0 说明
本文基于《CDH数仓项目(一) —— CDH安装部署搭建详细流程》开始搭建数仓
1 数仓搭建环境准备
1.1 Flume安装部署
1)添加服务
2) 选择Flume
3)选择依赖
4)选择部署节点
5) 安装完成
1.2 安装Sqoop
1)添加服务
2)选择Sqoop
3)选择部署节点
4)完成安装部署
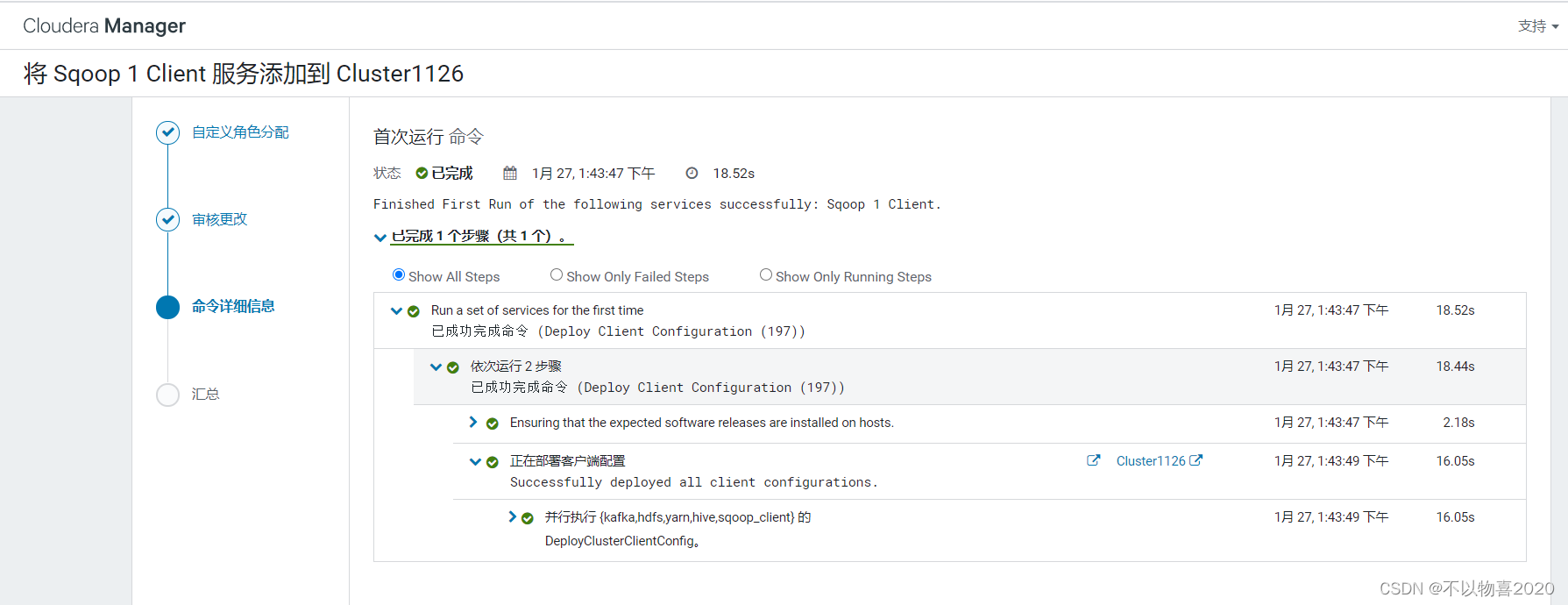
1.3 配置Hadoop支持LZO
1)点击主机,在下拉菜单中点击Parcel
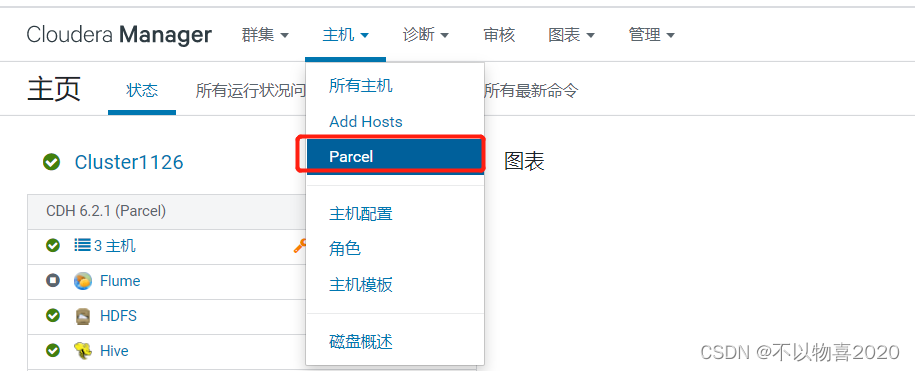
2)点击配置
3)任意选一个加上parcel库的url
本地url: http://chen102:8900/cloudera-repos/gplextras6/6.2.1/parcels/
远程url: https://archive.cloudera.com/gplextras6/6.2.1/parcels/
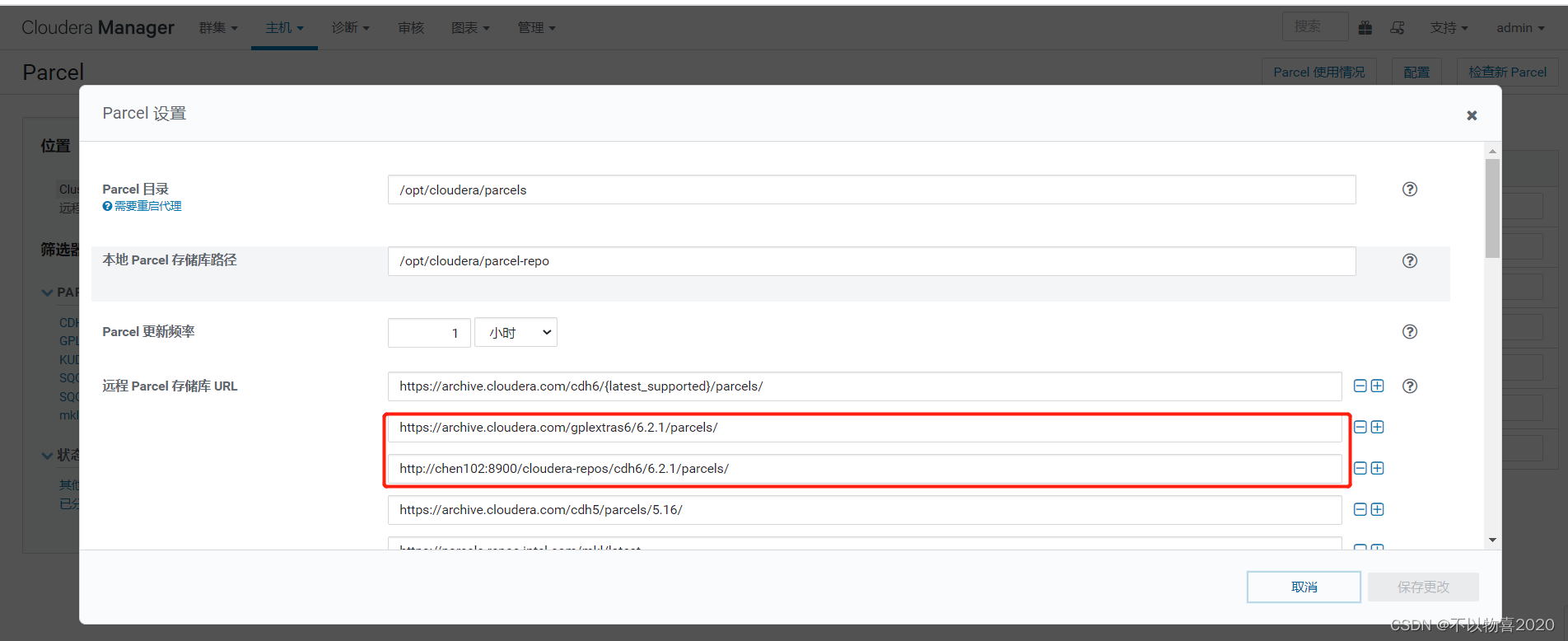
4)静待片刻,Parcel列表中出现了GPLEXTERAS,依次点击下载、分配、激活。
5)修改HDFS配置
在HDFS配置项中搜索“压缩编码解码器”,加入com.hadoop.compression.lzo.LzopCodec
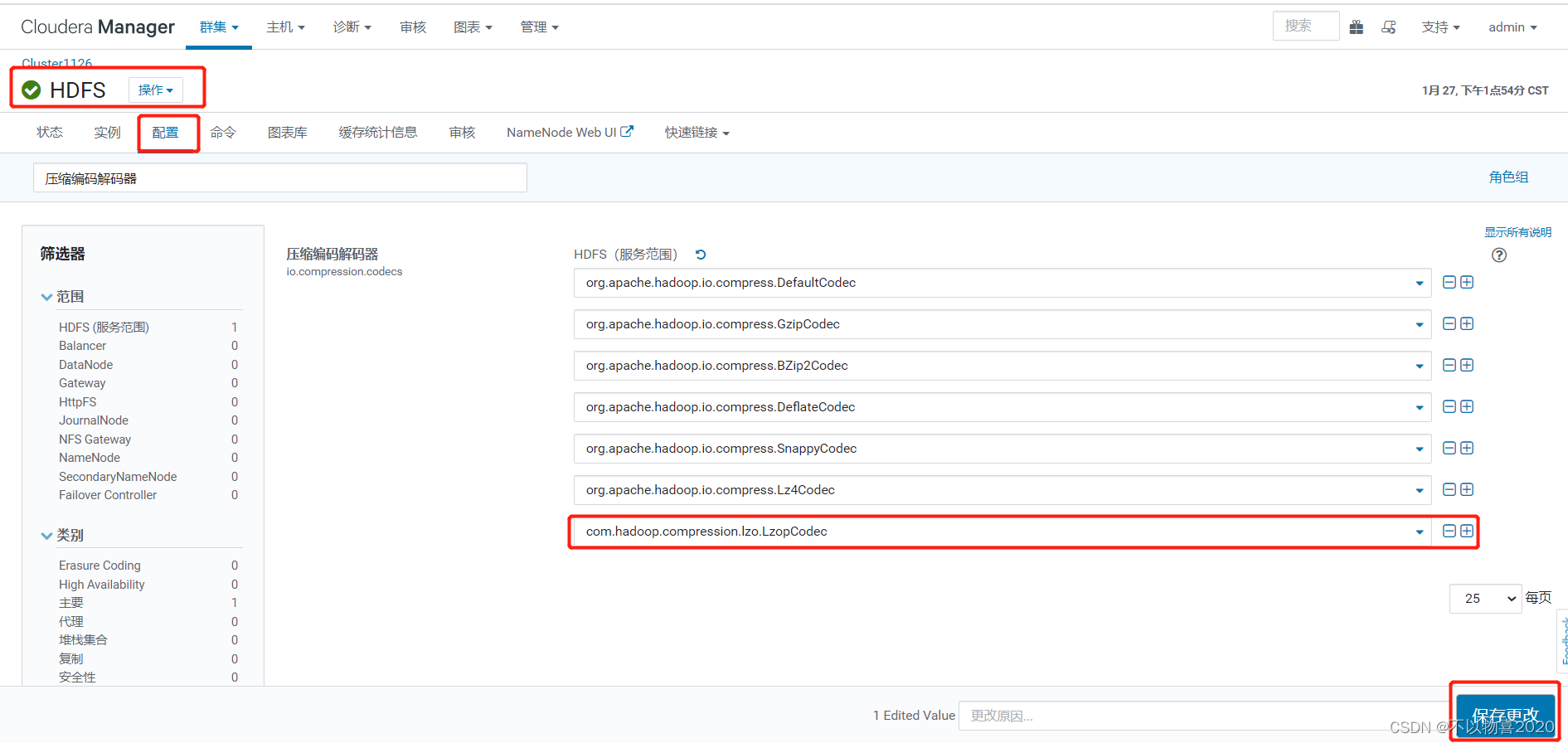
6)修改Hive配置
在Hive配置项中搜索“Hive 辅助 JAR 目录”,加入/opt/cloudera/parcels/GPLEXTRAS/lib/hadoop/lib
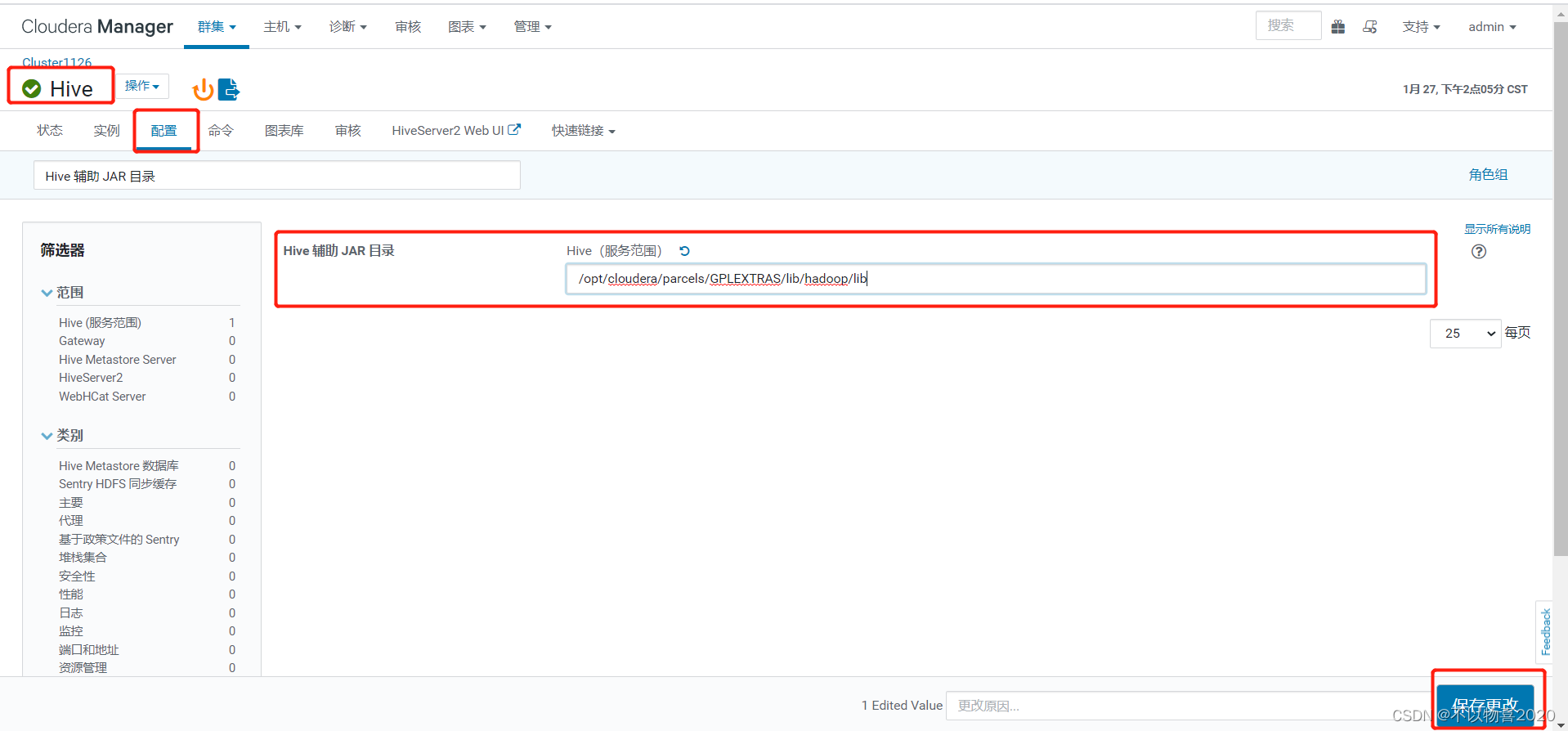
7)修改Sqoop配置
在Sqoop的配置项中搜索“sqoop-conf/sqoop-env.sh 的 Sqoop 1 Client 客户端高级配置代码段(安全阀)”,加入以下字段
HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/cloudera/parcels/GPLEXTRAS/lib/hadoop/lib/*
JAVA_LIBRARY_PATH=$JAVA_LIBRARY_PATH:/opt/cloudera/parcels/GPLEXTRAS/lib/hadoop/lib/native
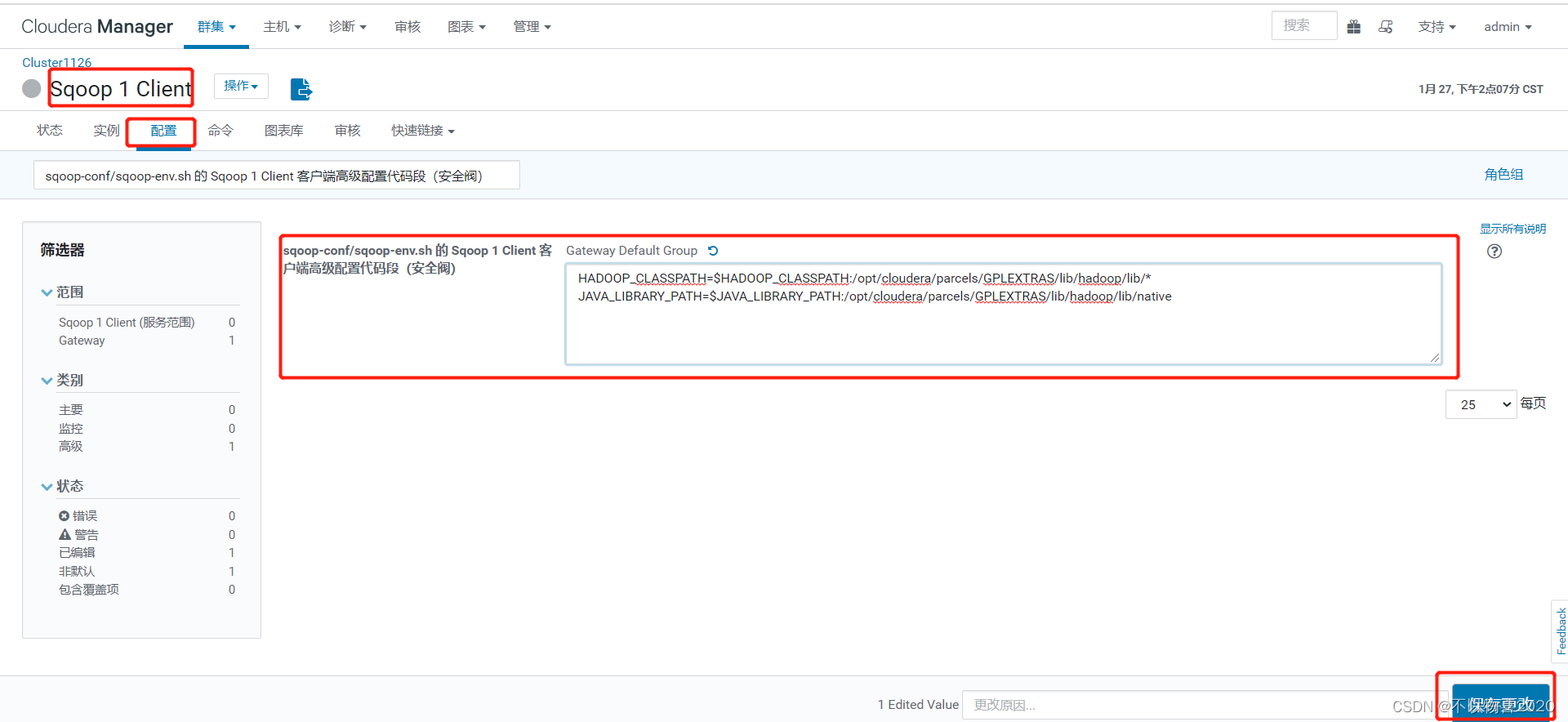
1.4 修改yarn配置
1)在yarn配置项中搜索“yarn.nodemanager.resource.memory-mb”,修改成4G。
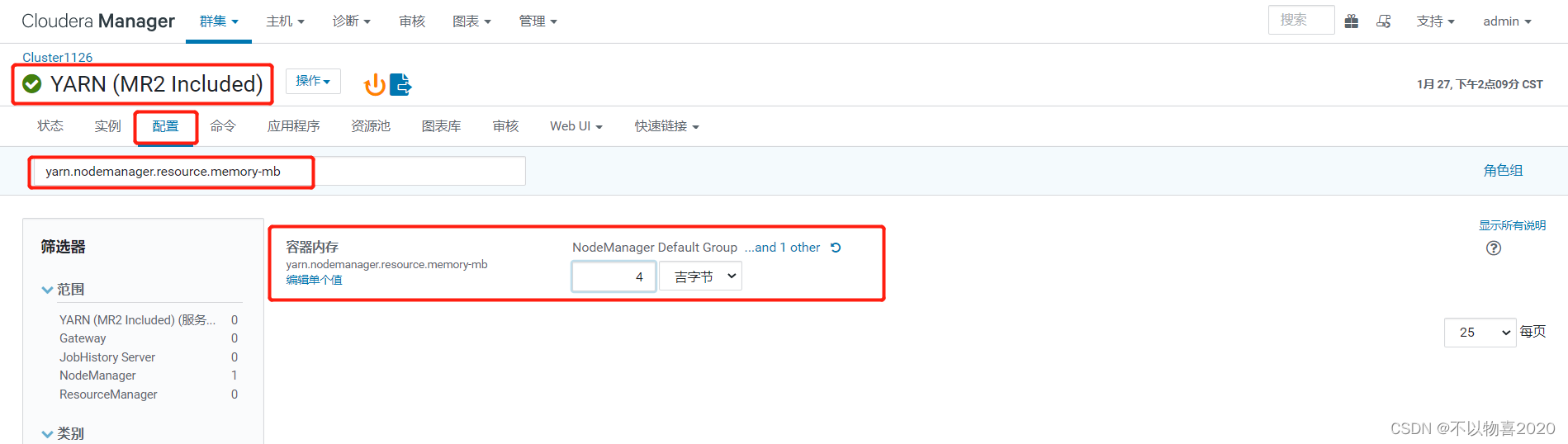
2)在yarn配置项中搜索“yarn.scheduler.maximum-allocation-mb”,修改成2G。
3)重启相关组件
2 HUE使用概述
2.1 来源
HUE=Hadoop User Experience(Hadoop用户体验),直白来说就一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。通过使用HUE我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据。
2.2 Hue用户管理
HUE的初始管理用户为admin,密码为admin。
1)在HUE中新建一个用户组——hive,并在该组下新建一个用户——hive。
(1)创建hive组

(2)创建hive用户

2)切换为hive用户
3 用户行为数仓搭建
3.1 日志采集Flume
3.1.1 用户行为日志生成
1)将log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar上传到chen102
该jar包百度云连接如下:
链接:https://pan.baidu.com/s/1aoFH-Uu8OhG1siRqHQQZSQ
提取码:zx1q
2)分发log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar到chen103
3.1.2 日志采集Flume配置
1)集群规划
| 服务器chen102 | 服务器chen103 | 服务器chen104 |
|---|---|---|
| Flume(日志采集) | Flume | Flume |
2)Flume配置分析
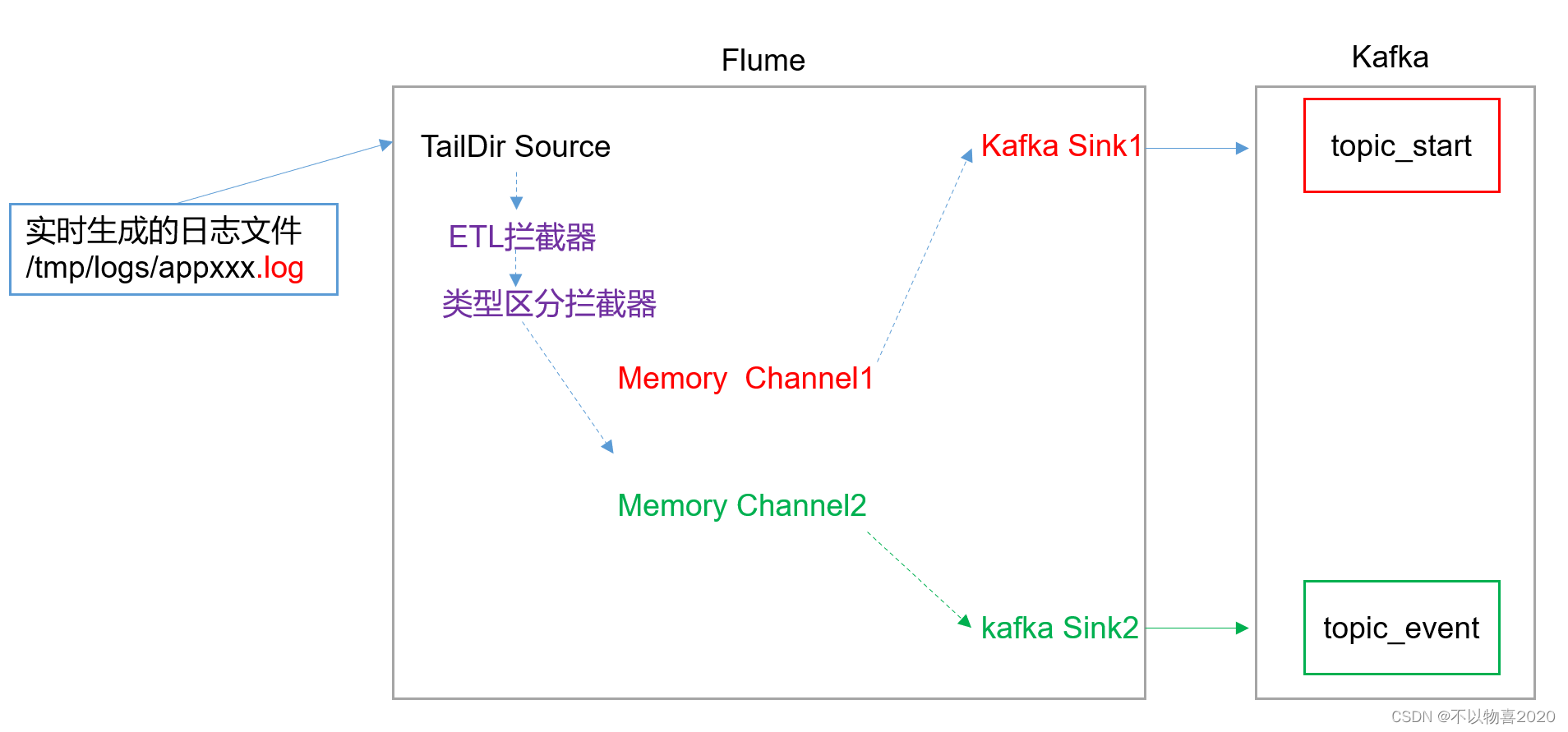
Flume直接读log日志的数据,log日志的格式是app-yyyy-mm-dd.log。
3)Flume的具体配置如下:
(1)在CM管理页面上点击Flume
(2)点击实例
(3)点击chen102的Agent选项
(4)点击配置
(5)对Flume Agent进行具体配置
内容如下:
a1.sources=r1
a1.channels=c1 c2
a1.sinks=k1 k2
# configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.atguigu.flume.interceptor.LogTypeInterceptor$Builder
# selector
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
# configure channel
a1.channels.c1.type = memory
a1.channels.c1.capacity=10000
a1.channels.c1.byteCapacityBufferPercentage=20
a1.channels.c2.type = memory
a1.channels.c2.capacity=10000
a1.channels.c2.byteCapacityBufferPercentage=20
# configure sink
# start-sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = topic_start
a1.sinks.k1.kafka.bootstrap.servers = chen102:9092,chen103:9092,chen104:9092
a1.sinks.k1.kafka.flumeBatchSize = 2000
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.channel = c1
# event-sink
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.topic = topic_event
a1.sinks.k2.kafka.bootstrap.servers = chen102:9092,chen103:9092,chen104:9092
a1.sinks.k2.kafka.flumeBatchSize = 2000
a1.sinks.k2.kafka.producer.acks = 1
