目录
3. 无重复字符的最长子串 中等
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew" 输出: 3 解释: 因为无重复字符的最长子串是"wke",所以其长度为 3。 请注意,你的答案必须是 子串 的长度,"pwke"是一个子序列,不是子串。
public int lengthOfLongestSubstring(String s) {
Set<Character> set = new HashSet<>();
int ans = 0;
int l = 0;
int r = 0;
while (r < s.length()) {
while (set.contains(s.charAt(r))) {
set.remove(s.charAt(l));
l++;
}
set.add(s.charAt(r));
r++;
ans = Math.max(ans, set.size());
}
return ans;
}解析:通过操作set来实现
18. 四数之和 中等
给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。
注意:
答案中不可以包含重复的四元组。
示例:
给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。
满足要求的四元组集合为:
[
[-1, 0, 0, 1],
[-2, -1, 1, 2],
[-2, 0, 0, 2]
]
//双指针
public List<List<Integer>> fourSum(int[] nums, int target) {
List<List<Integer>> ans = new ArrayList<>();
if (nums == null || nums.length < 3) {
return ans;
}
int n = nums.length;
Arrays.sort(nums);
for (int i = 0; i < n - 3; i++) {
if (i != 0 && nums[i] == nums[i - 1]) {
continue;
}
//控制最大最小值优化
int min = nums[i] + nums[i + 1] + nums[i + 2] + nums[i + 3];
if (min > target) {
break;
}
int max = nums[i] + nums[n - 1] + nums[n - 2] + nums[n - 3];
if (max < target) {
continue;
}
for (int j = i + 1; j < n - 2; j++) {
if (j != i + 1 && nums[j] == nums[j - 1]) {
continue;
}
int left = j + 1;
int right = n - 1;
//控制最大最小值优化
int min1 = nums[i] + nums[j] + nums[left] + nums[left + 1];
if (min1 > target) {
break;
}
int max1 = nums[i] + nums[j] + nums[right] + nums[right - 1];
if (max1 < target) {
continue;
}
while (left < right) {
int num = nums[i] + nums[j] + nums[left] + nums[right];
if (num == target) {
ans.add(Arrays.asList(nums[i], nums[j], nums[left], nums[right]));
left++;
while (left < right && nums[left] == nums[left - 1]) {
left++;
}
right--;
while (left < right && nums[right] == nums[right + 1]) {
right--;
}
} else if (num > target) {
right--;
} else {
left++;
}
}
}
}
return ans;
}解析:稳定i和j两个点,然后用left和right两个指针向中间夹,选出合适的值
36. 有效的数独 中等
判断一个 9x9 的数独是否有效。只需要根据以下规则,验证已经填入的数字是否有效即可。
- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。

上图是一个部分填充的有效的数独。
数独部分空格内已填入了数字,空白格用 '.' 表示。
示例 1:
输入:
[
["5","3",".",".","7",".",".",".","."],
["6",".",".","1","9","5",".",".","."],
[".","9","8",".",".",".",".","6","."],
["8",".",".",".","6",".",".",".","3"],
["4",".",".","8",".","3",".",".","1"],
["7",".",".",".","2",".",".",".","6"],
[".","6",".",".",".",".","2","8","."],
[".",".",".","4","1","9",".",".","5"],
[".",".",".",".","8",".",".","7","9"]
]
输出: true
示例 2:
输入:
[
["8","3",".",".","7",".",".",".","."],
["6",".",".","1","9","5",".",".","."],
[".","9","8",".",".",".",".","6","."],
["8",".",".",".","6",".",".",".","3"],
["4",".",".","8",".","3",".",".","1"],
["7",".",".",".","2",".",".",".","6"],
[".","6",".",".",".",".","2","8","."],
[".",".",".","4","1","9",".",".","5"],
[".",".",".",".","8",".",".","7","9"]
]
输出: false
解释: 除了第一行的第一个数字从 5 改为 8 以外,空格内其他数字均与 示例1 相同。
但由于位于左上角的 3x3 宫内有两个 8 存在, 因此这个数独是无效的。说明:
- 一个有效的数独(部分已被填充)不一定是可解的。
- 只需要根据以上规则,验证已经填入的数字是否有效即可。
- 给定数独序列只包含数字
1-9和字符'.'。 - 给定数独永远是
9x9形式的。
public boolean isValidSudoku(char[][] board) {
Map<Integer, Integer> rows[] = new HashMap[9];
Map<Integer, Integer> cols[] = new HashMap[9];
Map<Integer, Integer> boxs[] = new HashMap[9];
for (int i = 0; i < 9; i++) {
rows[i] = new HashMap<>();
cols[i] = new HashMap<>();
boxs[i] = new HashMap<>();
}
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
char num = board[i][j];
if (num != '.') {
int n = (int) num;
int idx = (i / 3) * 3 + (j / 3);
rows[i].put(n, rows[i].getOrDefault(n, 0) + 1);
cols[j].put(n, cols[j].getOrDefault(n, 0) + 1);
boxs[idx].put(n, boxs[idx].getOrDefault(n, 0) + 1);
if (rows[i].get(n) > 1 || cols[j].get(n) > 1 || boxs[idx].get(n) > 1) {
return false;
}
}
}
}
return true;
}解析:每行一个map,每列一个map,每九个格子一个map,如果有重复,则返回false
49. 字母异位词分组 中等
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
输入: ["eat", "tea", "tan", "ate", "nat", "bat"]
输出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
说明:
- 所有输入均为小写字母。
- 不考虑答案输出的顺序。
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<>();
if (strs == null || strs.length == 0) {
return new ArrayList<>();
}
for (String str : strs) {
char[] arr = str.toCharArray();
Arrays.sort(arr);
String key = String.valueOf(arr);
map.putIfAbsent(key, new ArrayList<String>());
map.get(key).add(str);
}
return new ArrayList<>(map.values());
}94. 二叉树的中序遍历 中等
给定一个二叉树,返回它的中序 遍历。
示例:
输入: [1,null,2,3]
1
\
2
/
3
输出: [1,3,2]进阶: 递归算法很简单,你可以通过迭代算法完成吗?
//递归
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
dfs(ans, root);
return ans;
}
private void dfs(List<Integer> ans, TreeNode root) {
if (root == null) {
return;
}
dfs(ans, root.left);
ans.add(root.val);
dfs(ans, root.right);
}解析:递归实现
//迭代
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
Stack<TreeNode> stack = new Stack<TreeNode>();
while (root != null || !stack.isEmpty()) {
while (root != null) {
stack.add(root);
root = root.left;
}
if (!stack.isEmpty()) {
root = stack.pop();
ans.add(root.val);
root = root.right;
}
}
return ans;
}解析:通过栈来实现
138. 复制带随机指针的链表 中等
给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。
要求返回这个链表的 深拷贝。
我们用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
示例 1:
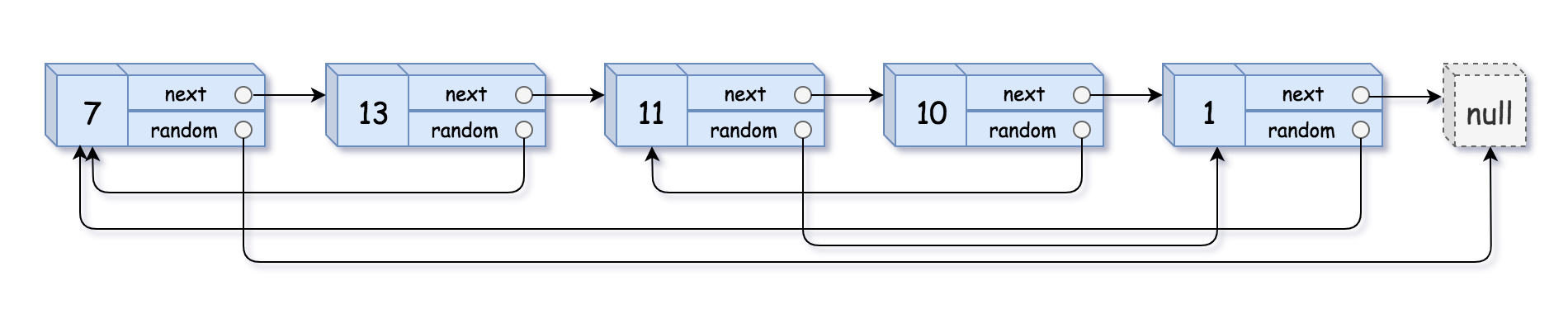
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
示例 4:
输入:head = []
输出:[]
解释:给定的链表为空(空指针),因此返回 null。
提示:
-10000 <= Node.val <= 10000Node.random为空(null)或指向链表中的节点。- 节点数目不超过 1000 。
private Map<Node, Node> map = new HashMap<>();
public Node copyRandomList(Node head) {
if (head == null) {
return head;
}
if (map.containsKey(head)) {
return map.get(head);
}
Node node = new Node(head.val);
map.put(head, node);
node.next = copyRandomList(head.next);
node.random = copyRandomList(head.random);
return node;
}解析:每一步把设置过得节点存储起来
166. 分数到小数 中等
给定两个整数,分别表示分数的分子 numerator 和分母 denominator,以字符串形式返回小数。
如果小数部分为循环小数,则将循环的部分括在括号内。
示例 1:
输入: numerator = 1, denominator = 2
输出: "0.5"
示例 2:
输入: numerator = 2, denominator = 1
输出: "2"示例 3:
输入: numerator = 2, denominator = 3
输出: "0.(6)"
public String fractionToDecimal(int numerator, int denominator) {
if (numerator == 0) {
return "0";
}
StringBuilder builder = new StringBuilder();
if (numerator < 0 ^ denominator < 0) {
builder.append("-");
}
long num1 = Math.abs(Long.valueOf(numerator));
