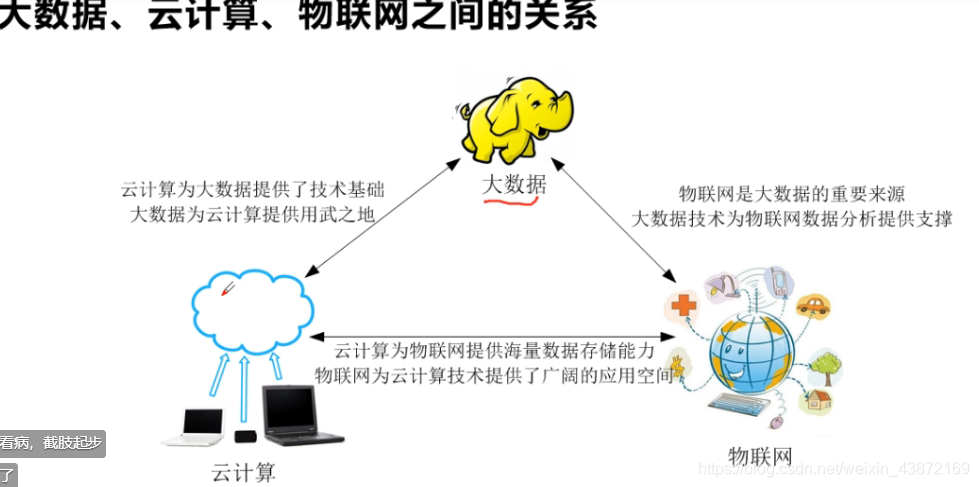
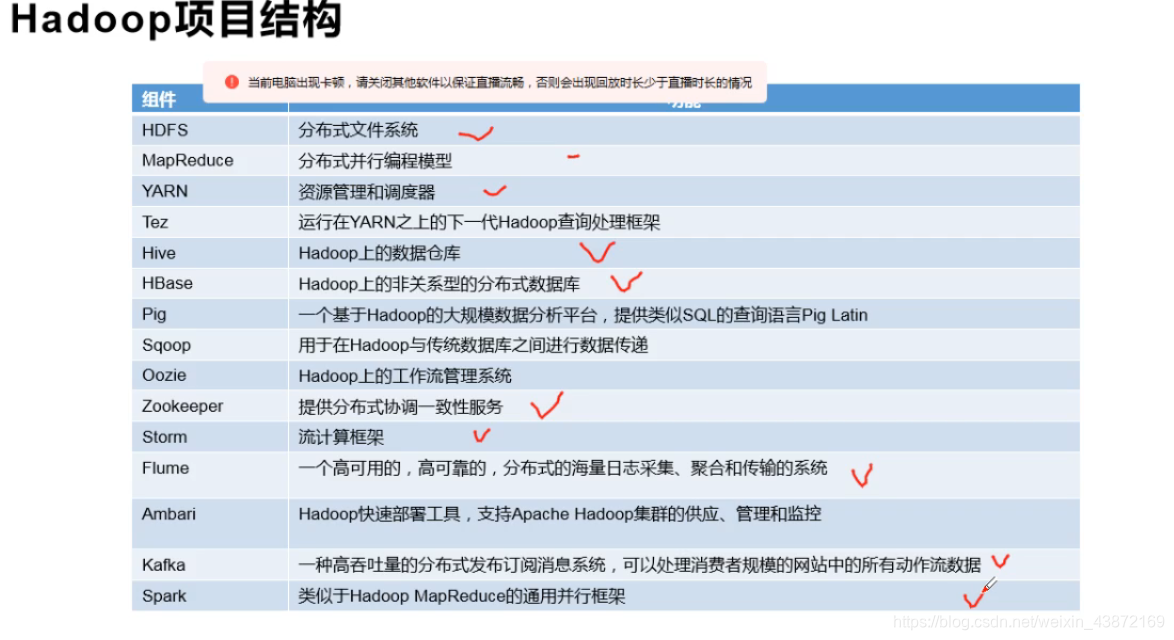
一 大数据概论
众所周知。大数据技术在如今社会应用越来越广泛,如百度搜索的东西,给你推荐你所搜索的东西,如淘宝你平时的浏览的东西,淘宝自动会推给你各种你所浏览的东西。科学数据,金融数据,零售数据,社交网络数据,交通数据,物联网数据,政务大数据,医疗大数据等等等等。
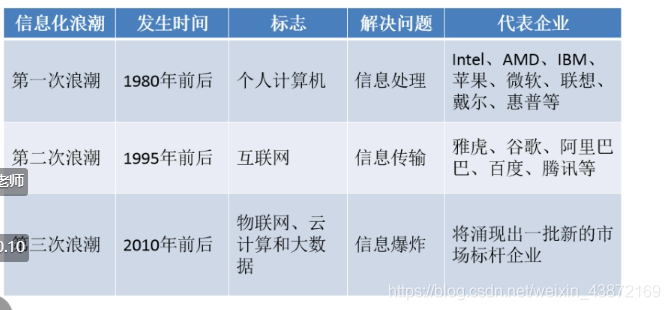
当前处于第二阶段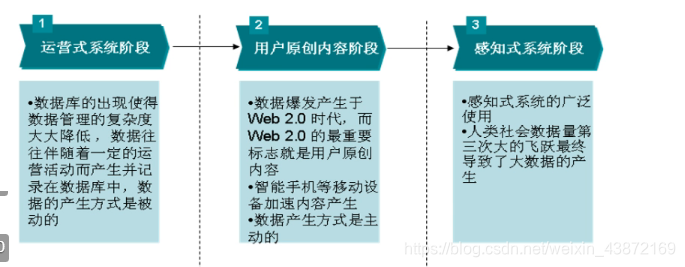
大数据基本概念之大数据定义(4V特征)
4V包括四个层面:数据量大(volume)数据类型繁多(variety)
处理速度快(velocity)价值密度低(value)
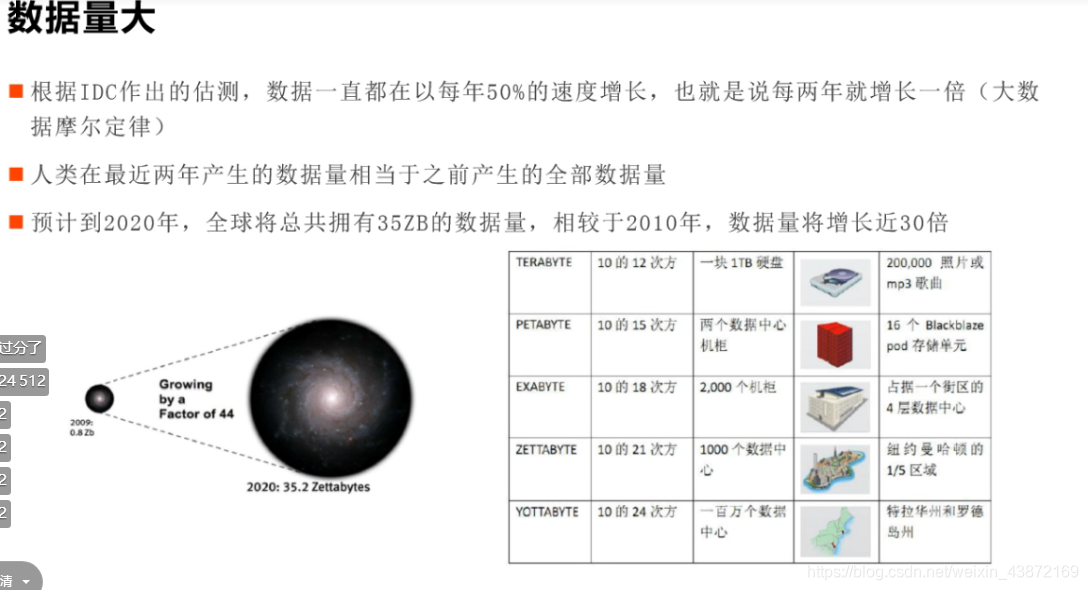