a1.sinks.k2.channel = c2
注意:com.atguigu.flume.interceptor.LogETLInterceptor和com.atguigu.flume.interceptor.LogTypeInterceptor是自定义的拦截器的全类名。需要根据用户自定义的拦截器做相应修改。
(6)在chen103上重复相同的操作
4)将自定义的拦截器flume-interceptor-1.0-SNAPSHOT.jar包放入到chen102的/opt/cloudera/parcels/CDH/lib/flume-ng/lib文件夹下面。如果没有自定义拦截器可以取消
5)分发Flume的jar包到chen103
3.1.3 消费Kafka Flume配置
1)集群规划
| chen102 | chen103 | chen104 |
|---|---|---|
| Flume(消费kafka) |
2)Flume配置分析
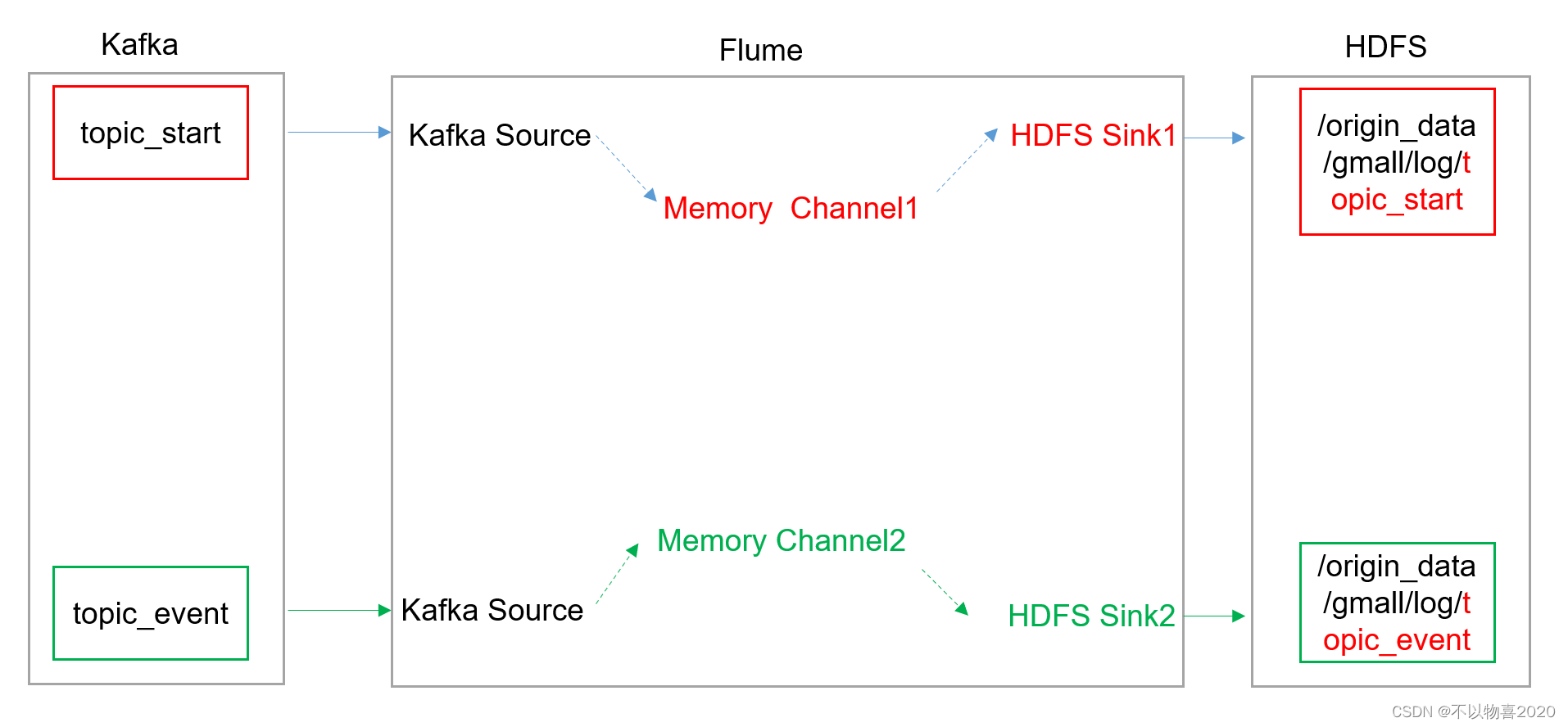
3)Flume的具体配置如下:
(1)在CM管理页面chen104上Flume的配置中找到代理名称
a1
在配置文件如下内容(kafka-hdfs)
## 组件
a1.sources=r1 r2
a1.channels=c1 c2
a1.sinks=k1 k2
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_start
## source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.kafka.bootstrap.servers = chen102:9092,chen103:9092,chen104:9092
a1.sources.r2.kafka.topics=topic_event
## channel1
a1.channels.c1.type=memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=10000
## channel2
a1.channels.c2.type=memory
a1.channels.c2.capacity=100000
a1.channels.c2.transactionCapacity=10000
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.proxyUser=hive
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logstart-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
##sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.proxyUser=hive
a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
a1.sinks.k2.hdfs.round = true
a1.sinks.k2.hdfs.roundValue = 10
a1.sinks.k2.hdfs.roundUnit = second
## 不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2
3.1.4 模拟生成日志
1)确保Flume、Kafka等服务正常运行
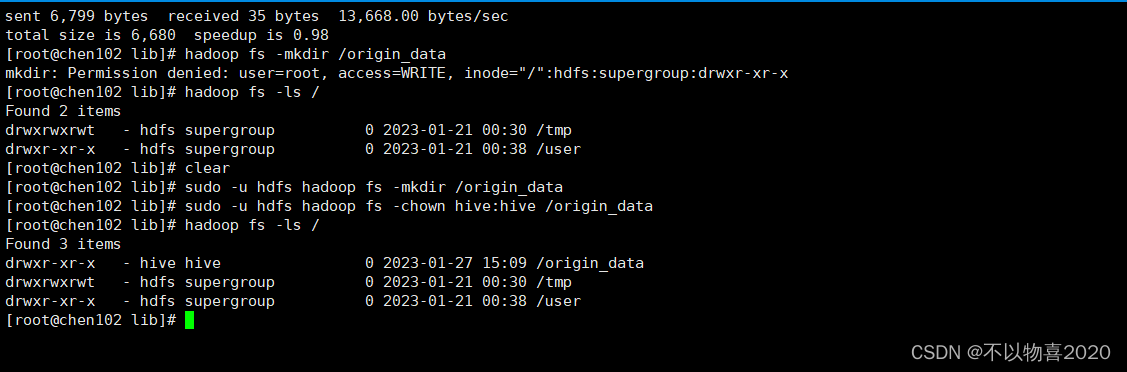
2)在HDFS创建/origin_data路径,并修改所有者为hive
sudo -u hdfs hadoop fs -mkdir /origin_data
sudo -u hdfs hadoop fs -chown hive:hive /origin_data
3)调用命令或脚本生成日志
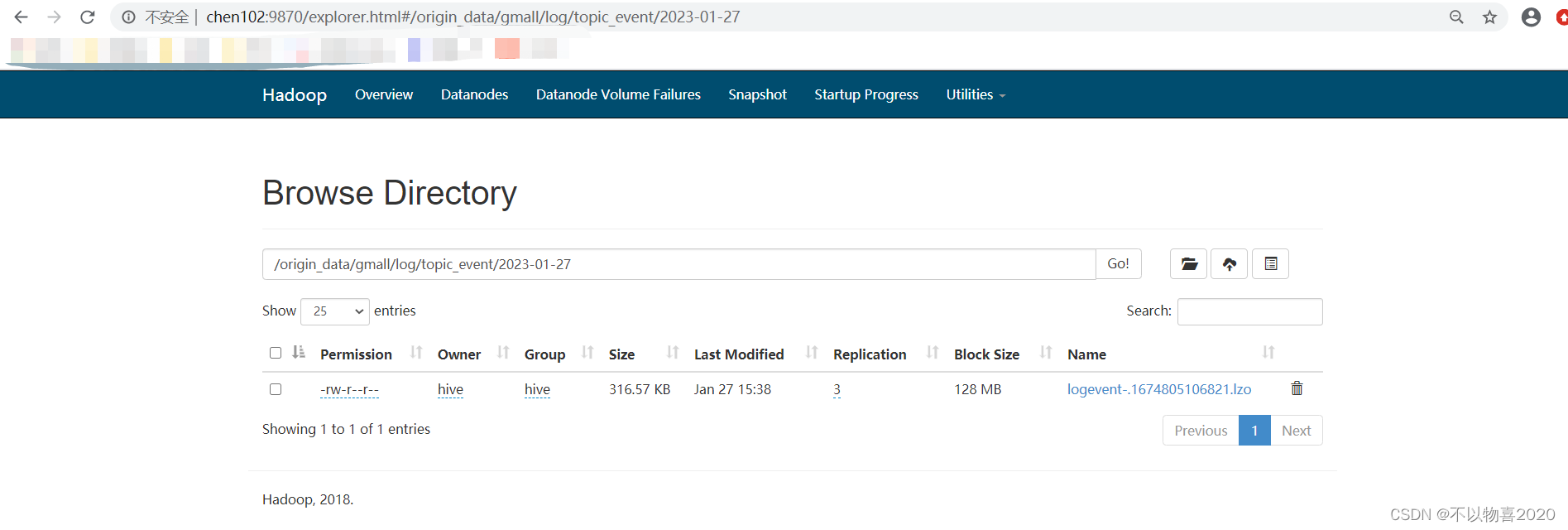
4)登录HDFS-WEBUI
可以发现能够正常采集到相应的日志数据,并生成了目录
3.2 数仓ODS层
3.2.1 创建数据库
1)创建数据仓库目录,并修改所有者
sudo -u hdfs hadoop fs -mkdir /warehouse
sudo -u hdfs hadoop fs -chown hive:hive /warehouse
2)修改hive配置
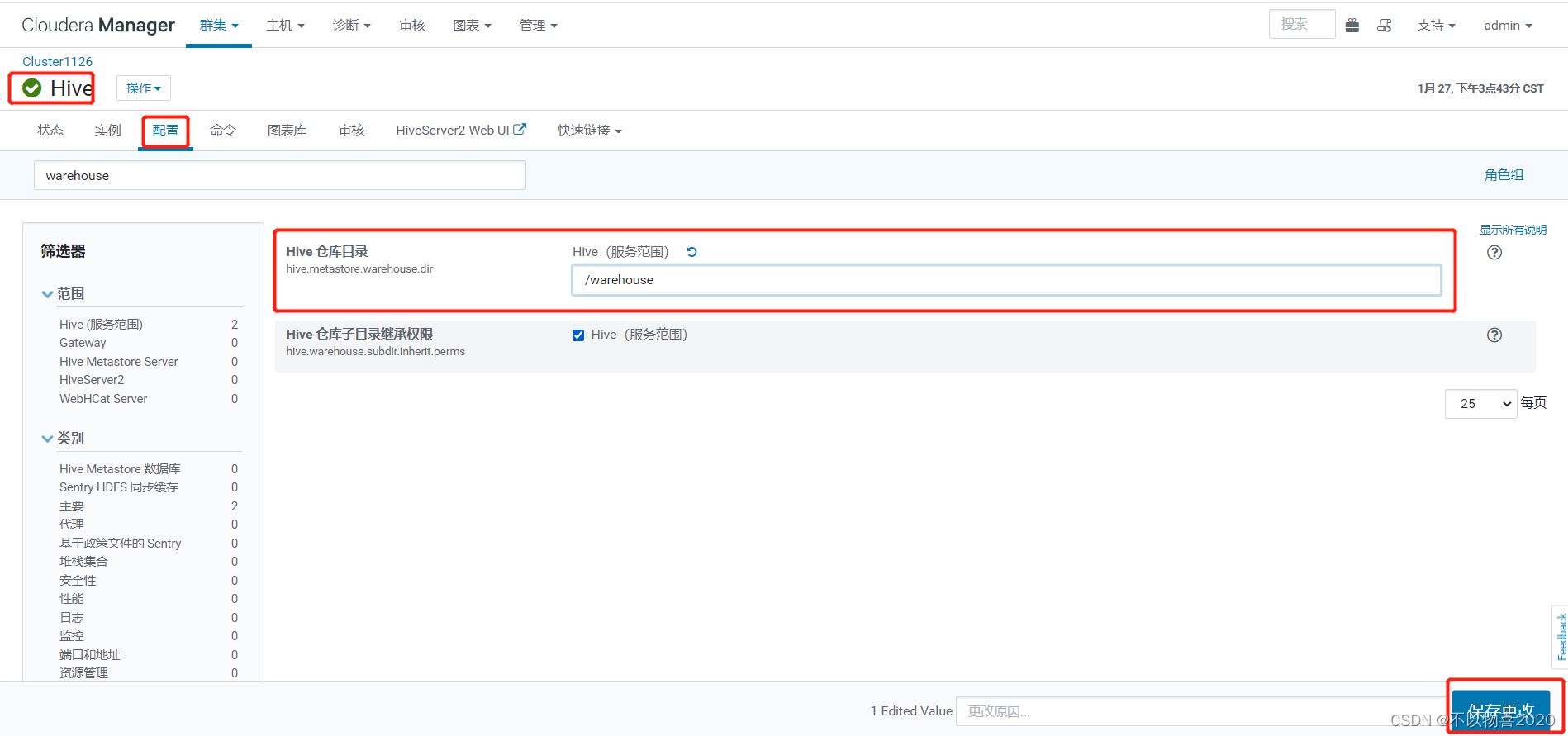
3)使用hue组件的hive用户进行操作
4)创建gmall数据库
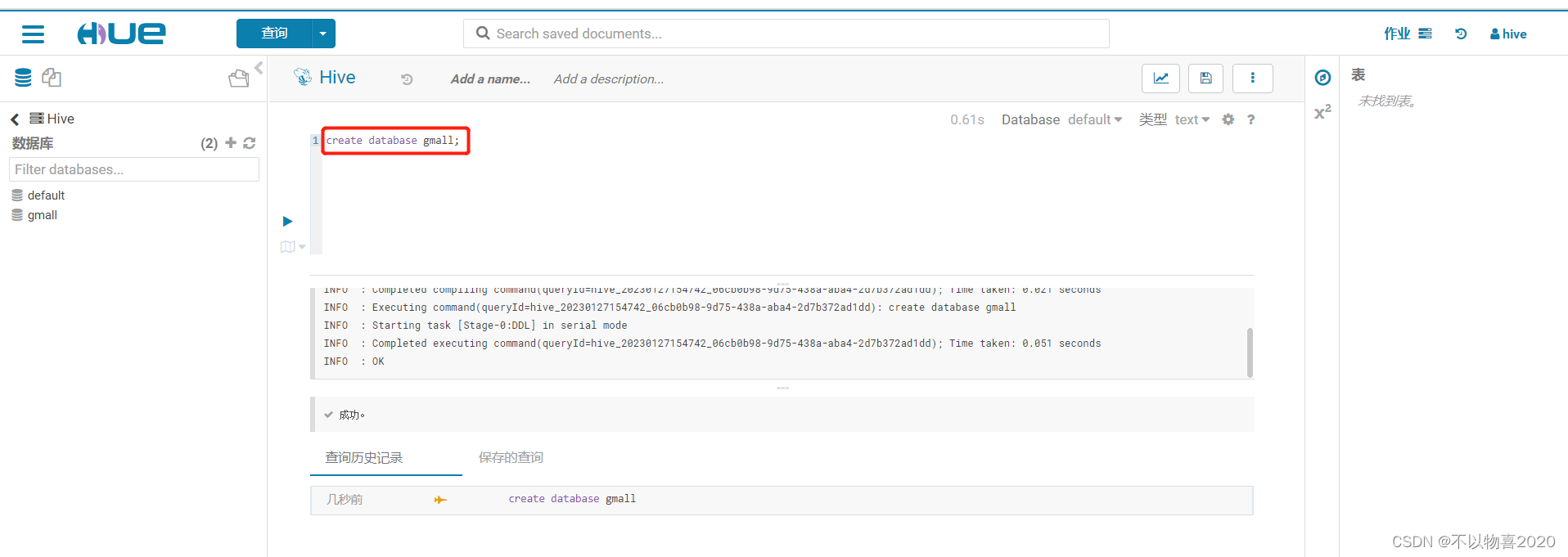
5)使用gmall数据库
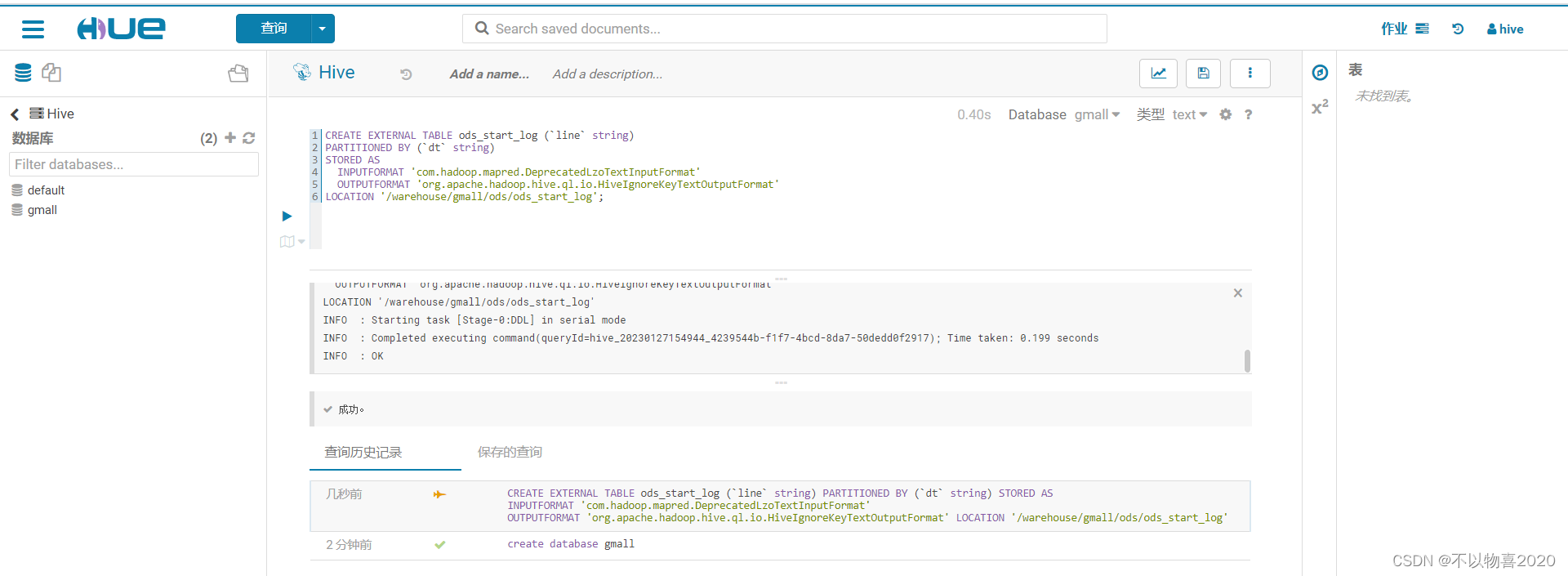
3.2.2 创建启动日志表
CREATE EXTERNAL TABLE ods_start_log (`line` string)
PARTITIONED BY (`dt` string)
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_start_log';
3.2.3 ods层加载数据脚本
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
echo "===日志日期为 $do_date==="
sql="
load data inpath '/origin_data/gmall/log/topic_start/$do_date' into table "$APP".ods_start_log partition(dt='$do_date');
"
beeline -u "jdbc:hive2://chen102:10000/" -n hive -e "$sql"
3.2.4 执行脚本
sh ods_log.sh 2023-01-27
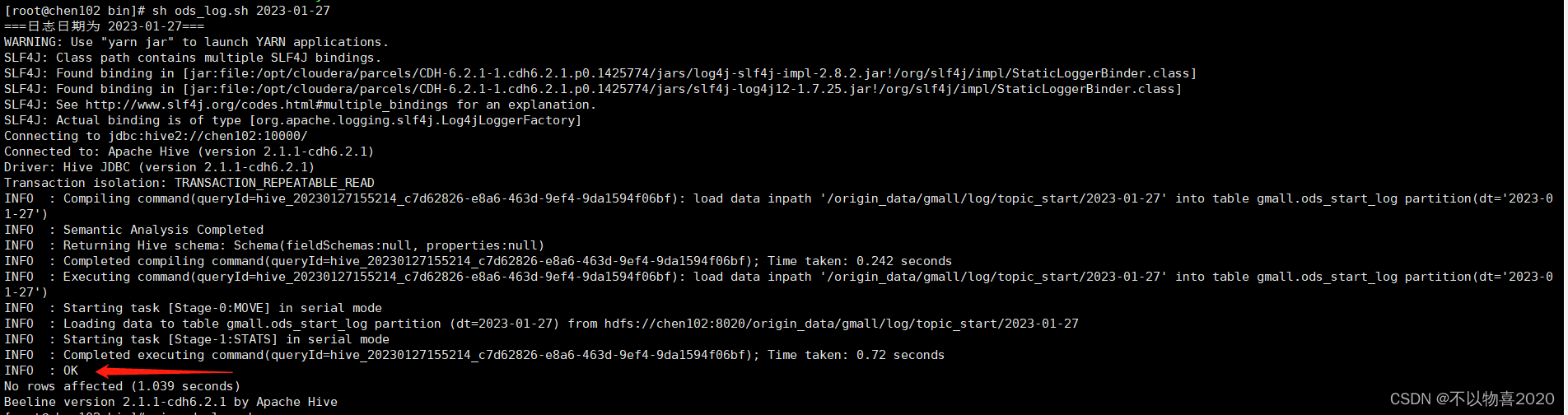
可在hue页面查看数据是否导入成功
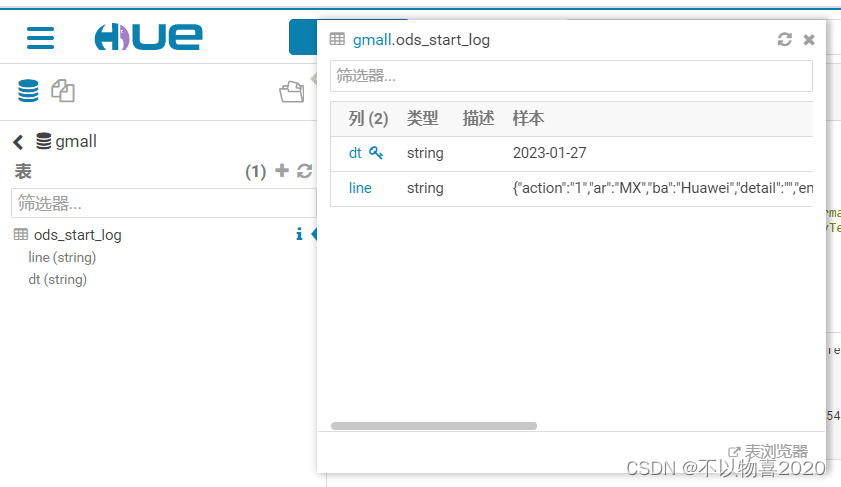
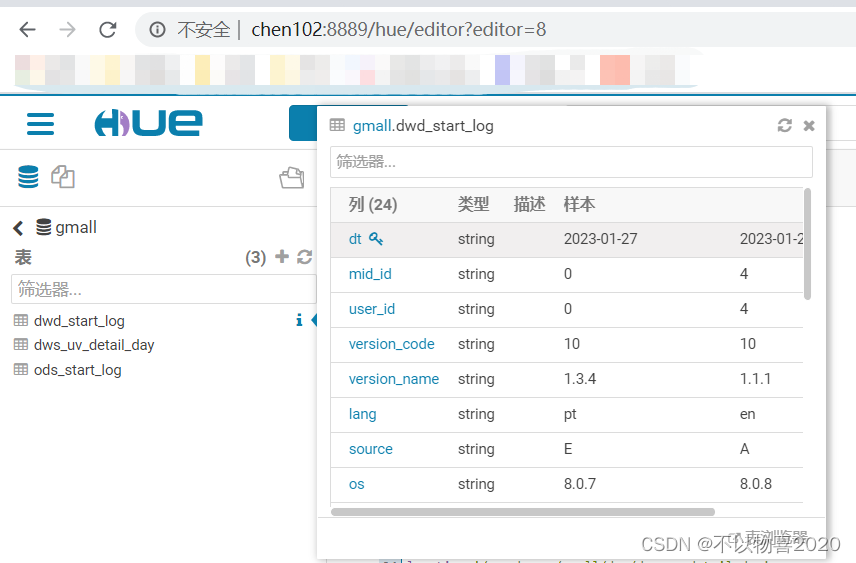
3.3 DWD层
3.3.1 创建启动表
drop table if exists dwd_start_log;
CREATE EXTERNAL TABLE dwd_start_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`entry` string,
`open_ad_type` string,
`action` string,
`loading_time` string,
`detail` string,
`extend1` string
)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_start_log/';
3.3.2 DWD数据导入脚本