long num2 = Math.abs(Long.valueOf(denominator));
builder.append(String.valueOf(num1 / num2));
long num3 = num1 % num2;
if (num3 == 0) {
return builder.toString();
}
Map<Long, Integer> map = new HashMap<>();
builder.append(".");
while (num3 != 0) {
if (map.containsKey(num3)) {
builder.insert(map.get(num3), "(");
builder.append(")");
break;
}
map.put(num3, builder.length());
num3 *= 10;
builder.append(String.valueOf(num3 / num2));
num3 %= num2;
}
return builder.toString();
}解析:将小数点后面的数和位置存储起来,如果后面发现在这个数重复了,则在数的位置插入左括号,将右括号加入到字符串后面
187. 重复的DNA序列 中等
所有 DNA 都由一系列缩写为 A,C,G 和 T 的核苷酸组成,例如:“ACGAATTCCG”。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
编写一个函数来查找目标子串,目标子串的长度为 10,且在 DNA 字符串 s 中出现次数超过一次。
示例:
输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT"
输出:["AAAAACCCCC", "CCCCCAAAAA"] //个人实现
public List<String> findRepeatedDnaSequences(String s) {
List<String> ans = new ArrayList<>();
Set<String> set = new HashSet<>();
for (int i = 0; i <= s.length() - 10; i++) {
String str = s.substring(i, i + 10);
if (set.contains(str)) {
if (!ans.contains(str)) {
ans.add(str);
}
} else {
set.add(str);
}
}
return ans;
}274. H 指数 中等
给定一位研究者论文被引用次数的数组(被引用次数是非负整数)。编写一个方法,计算出研究者的 h 指数。
h 指数的定义:h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。(其余的 N - h 篇论文每篇被引用次数 不超过 h 次。)
例如:某人的 h 指数是 20,这表示他已发表的论文中,每篇被引用了至少 20 次的论文总共有 20 篇。
示例:
输入:citations = [3,0,6,1,5]输出:3 解释:给定数组表示研究者总共有5篇论文,每篇论文相应的被引用了3, 0, 6, 1, 5次。 由于研究者有3篇论文每篇 至少 被引用了3次,其余两篇论文每篇被引用 不多于3次,所以她的 h 指数是3。
public int hIndex(int[] citations) {
Arrays.sort(citations);
int n = citations.length;
int i = 0;
while (i < citations.length && citations[n - i - 1]) {
i++;
}
return i;
}解析:如果最后一个元素的值大于i,则i后移,直到最后一个元素不大于i为止
299. 猜数字游戏 中等
你在和朋友一起玩 猜数字(Bulls and Cows)游戏,该游戏规则如下:
- 你写出一个秘密数字,并请朋友猜这个数字是多少。
- 朋友每猜测一次,你就会给他一个提示,告诉他的猜测数字中有多少位属于数字和确切位置都猜对了(称为“Bulls”, 公牛),有多少位属于数字猜对了但是位置不对(称为“Cows”, 奶牛)。
- 朋友根据提示继续猜,直到猜出秘密数字。
请写出一个根据秘密数字和朋友的猜测数返回提示的函数,返回字符串的格式为 xAyB ,x 和 y 都是数字,A 表示公牛,用 B 表示奶牛。
xA表示有x位数字出现在秘密数字中,且位置都与秘密数字一致。yB表示有y位数字出现在秘密数字中,但位置与秘密数字不一致。
请注意秘密数字和朋友的猜测数都可能含有重复数字,每位数字只能统计一次。
示例 1:
输入: secret = "1807", guess = "7810" 输出: "1A3B" 解释:1公牛和3奶牛。公牛是8,奶牛是0,1和7。
示例 2:
输入: secret = "1123", guess = "0111" 输出: "1A1B" 解释: 朋友猜测数中的第一个1是公牛,第二个或第三个1可被视为奶牛。
说明: 你可以假设秘密数字和朋友的猜测数都只包含数字,并且它们的长度永远相等。
//个人实现,效率不高
public String getHint(String secret, String guess) {
int a = 0;
int b = 0;
Map<Character, Integer> map = new HashMap<>();
for (int i = 0; i < secret.length(); i++) {
char ch = secret.charAt(i);
if (ch == guess.charAt(i)) {
a++;
}
map.put(ch, map.getOrDefault(ch, 0) + 1);
}
for (int i = 0; i < secret.length(); i++) {
char ch = guess.charAt(i);
if (map.containsKey(ch)) {
b++;
map.put(ch, map.get(ch) - 1);
if (map.get(ch) == 0) {
map.remove(ch);
}
}
}
int bRes = b - a;
return a + "A" + bRes + "B";
}解析:个人实现,效率不高
第一步将secret中各个字符及其数量存储起来
如果字符相等且其下标相同,则a++
再次遍历,如果存在相同的元素,则b++
用b-a表示需要输出的b
最后一步打印即可
347. 前 K 个高频元素 中等
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]提示:
- 你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
- 你的算法的时间复杂度必须优于 O(n log n) , n 是数组的大小。
- 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
- 你可以按任意顺序返回答案。
public int[] topKFrequent(int[] nums, int k) {
Map<Integer, Integer> map = new HashMap<>();
for (int num : nums) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
List<Map.Entry<Integer, Integer>> list = new ArrayList<>(map.entrySet());
list.sort(new Comparator<Map.Entry<Integer, Integer>>() {
@Override
public int compare(Map.Entry<Integer, Integer> o1, Map.Entry<Integer, Integer> o2) {
return o2.getValue().compareTo(o1.getValue());
}
});
int[] res = new int[k];
for (int i = 0; i < k; i++) {
res[i] = list.get(i).getKey();
}
return res;
}解析:先将数组元素和数组元素对应的数量存储在map集合中
将map元素转为map的entryset集合存储在list集合中
将list集合按照map的value值进行排序
找出k个元素返回即可
380. 常数时间插入、删除和获取随机元素 中等
设计一个支持在平均 时间复杂度 O(1) 下,执行以下操作的数据结构。
insert(val):当元素 val 不存在时,向集合中插入该项。remove(val):元素 val 存在时,从集合中移除该项。getRandom:随机返回现有集合中的一项。每个元素应该有相同的概率被返回。
示例 :
// 初始化一个空的集合。
RandomizedSet randomSet = new RandomizedSet();
// 向集合中插入 1 。返回 true 表示 1 被成功地插入。
randomSet.insert(1);
// 返回 false ,表示集合中不存在 2 。
randomSet.remove(2);
// 向集合中插入 2 。返回 true 。集合现在包含 [1,2] 。
randomSet.insert(2);
// getRandom 应随机返回 1 或 2 。
randomSet.getRandom();
// 从集合中移除 1 ,返回 true 。集合现在包含 [2] 。
randomSet.remove(1);
// 2 已在集合中,所以返回 false 。
randomSet.insert(2);
// 由于 2 是集合中唯一的数字,getRandom 总是返回 2 。
randomSet.getRandom();
class RandomizedSet {
private Map<Integer, Integer> map = new HashMap<>();
private List<Integer> list = new ArrayList<>();
private Random random = new Random();
public RandomizedSet() {
}
public boolean insert(int val) {
if (map.containsKey(val)) {
return false;
}
map.put(val, list.size());
list.add(list.size(), val);
return true;
}
public boolean remove(int val) {
if (!map.containsKey(val)) {
return false;
}
int lastElement = list.get(list.size() - 1);
int idx = map.get(val);
list.set(idx, lastElement);
map.put(lastElement, idx);
list.remove(list.size() - 1);
map.remove(val);
return true;
}
public int getRandom() {
return list.get(random.nextInt(list.size()));
}
}解析:使用一个map,键为val,值val的下标
使用一个list,存储元素val
使用一个random作为随机数生成器
438. 找到字符串中所有字母异位词 中等
给定一个字符串 s 和一个非空字符串 p,找到 s 中所有是 p 的字母异位词的子串,返回这些子串的起始索引。
字符串只包含小写英文字母,并且字符串 s 和 p 的长度都不超过 20100。
说明:
- 字母异位词指字母相同,但排列不同的字符串。
- 不考虑答案输出的顺序。
示例 1:
输入:
s: "cbaebabacd" p: "abc"
输出:
[0, 6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的字母异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的字母异位词。
示例 2:
输入:
s: "abab" p: "ab"
输出:
[0, 1, 2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的字母异位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的字母异位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的字母异位词。
public List<Integer> findAnagrams(String s, String p) {
List<Integer> ans = new ArrayList<>();
if (s == null || p == null || s.length() < p.length()) {
return ans;
}
char[] pArr = p.toCharArray();
Arrays.sort(pArr);
int n = p.length();
for (int i = 0; i <= s.length() - n; i++) {
char[] sArr = s.substring(i, i + n).toCharArray();
Arrays.sort(sArr);
if (Arrays.equals(pArr, sArr)) {
ans.add(i);
}
}
return ans;
}解析:简单版本的实现
451. 根据字符出现频率排序 中等
给定一个字符串,请将字符串里的字符按照出现的频率降序排列。
示例 1:
输入:
"tree"
输出:
"eert"
解释:
'e'出现两次,'r'和't'都只出现一次。
因此'e'必须出现在'r'和't'之前。此外,"eetr"也是一个有效的答案。