数据量:
大数据涉及的技术:1.数据采集 2. 数据存储 3. 数据处理/分析/挖掘 4.可视化
二 初识Hadoop
Hadoop概述
开源的

Hadoop可以搭建大型数据仓库,PB级数据的存储,处理,分析,统计等业务
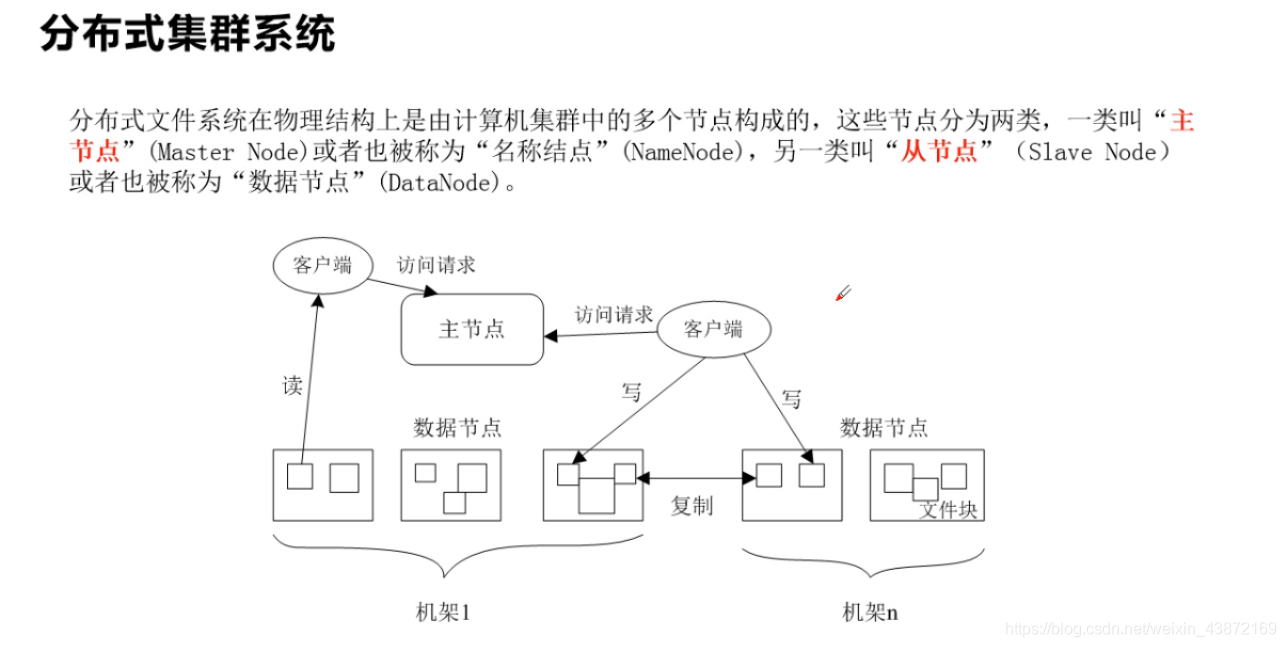
分布式集群:多台计算机构成
主节点就是管理从节点位置的计算机(图书管理员)
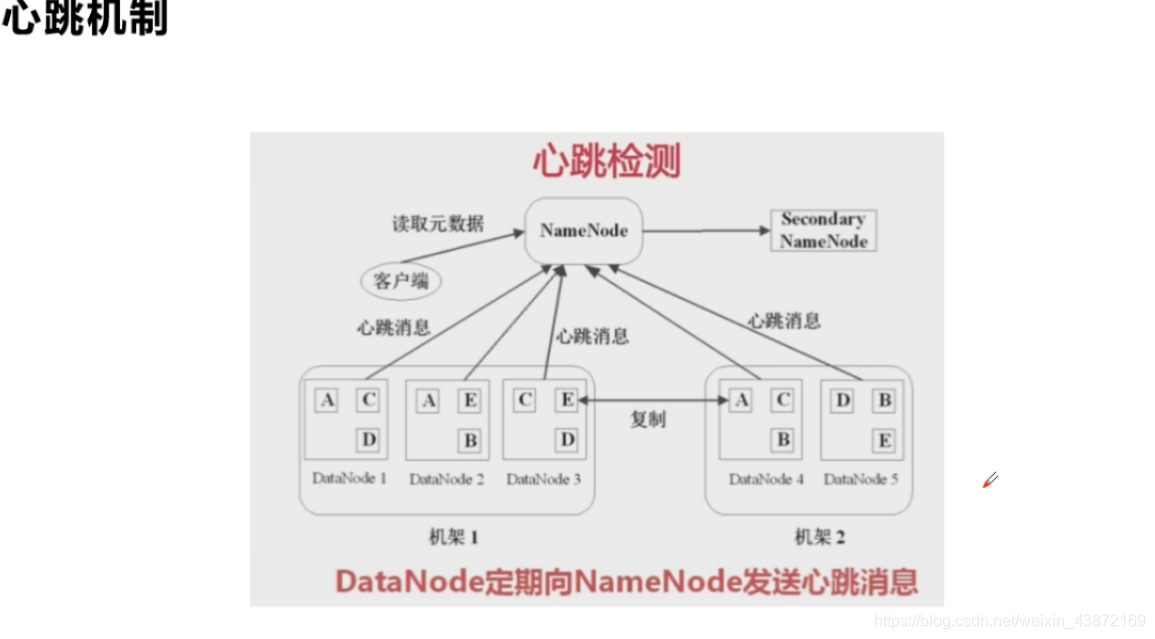
心跳机制:
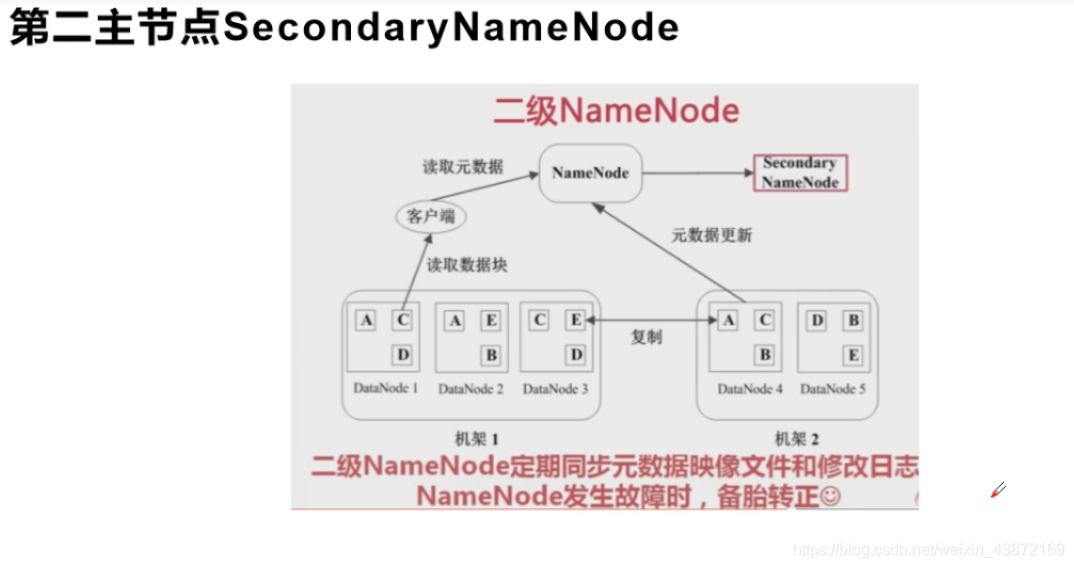
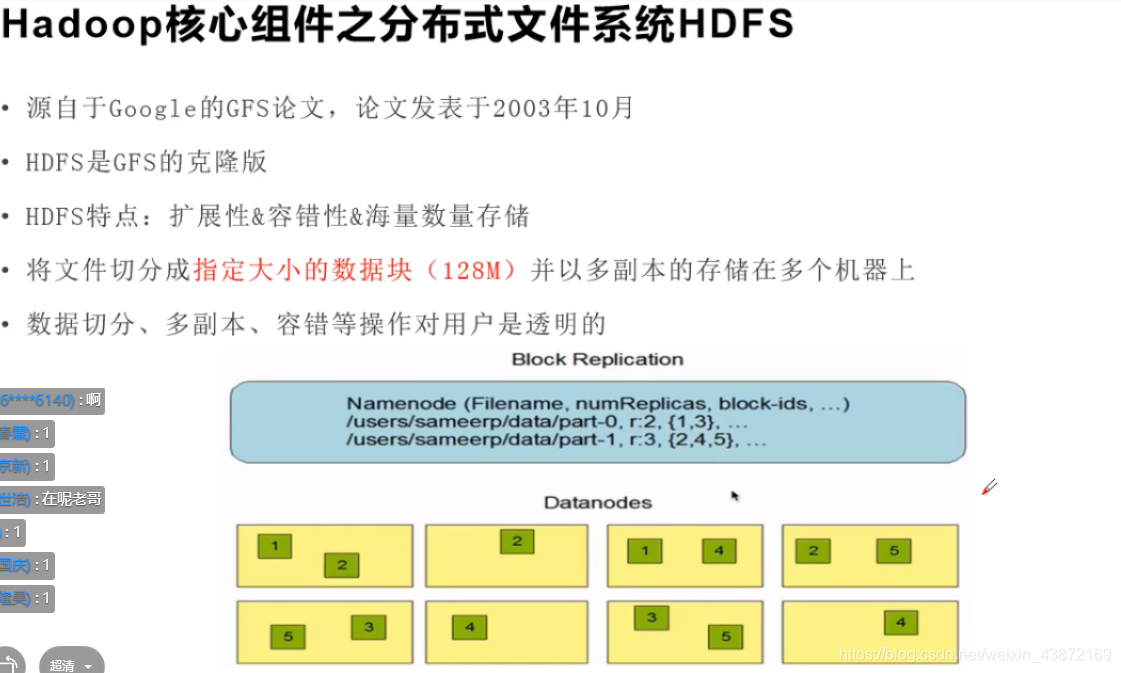
Hadoop三大核心组件:
HDFS(分布式文件系统) YARN(资源调度系统)MapReduce(分布式计算框架)