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table "$APP".dwd_start_log
PARTITION (dt='$do_date')
select
get_json_object(line,'$.mid') mid_id,
get_json_object(line,'$.uid') user_id,
get_json_object(line,'$.vc') version_code,
get_json_object(line,'$.vn') version_name,
get_json_object(line,'$.l') lang,
get_json_object(line,'$.sr') source,
get_json_object(line,'$.os') os,
get_json_object(line,'$.ar') area,
get_json_object(line,'$.md') model,
get_json_object(line,'$.ba') brand,
get_json_object(line,'$.sv') sdk_version,
get_json_object(line,'$.g') gmail,
get_json_object(line,'$.hw') height_width,
get_json_object(line,'$.t') app_time,
get_json_object(line,'$.nw') network,
get_json_object(line,'$.ln') lng,
get_json_object(line,'$.la') lat,
get_json_object(line,'$.entry') entry,
get_json_object(line,'$.open_ad_type') open_ad_type,
get_json_object(line,'$.action') action,
get_json_object(line,'$.loading_time') loading_time,
get_json_object(line,'$.detail') detail,
get_json_object(line,'$.extend1') extend1
from "$APP".ods_start_log
where dt='$do_date';
"
beeline -u "jdbc:hive2://chen102:10000/" -n hive -e "$sql"
3.3.3 执行脚本并验证
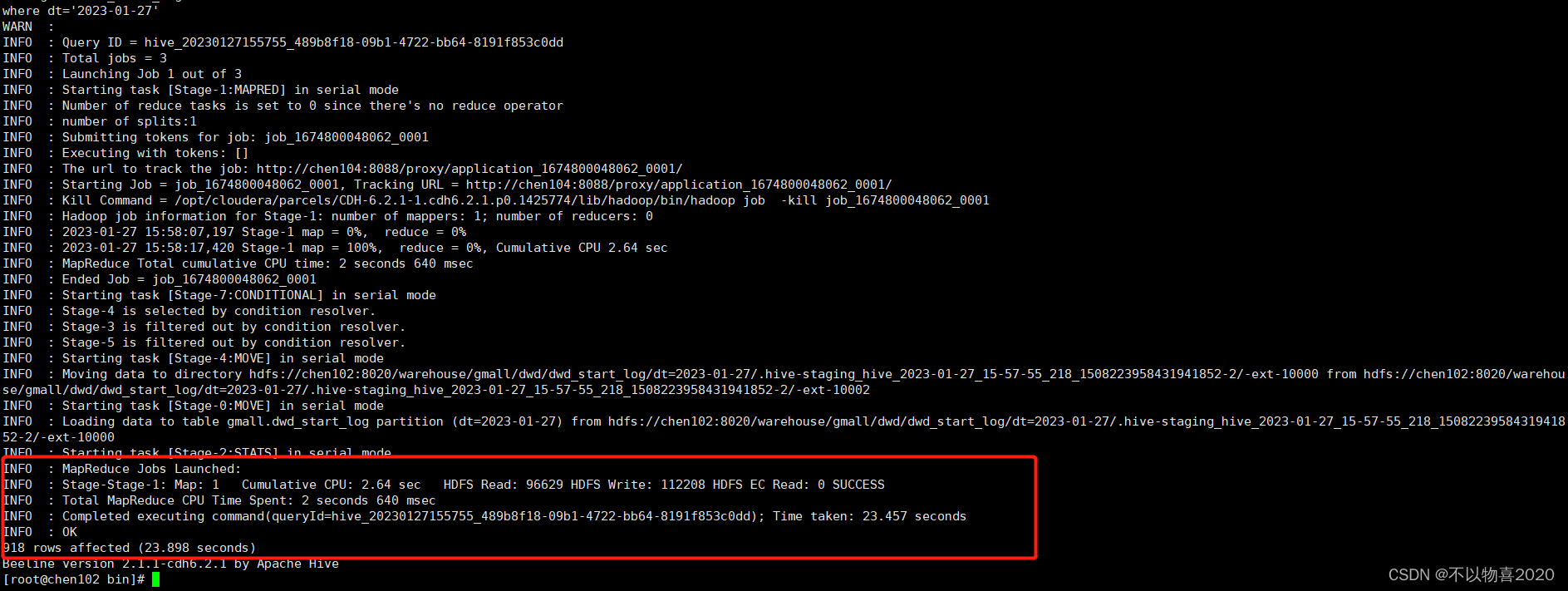
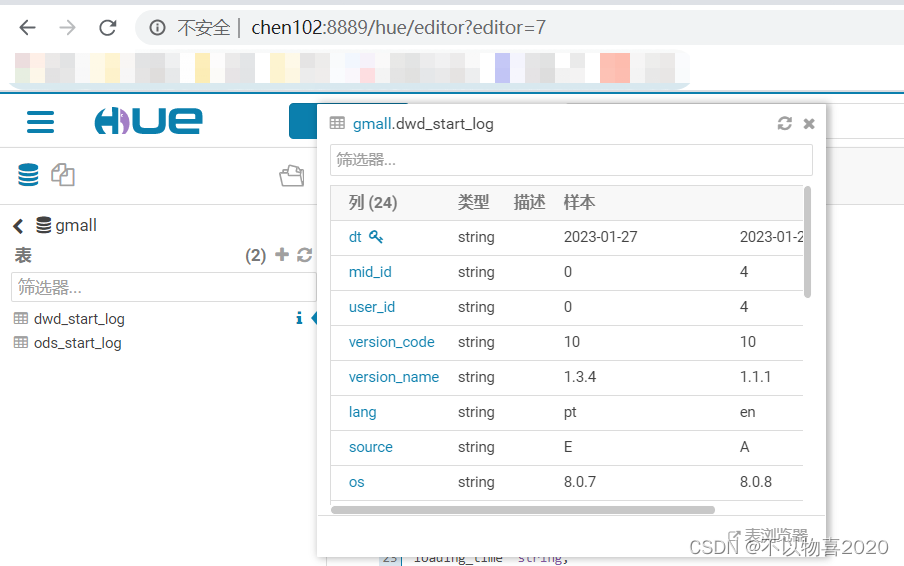
3.4 DWS层
目标:统计当日、当周、当月活动的每个设备明细
3.4.1 每日设备活跃明细
建表
drop table if exists dws_uv_detail_day;
create external table dws_uv_detail_day
(
`mid_id` string COMMENT '设备唯一标识',
`user_id` string COMMENT '用户标识',
`version_code` string COMMENT '程序版本号',
`version_name` string COMMENT '程序版本名',
`lang` string COMMENT '系统语言',
`source` string COMMENT '渠道号',
`os` string COMMENT '安卓系统版本',
`area` string COMMENT '区域',
`model` string COMMENT '手机型号',
`brand` string COMMENT '手机品牌',
`sdk_version` string COMMENT 'sdkVersion',
`gmail` string COMMENT 'gmail',
`height_width` string COMMENT '屏幕宽高',
`app_time` string COMMENT '客户端日志产生时的时间',
`network` string COMMENT '网络模式',
`lng` string COMMENT '经度',
`lat` string COMMENT '纬度'
)
partitioned by(dt string)
stored as parquet
location '/warehouse/gmall/dws/dws_uv_detail_day'
;
3.4.2 数据导入脚本
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table "$APP".dws_uv_detail_day partition(dt='$do_date')
select
mid_id,
concat_ws('|', collect_set(user_id)) user_id,
concat_ws('|', collect_set(version_code)) version_code,
concat_ws('|', collect_set(version_name)) version_name,
concat_ws('|', collect_set(lang)) lang,
concat_ws('|', collect_set(source)) source,
concat_ws('|', collect_set(os)) os,
concat_ws('|', collect_set(area)) area,
concat_ws('|', collect_set(model)) model,
concat_ws('|', collect_set(brand)) brand,
concat_ws('|', collect_set(sdk_version)) sdk_version,
concat_ws('|', collect_set(gmail)) gmail,
concat_ws('|', collect_set(height_width)) height_width,
concat_ws('|', collect_set(app_time)) app_time,
concat_ws('|', collect_set(network)) network,
concat_ws('|', collect_set(lng)) lng,
concat_ws('|', collect_set(lat)) lat
from "$APP".dwd_start_log
where dt='$do_date'
group by mid_id;
"
beeline -u "jdbc:hive2://chen102:10000/" -n hive -e "$sql"
3.4.3 执行并验证
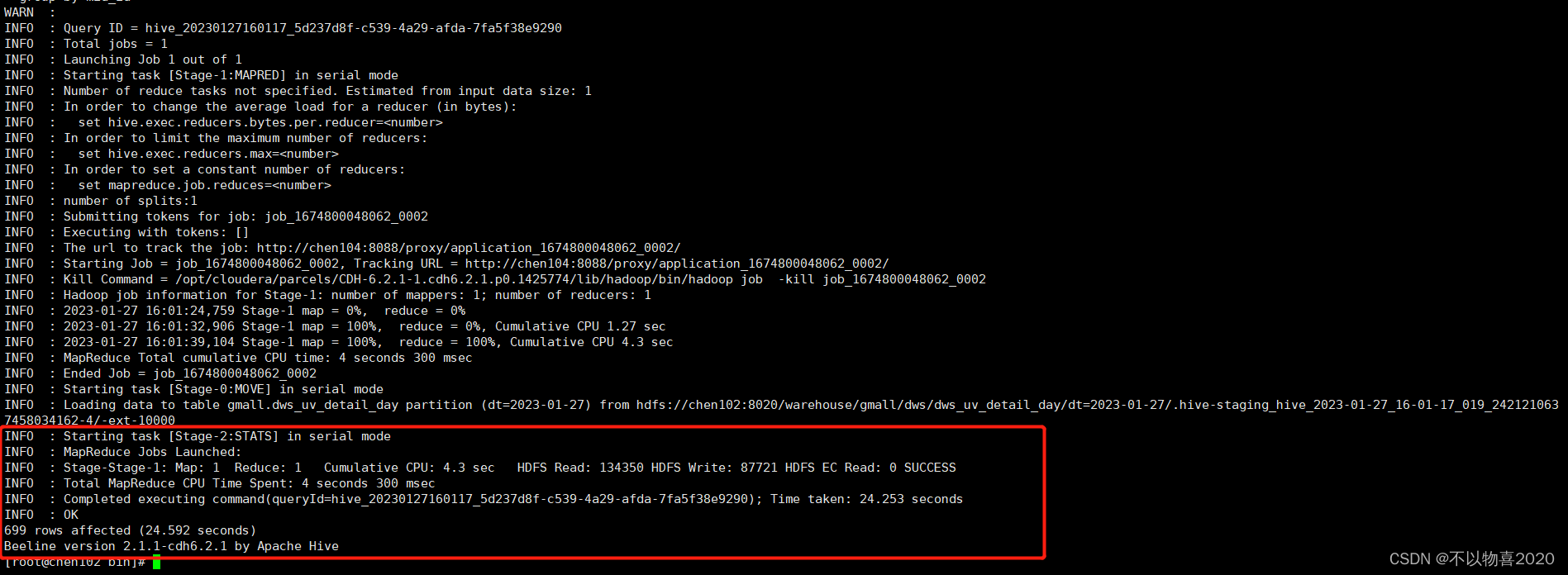
3.5 ADS层
目标:当日活跃设备数
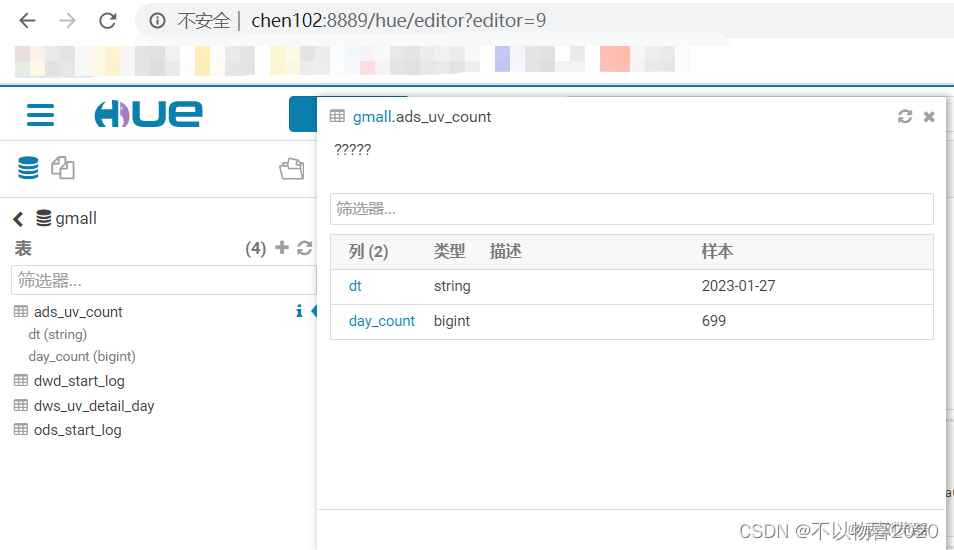
3.5.1 建表
drop table if exists ads_uv_count;
