TAG_NAME, 'div')
# Get all the elements available with tag name 'p'
elements = element.find_elements(By.TAG_NAME, 'p')
for e in elements:
print(e.text)
7.3 Active 元素
# 选择器中 name="q" 的标签并输入值
driver.find_element(By.CSS_SELECTOR, '[name="q"]').send_keys("webElement")
# 获取当前模拟鼠标焦点的信息
attr = driver.switch_to.active_element.get_attribute("title")
print(attr)
7.4 是否启动/禁用的元素
如果在当前浏览上下文中启用了连接的元素, 则返回布尔值 True, 否则返回 False.
value = driver.find_element(By.NAME, 'btnK').is_enabled()
print(value)
如果在当前浏览上下文中选择了引用的元素, 则返回布尔值 True, 否则返回 False.
此方法广泛用于复选框、单选按钮、输入元素和选项元素.
value = driver.find_element(By.CSS_SELECTOR, "input[type='checkbox']:first-of-type").is_selected()
print(value)
7.5 得到元素 (标签, 样式, 内容, 属性)
# 查询 id="button" 是什么标签
name = driver.find_element(By.ID, "button").tag_name
print(name)
# 获取标签的 css 值
css_value = driver.findElement(By.LINK_TEXT, "More information...").value_of_css_property('color')
print(css_value)
# 获取标签的文本内容
text = driver.find_element(By.CSS_SELECTOR, "h1").text
print(text)
# 获取标签的文本内容
src = driver.find_element(By.TAG_NAME, "a").get_attribute("src")
print(src)
获取标签矩阵数据:
- 从元素左上角开始的 X 轴位置
- 从元素左上角开始的 y 轴位置
- 元素的高度
- 元素的宽度
res = driver.find_element(By.CSS_SELECTOR, "h1").rect
print(res)
8. 键盘操作
8.1 发送键
# 向 name="q" 标签中添加内容后执行回车键操作
driver.find_element(By.NAME, "q").send_keys("webdriver" + Keys.ENTER)
8.2 Ctrl, Shift, Alt 键
key_down: 在控件有焦点的情况下按下键时发生.
key_up: 在控件有焦点的情况下释放键时发生.
search = driver.find_element(By.NAME, "q")
# 获取行为对象
action = webdriver.ActionChains(driver)
# 执行 Ctrl + A
action.key_down(Keys.CONTROL).send_keys("a").perform()
# 按下 Shift 键输入 qwerty 后松开 Shift 键输入 qwerty 后提交.
action.key_down(Keys.SHIFT).send_keys_to_element(search, "qwerty").key_up(Keys.SHIFT).send_keys("qwerty").perform()
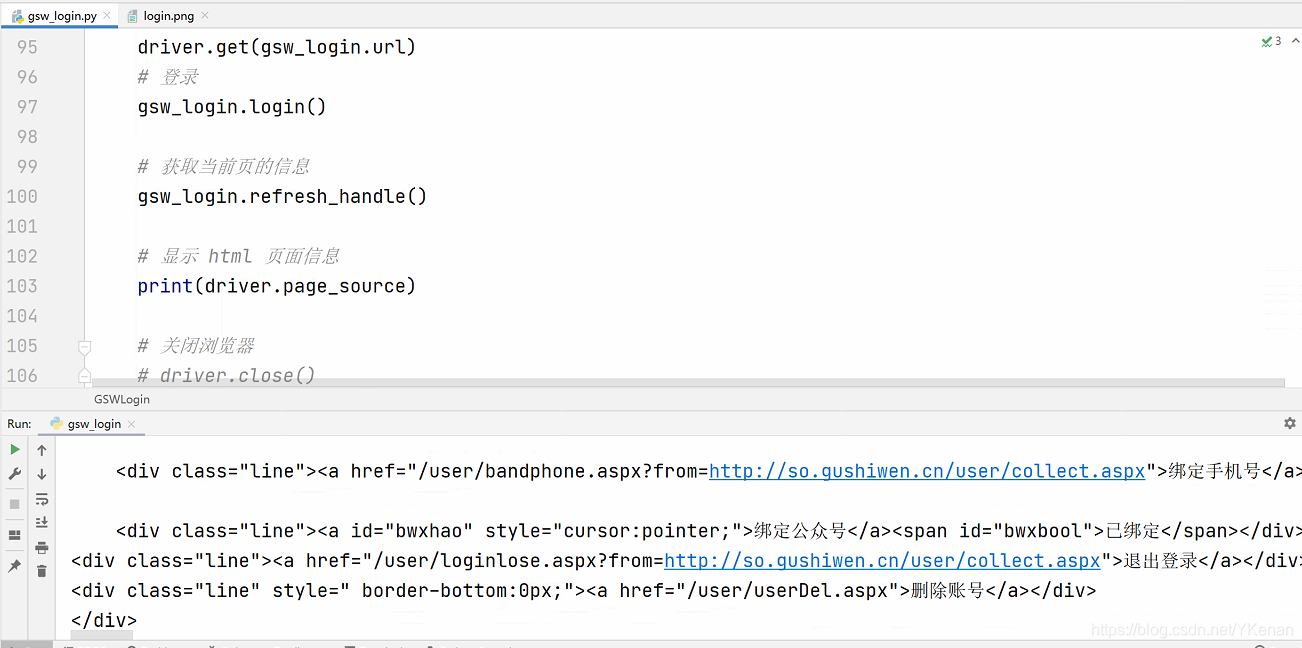
9. 登录古诗文网实例
前面通过 OCR 获取过图片验证码, 这里进行登录.
