文本向量化
TF-IDF:(文本向量化,用来表示文本)

 分母加一:为了防止:分母为0
分母加一:为了防止:分母为0

衡量: 某个词在该篇文章中的重要性 ,可以查找文章关键字;通过计算词频的方式

txt_list列表为:
['愿 中国 青年 都 能 摆脱 冷气 , 只是 向上 走 , 不必 听 自暴自弃 者 流 的话 。 能 做事 的 做事 , 能 发声 的 发声 。', '有 一分 热 , 发一分光 , 就 令 萤火 一般 , 也 可以 在 黑暗 里发 一点 光 , 不必 等候 炬火 。 此后 如竟 没有 炬火 : 我 便是 唯一 的 光 。']
tfidf_model = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b",max_features=10,max_df=0.6,stop_words=["是", "的"]).fit(txt_list)
print("\n词频统计:\n",tfidf_model.vocabulary_)
#通过它来表示文章
transfer_data = tfidf_model.fit_transform(txt_list)
print('\n得到tf-idf矩阵,稀疏矩阵表示:\n', transfer_data)
print("文本特征抽取的结果百分占比为:\n", transfer_data.toarray())
print("提取关键字,返回排名前10关键字:\n", tfidf_model.get_feature_names())
参考:(115条消息) 文本向量化——基于TF-IDF词袋模型的文本向量化方法_小小小小U的博客-CSDN博客
然后:
计算文本相似度 (利用余弦公式)
基于支持向量机的新闻分类tf-idf
词的向量化
如何让计算机识别: 汉字
词向量
词的向量化 - zxclegend - 博客园 (cnblogs.com)

一、One-hot Representation
1.定义
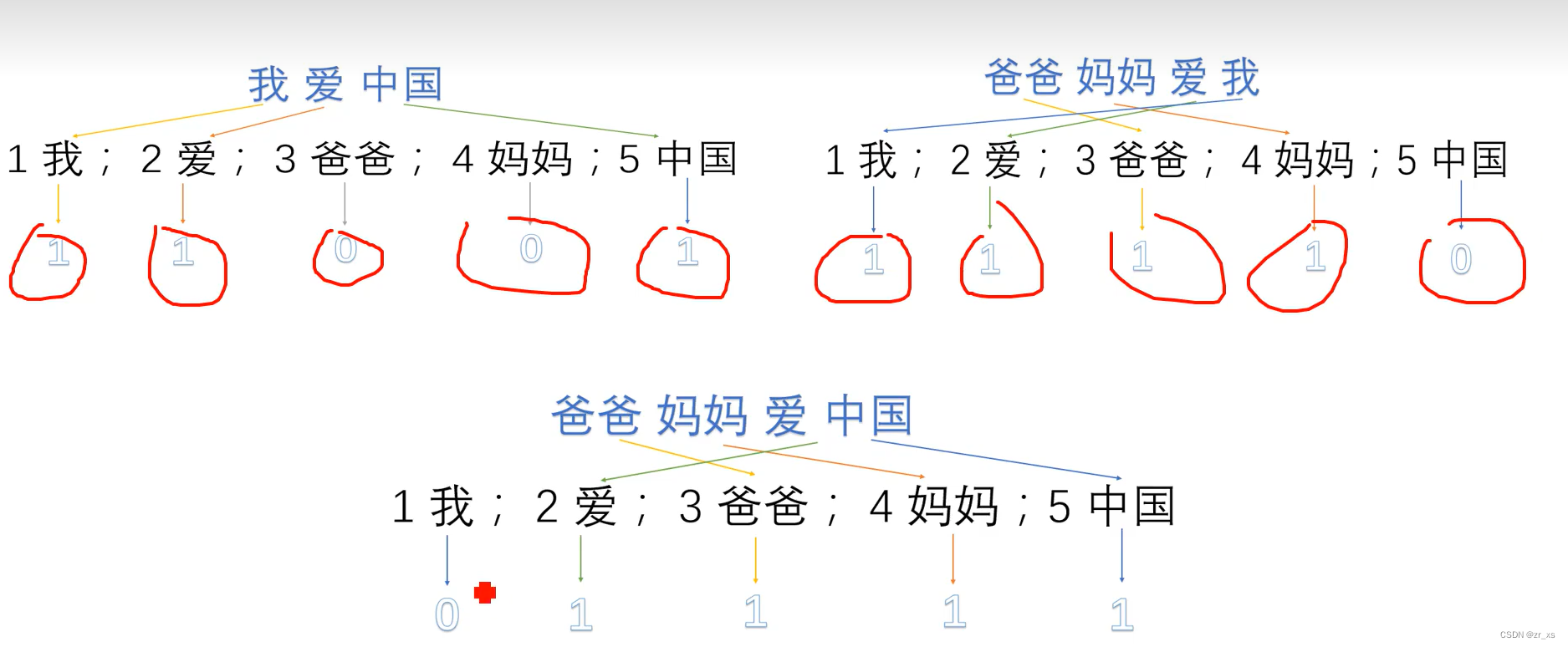
这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。方法简单,然这种表示方法也存在一个重要的问题就是“词汇鸿沟”现象:任意两个词之间都是孤立的。从数学上解释,正交基的积为0。
每一个sample: 由3个词组成。 sample的特征向量表示:
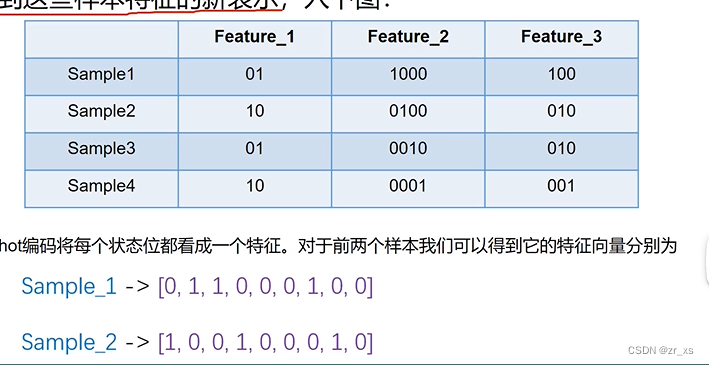
2.词袋模型:


优缺点:
+
不能表示出:词与词之间的关系
y维度灾难
one-hot: 是只有一个位置为1,其余位置为0的稀疏向量

二、weod2vec
也是一种词的表示 ;Word2vec(基本思想是把自然语言中的每一个词,表示成一个统一意义统一维度的短向量)

- 两个算法:continuous bag-of-words (CBOW)和skip-gram。
- CBOW是给定上下文环境时,预测该环境中间的那个中心词。(例如:我 爱 中国,利用 我 中国,预测 爱 )
- Skip-gram正好相反,预测一个中心词上下文环境的分布,其图示如下。(
- 两个训练方法:负采样(negative sampling)和分层softmax。
- 是神经网络的一个副产物 (理解神经网络:)

weod2vec ,2个向量关于文本相似度的计算
![]()
将每一个词,从多个维度来表示它(下面数字)


假设:
A B分别代表足球 篮球 ,那么在词向量空间中 (无论是在二维,还是高维上【50到300维,一般】,距离应该相近)