Greenplum基本概念
https://gp-docs-cn.github.io/docs/admin_guide/intro/arch_overview.html
Greenplum数据库是一种大规模并行处理(MPP)数据库,其架构特别针对管理大规模分析型数据仓库以及商业智能工作负载而设计。MPP(也被称为shared nothing架构)指有多个处理器协同执行一个操作的系统,每一个处理器都有其自己的内存、操作系统和磁盘。Greenplum使用这种高性能系统架构来分布数T字节数据仓库的负载并且能够使用系统的所有资源并行处理一个查询。
Greenplum数据库是基于PostgreSQL 8.3.23开发且面向磁盘的数据库实例,形成一个紧密结合的数据库管理系统(DBMS)。其SQL支持、特性、配置选项和最终用户功能在大部分情况下和PostgreSQL非常相似。与Greenplum数据库交互的数据库用户会感觉在使用一个常规的PostgreSQL DBMS。
Greenplum数据库可以使用追加优化(append-optimized,AO)的存储格式来批量装载和读取数据,并且能提供HEAP表上的性能优势。追加优化的存储为数据保护、压缩和行/列方向提供了校验和。行式或者列式追加优化的表都可以被压缩。
Greenplum数据库和PostgreSQL的主要区别在于:
- 为了支持Greenplum数据库的并行结构,PostgreSQL的内部已经被修改或者增补。例如,系统目录、优化器、查询执行器以及事务管理器组件都已经被修改或者增强,以便能够在所有的并行PostgreSQL数据库实例之上同时执行查询。Greenplum的Interconnect(网络层)允许在不同的PostgreSQL实例之间通讯,让系统表现为一个逻辑数据库。
- Greenplum数据库可以选用列式存储,数据在逻辑上还是组织成一个表,但其中的行和列在物理上是存储在一种面向列的格式中,而不是存储成行。列式存储只能和追加优化表一起使用。列式存储是可压缩的。当用户只需要返回感兴趣的列时,列式存储可以提供更好的性能。所有的压缩算法都可以用在行式或者列式存储的表上,但是行程编码(RLE)压缩只能用于列式存储的表。Greenplum数据库在所有使用列式存储的追加优化表上都提供了压缩。
Greenplum数据库的查询使用一种火山式查询引擎模型,其中的执行引擎拿到一个执行计划并且用它产生一棵物理操作符树,然后通过物理操作符计算表,最后返回结果作为查询响应。
通过将数据和处理负载分布在多个服务器或者主机上来存储和处理大量的数据。Greenplum数据库是一个基于PostgreSQL 8.3的数据库组成的阵列,阵列中的数据库工作在一起呈现了一个单一数据库的景象。Master是Greenplum数据库系统的入口。客户端会连接到这个数据库实例并且提交SQL语句。Master会协调与系统中其他称为Segment的数据库实例一起工作,Segment负责存储和处理数据。
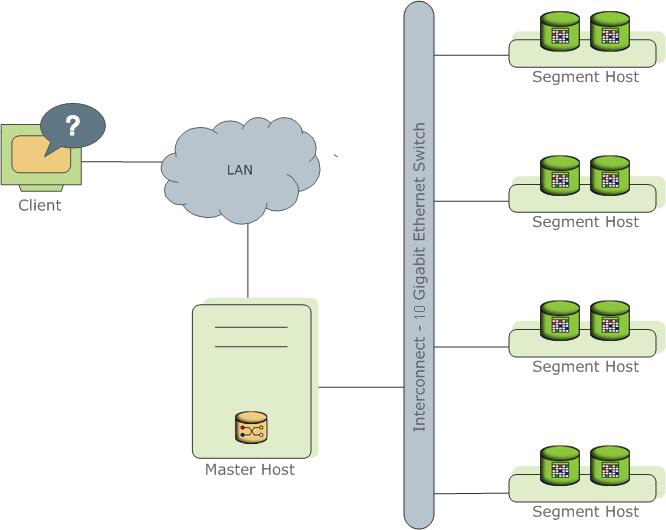
Greenplum的Master
Greenplum数据库的Master是整个Greenplum数据库系统的入口,它接受连接和SQL查询并且把工作分布到Segment实例上,与Greenplum数据库(通过Master)交互时,会觉得他们是在与一个典型的PostgreSQL数据库交互,可以使用psql之类的客户端或者JDBC、ODBC、libpq(PostgreSQL的C语言API)等应用编程接口(API)连接到数据库。
