分类目录:《自然语言处理从入门到应用》总目录
对于不同的学习方法得到的词向量,通常可以根据其对词义相关性或者类比推理性的表达能力进行评价,这种方式属于内部任务评价方法(Intrinsic Evaluation)。在实际任务中,则需要根据下游任务的性能指标判断,也称为外部任务评价方法(Extrinsic Evaluation)。本文首先介绍两种常用的内部任务评价方法,然后以情感分类任务为例,介绍如何将预训练词向量应用于下游任务。
词义相关性
对词义相关性的度量是词向量的重要性质之一。可以根据词向量对词义相关性的表达能力衡量词向量的好坏。利用词向量低维、稠密、连续的特性,可以方便地度量任意两个词之间的相关性。例如,给定词 w a w_a wa与 w b w_b wb,它们在词向量空间内的余弦相似度就可以作为其词义相关性的度量:
sim ( w a , w b ) = cos ( v w a , v w b ) = v w a × v w b ∣ ∣ v w a ∣ ∣ × ∣ ∣ v w b ∣ ∣ \text{sim}(w_a, w_b)=\cos(v_{w_a}, v_{w_b})=\frac{v_{w_a}\times v_{w_b}}{||v_{w_a}||\times ||v_{w_b}||} sim(wa,wb)=cos(vwa,vwb)=∣∣vwa∣∣×∣∣vwb∣∣vwa×vwb
基于该相关性度量,即可实现K近邻(K-Nearest Neighbors,KNN)查询。
类比性
词的类比性(Word Analogy)是对于词向量的另一种常用的内部任务评价方法。对词向量在向量空间内的分布进行分析可以发现,对于语法或者语义关系相同的两个词对 [ w a , w b ] [w_a, w_b] [wa,wb]与 [ w c , w d ] [w_c, w_d] [wc,wd],它们的词向量在一定程度上满足: v w a − v w b ≈ v w c − v w d v_{w_a} - v_{w_b}\approx v_{w_c} - v_{w_d} vwa−vwb≈vwc−vwd的几何性质。例如,在下图的示例中有以下类比关系:
v women − v men ≈ v queen − v king v queens − v queen ≈ v kings − v king \begin{aligned} v_{\text{women}} - v_{\text{men}}& \approx v_{\text{queen}} - v_{\text{king}}\\ v_{\text{queens}} - v_{\text{queen}}&\approx v_{\text{kings}} - v_{\text{king}} \end{aligned} vwomen−vmenvqueens−vqueen≈vqueen−vking≈vkings−vking
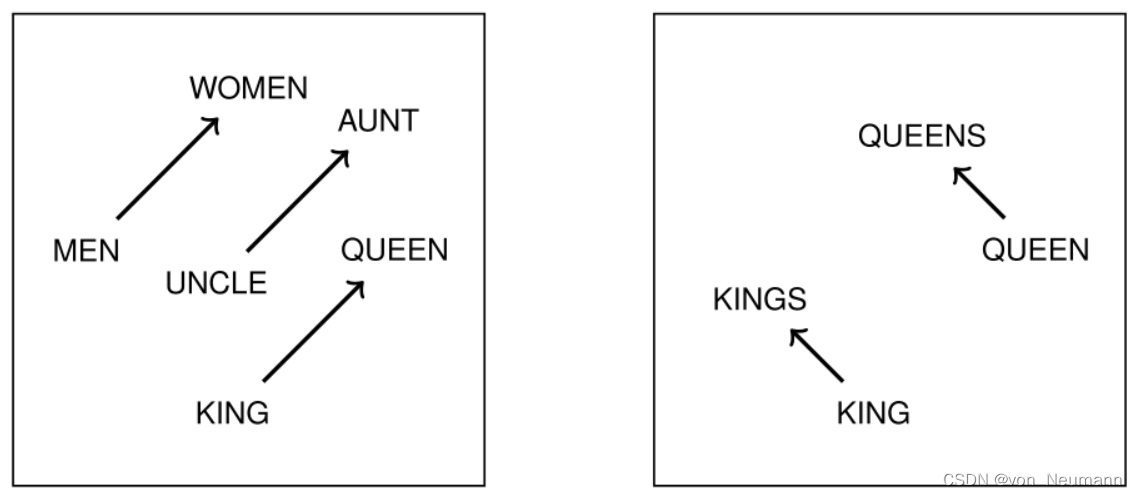
这两个例子分别从词义和词法两个角度展示了词向量的类比性。根据这一性质,可以进行词与词之间的关系推理,从而回答诸如“ w a w_a wa之于 w b w_b wb,相当于 w c w_c wc之于什么”的问题。对于下画线处的词,可以利用下式在词向量空间内进行搜索得到:
w d = arg min w ( cos ( v w , v w c + v w b − v w a ) ) w_d=\arg\min_w(\cos(v_w, v_{w_c} + v_{w_b} - v_{w_a})) wd=argwmin(cos(vw,vwc+vwb−vwa))
一般来说,词向量在以上评价方法中的表现与训练数据的来源及规模、词向量的维度等因素密切相关。在实际应用中,需要根据词向量在具体任务中的表现来选择。
参考文献:
[1] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[2] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[3] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[4] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[5] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.