这次获取验证码不是通过连接, 而是获取元素截图得到照片识别验证码. 因为获取连接会变化.
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import time
from aip import AipOcr
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 读取文件
def get_file_content(file_path):
with open(file_path, 'rb') as fp:
return fp.read()
# 定义一个类
class GSWLogin(object):
def __init__(self, username, password, APP_ID, API_KEY, SECRET_KEY):
self.url = 'https://so.gushiwen.cn/user/login.aspx'
self.driver = webdriver.Firefox(executable_path=r"D:\install\python\python\Scripts\geckodriver.exe")
self.wait = WebDriverWait(self.driver, 30)
self.username = username
self.password = password
self.APP_ID = APP_ID
self.API_KEY = API_KEY
self.SECRET_KEY = SECRET_KEY
# 窗口处理
def refresh_handle(self, is_refresh=False):
# 得到跳转之前的页面
original_window = self.driver.current_window_handle
# 获取所有的窗口
handles = self.driver.window_handles
# 切换窗口
for handle in handles:
if handle != original_window:
# 关闭前面的窗口
self.driver.close()
self.driver.switch_to.window(handle)
# 等到新窗口的打开
self.wait.until(EC.new_window_is_opened(original_window))
# 刷新和沉睡是为了防止得到的页面代码不全
if is_refresh:
self.driver.refresh()
# 得到验证码
def get_code(self):
# SDK客户端
client = AipOcr(self.APP_ID, self.API_KEY, self.SECRET_KEY)
# 转化
url_content = get_file_content("./data/login.png")
# 调用通用文字识别(含位置信息版)
accurate_url = client.accurate(url_content)
return accurate_url["words_result"][0]["words"]
# 得到验证码照片
def get_code_image(self):
# 捕获元素进行截图
img_code = self.wait.until(EC.presence_of_element_located((By.ID, 'imgCode')))
img_code.screenshot('./data/login.png')
# 登录
def login(self):
# 获取标签
user = self.wait.until(EC.presence_of_element_located((By.ID, 'email')))
pwd = self.wait.until(EC.presence_of_element_located((By.ID, 'pwd')))
code = self.wait.until(EC.presence_of_element_located((By.ID, 'code')))
time.sleep(3)
# 清空后填写内容
user.clear()
user.send_keys(self.username)
pwd.clear()
pwd.send_keys(self.password)
code.clear()
# 得到验证码
self.get_code_image()
gsw_code = self.get_code()
print(gsw_code)
code.send_keys(gsw_code.strip())
# 点击登录
deng_lu = self.wait.until(EC.presence_of_element_located((By.ID, 'denglu')))
deng_lu.click()
if __name__ == '__main__':
# 实例化对象
gsw_login = GSWLogin("username", "password", "APP_ID", "API_KEY", "SECRET_KEY")
driver = gsw_login.driver
wait = gsw_login.wait
# 请求古诗文网界面
driver.get(gsw_login.url)
# 登录
gsw_login.login()
# 获取当前页的信息
gsw_login.refresh_handle()
# 显示 html 页面信息
print(driver.page_source)
# 关闭浏览器
# driver.close()