HDFS可以将数据多副本存储,这样的好处1.如果一台机器上的一个副本坏了,其他机器也可以有该数据的副本 2. 由于一个文件可以切分为多个副本存储在多个计算机中,所以只需要几台计算机就可以算出整个文件。
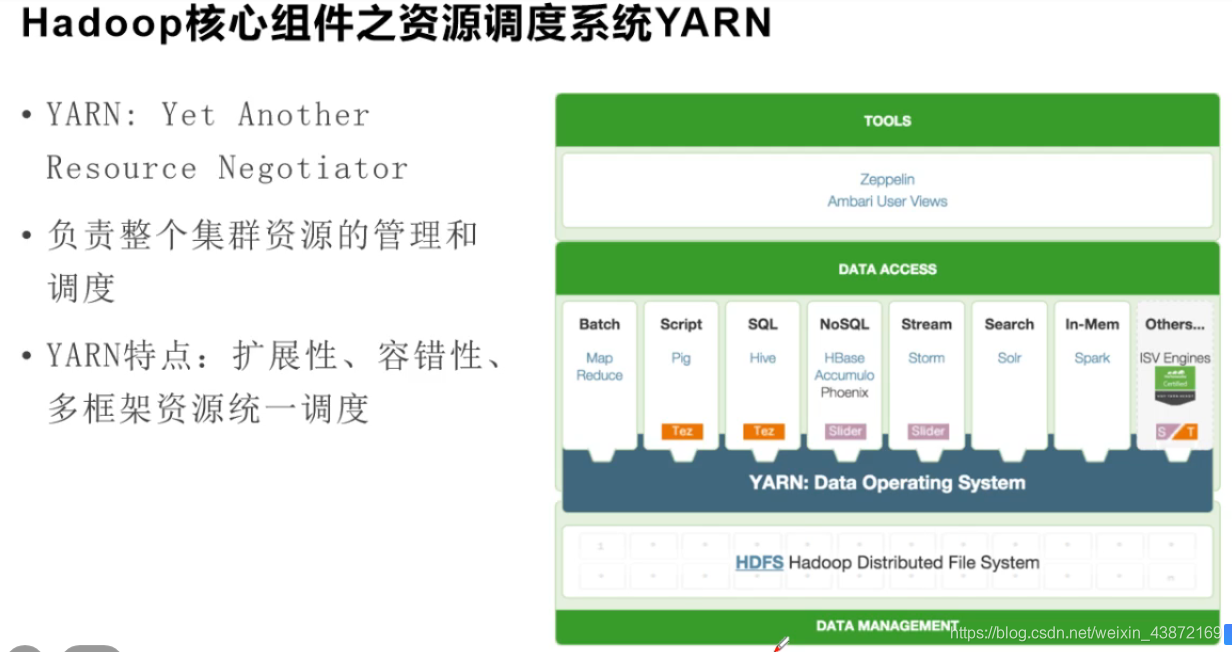
YARN 特点:扩展性,容错性,多框架资源统一调度
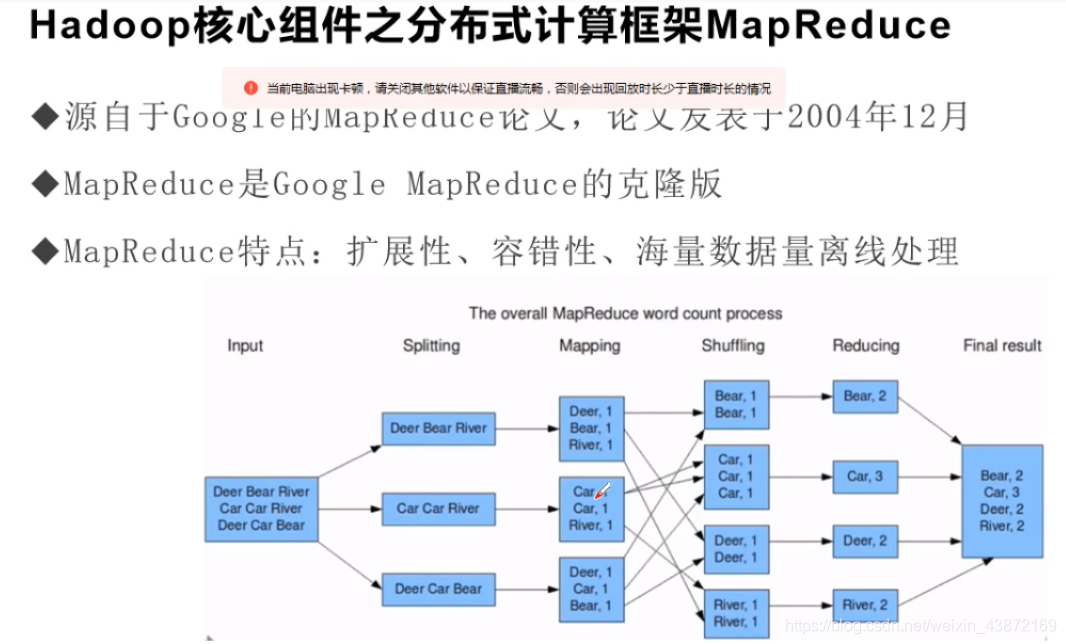
MapReduce框架
特点:扩展性,容错性,海量数据量离线处理。
例子如下图蓝色部分:将所有单词集合在一快,然后将每一排单词放在不同的三个机器中,然后将每台机器中的单词切分,并将切分的单词个数标出来,然后将相同的单词集合起来,将相同单词集合到同一台计算机,然后将单词个数总和起来,然后将每台计算机的单词和个数集合到一台计算机中即完成单词的统计。**



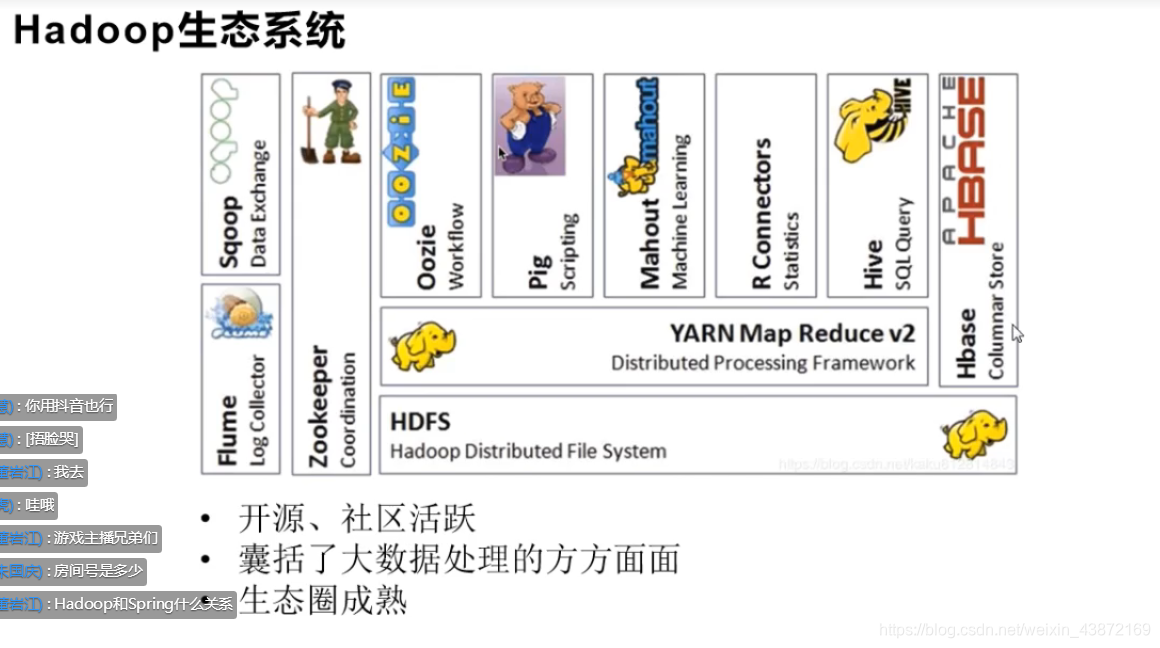
Apache版本不适合开发,适合学习



三 HDFS
1.设计目标