create external table ads_uv_count(
`dt` string COMMENT '统计日期',
`day_count` bigint COMMENT '当日用户数量'
) COMMENT '活跃设备数'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_uv_count/'
;
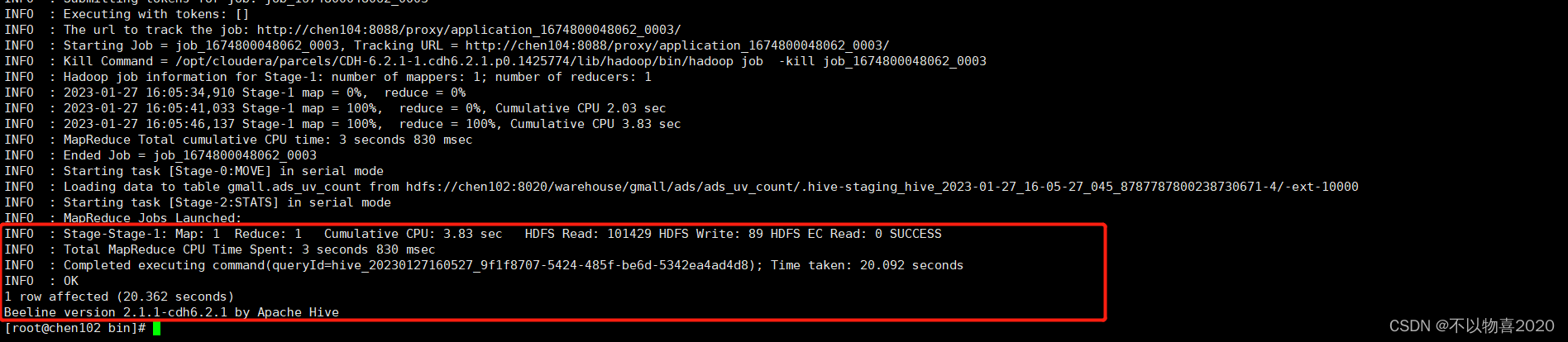
3.5.2 ADS层加载脚本
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table "$APP".ads_uv_count
select
'$do_date' dt,
daycount.ct
from
(
select
'$do_date' dt,
count(*) ct
from "$APP".dws_uv_detail_day
where dt='$do_date'
)daycount;
"
beeline -u "jdbc:hive2://chen102:10000/" -n hive -e "$sql"
3.5.3 执行并验证
4 业务数仓搭建
4.1 业务数据生成
1)连接Mysql创建数据库gmall
2)设置数据库编码
3)导入建表语句(1建表脚本)
sql脚本如下:
链接:https://pan.baidu.com/s/1WX3xVMQvAApSUZMobWLiLQ
提取码:8emk
- 生成数据
CALL init_data('2019-02-10',1000,200,300,TRUE);
4.2 Sqoop导入脚本
#!/bin/bash
export HADOOP_USER_NAME=hive
db_date=$2
echo $db_date
db_name=gmall
import_data() {
sqoop import \
--connect jdbc:mysql://chen102:3306/$db_name \
--username root \
--password Chen.123456 \
--target-dir /origin_data/$db_name/db/$1/$db_date \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query "$2"' and $CONDITIONS;'
}
import_sku_info(){
import_data "sku_info" "select
id, spu_id, price, sku_name, sku_desc, weight, tm_id,
category3_id, create_time
from sku_info where 1=1"
}
import_user_info(){
import_data "user_info" "select
id, name, birthday, gender, email, user_level,
create_time
from user_info where 1=1"
}
import_base_category1(){
import_data "base_category1" "select
id, name from base_category1 where 1=1"
}
import_base_category2(){
import_data "base_category2" "select
id, name, category1_id from base_category2 where 1=1"
}
import_base_category3(){
import_data "base_category3" "select id, name, category2_id from base_category3 where 1=1"
}
import_order_detail(){
import_data "order_detail" "select
od.id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
o.create_time
from order_info o , order_detail od
where o.id=od.order_id
and DATE_FORMAT(create_time,'%Y-%m-%d')='$db_date'"
}
import_payment_info(){
import_data "payment_info" "select
id,
out_trade_no,
order_id,
user_id,
alipay_trade_no,
total_amount,
subject,
payment_type,
payment_time
from payment_info
where DATE_FORMAT(payment_time,'%Y-%m-%d')='$db_date'"
}
import_order_info(){
import_data "order_info" "select
id,
total_amount,
order_status,
user_id,
payment_way,
out_trade_no,
create_time,
operate_time
from order_info
where (DATE_FORMAT(create_time,'%Y-%m-%d')='$db_date' or DATE_FORMAT(operate_time,'%Y-%m-%d')='$db_date')"
}
case $1 in
"base_category1")
import_base_category1
;;
"base_category2")
import_base_category2
;;
"base_category3")
import_base_category3
;;
"order_info")
import_order_info
;;
"order_detail")
import_order_detail
;;
"sku_info")
import_sku_info
;;
"user_info")
import_user_info
;;
"payment_info")
import_payment_info
;;
"all")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
;;
esac
执行结果如下:
修改/orgin_data/gmall/db路径的访问权限
sudo -u hdfs hadoop fs -chmod -R 777 /origin_data/gmall/db
4.3 ODS层
4.3.1 创建订单表
drop table if exists ods_order_info;
create external table ods_order_info (
`id` string COMMENT '订单编号',
