神经网络语言模型
用句子
S的概率
p(S)来定量刻画句子。
统计语言模型是利用概率统计方法来学习参数
p(wi∣w1…wi−1),神经网络语言模型则通过神经网络学习参数.
统计语言模型的缺点
- 平滑技术错综复杂且需要回退至低阶,使得该模型无法面向更大的n元文法获取更多的词信息.
- 基于最大似然估计的语言模型缺少对上下文的泛化,如观察到蓝汽车和红汽车不会影响出现黑汽车的概率.
神经网络语言模型
根据所用的神经网络不同,可以分为
NNLM
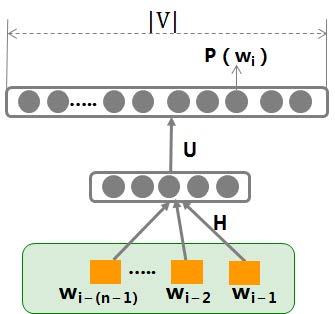
输入:
X:wi−1
输出:
p(wi∣wi−1)
参数:
θ=H,U,b1,b2
运算关系:
p(wi∣wi−1)=∑k=1∣V∣exp(y(vk))exp(y(wi))y(wi)=b2+U(tanh(XH+b1))
目标函数:
采用log损失
L(Y,P(Y∣X))=−logP(Y∣X)
参数训练:
随机梯度下降优化训练目标,每次迭代,随机从语料D选取一段文本
wi−(n−1)…wi作为训练样本进行一次梯度迭代.
θ←θ−α∂θ∂logP(wi∣wi−(n−1)…wi−1)
其中,
α为学习率,
θ={H,U,b1,b2}
RNNLM
输入:
X:wi−1和
h(t−1)
输出:
p(wi∣wi−1)和
h(t)
参数:
θ=H,U,M,b1,b2
运算关系:
p(wi∣wi−1)=∑k=1∣V∣exp(y(vk))exp(y(wi))y(wi)=b2+U(tanh(XH+Mh(t−1)+b1))h(t)=tanh(XH+Mh(t−1)+b1)
目标函数:
采用log损失
L(Y,P(Y∣X))=−logP(Y∣X)
参数训练:
采用随机梯度下降优化训练目标.
θ←θ−α∂θ∂logP(wi∣wi−(n−1)…wi−1)
神经网络词向量
词的表示问题.
离散表示
One-hot
优势:稀疏方式存储非常简洁
不足:词汇鸿沟,维度灾难
词袋模型
每个数表示该词在文档中出现的次数.
TF_IDF
每个数代表该词在整个文档中的占比.
分布式表示
核心思想:用一个词的上下文来表示该词.
NNLM模型-词向量
将输入词向量作为参数在NNLM模型中进行训练
- 优点:
降维,消除词汇鸿沟,自带平滑
- 应用:
同义词检测、单词类比
RNNLM模型-词向量
将输入词向量作为参数在RNNLM模型中进行训练
C&W模型
采用直接对n元短语打分的方式替代语言模型中求解条件概率的方法:对于语料中出现过的短语,打高分;对于未出现的随机短语打低分.
特点:
C&W模型的目标函数是求目标词W与其上下文C的联合打分,而其他模型均是根据上下文C,来预测目标词W.
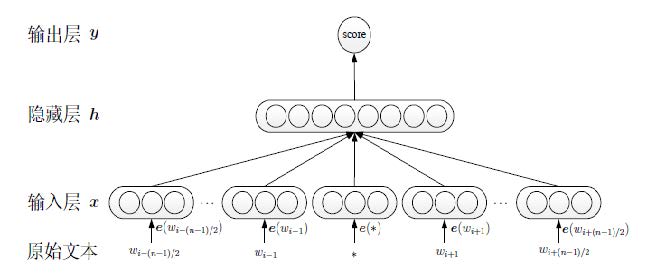
输入:
目标词
wi与其上下文
x=[e(wi−(n−1)),…,e(wi),…,e(wi+(n−1))]
隐藏层:
上下文和目标词的联合表示.
输出:
对输入序列打分
优化目标:
对于整个语料最小化
(w,c)∈D∑w′∈V∑max(0,1−score(w,c)+score(w′,c))
其中,c表示目标词w的上下文
- 正样本来自语料
- 负样本则是将正样本序列中的中间词替换成其他词.
对比:
C&W模型在运算速度上优于NNLM模型,但在许多语言学任务上,效果不如其他模型.
CBOW
(Continuous Bag-of Words),Mikolov等人在2013年提出了CBOW和Skip-gram模型,主要针对NNLM训练复杂度过高的问题进行改进.