非常大的分布式文件系统,运行在普通廉价的硬件上,易扩展,为用户提供性能不错的文件存储服务
2.HDFS架构
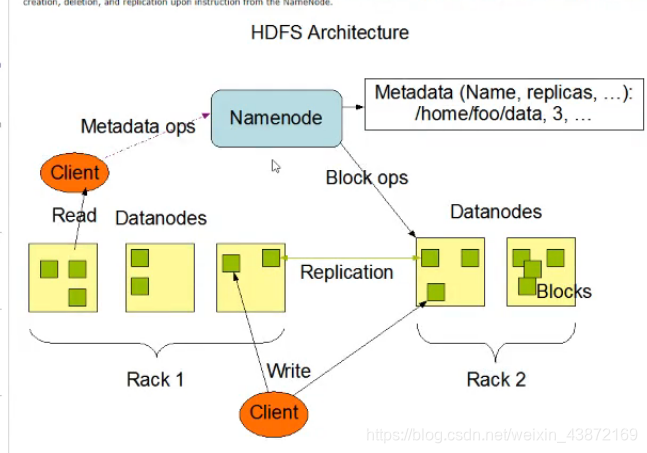
3.副本存放策略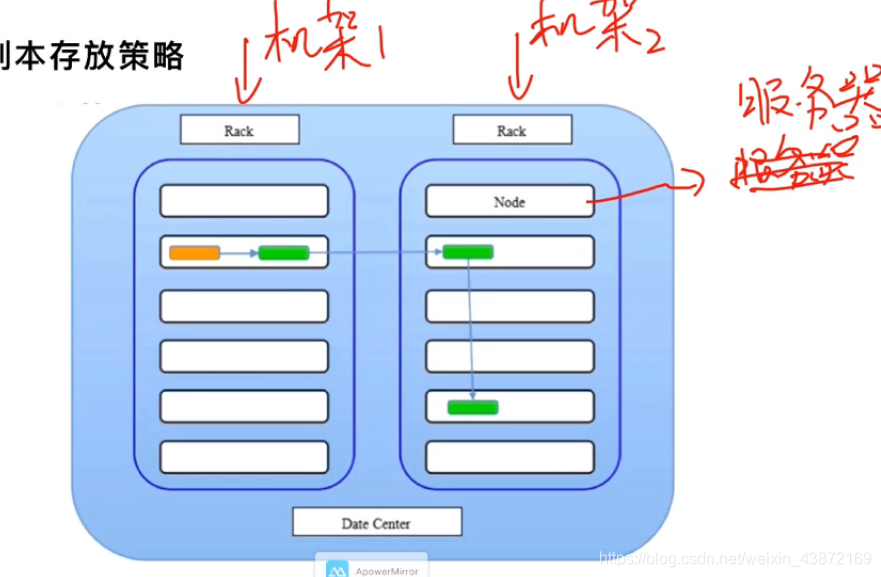
4.HDFS环境搭建

*注:虚拟机中快照是当前虚拟机的状态复制,当操作不当时可以回退。
四 HDFS环境搭建
1.jdk的安装(装java)
-
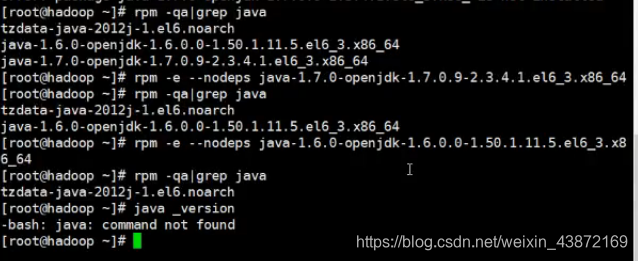
检查自带jdk,有就卸载
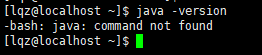
找jdk:rpm -qa|grep java
切换命令 :su -root
删除jdk:rpm -e --nodeps 名字
-
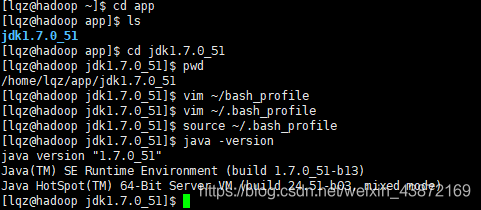
安装jdk
