分类目录:《自然语言处理从入门到应用》总目录
对于给定的一段输入文本 w 1 w 2 ⋯ w n w_1w_2\cdots w_n w1w2⋯wn,双向语言模型从前向(从左到右)和后向(从右到左)两个方向同时建立语言模型。这样做的好处在于,对于文本中任一时刻的词 w t w_t wt,可以同时获得其分别基于左侧上下文信息和右侧上下文信息的表示。具体地,模型首先对每个词单独编码。这一过程是上下文无关的,主要利用了词内部的字符序列信息。基于编码后的词表示序列,模型使用两个不同方向的多层长短时记忆网络(LSTM)分别计算每一时刻词的前向、后向隐含层表示,也就是上下文相关的词向量表示。利用该表示,模型预测每一时刻的目标词。对于前向语言模型, t t t时刻的目标词是 w t + 1 w_{t+1} wt+1,对于后向语言模型,目标词是 w t − 1 w_{t-1} wt−1。
输入表示层
ELMo模型采用基于字符组合的神经网络表示输入文本中的每个词,目的是减小未登录词(Out-Of-Vocabulary,OOV)对模型的影响。下图展示了输入表示层的基本结构。首先,字符向量层将输入层中的每个字符(含额外添加的起止符)转换为向量表示。假设 w t w_t wt由字符序列 c 1 c 2 ⋯ c l c_1c_2\cdots c_l c1c2⋯cl构成,对于其中的每个字符 c i c_i ci,可以表示为: v c i = E char e c i v_{c_i}=E^{\text{char}}e_{c_i} vci=Echareci。其中, E char ∈ R d char × ∣ V char ∣ E^{\text{char}}\in R^{d^{\text{char}}\times |V^{\text{char}}|} Echar∈Rdchar×∣Vchar∣表示字符向量矩阵; V char V^{\text{char}} Vchar表示所有字符集合; d char d^{\text{char}} dchar表示字符向量维度; e c i e_{c_i} eci表示字符 c i c_i ci的独热编码。记 w t w_t wt中所有字符向量组成的矩阵为 C t ∈ R d char × l C_t\in R^{d^{\text{char}}\times l} Ct∈Rdchar×l,即 C t = [ v c 1 , v c 2 , ⋯ , v c l ] C_t=[v_{c_1}, v_{c_2}, \cdots, v_{c_l}] Ct=[vc1,vc2,⋯,vcl]。接下来,利用卷积神经网络对字符级向量表示序列进行语义组合(Semantic Composition)。这里使用一维卷积神经网络,将字符向量的维度 d char d^{\text{char}} dchar作为输入通道的个数,记为 N in N^{\text{in}} Nin,输出向量的维度作为输出通道的个数,记为 N out N^{\text{out}} Nout。另外,通过使用多个不同大小(宽度)的卷积核,可以利用不同粒度的字符级上下文信息,并得到相应的隐含层向量表示,这些隐含层向量的维度由每个卷积核对应的输出通道个数确定。拼接这些向量,就得到了每一位置的卷积输出。然后,池化操作隐含层所有位置的输出向量,就可以得到对于词 w t w_t wt的定长向量表示,记为 f t f_t ft。假设使用宽度分别为{1,2,3,4,5,6,7}的7个一维卷积核,对应的输出通道数量分别为{32,32,64,128,256,512,1024},那么输出向量 f t f_t ft的维度为2048。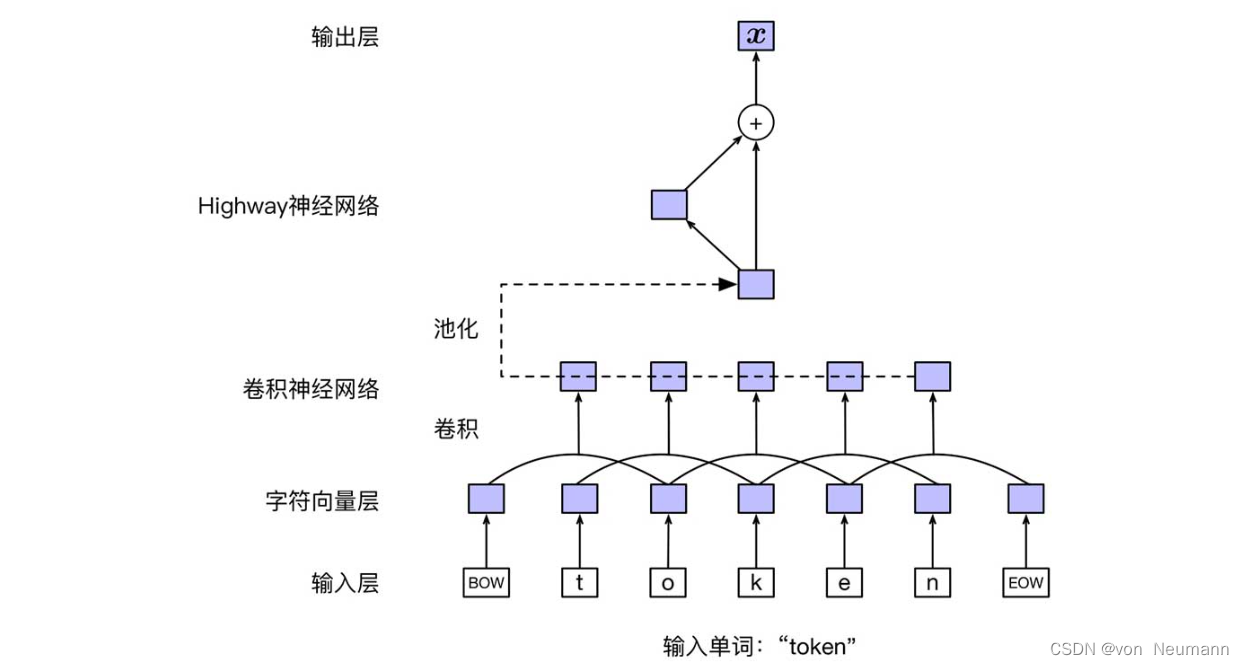 接着,模型使用两层Highway神经网络对卷积神经网络输出作进一步变换,得到最终的词向量表示 x t x_t xt。Highway神经网络在输入与输出之间直接建立“通道”,使得输出层可以直接将梯度回传至输入层,从而避免因网络层数过多而带来的梯度爆炸或弥散的问题。单层Highway神经网络的具体计算方式如下:
