计算机处理图像和文字的实质是在向量矩阵等基础上将其转化为数字,然后计算搜索的内容和库内容信息的匹配度
文字--->数值向量
算法案例:
词编码:N-gram
权重:TF-IDF ---->word2vec---->sense2vec
-----------------------------------------------------------------------------------------------------
NLP常见任务
自动摘要(百度,google)
指代消解 (代词理解指代是什么)
机器翻译 (应用面很广, 但目前还不完善)
词性标注
分词(中文,英文,日文)
主题识别
文本分类
.............
-----------------------------------------------------------------------------------------------------
NLP处理方法:
传统:基于规则
现代:基于统计机器学习
HMM CRF SVM LDA CNN......
"规则"隐含在模型参数里
-----------------------------------------------------------------------------------------------------
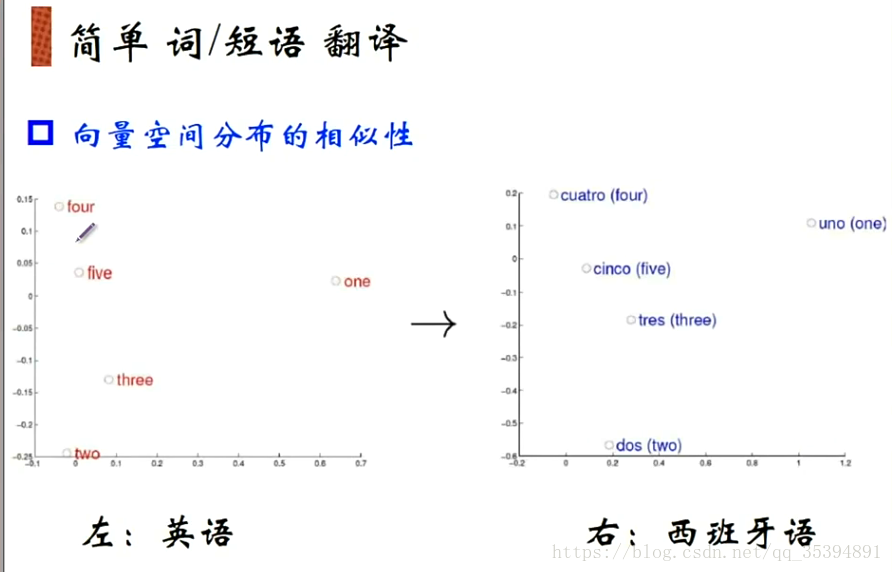

-----------------------------------------------------------------------------------------------------
数据决定结果上限
算法将以多大程度接近结果上限
词权重:(词在文档中的顺序没有被考虑)
TF-IDF 信息检索
Binary weighting 短文本相似性
离散表示缺点:
词表维度随着语料库增长膨胀
n-gram词序列随语料库膨胀更快
数据稀疏问题
无法衡量词向量之间的关系
分布式表示:
用一个词附近的其他词来表示该词
--》被称为现代统计自然语言处理中最有创见的想法之一
共现矩阵:
主要发现主题,用于主题模型,如LSA
局域窗中的word-word共现矩阵可以挖掘语法和语义信息
共现矩阵存的问题:
向量维度随着词典大小线性增长
存储整个词典的空间消耗非常大
一些模型如文本分类模型会面临稀疏性问题
模型会欠稳定
构造低维稠密向量作为词的分布式表示(25维~1000维)!
SVD降维

-----------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------