解压: tar -zxvf jdk名字 ~C 解压的位置

配置环境变量:vim ~/.bash_profile
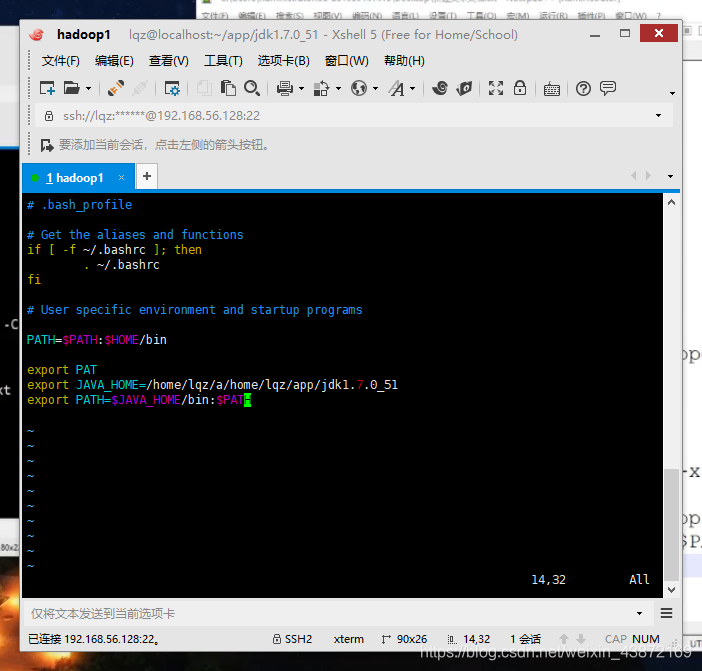
配置完重启这个文件使配置文件生效:source ~/.bash_profile
检验下:java -version
2 安装SSH(实现免密登录)
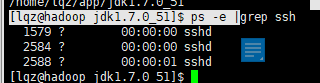
检测有没有ssh:ps -e | grep ssh
-
生成密钥:ssh-keygen -t rsa
(rsa是公钥)
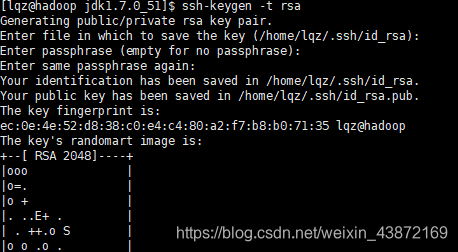
pub是公钥 -
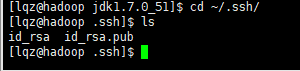
生成的密钥拷贝到特定的文件夹下

密钥如下:
-
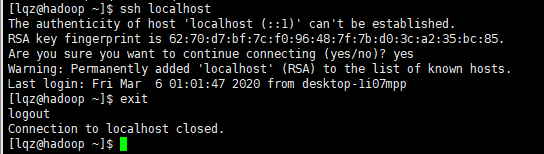