`total_amount` decimal(10,2) COMMENT '订单金额',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id' ,
`payment_way` string COMMENT '支付方式',
`out_trade_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间'
) COMMENT '订单表'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ods/ods_order_info/'
;
4.3.2 订单详情表
drop table if exists ods_order_detail;
create external table ods_order_detail(
`id` string COMMENT '订单编号',
`order_id` string COMMENT '订单号',
`user_id` string COMMENT '用户id' ,
`sku_id` string COMMENT '商品id',
`sku_name` string COMMENT '商品名称',
`order_price` string COMMENT '商品价格',
`sku_num` string COMMENT '商品数量',
`create_time` string COMMENT '创建时间'
) COMMENT '订单明细表'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ods/ods_order_detail/'
4.3.3 创建商品表
drop table if exists ods_sku_info;
create external table ods_sku_info(
`id` string COMMENT 'skuId',
`spu_id` string COMMENT 'spuid',
`price` decimal(10,2) COMMENT '价格' ,
`sku_name` string COMMENT '商品名称',
`sku_desc` string COMMENT '商品描述',
`weight` string COMMENT '重量',
`tm_id` string COMMENT '品牌id',
`category3_id` string COMMENT '品类id',
`create_time` string COMMENT '创建时间'
) COMMENT '商品表'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ods/ods_sku_info/'
;
4.3.4 创建用户表
drop table if exists ods_user_info;
create external table ods_user_info(
`id` string COMMENT '用户id',
`name` string COMMENT '姓名',
`birthday` string COMMENT '生日' ,
`gender` string COMMENT '性别',
`email` string COMMENT '邮箱',
`user_level` string COMMENT '用户等级',
`create_time` string COMMENT '创建时间'
) COMMENT '用户信息'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ods/ods_user_info/'
;
4.3.5 创建一级分类表
drop table if exists ods_base_category1;
create external table ods_base_category1(
`id` string COMMENT 'id',
`name` string COMMENT '名称'
) COMMENT '商品一级分类'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ods/ods_base_category1/'
;
4.3.6 创建二级分类表
drop table if exists ods_base_category2;
create external table ods_base_category2(
`id` string COMMENT ' id',
`name` string COMMENT '名称',
category1_id string COMMENT '一级品类id'
) COMMENT '商品二级分类'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ods/ods_base_category2/'
;
4.3.7 创建三级分类表
drop table if exists ods_base_category3;
create external table ods_base_category3(
`id` string COMMENT ' id',
`name` string COMMENT '名称',
category2_id string COMMENT '二级品类id'
) COMMENT '商品三级分类'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ods/ods_base_category3/'
;
4.3.8 创建支付流水表
drop table if exists `ods_payment_info`;
create external table `ods_payment_info`(
`id` bigint COMMENT '编号',
`out_trade_no` string COMMENT '对外业务编号',
`order_id` string COMMENT '订单编号',
`user_id` string COMMENT '用户编号',
`alipay_trade_no` string COMMENT '支付宝交易流水编号',
`total_amount` decimal(16,2) COMMENT '支付金额',
`subject` string COMMENT '交易内容',
`payment_type` string COMMENT '支付类型',
`payment_time` string COMMENT '支付时间'
) COMMENT '支付流水表'
PARTITIONED BY ( `dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ods/ods_payment_info/'
;
4.3.8 ODS数据导入脚本
#!/bin/bash
