词向量
为什么需要词向量
1.词向量可以大量的预料中拿到一些对知识表达的方式
2.无法直接对文本进行计算,文本是标记性语言,计算机对数字比较敏感,词向量吧文字转成了数值向量
词编码方式
从onehot到语言模型n-gram到TF-IDF的权重到共现矩阵到Word2Vec到Doc2Vec
词编码需要保证词的相似性
如果用one-hot编码我们得不到词于词之间的关系
比如一些近义词向量比较近
所以我们需要如下的表达形式
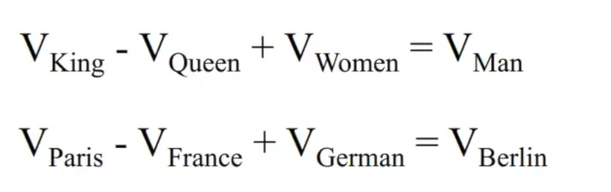

表达足够准确
你的数据决定结果上线
你的算法决定多逼近上线
One-hot表示

每一个单词有唯一索引
词典中的顺序和句子中的顺序无关
词袋

词权重
每个词的重要度都是不一样的

TF:词频,IDF:词的稀有度
语言模型
离散表示

词表维度随着语料库增长膨胀
n-gram词序列随语料库膨胀更快
数据稀疏问题
无法捕捉背景知识
分布式表示
把特征分别抽出来

减少需要记忆的量
进一步
用一个词附件的其他词来表示该词,类似于做英语阅读理解根据上下文猜词意
- 共现矩阵
主要用于发现主题,用于主题模型
可以帮助我们挖掘语法和语义信息
局域窗,一般设为5~10

问题
- 向量维数随着词典大小线性增长
- 存储整个词典的空间消耗非常大
- 一些模型如文本分类模型会面临稀疏性问题
- 模型会欠稳定
构造低维稠密向量作为词的分布式表示 (25~1000维)!
- SVD降维
因为共现矩阵的维度实在太大了,我们想到降维的方式是不是可以减少计算量,那我们试试用SVD来降维
numpy.linalg.svd()
问题:
计算量随语料库和词典增长膨胀太快
难以为词典中新加入的词分配词向量
与其他深度学习模型框架差异大
NNLM(神经网络语言模型)
非对称的前向窗函数
直接从语言模型出发,将模型最优化过程转化为求词向量表示的过程

这里输入是一个onehot比如有5000个词,第一个词输入就是[1,0,0,0,…,0] 1*5000
C刚开始随机赋值
C矩阵的每一列相当于一个词的词向量
比如第一列就是对第一个词的词向量
最后一层全连接
我们需要的是要学出来C矩阵
感觉和SOM网络有点类似需要的都是训练出来的参数
缺点:时间复杂度比较高
需要大量数据和计算,太复杂

word2vec
重头戏来了
CBOW(连续词袋)
NNLM毕竟是一个神经网络,最后一层是一个个词向量的拼接和输出层的全连接的softmax,计算量太大了

这里把隐层拿掉了
拼接改为求和
问题
输出层太多了
如果输出层是10W,投射层是500的话,最后一层就是10W*500的全连接,这里计算量还是太大了,这里有两个解决方法
- 层次softmax

使用huffman数来编码输出层的词典,根据词频来建立huffman树
用层级的来表示平铺的
- 负例采样
调出一个负样本的子集

用词频做分段
然后根据分段随机取值
Skip-Gram

和CBOW相反
缺点
对每个local context window单独训练,没有利用包 含在global co-currence矩阵中的统计信息
解决方法:glove
对多义词无法很好的表示和处理,因为使用了唯一 的词向量 ,相当于做了平滑,比如苹果水果和苹果手机中的苹果在词向量中都被表达成了一个意思
解决方法:sense2vec
总结
- 离散表示
One-hot representation, Bag Of Words Unigram语言模型
N-gram词向量表示和语言模型
Co-currence矩阵的行(列)向量作为词向量 - 分布式连续表示
Co-currence矩阵的SVD降维的低维词向量表示
Word2Vec: Continuous Bag of Words Model
Word2Vec: Skip-Gram Model
NLP应用

python代码
代码我放在下一篇博客里边了
https://editor.csdn.net/md/?articleId=107113951
词向量训练