测试下连通性:ssh 主机名/ip地址
连接本地,然后exit退出
ifconfig可以查出ip地址,用ssh localhost和ssh ip地址一样
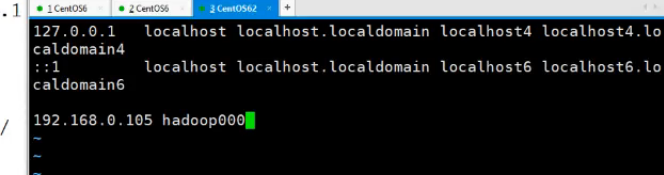
修改地址和主机名的映射:vim /etc/hosts
(用root用户)
查看修改主机名:
3.安装HDFS(hadoop)
-
解压 和上面一样tar -zxvf hadoop名字 ~C 解压的位置
bin里面装的客户端命令集
cmd是windows系统用的

可以删掉cmd
sbin是HDFS系统的命令
hadoop的配置文件

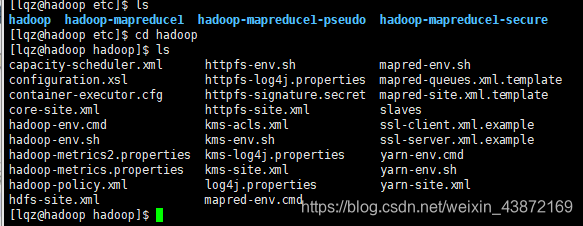
- 配置hadoop文件
三个文件
第一个

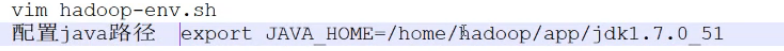
原来的文件如下
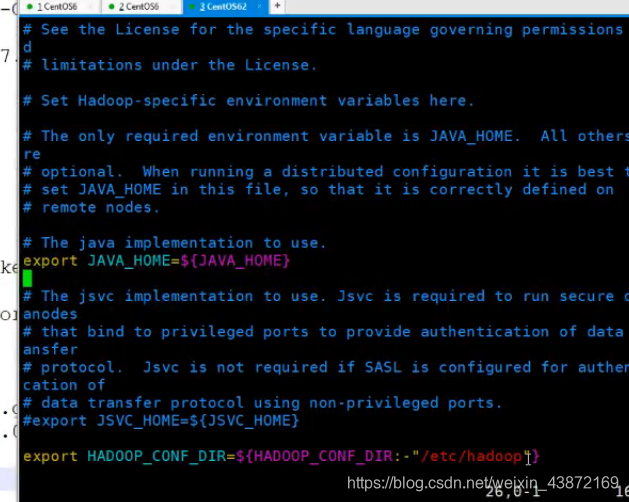