Master是全局系统目录的所在,全局系统目录包含有关Greenplum数据库系统本身的元数据的系统表,Master上不包含任何用户数据,数据只存在于Segment之上。Master会认证客户端连接、处理到来的SQL命令、在Segment之间分布工作负载、协调每一个Segment返回的结果以及把最终结果呈现给客户端程序。
Greenplum数据库使用预写式日志(WAL)来实现主/备镜像。在基于WAL的日志中,所有的修改都会在应用之前被写入日志,以确保对于任何正在处理的操作的数据完整性。
Greenplum的Segment
Greenplum数据库的Segment实例是独立的PostgreSQL数据库,每一个都存储了数据的一部分并且执行查询处理的主要部分。当一个用户通过Greenplum的Master连接到数据库并且发出一个查询时,在每一个Segment数据库上都会创建一些进程来处理该查询的工作。
用户定义的表及其索引会可用的Segment上,Segment包含数据的不同部分。服务于Segment数据的数据库服务器进程运行在相应的Segment实例之下。用户通过Master与一个Greenplum数据库系统中的Segment交互,一台Segment主机通常运行2至8个Greenplum的Segment,这取决于CPU核数、RAM、存储、网络接口和工作负载。Segment主机预期都以相同的方式配置。从Greenplum数据库获得最佳性能的关键在于在大量能力相同的Segment之间平均地分布数据和工作负载,这样所有的Segment可以同时开始为一个任务工作并且同时完成它们的工作。
Greenplum的查询分发
Master接收解析并且优化查询。作为结果的查询计划可能是并行的或者定向的。Master会把并行查询计划分发到所有的Segment。把定向查询计划分发到单一的一个Segment。每个Segment负责在其自己的数据集上执行本地数据库操作。大部分的数据库操作(例如表扫描、连接、聚集和排序)都会以并行的方式在所有Segment上执行。在一个Segment的数据库上执行的每个操作都独立于存储在其他Segment数据库中的数据。
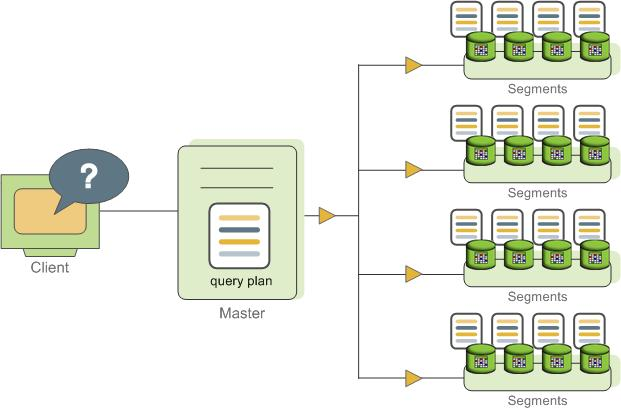
某些查询可能只访问单个Segment上的数据,例如单行的INSERT、UPDATE、DELETE或者SELECT操作或者以表分布键列过滤的查询。在这些查询中,查询计划不会被分发到所有的Segment,而是定向给到包含受影响或者相关行的Segment。
除通常的数据库操作(例如表扫描、连接等等)之外,Greenplum数据库还有“移动”的操作,移动涉及Segment之间移动元组,并非每一个查询都需要移动操作(定向查询计划就不需要通过Interconnect移动数据),为了在查询执行期间达到最大并行度,Greenplum将查询计划的工作划分成切片。切片是Segment能够在其上独立工作的计划片段。只要有一个移动操作出现在计划中,该查询计划就会被切片,在移动的两端分别有一个切片。考虑下面涉及两个表之间连接的简单查询:
SELECT customer, amount
FROM sales JOIN customer USING (cust_id)
WHERE dateCol = '04-30-2016';这个例子的重分布移动是必要的,需要Segment之间移动元组以完成连接,因为customer表在Segment上按照cust_id分布,而sales表是按照sale_id分布。为了执行该连接,sales元组必须按照cust_id重新分布,该计划在重分布移动操作的两边被切换,形成了slice 1和slice 2。这个查询计划由另一种称为收集移动的移动操作。收集操作表示Segment何时将结果发回给Master,Master再将结果呈现给客户端。由于只要有移动产生查询计划就会被切片,这个计划在其最顶层也有一个隐式的切片(slice 3)。不是所有的查询计划都涉及收集移动。例如,一个CREATE TABLE x AS SELECT...语句不会有收集移动,因为元组都被发送到新创建的表而不是发给Master。
