题面
题解
1.对于此题,我们可以用二维字符串哈希来做,我们可以在nm的矩阵中枚举出所有ab矩阵的hash值,然后对于q次询问,只需要判断给出的a*b矩阵的hash值是否在枚举的集合中即可
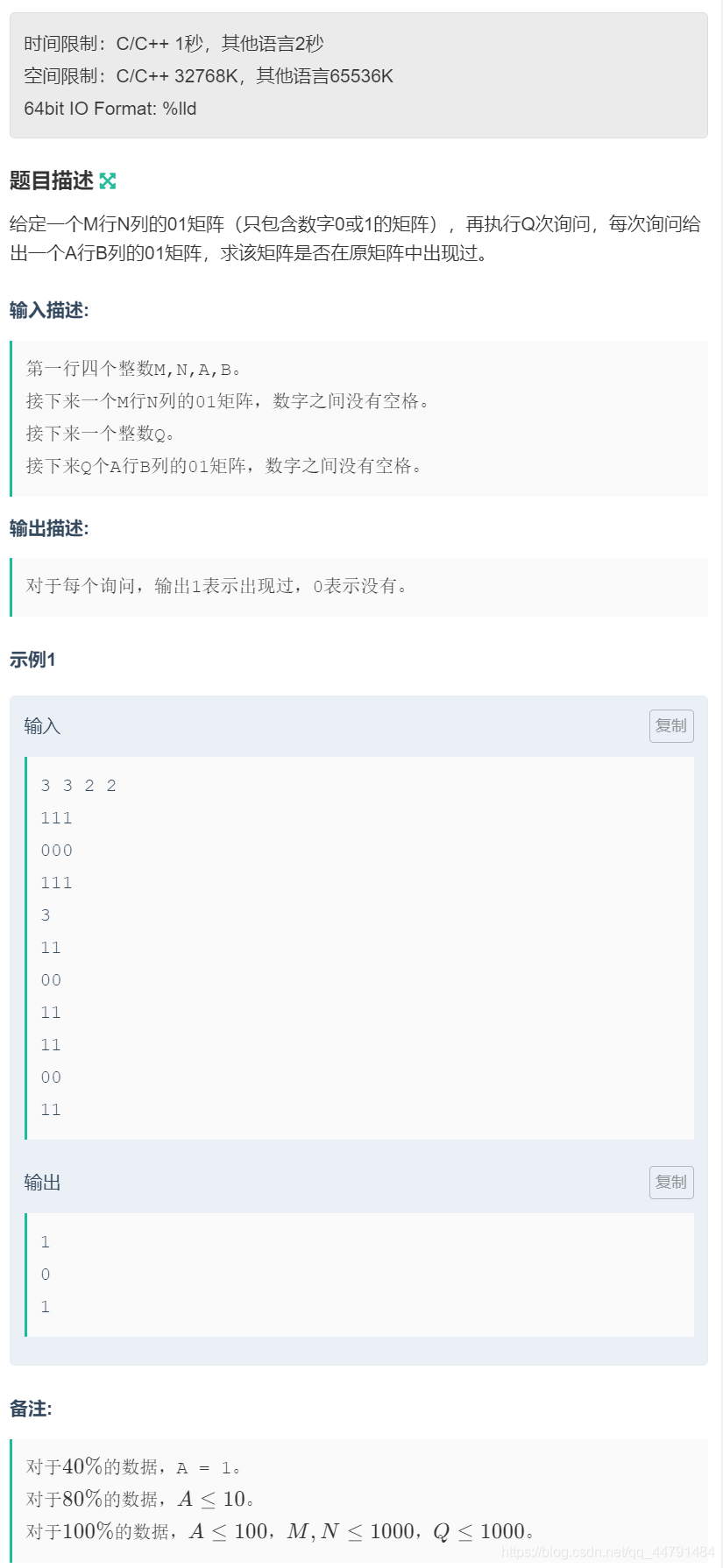
2. 类比一维hash,我们推出二维hash,如图所示
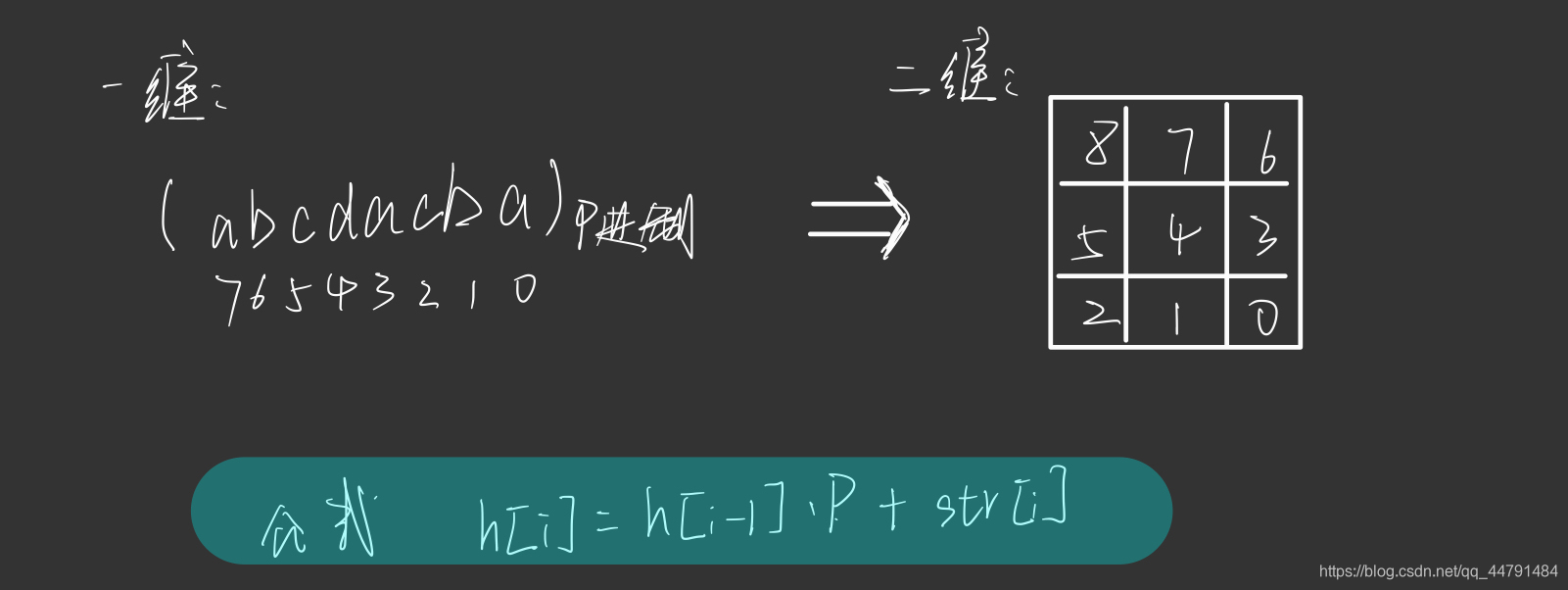
3.如何枚举n*m的矩阵中枚举出所有a * b矩阵的hash值 ,我们可以从左到右枚举列,固定为b列,然后开始枚举,如图所以(假设是5 * 6的矩阵,枚举3 * 3的矩阵)蓝-红-绿-紫。对于大矩阵,我们提前预处理出每一行的hash值(一维hash),然后枚举小矩阵的时候,我们可以将其看成一个整体,相当于抽象成为列的hash,我们每次向下移动一个,蓝–>红的过程,就是将第一行hash删除,加上第四行的hash蓝矩阵的hash就变成了红矩阵的hash
4.最后还有一个优化,否则会爆空间,就是我们可以先将询问所得的hash值算出放入枚举集合中,然后再进行枚举,删除集合中枚举的值,最后询问如果集合中存在小矩阵的hash,输出0,这样set集合中就是少很多元素。
代码
#include<iostream>
#include<cstdio>
#include<string>
#include<cstring>
#include<algorithm>
#include<unordered_set>
#include<vector>
using namespace std;
typedef unsigned long long ULL;
const int N = 1010, M = N * N;
const int P = 131;
int n, m, a, b, q;
ULL h[N][N], p[M];
char str[N];
ULL get(ULL f[], int l, int r) {
return f[r] - f[l - 1] * p[r - l + 1];
}
int main() {