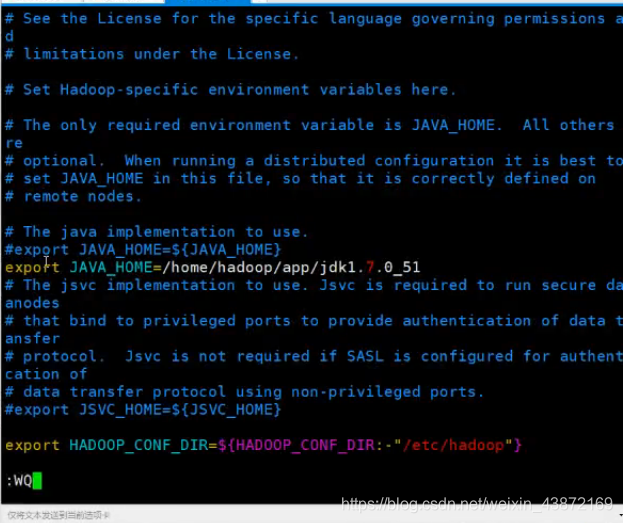
更改为:追加一个java文件变量
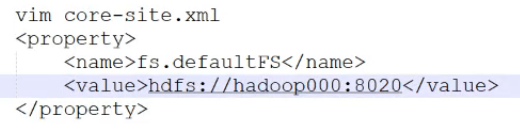
第二个:core-site
查找主机名
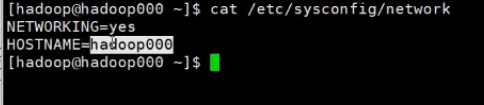
8020前面是主机名
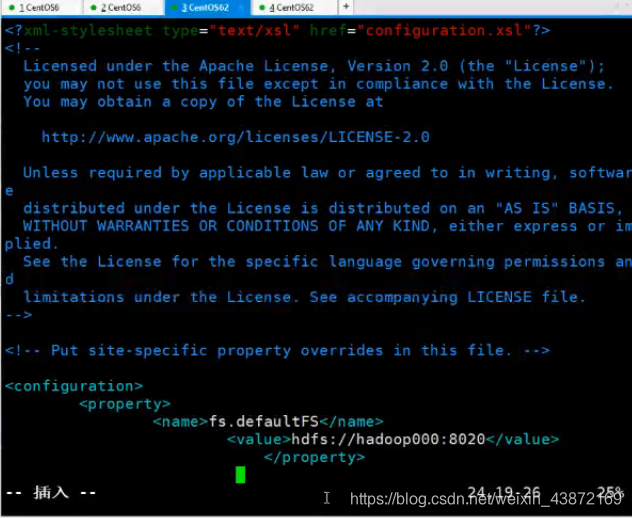
配置个临时文件夹存放hdfs的,在第二个上面(官网上有)

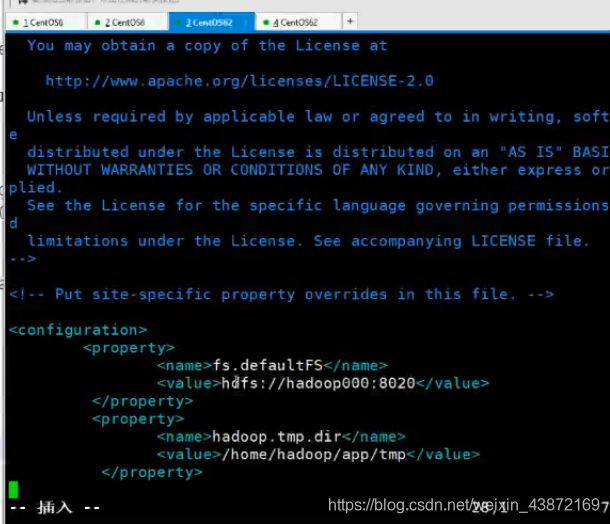
第三个:系统中的一些配置
只有1个副本,一个节点

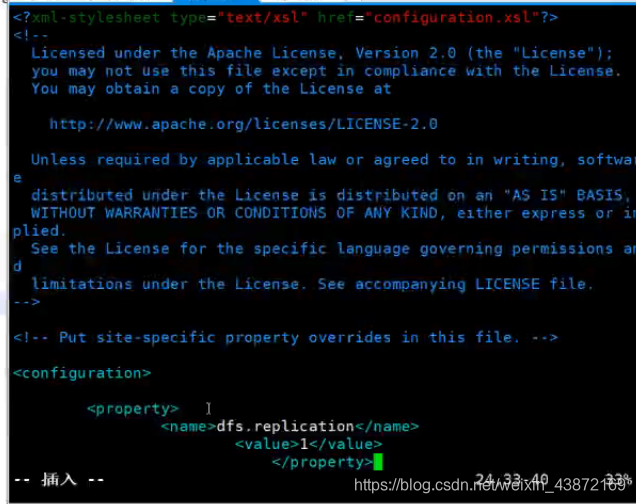
第四个 localhost变成本机名

4.启动hdfs
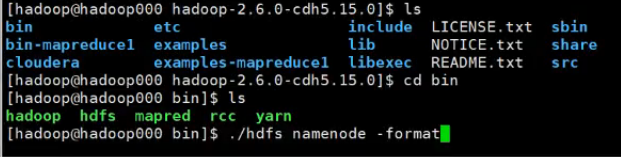