示例 2:
输入:
"cccaaa"
输出:
"cccaaa"
解释:
'c'和'a'都出现三次。此外,"aaaccc"也是有效的答案。
注意"cacaca"是不正确的,因为相同的字母必须放在一起。
示例 3:
输入:
"Aabb"
输出:
"bbAa"
解释:
此外,"bbaA"也是一个有效的答案,但"Aabb"是不正确的。
注意'A'和'a'被认为是两种不同的字符。
public String frequencySort(String s) {
Map<Character, Integer> map = new HashMap<>();
for (int i = 0; i < s.length(); i++) {
char ch = s.charAt(i);
map.put(ch, map.getOrDefault(ch, 0) + 1);
}
List<Map.Entry<Character, Integer>> list = new ArrayList<>(map.entrySet());
list.sort(new Comparator<Map.Entry<Character, Integer>>() {
@Override
public int compare(Map.Entry<Character, Integer> o1, Map.Entry<Character, Integer> o2) {
return o2.getValue().compareTo(o1.getValue());
}
});
StringBuilder builder = new StringBuilder();
for (Map.Entry<Character, Integer> entry : list) {
for (Integer i = 0; i < entry.getValue(); i++) {
builder.append(entry.getKey());
}
}
return builder.toString();
}解析:先将s中的字符及各个字符的元素个数存储在map集合中
然后按照元素个数来进行排序
根据字符的数量进行拼接成一个字符串
454. 四数相加 II 中等
给定四个包含整数的数组列表 A , B , C , D ,计算有多少个元组 (i, j, k, l) ,使得 A[i] + B[j] + C[k] + D[l] = 0。
为了使问题简单化,所有的 A, B, C, D 具有相同的长度 N,且 0 ≤ N ≤ 500 。所有整数的范围在 -228 到 228 - 1 之间,最终结果不会超过 231 - 1 。
例如:
输入:
A = [ 1, 2]
B = [-2,-1]
C = [-1, 2]
D = [ 0, 2]
输出:
2
解释:
两个元组如下:
1. (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0
2. (1, 1, 0, 0) -> A[1] + B[1] + C[0] + D[0] = 2 + (-1) + (-1) + 0 = 0
public int fourSumCount(int[] A, int[] B, int[] C, int[] D) {
int count = 0;
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < A.length; i++) {
for (int j = 0; j < B.length; j++) {
int sumAB = A[i] + B[j];
map.put(sumAB, map.getOrDefault(sumAB, 0) + 1);
}
}
for (int i = 0; i < C.length; i++) {
for (int j = 0; j < D.length; j++) {
int sumCD = -(C[i] + D[j]);
if (map.containsKey(sumCD)) {
count += map.get(sumCD);
}
}
}
return count;
}解析:将AB数组的结果存储在map集合中
如果map集合中包含CD数组结果的相反数,则count加上AB数组元素对应的个数
508. 出现次数最多的子树元素和 中等
给你一个二叉树的根结点,请你找出出现次数最多的子树元素和。一个结点的「子树元素和」定义为以该结点为根的二叉树上所有结点的元素之和(包括结点本身)。
你需要返回出现次数最多的子树元素和。如果有多个元素出现的次数相同,返回所有出现次数最多的子树元素和(不限顺序)。
示例 1:
输入:
5
/ \
2 -3
返回 [2, -3, 4],所有的值均只出现一次,以任意顺序返回所有值。
示例 2:
输入:
5
/ \
2 -5
返回 [2],只有 2 出现两次,-5 只出现 1 次。
提示: 假设任意子树元素和均可以用 32 位有符号整数表示。
public int[] findFrequentTreeSum(TreeNode root) {
if (root == null) {
return new int[]{};
}
Map<Integer, Integer> map = new HashMap<>();
postOrder(root, map);
List<Map.Entry<Integer, Integer>> list = new ArrayList<>(map.entrySet());
list.sort(new Comparator<Map.Entry<Integer, Integer>>() {
@Override
public int compare(Map.Entry<Integer, Integer> o1, Map.Entry<Integer, Integer> o2) {
return o2.getValue().compareTo(o1.getValue());
}
});
int val = list.get(0).getValue();
List<Integer> ans = new ArrayList<>();
for (Map.Entry<Integer, Integer> entry : list) {
if (val == entry.getValue()) {
ans.add(entry.getKey());
}
}
int[] res = new int[ans.size()];
for (int i = 0; i < ans.size(); i++) {
res[i] = ans.get(i);
}
return res;
}
private int postOrder(TreeNode root, Map<Integer, Integer> map) {
if (root == null) {
return 0;
}
int left = postOrder(root.left, map);
int right = postOrder(root.right, map);
int val = root.val + left + right;
map.put(val, map.getOrDefault(val, 0) + 1);
return val;
}解析:个人实现,效率较低
先将各个子树的节点和及其数量存储在一个map集合中
在使用map的value属性进行排序
选出最大数量的进行输出
525. 连续数组 中等
给定一个二进制数组, 找到含有相同数量的 0 和 1 的最长连续子数组(的长度)。
示例 1:
输入: [0,1]
输出: 2
说明: [0, 1] 是具有相同数量0和1的最长连续子数组。示例 2:
输入: [0,1,0]
输出: 2
说明: [0, 1] (或 [1, 0]) 是具有相同数量0和1的最长连续子数组。注意: 给定的二进制数组的长度不会超过50000。
public int findMaxLength(int[] nums) {
int count = 0, ans = 0;
Map<Integer, Integer> map = new HashMap<>();
map.put(0, -1);
for (int i = 0; i < nums.length; i++) {
count += nums[i] == 1 ? 1 : -1;
if (map.containsKey(count)) {
ans = Math.max(ans, i - map.get(count));
} else {
map.put(count, i);
}
}
return ans;
}解析:我们从头开始遍历数组,在任何时候,如果 count 变成了 0 ,这表示我们从开头到当前位置遇到的 0 和 1 的数目一样多
另一个需要注意的是,如果我们在遍历数组的过程汇中遇到了相同的 count 2 次,这意味着这两个位置之间 0 和 1 的数目一样多。
535. TinyURL 的加密与解密 中等
TinyURL是一种URL简化服务, 比如:当你输入一个URL https://leetcode.com/problems/design-tinyurl 时,它将返回一个简化的URL http://tinyurl.com/4e9iAk.
要求:设计一个 TinyURL 的加密 encode 和解密 decode 的方法。你的加密和解密算法如何设计和运作是没有限制的,你只需要保证一个URL可以被加密成一个TinyURL,并且这个TinyURL可以用解密方法恢复成原本的URL。
private Map<Integer, String> map = new HashMap<>();
private int i;
public String encode(String longUrl) {
map.put(i, longUrl);
return "http://tinyurl.com/" + i;
}
public String decode(String shortUrl) {
return map.get(Integer.parseInt(shortUrl.replace("http://tinyurl.com/", "")));
}解析:使用一个计数器,简单实现
554. 砖墙 中等
你的面前有一堵矩形的、由多行砖块组成的砖墙。 这些砖块高度相同但是宽度不同。你现在要画一条自顶向下的、穿过最少砖块的垂线。
砖墙由行的列表表示。 每一行都是一个代表从左至右每块砖的宽度的整数列表。
如果你画的线只是从砖块的边缘经过,就不算穿过这块砖。你需要找出怎样画才能使这条线穿过的砖块数量最少,并且返回穿过的砖块数量。
你不能沿着墙的两个垂直边缘之一画线,这样显然是没有穿过一块砖的。
示例:
输入: [[1,2,2,1],
[3,1,2],
[1,3,2],
[2,4],
[3,1,2],
[1,3,1,1]]
输出: 2
解释:
提示:
- 每一行砖块的宽度之和应该相等,并且不能超过 INT_MAX。
- 每一行砖块的数量在 [1,10,000] 范围内, 墙的高度在 [1,10,000] 范围内, 总的砖块数量不超过 20,000。
public int leastBricks(List<List<Integer>> wall) {
int ans = 0;
Map<Integer, Integer> map = new HashMap<>();
for (List<Integer> row : wall) {
int sum = 0;
for (int i = 0; i < row.size() - 1; i++) {
sum += row.get(i);
map.put(sum, map.getOrDefault(sum, 0) + 1);
}
}
int res = wall.size();
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
res = Math.min(res, wall.size() - entry.getValue());
}
return res;
}解析:除去每行最后一块砖
算出每块砖最后的相同的位置的数量
减去相同的位置,得到的最小值,即为最终答案
560. 和为K的子数组 中等
给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数。
示例 1 :
输入:nums = [1,1,1], k = 2
输出: 2 , [1,1] 与 [1,1] 为两种不同的情况。
说明 :
- 数组的长度为 [1, 20,000]。
- 数组中元素的范围是 [-1000, 1000] ,且整数 k 的范围是 [-1e7, 1e7]。
//前序和求解
public int subarraySum(int[] nums, int k) {
int n = nums.length;
int[] preSum = new int[n + 1];
for (int i = 0; i < nums.length; i++) {
preSum[i + 1] += preSum[i] + nums[i];
}
int res = 0;
for (int i = 0; i < n; i++) {
for (int j = i; j < n; j++) {
if (preSum[j + 1] - preSum[i] == k) {
res++;
}
}
}
return res;
}解析:先计算出数组中的各个元素的前序和
然后依次遍历求出符合条件的解即可
public int subarraySum(int[] nums, int k) {
Map<Integer, Integer> map = new HashMap<>();
int count = 0;
int preSum = 0;
map.put(preSum, 1);
for (int num : nums) {
preSum += num;
if (map.containsKey(preSum - k)) {
count += map.get(preSum - k);
}
map.put(preSum, map.getOrDefault(preSum, 0) + 1);
}
return count;
}解析:计算完包括了当前数前缀和以后,我们去查一查在当前数之前,有多少个前缀和等于 preSum - k 呢?