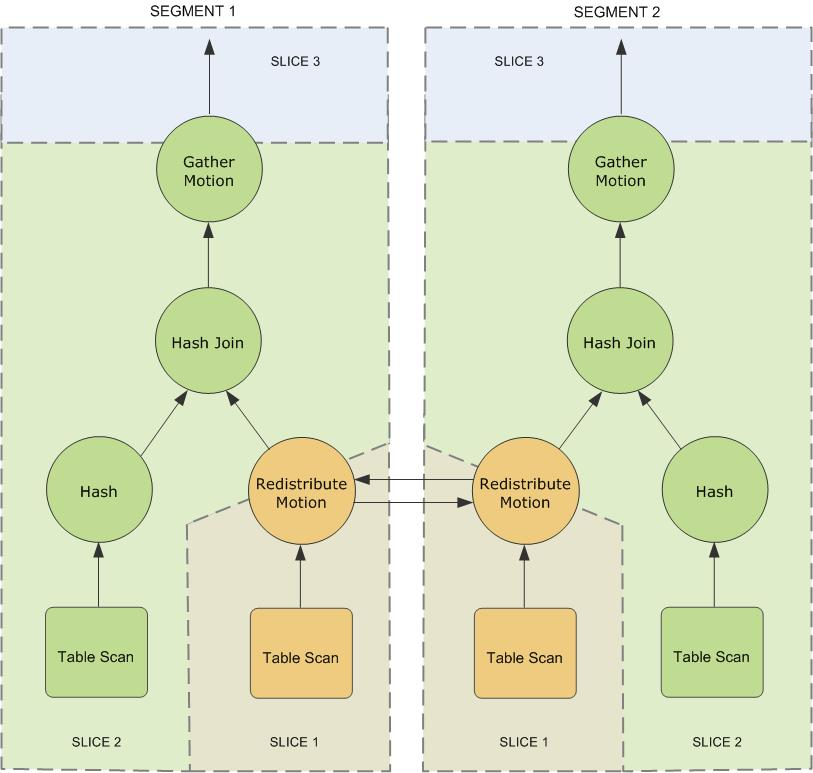
Greenplum会创建若干数据库进程来处理查询的工作。在Master上,查询工作者进程被称作查询分发器(QD)。QD负责创建并且分发查询计划。它也收集并且表达最终的结果。在Segment上,查询工作者进程被称为查询执行器(QE)。QE负责完成它那一部分的工作并且与其他工作者进程交流它的中间结果。对查询计划的每一个切片至少要分配一个工作者进程。工作者进程独立地工作在分配给它的那部分查询计划上。在查询执行期间,每个Segment将有若干进程并行地为该查询工作。
为查询计划的同一个切片工作但位于不同Segment上的相关进程被称作团伙。随着部分工作的完成,元组会从一个进程团伙流向查询计划中的下一个团伙。这种Segment之间的进程间通信被称作Greenplum数据库的Interconnect组件。

Greenplum数据库的集群管理和状态查看
Greenplum数据库提供了标准的命令行工具来执行通常的监控和管理任务。Greenplum的命令行工具位于 $GPHOME/bin目录中并且在Master主机上执行。Greenplum为下列管理任务提供了实用工具:
- 在一个阵列上安装Greenplum数据库
- 初始化一个Greenplum数据库系统
- 开始和停止Greenplum数据库
- 增加或者移除一个主机
- 扩展阵列并且在新的Segment上重新分布表
- 恢复失效的Segment实例
- 管理失效Master实例的故障切换和恢复
- 备份和恢复一个数据库(并行)
- 并行装载数据
- 在Greenplum数据库之间转移数据
- 系统状态报告
1、查看segment节点状态
select * from gp_segment_configuration;
pgdb=# select * from gp_segment_configuration;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
------+---------+------+----------------+------+--------+------+-------------+-------------+-----------------------------
1 | -1 | p | p | n | u | 5432 | greenplum-1 | greenplum-1 | /data/gpdata/master/gpseg-1
2 | 0 | p | p | n | u | 6000 | greenplum-2 | greenplum-2 | /data/gpdata/pdata/gpseg0
3 | 1 | p | p | n | u | 6000 | greenplum-3 | greenplum-3 | /data/gpdata/pdata/gpseg1
4 | 0 | m | m | n | d | 7000 | greenplum-3 | greenplum-3 | /data/gpdata/mdata/gpseg0