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table "$APP".ods_order_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table "$APP".ods_order_detail partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/sku_info/$do_date' OVERWRITE into table "$APP".ods_sku_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/user_info/$do_date' OVERWRITE into table "$APP".ods_user_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/payment_info/$do_date' OVERWRITE into table "$APP".ods_payment_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category1/$do_date' OVERWRITE into table "$APP".ods_base_category1 partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category2/$do_date' OVERWRITE into table "$APP".ods_base_category2 partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category3/$do_date' OVERWRITE into table "$APP".ods_base_category3 partition(dt='$do_date');
"
beeline -u "jdbc:hive2://hadoop102:10000/" -n hive -e "$sql"
执行结果如下:
4.4 DWD层
4.4.1 创建订单表
drop table if exists dwd_order_info;
create external table dwd_order_info (
`id` string COMMENT '',
`total_amount` decimal(10,2) COMMENT '',
`order_status` string COMMENT ' 1 2 3 4 5',
`user_id` string COMMENT 'id' ,
`payment_way` string COMMENT '',
`out_trade_no` string COMMENT '',
`create_time` string COMMENT '',
`operate_time` string COMMENT ''
)
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_order_info/'
4.4.2 创建订单详情表
drop table if exists dwd_order_detail;
create external table dwd_order_detail(
`id` string COMMENT '',
`order_id` decimal(10,2) COMMENT '',
`user_id` string COMMENT 'id' ,
`sku_id` string COMMENT 'id',
`sku_name` string COMMENT '',
`order_price` string COMMENT '',
`sku_num` string COMMENT '',
`create_time` string COMMENT ''
)
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_order_detail/'
;
4.4.3 创建用户表
drop table if exists dwd_user_info;
create external table dwd_user_info(
`id` string COMMENT 'id',
`name` string COMMENT '',
`birthday` string COMMENT '' ,
`gender` string COMMENT '',
`email` string COMMENT '',
`user_level` string COMMENT '',
`create_time` string COMMENT ''
)
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_user_info/'
;
4.4.4 创建支付流水表
drop table if exists `dwd_payment_info`;
create external table `dwd_payment_info`(
`id` bigint COMMENT '',
`out_trade_no` string COMMENT '',
`order_id` string COMMENT '',
`user_id` string COMMENT '',
`alipay_trade_no` string COMMENT '',
`total_amount` decimal(16,2) COMMENT '',
`subject` string COMMENT '',
`payment_type` string COMMENT '',
`payment_time` string COMMENT ''
)
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_payment_info/'
;
4.4.5 创建商品表
drop table if exists dwd_sku_info;
create external table dwd_sku_info(
`id` string COMMENT 'skuId',
`spu_id` string COMMENT 'spuid',
`price` decimal(10,2) COMMENT '' ,
`sku_name` string COMMENT '',
`sku_desc` string COMMENT '',
`weight` string COMMENT '',
`tm_id` string COMMENT 'id',
`category3_id` string COMMENT '1id',
`category2_id` string COMMENT '2id',
`category1_id` string COMMENT '3id',
`category3_name` string COMMENT '3',
`category2_name` string COMMENT '2',
`category1_name` string COMMENT '1',
`create_time` string COMMENT ''
)
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_sku_info/'