这是因为满足 preSum - (preSum - k) == k 的区间的个数是我们所关心的。
对于一开始的情况,下标 0 之前没有元素,可以认为前缀和为 0,个数为 1 个,因此 preSumFreq.put(0, 1);,这一点是必要且合理的。
609. 在系统中查找重复文件 中等
给定一个目录信息列表,包括目录路径,以及该目录中的所有包含内容的文件,您需要找到文件系统中的所有重复文件组的路径。一组重复的文件至少包括二个具有完全相同内容的文件。
输入列表中的单个目录信息字符串的格式如下:
"root/d1/d2/.../dm f1.txt(f1_content) f2.txt(f2_content) ... fn.txt(fn_content)"
这意味着有 n 个文件(f1.txt, f2.txt ... fn.txt 的内容分别是 f1_content, f2_content ... fn_content)在目录 root/d1/d2/.../dm 下。注意:n>=1 且 m>=0。如果 m=0,则表示该目录是根目录。
该输出是重复文件路径组的列表。对于每个组,它包含具有相同内容的文件的所有文件路径。文件路径是具有下列格式的字符串:
"directory_path/file_name.txt"
示例 1:
输入:
["root/a 1.txt(abcd) 2.txt(efgh)", "root/c 3.txt(abcd)", "root/c/d 4.txt(efgh)", "root 4.txt(efgh)"]
输出:
[["root/a/2.txt","root/c/d/4.txt","root/4.txt"],["root/a/1.txt","root/c/3.txt"]]
注:
- 最终输出不需要顺序。
- 您可以假设目录名、文件名和文件内容只有字母和数字,并且文件内容的长度在 [1,50] 的范围内。
- 给定的文件数量在 [1,20000] 个范围内。
- 您可以假设在同一目录中没有任何文件或目录共享相同的名称。
- 您可以假设每个给定的目录信息代表一个唯一的目录。目录路径和文件信息用一个空格分隔。
超越竞赛的后续行动:
- 假设您有一个真正的文件系统,您将如何搜索文件?广度搜索还是宽度搜索?
- 如果文件内容非常大(GB级别),您将如何修改您的解决方案?
- 如果每次只能读取 1 kb 的文件,您将如何修改解决方案?
- 修改后的解决方案的时间复杂度是多少?其中最耗时的部分和消耗内存的部分是什么?如何优化?
- 如何确保您发现的重复文件不是误报?
//个人实现
public List<List<String>> findDuplicate(String[] paths) {
Map<String, List<String>> map = new HashMap<>();
Map<String, Integer> map1 = new HashMap<>();
for (String path : paths) {
String[] strs = path.split(" ");
for (int i = 1; i < strs.length; i++) {
int left = strs[i].indexOf("(");
int right = strs[i].indexOf(")");
String key = strs[i].substring(left + 1, right);
map1.put(key, map1.getOrDefault(key, 0) + 1);
}
}
for (String path : paths) {
String[] strs = path.split(" ");
String keys = strs[0] + "/";
for (int i = 1; i < strs.length; i++) {
int left = strs[i].indexOf("(");
int right = strs[i].indexOf(")");
String pre = strs[i].substring(0, left);
String key = strs[i].substring(left + 1, right);
if (map1.get(key) >= 2) {
map.putIfAbsent(key, new ArrayList<>());
map.get(key).add(keys + pre);
}
}
}
List<List<String>> ans = new ArrayList<>();
for (String s : map.keySet()) {
ans.add(map.get(s));
}
return ans;
}解析:不就是截取字符串?
648. 单词替换 中等
在英语中,我们有一个叫做 词根(root)的概念,它可以跟着其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典和一个句子。你需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
你需要输出替换之后的句子。
示例 1:
输入:dictionary = ["cat","bat","rat"], sentence = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"
示例 2:
输入:dictionary = ["a","b","c"], sentence = "aadsfasf absbs bbab cadsfafs"
输出:"a a b c"
示例 3:
输入:dictionary = ["a", "aa", "aaa", "aaaa"], sentence = "a aa a aaaa aaa aaa aaa aaaaaa bbb baba ababa"
输出:"a a a a a a a a bbb baba a"
示例 4:
输入:dictionary = ["catt","cat","bat","rat"], sentence = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"
示例 5:
输入:dictionary = ["ac","ab"], sentence = "it is abnormal that this solution is accepted"
输出:"it is ab that this solution is ac"
提示:
1 <= dictionary.length <= 10001 <= dictionary[i].length <= 100dictionary[i]仅由小写字母组成。1 <= sentence.length <= 10^6sentence仅由小写字母和空格组成。sentence中单词的总量在范围[1, 1000]内。sentence中每个单词的长度在范围[1, 1000]内。sentence中单词之间由一个空格隔开。sentence没有前导或尾随空格。
public String replaceWords(List<String> dictionary, String sentence) {
Set<String> set = new HashSet<>();
StringBuilder builder = new StringBuilder();
for (String s : dictionary) {
set.add(s);
}
String[] strs = sentence.split(" ");
for (String str : strs) {
String preFix = "";
for (int i = 1; i <= str.length(); i++) {
preFix = str.substring(0, i);
if (set.contains(preFix)) {
break;
}
}
builder.append(preFix).append(" ");
}
return builder.toString().substring(0, builder.length() - 1);
}解析:将字典集合dictionary放入set集合中,降低查询的时间复杂度
切割句子sentence
将单词str从前向后切割,如果set集合中存在这个元素,则break跳出循环
将前缀preFix添加到builder后面
返回这个builder
676. 实现一个魔法字典 中等
实现一个带有buildDict, 以及 search方法的魔法字典。
对于buildDict方法,你将被给定一串不重复的单词来构建一个字典。
对于search方法,你将被给定一个单词,并且判定能否只将这个单词中一个字母换成另一个字母,使得所形成的新单词存在于你构建的字典中。
示例 1:
Input: buildDict(["hello", "leetcode"]), Output: Null
Input: search("hello"), Output: False
Input: search("hhllo"), Output: True
Input: search("hell"), Output: False
Input: search("leetcoded"), Output: False
注意:
- 你可以假设所有输入都是小写字母
a-z。 - 为了便于竞赛,测试所用的数据量很小。你可以在竞赛结束后,考虑更高效的算法。
- 请记住重置MagicDictionary类中声明的类变量,因为静态/类变量会在多个测试用例中保留。 请参阅这里了解更多详情。
//暴力法解决
class MagicDictionary {
private Map<Integer, List<String>> map = new HashMap<>();
public MagicDictionary() {
}
public void buildDict(String[] dictionary) {
for (String s : dictionary) {
int n = s.length();
map.putIfAbsent(n, new ArrayList<>());
map.get(n).add(s);
}
}
public boolean search(String searchWord) {
int n = searchWord.length();
if (!map.containsKey(n)) {
return false;
}
List<String> list = map.get(n);
for (String s : list) {
int count = 0;
for (int i = 0; i < n; i++) {
if (s.charAt(i) != searchWord.charAt(i)) {
count++;
}
}
if (count == 1) {
return true;
}
}
return false;
}
}解析:暴力法解决,将字典单词全部存入一个map集合中
查询的时候,根据map集合查找对应长度的list集合
遍历list集合,如果存在只相差一个元素的字符串,则返回true,否则返回false
//广义邻居求解
private Map<String, Integer> map = new HashMap<>();
private Set<String> set = new HashSet<>();
/** Initialize your data structure here. */
public MagicDictionary() {
}
public void buildDict(String[] dictionary) {
for (String s : dictionary) {
set.add(s);
for (String s1 : builder(s)) {
map.put(s1, map.getOrDefault(s1, 0) + 1);
}
}
}
private List<String> builder(String s) {
List<String> list = new ArrayList<>();
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i++) {
char temp = chars[i];
chars[i] = '*';
list.add(String.valueOf(chars));
chars[i] = temp;
}
return list;
}
public boolean search(String searchWord) {
for (String s : builder(searchWord)) {
int idx = map.getOrDefault(s, 0);
if (idx > 1 || idx == 1 && !set.contains(searchWord)) {
return true;
}
}
return false;
}解析:先将所有的字典字符串的邻居存入map集合中,将字典字符串存入set中
查询即可
692. 前K个高频单词 中等
给一非空的单词列表,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字母顺序排序。
示例 1:
输入: ["i", "love", "leetcode", "i", "love", "coding"], k = 2
输出: ["i", "love"]
解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 "i" 在 "love" 之前。
示例 2:
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
输出: ["the", "is", "sunny", "day"]
解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
注意:
- 假定 k 总为有效值, 1 ≤ k ≤ 集合元素数。
- 输入的单词均由小写字母组成。
扩展练习:
- 尝试以 O(n log k) 时间复杂度和 O(n) 空间复杂度解决。
//个人实现
public List<String> topKFrequent(String[] words, int k) {
List<String> ans = new ArrayList<>();
if (words == null || words.length == 0) {
return ans;
}