cin >> n >> m >> a >> b;
p[0] = 1;
for (int i = 1; i <= n * m; i++) p[i] = p[i - 1] * P;
for (int i = 1; i <= n; i++) {
cin >> str + 1;
for (int j = 1; j <= m; j++) {
h[i][j] = h[i][j - 1] * P + str[j];
}
}
unordered_set<ULL> S;
vector<ULL> v;
cin >> q;
while (q--) {
ULL s = 0;
for (int i = 1; i <= a; i++) {
cin >> str + 1;
for (int j = 1; j <= b; j++) {
s = s * P + str[j];
}
}
S.insert(s);
v.push_back(s);
}
for (int i = b; i <= m; i++) {
ULL s = 0;
int l = i - b + 1, r = i;
for (int j = 1; j <= n; j++) {
// 获取从 a 行 移到 a + 1 行的hash 值
// s * p^b + hash(a + 1)
// s * p^b 是因为 s 保存的是上一行求到的值,它要向下移,就相当于将上一行和当前行分别看做一个整体,进制为 p^b
// + hash(a + 1) 表示将当前行的 hash 值加上
s = s * p[b] + get(h[j], l, r);
// 将当前以第 a + 1 行为底矩阵的 hash 值 - 以第 a 行为底矩阵第一行的 hash 值(位数差为p^a*b)
if (j > a) s -= get(h[j - a], l, r) * p[a * b];
if (j >= a) S.erase(s);
}
}
for (auto x:v) {
if (S.count(x)) {
cout << 0 << endl;
} else {
cout << 1 << endl;
}
}
return 0;
}