格式换系统(仅第一次执行)
之前tmp没有文件。格式化后就有了tmp下有dfs
bin目录下 ./hdfs namenode -format
启动hdfs命令
在sbin下启动 ./start-dfs.sh
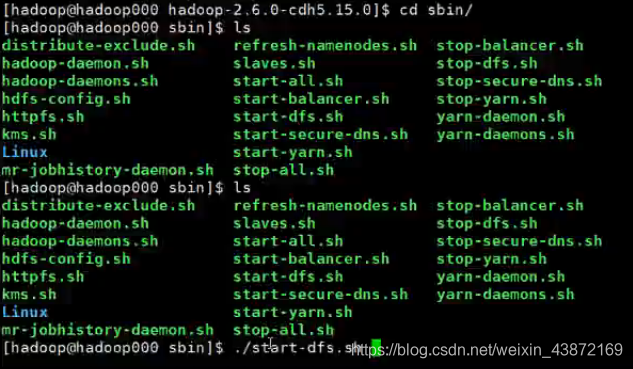
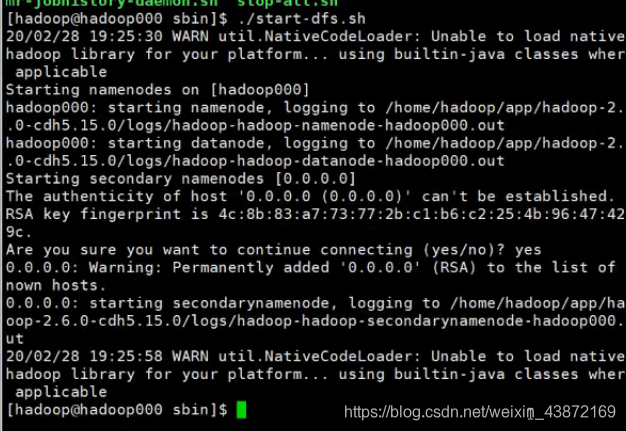
验证命令
1.jps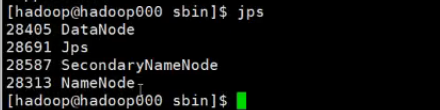
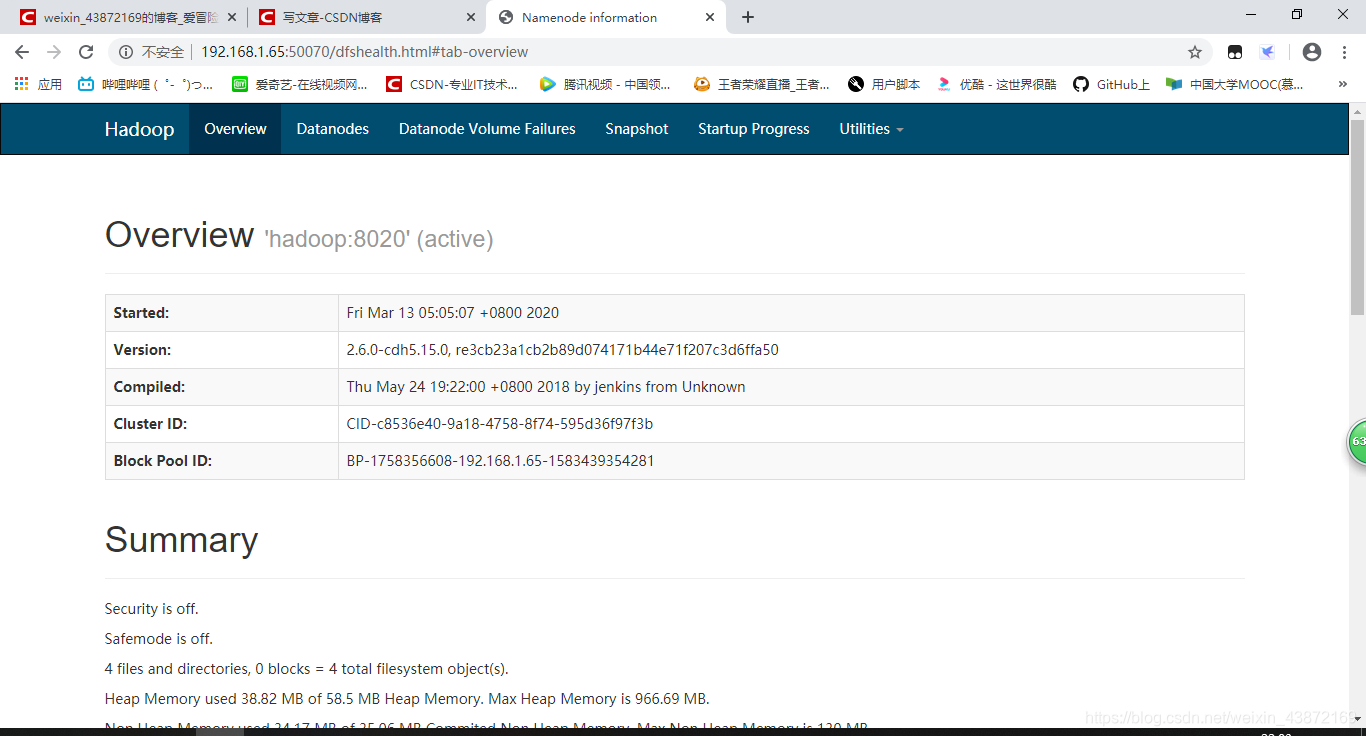
2.网站验证
在虚拟机里的网页看
ip:50070
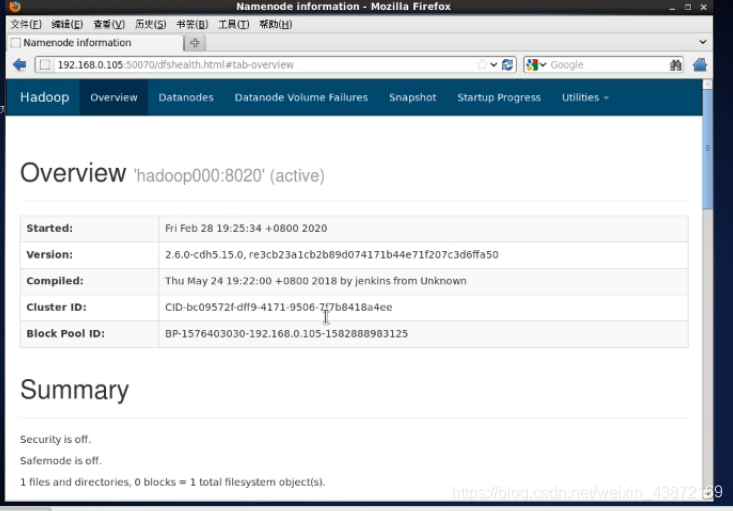

在本机电脑看,
1要关闭防火墙chkconfig iptables off
2要关闭防火墙服务service iptables stop