;
4.4.6 DWD层数据导入脚本
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table "$APP".dwd_order_info partition(dt)
select * from "$APP".ods_order_info
where dt='$do_date' and id is not null;
insert overwrite table "$APP".dwd_order_detail partition(dt)
select * from "$APP".ods_order_detail
where dt='$do_date' and id is not null;
insert overwrite table "$APP".dwd_user_info partition(dt)
select * from "$APP".ods_user_info
where dt='$do_date' and id is not null;
insert overwrite table "$APP".dwd_payment_info partition(dt)
select * from "$APP".ods_payment_info
where dt='$do_date' and id is not null;
insert overwrite table "$APP".dwd_sku_info partition(dt)
select
sku.id,
sku.spu_id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.tm_id,
sku.category3_id,
c2.id category2_id ,
c1.id category1_id,
c3.name category3_name,
c2.name category2_name,
c1.name category1_name,
sku.create_time,
sku.dt
from
"$APP".ods_sku_info sku
join "$APP".ods_base_category3 c3 on sku.category3_id=c3.id
join "$APP".ods_base_category2 c2 on c3.category2_id=c2.id
join "$APP".ods_base_category1 c1 on c2.category1_id=c1.id
where sku.dt='$do_date' and c2.dt='$do_date'
and c3.dt='$do_date' and c1.dt='$do_date'
and sku.id is not null;
"
beeline -u "jdbc:hive2://chen102:10000/" -n hive -e "$sql"
执行结果如下:
4.5 DWS层
1)为什么要建宽表
需求目标,把每个用户单日的行为聚合起来组成一张多列宽表,以便之后关联用户维度信息后进行,不同角度的统计分析。
4.5.1 创建用户行为宽表
drop table if exists dws_user_action;
create external table dws_user_action
(
user_id string comment '用户 id',
order_count bigint comment '下单次数 ',
order_amount decimal(16,2) comment '下单金额 ',
payment_count bigint comment '支付次数',
payment_amount decimal(16,2) comment '支付金额 '
) COMMENT '每日用户行为宽表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dws/dws_user_action/'
tblproperties ("parquet.compression"="snappy");
4.5.2 用户行为宽表导入脚本
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
with
tmp_order as
(
select
user_id,
count(*) order_count,
sum(oi.total_amount) order_amount
from "$APP".dwd_order_info oi
where date_format(oi.create_time,'yyyy-MM-dd')='$do_date'
group by user_id
) ,
tmp_payment as
(
select
user_id,
sum(pi.total_amount) payment_amount,
count(*) payment_count
from "$APP".dwd_payment_info pi
where date_format(pi.payment_time,'yyyy-MM-dd')='$do_date'
group by user_id
)
insert overwrite table "$APP".dws_user_action partition(dt='$do_date')
select
user_actions.user_id,
sum(user_actions.order_count),
sum(user_actions.order_amount),
sum(user_actions.payment_count),
sum(user_actions.payment_amount)
from
(
select
user_id,
order_count,
order_amount,
0 payment_count,
0 payment_amount
from tmp_order
union all
select
user_id,
0 order_count,
0 order_amount,
payment_count,
payment_amount
from tmp_payment
) user_actions
group by user_id;
"
beeline -u "jdbc:hive2://chen102:10000/" -n hive -e "$sql"
执行结果如下:
4.6 ADS层
求GMV成交总额
4.6.1 建表
drop table if exists ads_gmv_sum_day;
create external table ads_gmv_sum_day(
`dt` string COMMENT '统计日期',
`gmv_count` bigint COMMENT '当日gmv订单个数',
`gmv_amount` decimal(16,2) COMMENT '当日gmv订单总金额',
`gmv_payment` decimal(16,2) COMMENT '当日支付金额'
) COMMENT 'GMV'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_gmv_sum_day/'