Map<String, Integer> map = new HashMap<>();
for (String word : words) {
map.put(word, map.getOrDefault(word, 0) + 1);
}
List<Map.Entry<String, Integer>> list = new ArrayList<>(map.entrySet());
list.sort(new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if (o2.getValue() != o1.getValue()) {
return o2.getValue().compareTo(o1.getValue());
} else {
return o1.getKey().compareTo(o2.getKey());
}
}
});
for (int i = 0; i < k && i < list.size(); i++) {
ans.add(list.get(i).getKey());
}
return ans;
}解析:个人实现,专治各种花里胡哨
按照字符串的频率倒序排序,频率相同,按照字典序排序
打印即可
739. 每日温度 中等
请根据每日 气温 列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的均为华氏度,都是在 [30, 100] 范围内的整数。
//暴力破解
public int[] dailyTemperatures(int[] T) {
int[] res = new int[T.length];
for (int i = 0; i < T.length - 1; i++) {
for (int j = i + 1; j < T.length; j++) {
if (T[j] > T[i]) {
res[i] = j - i;
break;
}
}
}
return res;
}解析:从前向后遍历,暴力破解
//单调栈
public int[] dailyTemperatures(int[] T) {
Stack<Integer> stack = new Stack<>();
int[] res = new int[T.length];
for (int i = 0; i < T.length; i++) {
while (!stack.isEmpty() && T[i] > T[stack.peek()]) {
int idx = stack.pop();
res[idx] = i - idx;
}
stack.push(i);
}
return res;
}解析:每次栈存储当前元素的下标,
当当前元素大于栈顶元素,设置栈顶元素对应位置的下标为当前元素下标减去栈顶元素下标
//从后向前遍历
public int[] dailyTemperatures(int[] T) {
int n = T.length;
int[] res = new int[n];
for (int i = n - 2; i >= 0; i--) {
for (int j = i + 1; j < n; j += res[j]) {
//找到的比当前更大的值了
if (T[j] > T[i]) {
res[i] = j - i;
break;
//表示后面不会有比当前更大的值了,赋值为0后直接跳过
} else if (res[j] == 0) {
res[i] = 0;
break;
}
}
}
return res;
}解析:从后向前遍历,此方式效率较高
每次j加上res[j]个长度进行遍历
如果找到了比当前更大的值,则直接给当前值赋值
如果res[j]==0,则表示后面不会存在比当前更大的值,直接跳过
781. 森林中的兔子 中等
森林中,每个兔子都有颜色。其中一些兔子(可能是全部)告诉你还有多少其他的兔子和自己有相同的颜色。我们将这些回答放在 answers 数组里。
返回森林中兔子的最少数量。
示例:
输入: answers = [1, 1, 2]
输出: 5
解释:
两只回答了 "1" 的兔子可能有相同的颜色,设为红色。
之后回答了 "2" 的兔子不会是红色,否则他们的回答会相互矛盾。
设回答了 "2" 的兔子为蓝色。
此外,森林中还应有另外 2 只蓝色兔子的回答没有包含在数组中。
因此森林中兔子的最少数量是 5: 3 只回答的和 2 只没有回答的。
输入: answers = [10, 10, 10]
输出: 11
输入: answers = []
输出: 0
说明:
answers的长度最大为1000。answers[i]是在[0, 999]范围内的整数。
public int numRabbits(int[] answers) {
Map<Integer, Integer> map = new HashMap<>();
for (int answer : answers) {
map.put(answer, map.getOrDefault(answer, 0) + 1);
}
int ans = 0;
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
int key = entry.getKey() + 1;
int val = entry.getValue();
//获取大于val的key的最小倍数
ans += (-val % key + key) % key + val;
}
return ans;
}解析:主要是获取大于val的key的最小倍数,较难理解
930. 和相同的二元子数组 中等
在由若干 0 和 1 组成的数组 A 中,有多少个和为 S 的非空子数组。
示例:
输入:A = [1,0,1,0,1], S = 2
输出:4
解释:
如下面黑体所示,有 4 个满足题目要求的子数组:
[1,0,1,0,1]
[1,0,1,0,1]
[1,0,1,0,1]
[1,0,1,0,1]
提示:
A.length <= 300000 <= S <= A.lengthA[i]为0或1
//前序和+map
public int numSubarraysWithSum(int[] A, int S) {
int n = A.length;
int[] preSum = new int[n + 1];
for (int i = 0; i < n; i++) {
preSum[i + 1] += preSum[i] + A[i];
}
int ans = 0;
Map<Integer, Integer> map = new HashMap<>();
for (int ele : preSum) {
ans += map.getOrDefault(ele, 0);
map.put(ele + S, map.getOrDefault(ele + S, 0) + 1);
}
return ans;
}解析:使用前序和将数组中元素全部存储起来,然后用map进行遍历
939. 最小面积矩形 中等
给定在 xy 平面上的一组点,确定由这些点组成的矩形的最小面积,其中矩形的边平行于 x 轴和 y 轴。
如果没有任何矩形,就返回 0。
示例 1:
输入:[[1,1],[1,3],[3,1],[3,3],[2,2]]
输出:4
示例 2:
输入:[[1,1],[1,3],[3,1],[3,3],[4,1],[4,3]]
输出:2
提示:
1 <= points.length <= 5000 <= points[i][0] <= 400000 <= points[i][1] <= 40000- 所有的点都是不同的。
public int minAreaRect(int[][] points) {
//自带排序功能,按照x值的大小,从小到大排序
Map<Integer, List<Integer>> rows = new TreeMap<>();
for (int[] point : points) {
int x = point[0], y = point[1];
rows.putIfAbsent(x, new ArrayList<>());
rows.get(x).add(y);
}
Map<Integer, Integer> map = new HashMap<>();
int ans = Integer.MAX_VALUE;
for (int x : rows.keySet()) {
List<Integer> row = rows.get(x);
Collections.sort(row);
for (int i = 0; i < row.size(); i++) {
for (int j = i + 1; j < row.size(); j++) {
//获取直线的开始点
int y1 = row.get(i);
//获取直线的结束点
int y2 = row.get(j);
//将直线y1到y2作为key
int mod = y1 * 40001 + y2;
if (map.containsKey(mod)) {
ans = Math.min(ans, (x - map.get(mod)) * (y2 - y1));
}
//将直线y1到y2作为key,将这条直线的x作为value
map.put(mod, x);
}
}
}
return ans == Integer.MAX_VALUE ? 0 : ans;
}解析:使用TreeMap作为容器,存储所有的点
每次以一整条直线作为key,直线对应的x为value,存储在一个map集合中
954. 二倍数对数组 中等
给定一个长度为偶数的整数数组 A,只有对 A 进行重组后可以满足 “对于每个 0 <= i < len(A) / 2,都有 A[2 * i + 1] = 2 * A[2 * i]” 时,返回 true;否则,返回 false。
示例 1:
输入:[3,1,3,6]
输出:false
示例 2:
输入:[2,1,2,6]
输出:false
示例 3:
输入:[4,-2,2,-4]
输出:true
解释:我们可以用 [-2,-4] 和 [2,4] 这两组组成 [-2,-4,2,4] 或是 [2,4,-2,-4]示例 4:
输入:[1,2,4,16,8,4]
输出:false
提示:
0 <= A.length <= 30000A.length为偶数-100000 <= A[i] <= 100000
//个人实现,一定要先排序
public boolean canReorderDoubled(int[] A) {
Arrays.sort(A);
Map<Integer, Integer> map = new HashMap<>();
for (int ele : A) {
if (map.containsKey(2 * ele)) {
int count = map.get(2 * ele);
if (count == 1) {
map.remove(2 * ele);
} else {
map.put(2 * ele, --count);
}
} else if (map.containsKey(ele / 2) && ele % 2 == 0) {
int count = map.get(ele / 2);
if (count == 1) {
map.remove(ele / 2);
} else {
map.put(ele / 2, --count);
}
} else {
map.put(ele, map.getOrDefault(ele, 0) + 1);
}
}
return map.isEmpty();
}解析:使用之前一定要先排序,否则可能会出现匹配错误的问题
966. 元音拼写检查器 中等
在给定单词列表 wordlist 的情况下,我们希望实现一个拼写检查器,将查询单词转换为正确的单词。
对于给定的查询单词 query,拼写检查器将会处理两类拼写错误:
- 大小写:如果查询匹配单词列表中的某个单词(不区分大小写),则返回的正确单词与单词列表中的大小写相同。
- 例如:
wordlist = ["yellow"],query = "YellOw":correct = "yellow" - 例如:
wordlist = ["Yellow"],query = "yellow":correct = "Yellow" - 例如:
wordlist = ["yellow"],query = "yellow":correct = "yellow"
- 例如:
- 元音错误:如果在将查询单词中的元音(‘a’、‘e’、‘i’、‘o’、‘u’)分别替换为任何元音后,能与单词列表中的单词匹配(不区分大小写),则返回的正确单词与单词列表中的匹配项大小写相同。
- 例如:
wordlist = ["YellOw"],query = "yollow":correct = "YellOw" - 例如:
wordlist = ["YellOw"],query = "yeellow":correct = ""(无匹配项) - 例如:
wordlist = ["YellOw"],query = "yllw":correct = ""(无匹配项)
- 例如:
此外,拼写检查器还按照以下优先级规则操作:
- 当查询完全匹配单词列表中的某个单词(区分大小写)时,应返回相同的单词。
- 当查询匹配到大小写问题的单词时,您应该返回单词列表中的第一个这样的匹配项。
- 当查询匹配到元音错误的单词时,您应该返回单词列表中的第一个这样的匹配项。
- 如果该查询在单词列表中没有匹配项,则应返回空字符串。
给出一些查询 queries,返回一个单词列表 answer,其中 answer[i] 是由查询 query = queries[i] 得到的正确单词。
示例:
输入:wordlist = ["KiTe","kite","hare","Hare"], queries = ["kite","Kite","KiTe","Hare","HARE","Hear","hear","keti","keet","keto"]
输出:["kite","KiTe","KiTe","Hare","hare","","","KiTe","","KiTe"]提示:
1 <= wordlist.length <= 50001 <= queries.length <= 50001 <= wordlist[i].length <= 71 <= queries[i].length <= 7wordlist和queries中的所有字符串仅由英文字母组成。
private Set<String> set = new HashSet<>();
//大小写