接着,模型使用两层Highway神经网络对卷积神经网络输出作进一步变换,得到最终的词向量表示 x t x_t xt。Highway神经网络在输入与输出之间直接建立“通道”,使得输出层可以直接将梯度回传至输入层,从而避免因网络层数过多而带来的梯度爆炸或弥散的问题。单层Highway神经网络的具体计算方式如下:
x t = g ⊙ f t + ( 1 − g ) ⊙ ReLU ( W f t + b ) x_t=g\odot f_t+(1 - g)\odot\text{ReLU}(Wf_t+b) xt=g⊙ft+(1−g)⊙ReLU(Wft+b)
式中, g g g为门控向量,其以 f t f_t ft为输入,经线性变换后通过Sigmoid函数计算得到:
g = σ ( W g f t + b g ) g=\sigma(W^gf_t+b^g) g=σ(Wgft+bg)
式中, W g W^g Wg与 b g b^g bg为门控网络中的线性变换矩阵与偏置向量。可见,Highway神经网络的输出实际上是输入层与隐含层的线性插值结果。当然,通常模型的结构是根据实验调整和确定的,我们也可以自行尝试其他的模型结构。例如,可以使用字符级双向LSTM网络编码单词内字符串序列。接下来,在由上述过程得到的上下文无关词向量的基础之上,利用双向语言模型分别编码前向与后向上下文信息,从而得到每一时刻的动态词向量表示。
前向语言模型
在前向语言模型中,对于任一时刻目标词的预测,都只依赖于该时刻左侧的上下文信息或者历史。这里使用基于多层堆叠的长短时记忆网络语言模型。将模型中多层堆叠LSTM的参数记为 θ → LSTM \overrightarrow{\theta}^\text{LSTM} θLSTM,Softmax输出层参数记为 θ out \theta^\text{out} θout。则模型可以表示为:
p ( w 1 w 2 ⋯ w n ) = ∏ t = 1 n P ( w t ∣ x 1 : t − 1 ; θ → LSTM ; θ out ) p(w_1w_2\cdots w_n)=\prod_{t=1}^nP(w_t|x_{1:t-1}; \overrightarrow{\theta}^\text{LSTM}; \theta^\text{out}) p(w1w2⋯wn)=t=1∏nP(wt∣x1:t−1;θLSTM;θout)
后向语言模型
与前向语言模型相反,后向语言模型只考虑某一时刻右侧的上下文信息。可以表示为:
p ( w 1 w 2 ⋯ w n ) = ∏ t = 1 n P ( w t ∣ x t + 1 : n ; θ ← LSTM ; θ out ) p(w_1w_2\cdots w_n)=\prod_{t=1}^nP(w_t|x_{t+1:n}; \overleftarrow{\theta}^\text{LSTM}; \theta^\text{out}) p(w1w2⋯wn)=t=1∏nP(wt∣xt+1:n;θLSTM;θout)
参考文献:
[1] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[2] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[3] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[4] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[5] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.