5 | 1 | m | m | n | d | 7000 | greenplum-2 | greenplum-2 | /data/gpdata/mdata/gpseg12、查看segment节点故障等历史信息
select * from gp_configuration_history order by 1 desc ;3、gpstate工具提供查看数据库系统的状态信息,检查segment instance同步状态
gpstate -m该命令会输出各节点实例的同步状态,各节点的状态为“synchronizing”时为不正常,如果有数据,表示segment instance正在同步,隔几分钟再做一次,如果有实例长时间都不能同步完成,需要报给DBA做进一步监控
4、查看segment节点磁盘空闲情况
SELECT * FROM gp_toolkit.gp_disk_free;5、检查standby同步状态
gpstate -f该命令会输出Standby Master的同步状态,Standby Master状态为“synchronizing”时为不正常;要查看Greenplum数据库阵列配置更详细的信息,使用带有-s选项的gpstate;
gpstate -s6、greenplum提供pgssh指令,能够批量对pg集群的节点进行操作,比如:
gpssh -f ~/gpconfigs/hostfile_segonly -e "df -h |grep /data"
[gpadmin@greenplum-1 gpconfigs]$ gpssh -f ~/gpconfigs/hostfile_segonly -e "df -h |grep /data"
[greenplum-3] df -h |grep /data
[greenplum-3] /dev/vdb 197G 724M 187G 1% /data
[greenplum-2] df -h |grep /data
[greenplum-2] /dev/vdb 197G 724M 187G 1% /data7、完成所有配置后,初始化数据库;-c 跟初始化的系统参数,-h 后跟segment列表
gpinitsystem -c /home/gpadmin/gpconfigs/gpinitsystem_config -h /home/gpadmin/gpconfigs/hostfile_segonly8、启动集群
gpstart9、重启集群
gpstop -r10、查看数据磁盘
Master和Segment数据满了就会阻止正常的数据库活动继续。如果磁盘增长得太满,可能会导致数据库服务器关闭。可以使用gp_toolkit管理方案中的gp_disk_free外部表来检查Segment主机文件系统中的剩余空闲空间(以千字节计)。
SELECT * FROM gp_toolkit.gp_disk_free ORDER BY dfsegment;11、查看每个库的存储代销
查看数据库的总尺寸(以字节计),使用gp_toolkit管理方案中的gp_size_of_database视图。例如:
SELECT * FROM gp_toolkit.gp_size_of_database ORDER BY sodddatname;12、查看表占用的磁盘大小
SELECT relname AS name, sotdsize AS size, sotdtoastsize
AS toast, sotdadditionalsize AS other
FROM gp_toolkit.gp_size_of_table_disk as sotd, pg_class
WHERE sotd.sotdoid=pg_class.oid ORDER BY relname;