private Map<String, String> map1 = new HashMap<>();
//元音错误
private Map<String, String> map2 = new HashMap<>();
public String[] spellchecker(String[] wordlist, String[] queries) {
for (String s : wordlist) {
set.add(s);
String lowS = s.toLowerCase();
map1.putIfAbsent(lowS, s);
String buS = builder(s);
map2.putIfAbsent(buS, s);
}
String[] res = new String[queries.length];
int k = 0;
for (String query : queries) {
res[k++] = solver(query);
}
return res;
}
//传入一个字符串,返回对应的输出结果
private String solver(String s) {
//完全匹配
if (set.contains(s)) {
return s;
}
//大小写不同
String lowS = s.toLowerCase();
if (map1.containsKey(lowS)) {
return map1.get(lowS);
}
//元音字母
String buS = builder(s);
if (map2.containsKey(buS)) {
return map2.get(buS);
}
return "";
}
//返回可能得元音字母错误
private String builder(String s) {
StringBuilder builder = new StringBuilder();
char[] chars = s.toLowerCase().toCharArray();
for (int i = 0; i < chars.length; i++) {
builder.append(isVowel(chars[i]) ? '*' : chars[i]);
}
return builder.toString();
}
//是否元音字母
private boolean isVowel(char ch) {
return ch == 'a' || ch == 'e' || ch == 'i' || ch == 'o' || ch == 'u';
}解析:
对于第一种情况(完全匹配),我们使用集合存放单词以有效地测试查询单词是否在该组中。
对于第二种情况(大小写不同),我们使用一个哈希表,该哈希表将单词从其小写形式转换为原始单词(大小写正确的形式)。
对于第三种情况(元音错误),我们使用一个哈希表,将单词从其小写形式(忽略元音的情况下)转换为原始单词。
974. 和可被 K 整除的子数组 中等
给定一个整数数组 A,返回其中元素之和可被 K 整除的(连续、非空)子数组的数目。
示例:
输入:A = [4,5,0,-2,-3,1], K = 5
输出:7
解释:
有 7 个子数组满足其元素之和可被 K = 5 整除:
[4, 5, 0, -2, -3, 1], [5], [5, 0], [5, 0, -2, -3], [0], [0, -2, -3], [-2, -3]
提示:
1 <= A.length <= 30000-10000 <= A[i] <= 100002 <= K <= 10000
public int subarraysDivByK(int[] A, int K) {
//哈希表+逐一统计
Map<Integer, Integer> map = new HashMap<>();
int ans = 0, sum = 0;
map.put(0, 1);
for (int ele : A) {
sum += ele;
int mod = (sum % K + K) % K;
int m = map.getOrDefault(mod, 0);
ans += m;
map.put(mod, m + 1);
}
return ans;
}解析:如果前缀相等,则相减为0,对0取模为0
public int subarraysDivByK(int[] A, int K) {
//哈希表+单次统计
Map<Integer, Integer> map = new HashMap<>();
int ans = 0, sum = 0;
map.put(0, 1);
for (int ele : A) {
sum += ele;
int mod = (sum % K + K) % K;
map.put(mod, map.getOrDefault(mod, 0) + 1);
}
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
ans += entry.getValue() * (entry.getValue() - 1) / 2;
}
return ans;
}解析:如果前缀相同,则相减为0,对0取模为0
将每一个mod出现的次数统计出来
计算即可
981. 基于时间的键值存储 中等
创建一个基于时间的键值存储类 TimeMap,它支持下面两个操作:
1. set(string key, string value, int timestamp)
- 存储键
key、值value,以及给定的时间戳timestamp。
2. get(string key, int timestamp)
- 返回先前调用
set(key, value, timestamp_prev)所存储的值,其中timestamp_prev <= timestamp。 - 如果有多个这样的值,则返回对应最大的
timestamp_prev的那个值。 - 如果没有值,则返回空字符串(
"")。
示例 1:
输入:inputs = ["TimeMap","set","get","get","set","get","get"], inputs = [[],["foo","bar",1],["foo",1],["foo",3],["foo","bar2",4],["foo",4],["foo",5]]
输出:[null,null,"bar","bar",null,"bar2","bar2"]
解释:
TimeMap kv;
kv.set("foo", "bar", 1); // 存储键 "foo" 和值 "bar" 以及时间戳 timestamp = 1
kv.get("foo", 1); // 输出 "bar"
kv.get("foo", 3); // 输出 "bar" 因为在时间戳 3 和时间戳 2 处没有对应 "foo" 的值,所以唯一的值位于时间戳 1 处(即 "bar")
kv.set("foo", "bar2", 4);
kv.get("foo", 4); // 输出 "bar2"
kv.get("foo", 5); // 输出 "bar2"
示例 2:
输入:inputs = ["TimeMap","set","set","get","get","get","get","get"], inputs = [[],["love","high",10],["love","low",20],["love",5],["love",10],["love",15],["love",20],["love",25]]
输出:[null,null,null,"","high","high","low","low"]
提示:
- 所有的键/值字符串都是小写的。
- 所有的键/值字符串长度都在
[1, 100]范围内。 - 所有
TimeMap.set操作中的时间戳timestamps都是严格递增的。 1 <= timestamp <= 10^7TimeMap.set和TimeMap.get函数在每个测试用例中将(组合)调用总计120000次。
class TimeMap {
private Map<String, TreeMap<Integer, String>> map = new HashMap<>();
/** Initialize your data structure here. */
public TimeMap() {
}
public void set(String key, String value, int timestamp) {
if (!map.containsKey(key)) {
map.put(key, new TreeMap<>());
}
map.get(key).put(timestamp, value);
}
public String get(String key, int timestamp) {
if (!map.containsKey(key)) {
return "";
}
TreeMap<Integer, String> treeMap = map.get(key);
Integer i = treeMap.floorKey(timestamp);
return i != null ? treeMap.get(i) : "";
}
}解析:使用HashMap+TreeMap的组合,TreeMap自带排序功能
987. 二叉树的垂序遍历 中等
给定二叉树,按垂序遍历返回其结点值。
对位于 (X, Y) 的每个结点而言,其左右子结点分别位于 (X-1, Y-1) 和 (X+1, Y-1)。
把一条垂线从 X = -infinity 移动到 X = +infinity ,每当该垂线与结点接触时,我们按从上到下的顺序报告结点的值( Y 坐标递减)。
如果两个结点位置相同,则首先报告的结点值较小。
按 X 坐标顺序返回非空报告的列表。每个报告都有一个结点值列表。
示例 1:

输入:[3,9,20,null,null,15,7]
输出:[[9],[3,15],[20],[7]]
解释:
在不丧失其普遍性的情况下,我们可以假设根结点位于 (0, 0):
然后,值为 9 的结点出现在 (-1, -1);
值为 3 和 15 的两个结点分别出现在 (0, 0) 和 (0, -2);
值为 20 的结点出现在 (1, -1);
值为 7 的结点出现在 (2, -2)。
示例 2:

输入:[1,2,3,4,5,6,7]
输出:[[4],[2],[1,5,6],[3],[7]]
解释:
根据给定的方案,值为 5 和 6 的两个结点出现在同一位置。
然而,在报告 "[1,5,6]" 中,结点值 5 排在前面,因为 5 小于 6。
提示:
- 树的结点数介于
1和1000之间。 - 每个结点值介于
0和1000之间。
class Solution {
public List<List<Integer>> verticalTraversal(TreeNode root) {
List<List<Integer>> ans = new ArrayList<>();
if (root == null) {
return ans;
}
List<Tree> list = new ArrayList<>();
dfs(root, 0, 0, list);
list.sort(new Comparator<Tree>() {
@Override
public int compare(Tree o1, Tree o2) {
if (o1.x != o2.x) {
return o1.x - o2.x;
} else if (o1.y != o2.y) {
return o1.y - o2.y;
} else {
return o1.val - o2.val;
}
}
});
int preX = list.get(0).x;
ans.add(new ArrayList<>());
for (Tree tree : list) {
if (tree.x != preX) {
preX = tree.x;
ans.add(new ArrayList<>());
}
ans.get(ans.size() - 1).add(tree.val);
}
return ans;
}
private void dfs(TreeNode root, int x, int y, List<Tree> list) {
if (root != null) {
list.add(new Tree(root.val, x, y));
dfs(root.left, x - 1, y + 1, list);
dfs(root.right, x + 1, y + 1, list);
}
}
}
class Tree{
int val;
int x;
int y;
public Tree(int val, int x, int y) {
this.val = val;
this.x = x;
this.y = y;
}
}解析:将节点信息,x和y信息封装到一个Tree对象中
通过前序遍历将遍历到的信息放入一个list集合中
对这个集合进行排序
从前向后依次封装到ans中
1048. 最长字符串链 中等
给出一个单词列表,其中每个单词都由小写英文字母组成。
如果我们可以在 word1 的任何地方添加一个字母使其变成 word2,那么我们认为 word1 是 word2 的前身。例如,"abc" 是 "abac" 的前身。
词链是单词 [word_1, word_2, ..., word_k] 组成的序列,k >= 1,其中 word_1 是 word_2 的前身,word_2 是 word_3 的前身,依此类推。
从给定单词列表 words 中选择单词组成词链,返回词链的最长可能长度。
示例:
输入:["a","b","ba","bca","bda","bdca"]
输出:4
解释:最长单词链之一为 "a","ba","bda","bdca"。
提示:
1 <= words.length <= 10001 <= words[i].length <= 16words[i]仅由小写英文字母组成。
public int longestStrChain(String[] words) {
Map<String, Integer> map = new HashMap<>();
Arrays.sort(words, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();
}
});
int ans = 0;
for (String word : words) {
map.put(word, 1);
for (int i = 0; i < word.length(); i++) {