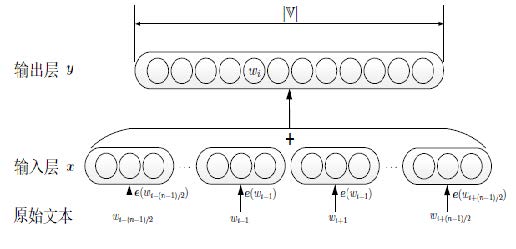
输入层:x:词
wi的上下文词向量平均值,不包括
wi
x=n−11wj∈c∑e(wj)
输出层:
p(wi∣c)=∑w′∈Vexp(e′(w′)Tx)exp(e′(wi)Tx)
优化目标:
最大化
∑(w,c)∈DlogP(w∣c)
参数训练:梯度下降法
Skip-gram
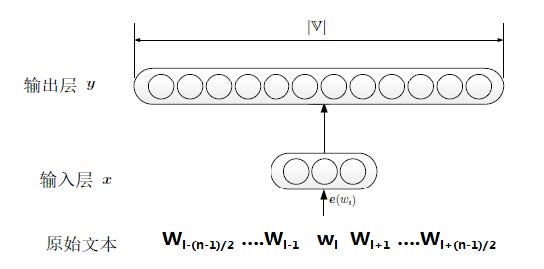
输入层:x:词
wi的词向量
输出层:
p(wj∣wi)=∑w′∈Vexp(e′(w′)Tx)exp(e′(wj)Tx)
优化目标:
最大化
∑(w,c)∈D∑wj∈clogP(wj∣w)
Hierachical softmax思想
对于词典中的任意词w,哈夫曼树中必然存在一条从根节点到该词所在的叶子节点的路径,将路径上存在的所有分支视为一次二分类,将每次分类的概率乘起来,就得到了最终
p(w∣context(w))
词向量工具
word2vec是google开源的将词表征为实数值向量的高校工具,其利用深度学习的思想,可以通过训练,把对词的处理简化为K维向量空间中的向量运算.
word2vec训练得到的词向量可用于机器翻译、相似词查找、关系挖掘、中文聚类等任务中.
word2vec共有两种类型,每种类型都有两个策略.
| 模型 |
CBOW |
CBOW |
Skip-gram |
Skip-gram |
| 方法 |
Hierarchical Softmax |
Negative Sampling |
Hierarchical Softmax |
Negative Sampling |
模型特点
| 模型 |
目标词与上下文位置 |
模型输入 |
模型输出 |
目标词与上下文词之间的关系 |
| NNLM |
(上文)(目标词) |
上文词向量拼接 |
目标词概率 |
上文在输入层、目标词在输出层,优化预测关系 |
| C&W |
(上文)(目标词)(下文) |
上下文及目标词词向量拼接 |
上下文及目标词联合打分 |
上下文和目标词都在输入层,优化组合关系 |
| CBOW |
(上文)(目标词)(下文) |
上下文各词词向量平均值 |
目标词概率 |
上下文在输入层、目标词都在输入层,优化预测关系 |
| Skip-gram |
(上文)(目标词)(下文) |
目标词词向量 |
上下文词概率 |
目标词在输入层、上下文在输出层,优化预测关系 |
不同模型对比
| 指标 |
– |
| 模型复杂度 |
NNLM>C&W>CBOW>Skip-gram |
| 参数个数 |
NNLM>(CBOW=Skip-gram)>C&W |
| 时间复杂度 |
NNLM>(CBOW=Skip-gram)>C&W |
构建词向量建议
- 当语料较小时,应当选用模型结构最简单的Skip-gram模型,当语料较大时,选用CBOW模型会有更好的效果.
- 预测目标词的模型比目标词与上下文呈组合关系的模型(C&W)在多个任务中有更好的性能.
- 训练时迭代优化的终止条件最好根据具体任务的验证集来判断,或近似地选取其它类似的任务作为指标.
- 词向量的维度一般要在50维以上,特别是当衡量词向量的语言学特性时,词向量的维度越大,效果越好.
词向量的用途
- 利用词向量的语言学特性完成任务. 利用词向量语义相似的词,其磁向量空间距离相近的特征可完成语义相关性任务,如同义词检测、单词类比.
- 将词向量作为静态特征输入. 使用词向量作为模型输入,在训练过程中,只调整模型参数,不调整词向量,如基于平均词向量的文本分类、命名实体识别等.
- 将词向量作为动态初值输入. 使用词向量作为神经网络的初始值,模型训练过程中调整词向量的初值,从而提升神经网络模型的优化效果.如基于卷积神经网络的文本分类、词性标注等.
参考资料
中国科学院大学-NLP课程课件(IIE胡玥老师主讲)