;
4.6.2 数据导入脚本
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert into table "$APP".ads_gmv_sum_day
select
'$do_date' dt,
sum(order_count) gmv_count,
sum(order_amount) gmv_amount,
sum(payment_amount) payment_amount
from "$APP".dws_user_action
where dt ='$do_date'
group by dt;
"
beeline -u "jdbc:hive2://chen102:10000/" -n hive -e "$sql"
执行结果如下:
4.6.3 数据导出脚本
1)在MySQL中创建ads_gmv_sum_day表
DROP TABLE IF EXISTS ads_gmv_sum_day;
CREATE TABLE ads_gmv_sum_day(
`dt` varchar(200) DEFAULT NULL COMMENT '统计日期',
`gmv_count` bigint(20) DEFAULT NULL COMMENT '当日gmv订单个数',
`gmv_amount` decimal(16, 2) DEFAULT NULL COMMENT '当日gmv订单总金额',
`gmv_payment` decimal(16, 2) DEFAULT NULL COMMENT '当日支付金额'
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '每日活跃用户数量' ROW_FORMAT = Dynamic;
#!/bin/bash
export HADOOP_USER_NAME=hive
db_name=gmall
export_data() {
sqoop export \
--connect "jdbc:mysql://chen102:3306/${db_name}?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password Atguigu.123456 \
--table $1 \
--num-mappers 1 \
--export-dir /warehouse/$db_name/ads/$1 \
--input-fields-terminated-by "\t" \
--update-mode allowinsert \
--update-key $2 \
--input-null-string '\\N' \
--input-null-non-string '\\N'
}
case $1 in
"ads_gmv_sum_day")
export_data "ads_gmv_sum_day" "dt"
;;
"all")
export_data "ads_gmv_sum_day" "dt"
;;
esac
执行结果如下:
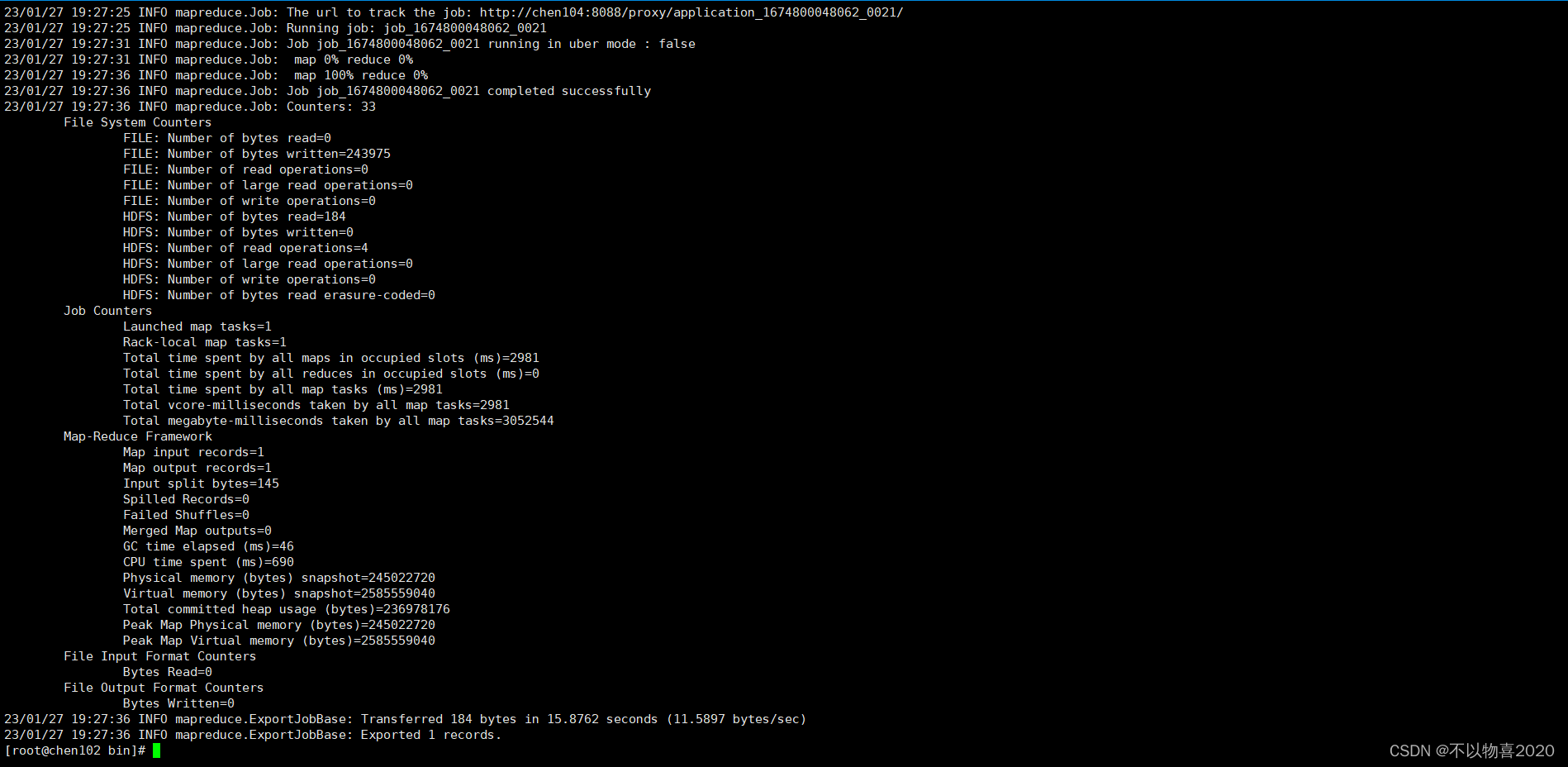
4.6.4 执行脚本并验证
select * from ads_gmv_sum_day
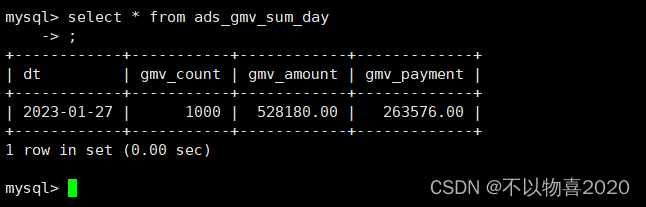
至此,用户行为数仓和业务数仓搭建完成。接下来是CDH即席查询——Impala
5 Oozie基于Hue实现GMV指标全流程调度
5.1 在Hue中创建Oozie任务GMV
1)生成新的业务数据
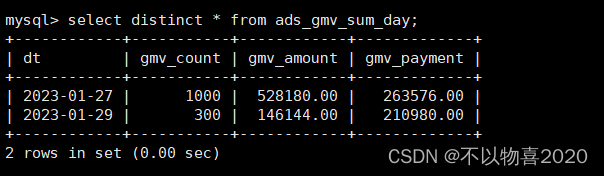
CALL init_data('2023-01-29',300,200,300,FALSE);
2)将oozie调度脚本上传到HDFS
sudo -u hive hadoop fs -mkdir /user/hive/bin/
cp /root/bin/*.sh /var/lib/hive/
sudo -u hive hadoop fs -put /var/lib/hive/*.sh /user/hive/bin
3)编辑workflow
4)添加工作流
5)保存并执行workflow
等待执行成功
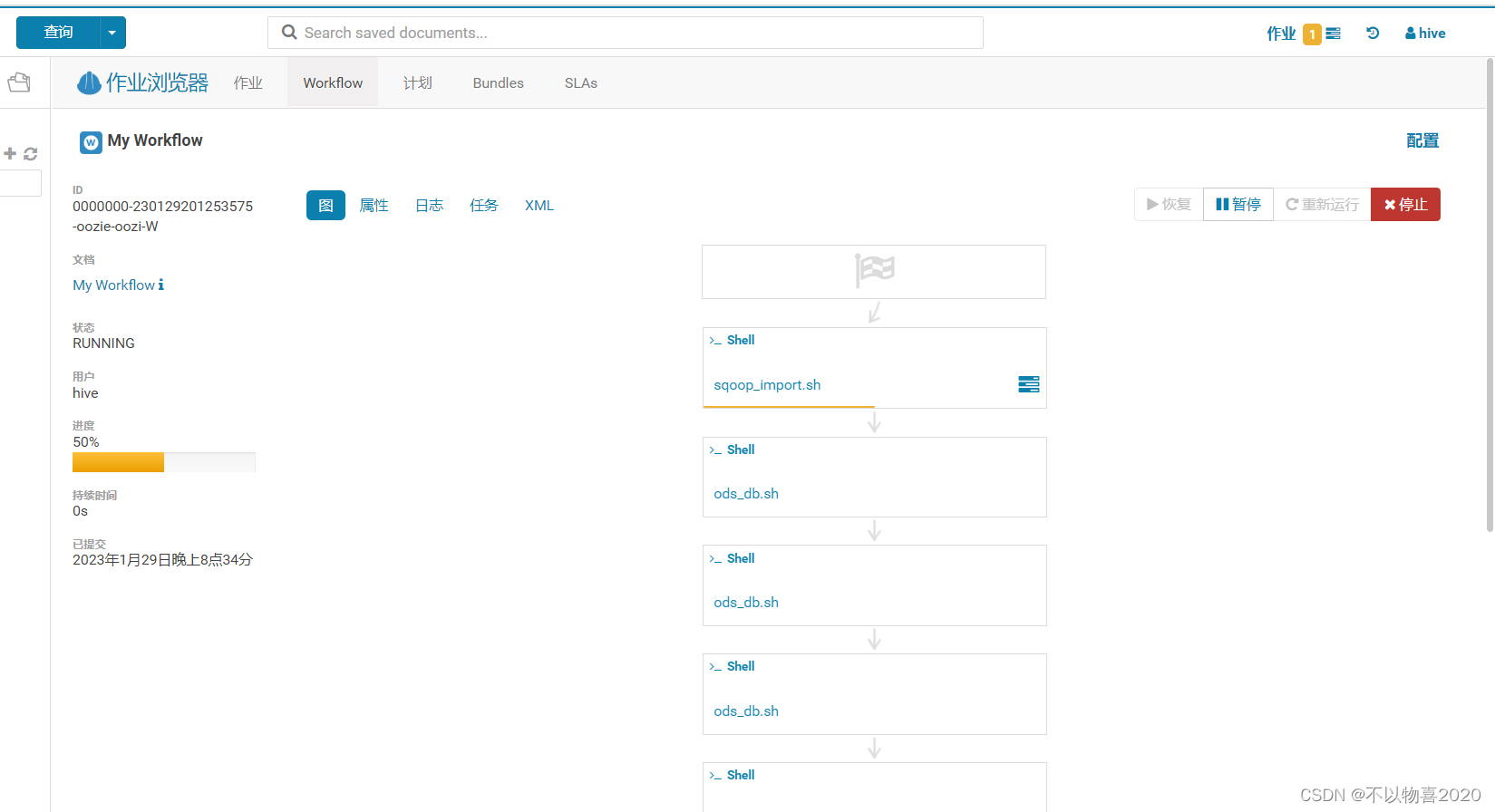
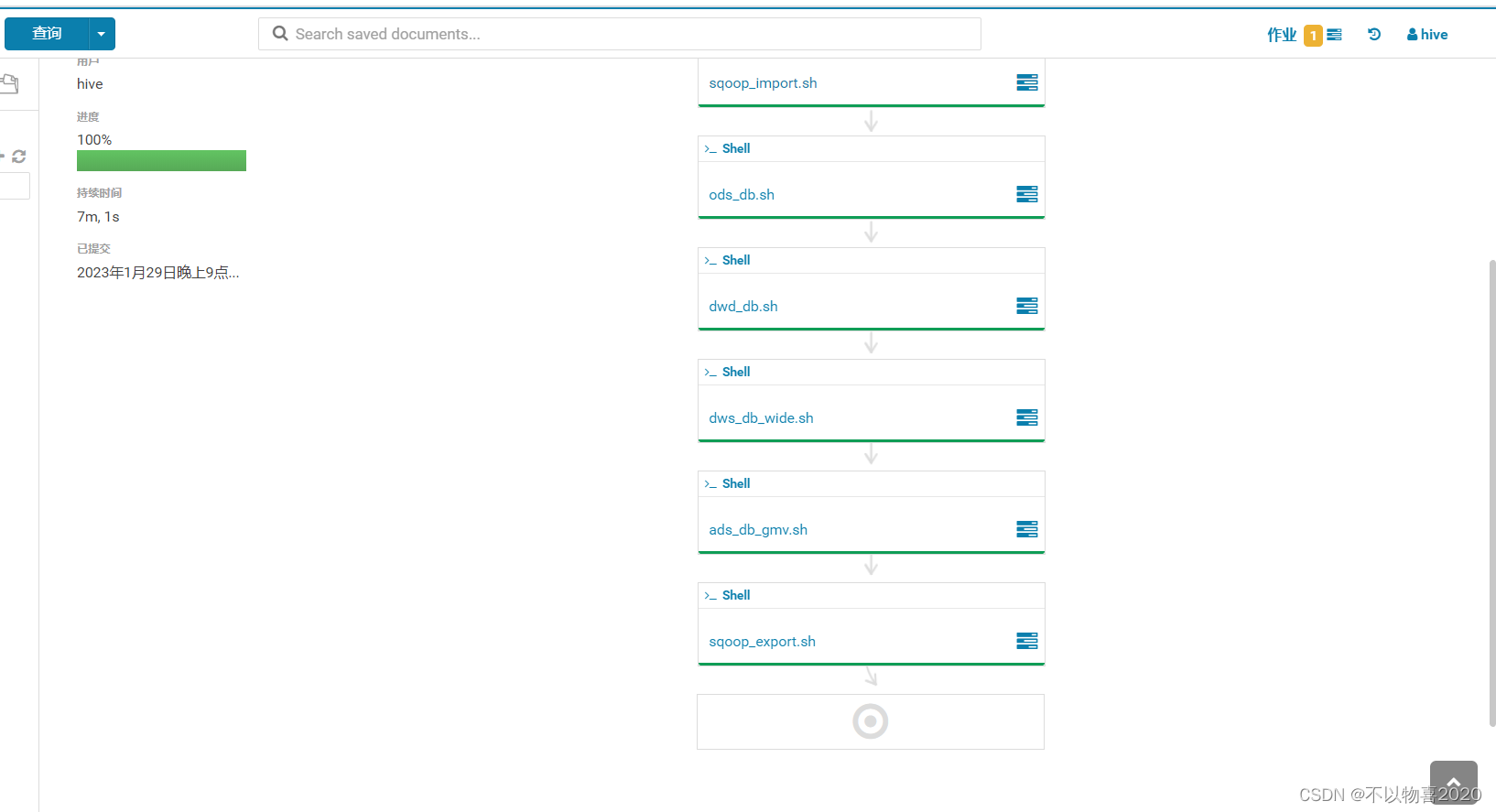
6) 查看Mysql执行结果
6 即席查询
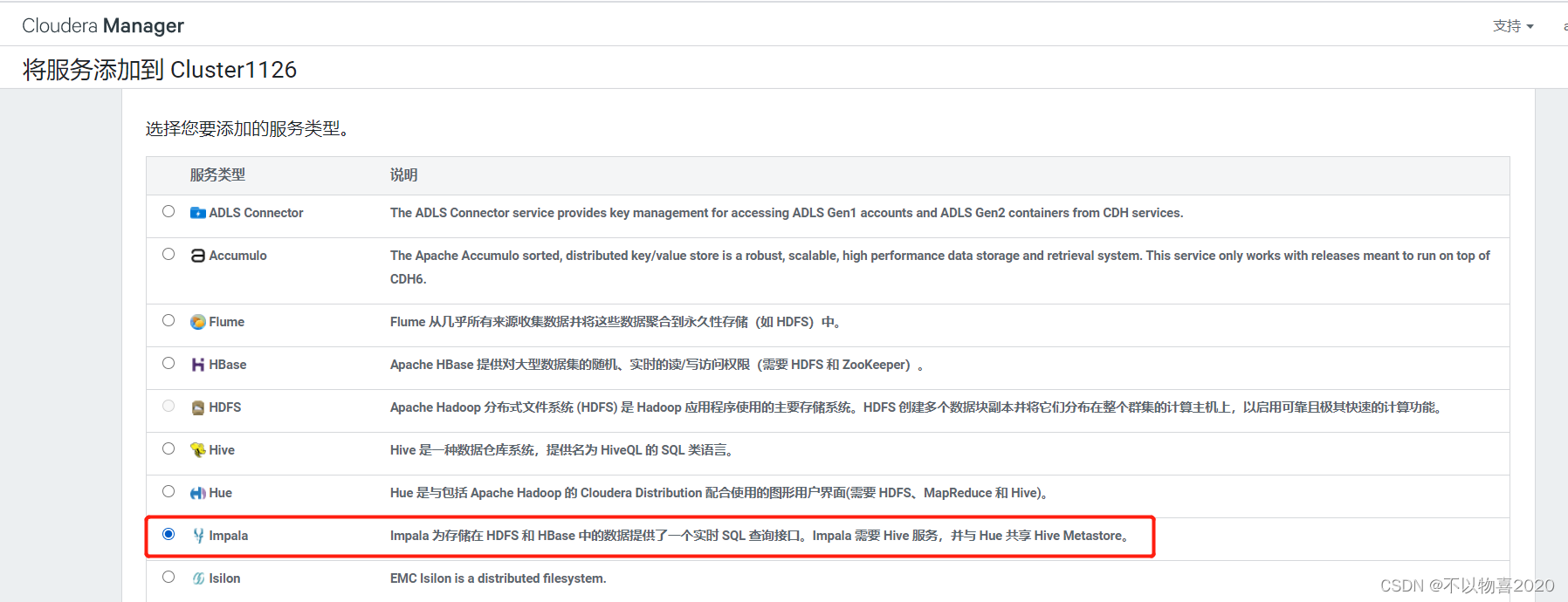
6.1 Impala安装
1)添加服务
2)角色分配
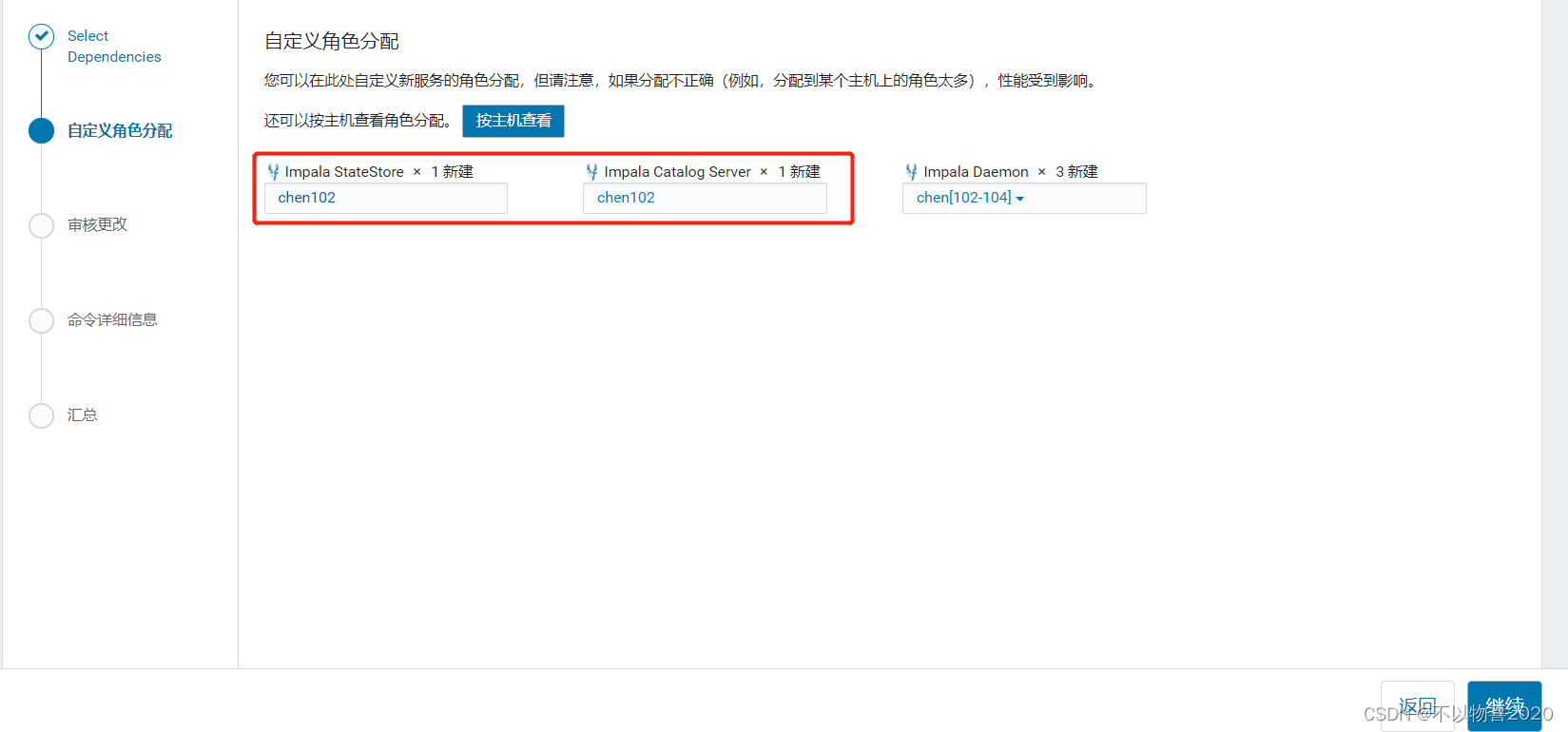
注意:最好将StateStore和CataLog Sever单独部署在同一节点上。
3)配置并启动Impala
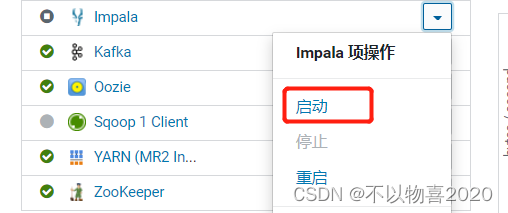
6.2 配置Hue支持Impala
1)进入HUE配置页面,搜索“impala”,开启HUE中的impala服务
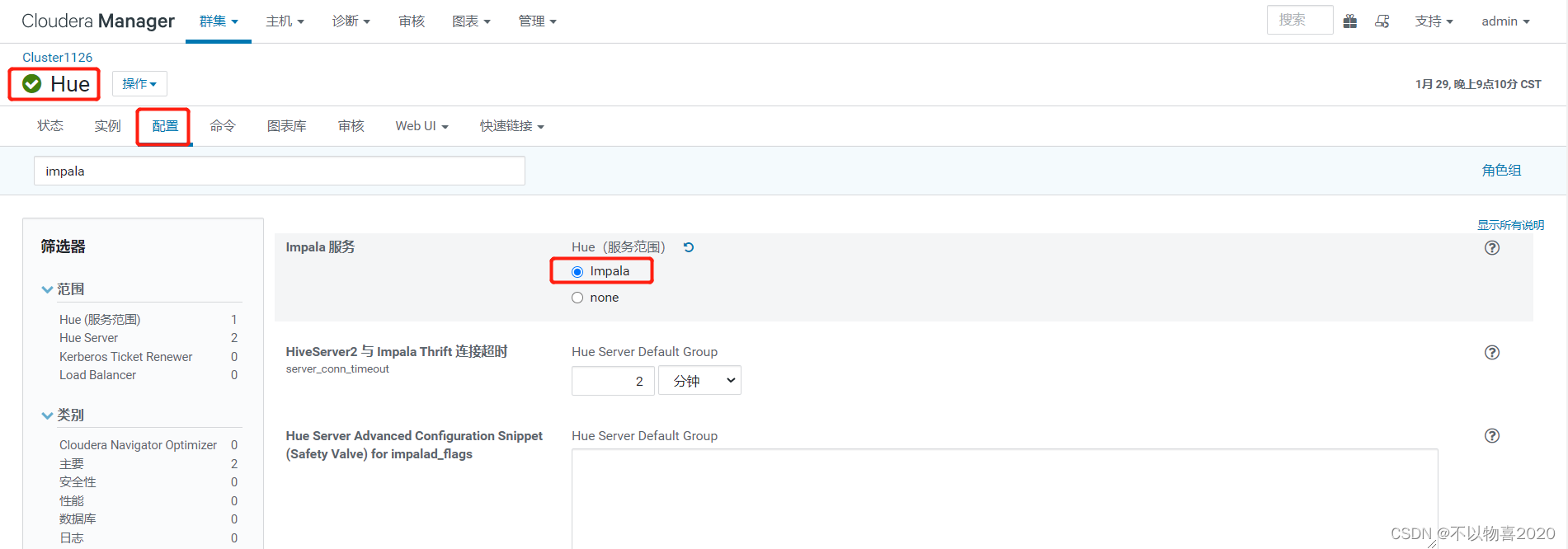
2)搜索“hue_safety_valve.ini 的 Hue 服务高级配置代码段(安全阀)”,输入以下代码段,确定HUE支持impala搜索引擎
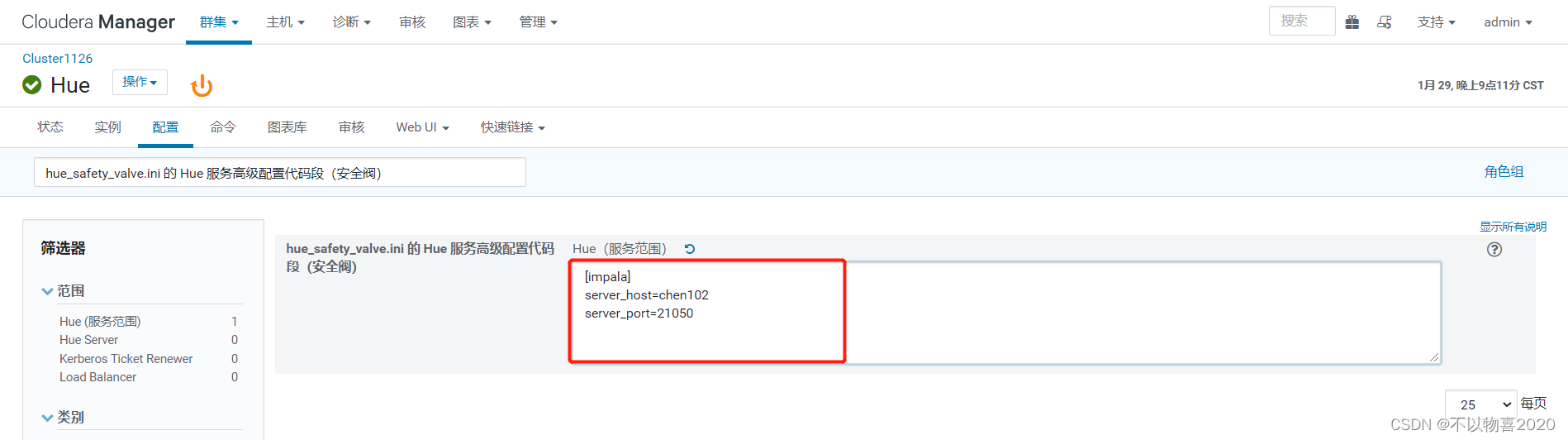
6.3 Impala基于Hue查询
- 打开hue
- 进入impala查询
分别用impala和hive查询以下SQL语句,对比查询速度。
select
sku.id,
sku.spu_id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.tm_id,
sku.category3_id,
c2.id category2_id ,
c1.id category1_id,
c3.name category3_name,
c2.name category2_name,
c1.name category1_name,
sku.create_time,
sku.dt
from
ods_sku_info sku
join ods_base_category3 c3 on sku.category3_id=c3.id
join ods_base_category2 c2 on c3.category2_id=c2.id
join ods_base_category1 c1 on c2.category1_id=c1.id
where sku.dt='2023-01-27' and c2.dt='2023-01-29';
hive查询耗时22秒
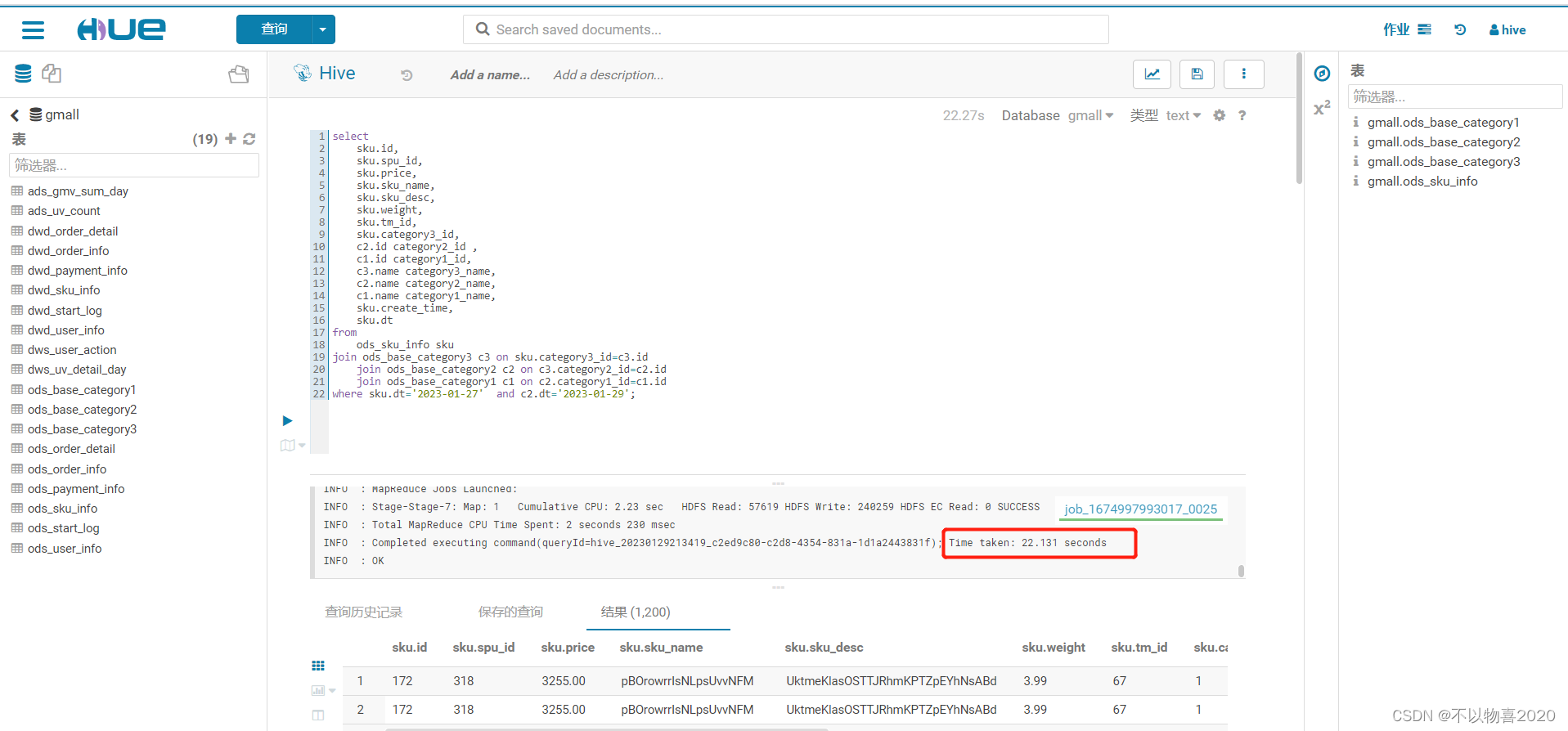
impala耗时2秒左右
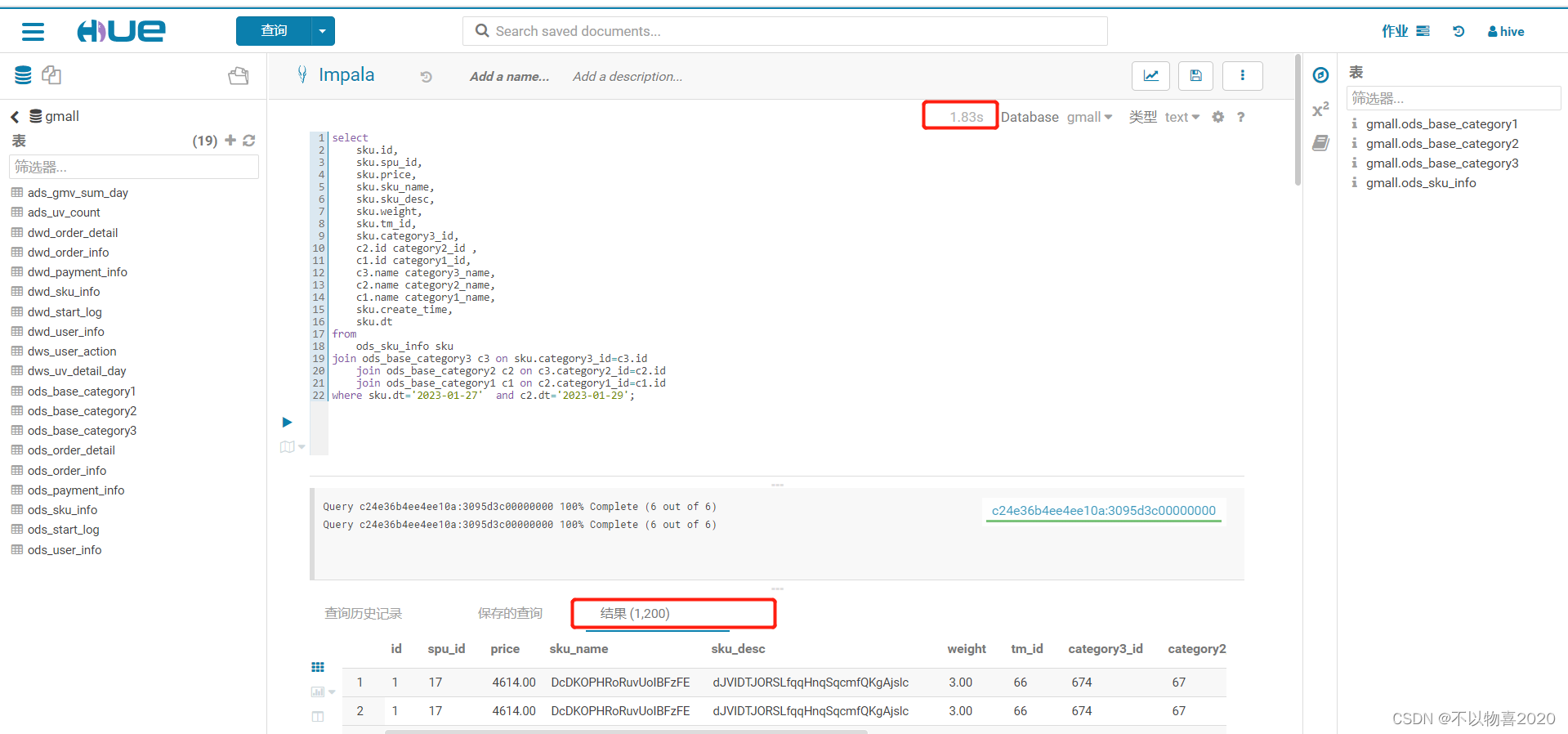
接下来是Kerberos认证和Sentry权限管理相关内容,详见《CDH数仓项目(四) —— 集群性能测试/资源管理/清理CDH集群》