StringBuilder builder = new StringBuilder(word);
String next = builder.deleteCharAt(i).toString();
if (map.containsKey(next) && map.get(next) + 1 > map.get(word)) {
map.put(word, map.get(next) + 1);
}
}
ans = Math.max(ans, map.get(word));
}
return ans;
}解析:先对数组中的数据,按照长度从小到大进行排序
依次初始化当前元素的最长子串长度为1
如果存在前驱子串,且前驱子串的长度+1大于当前子串长度
则将当前子串长度设置为前区长度+1
每次更新最长长度ans
1072. 按列翻转得到最大值等行数 中等
给定由若干 0 和 1 组成的矩阵 matrix,从中选出任意数量的列并翻转其上的 每个 单元格。翻转后,单元格的值从 0 变成 1,或者从 1 变为 0 。
返回经过一些翻转后,行上所有值都相等的最大行数。
示例 1:
输入:[[0,1],[1,1]] 输出:1 解释:不进行翻转,有 1 行所有值都相等。
示例 2:
输入:[[0,1],[1,0]] 输出:2 解释:翻转第一列的值之后,这两行都由相等的值组成。
示例 3:
输入:[[0,0,0],[0,0,1],[1,1,0]] 输出:2 解释:翻转前两列的值之后,后两行由相等的值组成。
提示:
1 <= matrix.length <= 3001 <= matrix[i].length <= 300- 所有
matrix[i].length都相等 matrix[i][j]为0或1
public int maxEqualRowsAfterFlips(int[][] matrix) {
Map<String, Integer> map = new HashMap<>();
int m = matrix.length;
int n = matrix[0].length;
int ans = 0;
boolean isZero = false;
for (int i = 0; i < m; i++) {
if (matrix[i][0] == 0) {
isZero = true;
} else {
isZero = false;
}
StringBuilder builder = new StringBuilder();
for (int j = 0; j < n; j++) {
if (isZero) {
builder.append(matrix[i][j]);
} else {
builder.append(matrix[i][j] ^ 1);
}
}
String temp = builder.toString();
map.put(temp, map.getOrDefault(temp, 0) + 1);
ans = Math.max(ans, map.get(temp));
}
return ans;
}解析:读懂题意最重要
可以将问题转为查找相同特征的行的最大数量
1090. 受标签影响的最大值 中等
我们有一个项的集合,其中第 i 项的值为 values[i],标签为 labels[i]。
我们从这些项中选出一个子集 S,这样一来:
|S| <= num_wanted- 对于任意的标签
L,子集S中标签为L的项的数目总满足<= use_limit。
返回子集 S 的最大可能的 和。
示例 1:
输入:values = [5,4,3,2,1], labels = [1,1,2,2,3], num_wanted = 3, use_limit = 1
输出:9
解释:选出的子集是第一项,第三项和第五项。
示例 2:
输入:values = [5,4,3,2,1], labels = [1,3,3,3,2], num_wanted = 3, use_limit = 2
输出:12
解释:选出的子集是第一项,第二项和第三项。
示例 3:
输入:values = [9,8,8,7,6], labels = [0,0,0,1,1], num_wanted = 3, use_limit = 1
输出:16
解释:选出的子集是第一项和第四项。
示例 4:
输入:values = [9,8,8,7,6], labels = [0,0,0,1,1], num_wanted = 3, use_limit = 2
输出:24
解释:选出的子集是第一项,第二项和第四项。
提示:
1 <= values.length == labels.length <= 200000 <= values[i], labels[i] <= 200001 <= num_wanted, use_limit <= values.length
class Solution {
public int largestValsFromLabels(int[] values, int[] labels, int num_wanted, int use_limit) {
PriorityQueue<Item> heap = new PriorityQueue<>(new Comparator<Item>() {
@Override
public int compare(Item o1, Item o2) {
return o2.value - o1.value;
}
});
Map<Integer, Integer> map = new HashMap<>();
int n = values.length;
for (int i = 0; i < n; i++) {
heap.add(new Item(values[i], labels[i]));
}
int count = 0;
int sum = 0;
while (!heap.isEmpty() && count < num_wanted) {
Item item = heap.poll();
if (!map.containsKey(item.label)) {
map.put(item.label, 1);
count++;
sum += item.value;
} else {
int k = map.get(item.label);
if (k < use_limit) {
map.put(item.label, k + 1);
count++;
sum += item.value;
}
}
}
return sum;
}
}
class Item{
int value;
int label;
public Item(int value, int label) {
this.value = value;
this.label = label;
}
}解析:创建一个新的类Item存储value和lable
将数组中的value和label存储在堆中
使用map来控制label的使用数量
1138. 字母板上的路径 中等
我们从一块字母板上的位置 (0, 0) 出发,该坐标对应的字符为 board[0][0]。
在本题里,字母板为board = ["abcde", "fghij", "klmno", "pqrst", "uvwxy", "z"],如下所示。

我们可以按下面的指令规则行动:
- 如果方格存在,
'U'意味着将我们的位置上移一行; - 如果方格存在,
'D'意味着将我们的位置下移一行; - 如果方格存在,
'L'意味着将我们的位置左移一列; - 如果方格存在,
'R'意味着将我们的位置右移一列; '!'会把在我们当前位置(r, c)的字符board[r][c]添加到答案中。
(注意,字母板上只存在有字母的位置。)
返回指令序列,用最小的行动次数让答案和目标 target 相同。你可以返回任何达成目标的路径。
示例 1:
输入:target = "leet"
输出:"DDR!UURRR!!DDD!"
示例 2:
输入:target = "code"
输出:"RR!DDRR!UUL!R!"
提示:
1 <= target.length <= 100target仅含有小写英文字母。
public String alphabetBoardPath(String target) {
int x = 0, y = 0, nx = 0, ny = 0;
Map<Integer, StringBuilder> map = new HashMap<>();
StringBuilder builder = new StringBuilder();
for (int i = 0; i < target.length(); i++) {
int temp = target.charAt(i) - 'a';
StringBuilder builder1 = new StringBuilder();
if (i > 0 && target.charAt(i) == target.charAt(i - 1)) {
builder.append("!");
} else if (map.containsKey(builder1)) {
builder.append(map.get(builder1));
x = temp / 5;
y = temp % 5;
} else {
nx = temp / 5;
ny = temp % 5;
if (y > ny) {
for (int j = 0; j < y - ny; j++) {
builder1.append("L");
}
}
if (x > nx) {
for (int j = 0; j < x - nx; j++) {
builder1.append("U");
}
}
if (x < nx) {
for (int j = 0; j < nx - x; j++) {
builder1.append("D");
}
}
if (y < ny) {
for (int j = 0; j < ny - y; j++) {
builder1.append("R");
}
}
builder1.append("!");
builder.append(builder1);
map.put(temp, builder1);
x = nx;
y = ny;
}
}
return builder.toString();
}解析:先算出字母的下标
使用上下左右移动下标
将字母的移动路径记录在map集合中
1487. 保证文件名唯一 中等
给你一个长度为 n 的字符串数组 names 。你将会在文件系统中创建 n 个文件夹:在第 i 分钟,新建名为 names[i] 的文件夹。
由于两个文件 不能 共享相同的文件名,因此如果新建文件夹使用的文件名已经被占用,系统会以 (k) 的形式为新文件夹的文件名添加后缀,其中 k 是能保证文件名唯一的 最小正整数 。
返回长度为 n 的字符串数组,其中 ans[i] 是创建第 i 个文件夹时系统分配给该文件夹的实际名称。
示例 1:
输入:names = ["pes","fifa","gta","pes(2019)"]
输出:["pes","fifa","gta","pes(2019)"]
解释:文件系统将会这样创建文件名:
"pes" --> 之前未分配,仍为 "pes"
"fifa" --> 之前未分配,仍为 "fifa"
"gta" --> 之前未分配,仍为 "gta"
"pes(2019)" --> 之前未分配,仍为 "pes(2019)"
示例 2:
输入:names = ["gta","gta(1)","gta","avalon"]
输出:["gta","gta(1)","gta(2)","avalon"]
解释:文件系统将会这样创建文件名:
"gta" --> 之前未分配,仍为 "gta"
"gta(1)" --> 之前未分配,仍为 "gta(1)"
"gta" --> 文件名被占用,系统为该名称添加后缀 (k),由于 "gta(1)" 也被占用,所以 k = 2 。实际创建的文件名为 "gta(2)" 。
"avalon" --> 之前未分配,仍为 "avalon"
示例 3:
输入:names = ["onepiece","onepiece(1)","onepiece(2)","onepiece(3)","onepiece"]
输出:["onepiece","onepiece(1)","onepiece(2)","onepiece(3)","onepiece(4)"]
解释:当创建最后一个文件夹时,最小的正有效 k 为 4 ,文件名变为 "onepiece(4)"。
示例 4:
输入:names = ["wano","wano","wano","wano"]
输出:["wano","wano(1)","wano(2)","wano(3)"]
解释:每次创建文件夹 "wano" 时,只需增加后缀中 k 的值即可。示例 5:
输入:names = ["kaido","kaido(1)","kaido","kaido(1)"]
输出:["kaido","kaido(1)","kaido(2)","kaido(1)(1)"]
解释:注意,如果含后缀文件名被占用,那么系统也会按规则在名称后添加新的后缀 (k) 。
提示:
1 <= names.length <= 5 * 10^41 <= names[i].length <= 20names[i]由小写英文字母、数字和/或圆括号组成。
public String[] getFolderNames(String[] names) {
Map<String, Integer> map = new HashMap<>();
String[] arr = new String[names.length];
int i = 0;
for (String name : names) {
if (!map.containsKey(name)) {
map.put(name, 1);
arr[i++] = name;
} else {
int count = map.get(name);
while (map.containsKey(name + "(" + count + ")")) {
count++;
}
map.put(name + "(" + count + ")", 1);
arr[i++] = name + "(" + count + ")";
map.put(name, map.get(name) + 1);
}
}
return arr;
}解析:用map存储name本身及其数量
如果存在,则后加(count)
没有直接存储
1577. 数的平方等于两数乘积的方法数 中等
给你两个整数数组 nums1 和 nums2 ,请你返回根据以下规则形成的三元组的数目(类型 1 和类型 2 ):
- 类型 1:三元组
(i, j, k),如果nums1[i]2 == nums2[j] * nums2[k]其中0 <= i < nums1.length且0 <= j < k < nums2.length - 类型 2:三元组
(i, j, k),如果nums2[i]2 == nums1[j] * nums1[k]其中0 <= i < nums2.length且0 <= j < k < nums1.length
示例 1:
输入:nums1 = [7,4], nums2 = [5,2,8,9]
输出:1
解释:类型 1:(1,1,2), nums1[1]^2 = nums2[1] * nums2[2] (4^2 = 2 * 8)示例 2:
输入:nums1 = [1,1], nums2 = [1,1,1]
输出:9
解释:所有三元组都符合题目要求,因为 1^2 = 1 * 1
类型 1:(0,0,1), (0,0,2), (0,1,2), (1,0,1), (1,0,2), (1,1,2), nums1[i]^2 = nums2[j] * nums2[k]
类型 2:(0,0,1), (1,0,1), (2,0,1), nums2[i]^2 = nums1[j] * nums1[k]
示例 3:
输入:nums1 = [7,7,8,3], nums2 = [1,2,9,7]
输出:2
解释:有两个符合题目要求的三元组
类型 1:(3,0,2), nums1[3]^2 = nums2[0] * nums2[2]
类型 2:(3,0,1), nums2[3]^2 = nums1[0] * nums1[1]
示例 4:
输入:nums1 = [4,7,9,11,23], nums2 = [3,5,1024,12,18]
输出:0
解释:不存在符合题目要求的三元组
提示:
1 <= nums1.length, nums2.length <= 10001 <= nums1[i], nums2[i] <= 10^5
class Solution {
public int numTriplets(int[] nums1, int[] nums2) {
return helper(nums1, nums2) + helper(nums2, nums1);
}
private int helper(int[] num1, int[] num2) {
if (num1.length < 2) {
return 0;
}
int ans = 0;
Map<Long, Integer> map = new HashMap<>();
for (int i = 0; i < num1.length; i++) {
for (int j = i + 1; j < num1.length; j++) {
long val = (long) num1[i] * (long) num1[j];
map.put(val, map.getOrDefault(val, 0) + 1);
}
}
for (int i = 0; i < num2.length; i++) {
long val = (long) num2[i] * (long) num2[i];
if (map.containsKey(val)) {
ans += map.get(val);
}
}
return ans;
}
}解析:就是分成两种情况
在第一个数组中找出两个数相乘,得到的结果和数量存入map中
在第二个数组中炒一个数进行平方,在map集合中查询
返回最终结果
面试题
面试题 10.02. 变位词组 中等
编写一种方法,对字符串数组进行排序,将所有变位词组合在一起。变位词是指字母相同,但排列不同的字符串。
注意:本题相对原题稍作修改
示例:
输入: ["eat", "tea", "tan", "ate", "nat", "bat"],
输出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
说明:
- 所有输入均为小写字母。
- 不考虑答案输出的顺序。
public List<List<String>> groupAnagrams(String[] strs) {
List<List<String>> ans = new ArrayList<>();
if (strs == null || strs.length == 0) {
return ans;
}
Map<String, List<String>> map = new HashMap<>();
for (String str : strs) {
char[] chars = str.toCharArray();
Arrays.sort(chars);
String key = String.valueOf(chars);
map.putIfAbsent(key, new ArrayList<>());
map.get(key).add(str);
}
for (Map.Entry<String, List<String>> entry : map.entrySet()) {
ans.add(entry.getValue());
}
return ans;
}解析:和字母异位词分组是一个题
面试题 16.02. 单词频率 中等
设计一个方法,找出任意指定单词在一本书中的出现频率。
你的实现应该支持如下操作:
WordsFrequency(book)构造函数,参数为字符串数组构成的一本书get(word)查询指定单词在书中出现的频率
示例:
WordsFrequency wordsFrequency = new WordsFrequency({"i", "have", "an", "apple", "he", "have", "a", "pen"});
wordsFrequency.get("you"); //返回0,"you"没有出现过
wordsFrequency.get("have"); //返回2,"have"出现2次
wordsFrequency.get("an"); //返回1
wordsFrequency.get("apple"); //返回1
wordsFrequency.get("pen"); //返回1
提示:
book[i]中只包含小写字母1 <= book.length <= 1000001 <= book[i].length <= 10get函数的调用次数不会超过100000
class WordsFrequency {
private Map<String, Integer> map = new HashMap<>();
public WordsFrequency(String[] book) {
for (String s : book) {
map.put(s, map.getOrDefault(s, 0) + 1);
}
}
public int get(String word) {
return map.getOrDefault(word, 0);
}
}解析:这种方式实现简单的一逼
面试题 16.24. 数对和 中等
设计一个算法,找出数组中两数之和为指定值的所有整数对。一个数只能属于一个数对。
示例 1:
输入: nums = [5,6,5], target = 11
输出: [[5,6]]示例 2:
输入: nums = [5,6,5,6], target = 11
输出: [[5,6],[5,6]]提示:
nums.length <= 100000
public List<List<Integer>> pairSums(int[] nums, int target) {
//个人实现,暴力破解,不通过
List<List<Integer>> ans = new ArrayList<>();
if (nums == null || nums.length == 0) {
return ans;
}
int n = nums.length;
boolean[] visited = new boolean[n];
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (visited[i]) {
break;
}
if (visited[j]) {
continue;
}
if (nums[i] + nums[j] == target) {
ans.add(Arrays.asList(nums[i], nums[j]));
visited[i] = true;
visited[j] = true;
}
}
}
return ans;
}解析:个人实现,暴力破解,无法通过,复杂度太高
//个人实现,实现方式比较憨,效率也不高,建议不看
public List<List<Integer>> pairSums(int[] nums, int target) {
List<List<Integer>> ans = new ArrayList<>();
if (nums == null || nums.length == 0) {
return ans;
}
Map<Integer, Integer> map = new HashMap<>();
for (int num : nums) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
Map<Integer, Boolean> map1 = new HashMap<>();
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
if (map1.getOrDefault(entry.getKey(), false) || map1.getOrDefault(target - entry.getKey(), false)) {
continue;
}
int num1 = entry.getValue();
if (map.containsKey(target - entry.getKey())) {
int num2 = map.get(target - entry.getKey());
if (entry.getKey() == (target - entry.getKey()) && entry.getValue() == 1) {
continue;
}
int n = Math.min(num1, num2);
if (entry.getKey() == target - entry.getKey()) {
n = n / 2;
}
for (int i = 0; i < n; i++) {
ans.add(Arrays.asList(entry.getKey(), target - entry.getKey()));
}
map1.put(entry.getKey(), true);
map1.put(target - entry.getKey(), true);
}
}
return ans;
}解析:个人实现,方式比较憨,不建议看
//哈希表
public List<List<Integer>> pairSums(int[] nums, int target) {
List<List<Integer>> ans = new ArrayList<>();
if (nums == null || nums.length == 0) {
return ans;
}
Map<Integer, Integer> map = new HashMap<>();
for (int num : nums) {
int count = map.getOrDefault(target - num, 0);
if (count != 0) {
ans.add(Arrays.asList(num, target - num));
if (count == 1) {
map.remove(target - num);
} else {
map.put(target - num, --count);
}
} else {
map.put(num, map.getOrDefault(num, 0) + 1);
}
}
return ans;
}解析:创建一个map集合
如果存在符合条件的一个元素,则删除
如果多个,减去一个
//双指针实现
public List<List<Integer>> pairSums(int[] nums, int target) {
List<List<Integer>> ans = new ArrayList<>();
Arrays.sort(nums);
int left = 0, right = nums.length - 1;
while (left < right) {
if (nums[left] + nums[right] == target) {
ans.add(Arrays.asList(nums[left], nums[right]));
left++;
right--;
} else if (nums[left] + nums[right] < target) {
left++;
} else {
right--;
}
}
return ans;
}解析:先对数组进行排序
使用双指针向中间查找
剑指offer
剑指 Offer 48. 最长不含重复字符的子字符串 中等
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew" 输出: 3 解释: 因为无重复字符的最长子串是"wke",所以其长度为 3。 请注意,你的答案必须是 子串 的长度,"pwke"是一个子序列,不是子串。
提示:
s.length <= 40000
注意:本题与主站 3 题相同:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/
public int lengthOfLongestSubstring(String s) {
Set<Character> set = new HashSet<>();
int ans = 0, l = 0;
for (int r = 0; r < s.length(); r++) {
while (set.contains(s.charAt(r))) {
set.remove(s.charAt(l++));
}
set.add(s.charAt(r));
ans = Math.max(ans, set.size());
}
return ans;
}解析:不断向集合中添加和删除元素