刘毅 360云计算
女主宣言
异常检测是AIOps领域中最为常见也是十分重要的一个问题,它将直接影响到报警产生以及后续所有自愈动作的开展。异常检测作为运维领域的通用场景,已经存在很多的方法模型可以使用。但是各个方法之间的异同,不同方法针对不同场景该如何匹配还是值得使用者认真考虑一番。本文详细介绍了常见的一些异常检测方法的优劣以及使用场景,并利用一个实际的场景作为例子,展示了360在大数据背景下是如何利用异常检测模型进行网络监测的。
PS:丰富的一线技术、多元化的表现形式,尽在“360云计算”,点关注哦!
1
异常检测简介
异常点也称为离群点,一般由于数据来源于不同的类型,噪声或者收集时的误差所产生。所谓异常检测,就是利用某些方法将异常点找出来。异常检测的应用有很多,这里只做简单的举例,例如在数据预处理方面可以用于去噪,在运维领域则产生报警,在金融和安全领域中,异常检测可以帮助判断数据波动以及是否受到***等等。
2
异常检测方法
规则匹配法
固定阈值法
固定阈值法是比较常见的一种异常检测方法,一般由业务人员针对不同的业务场景,设置一个固定的阈值。当观测值大于(或小于)阈值时则判断观测值是异常的,否则认为是正常的。该方法的优点在于简便,缺点在于过于依赖阈值设置者的经验,场景适配性低,不够通用。下图给出了固定阈值方法判断异常的效果图,图中阈值设置为90,大于90的点视为异常点。可以看出只有少数点被检测为异常点,会出现漏报的问题。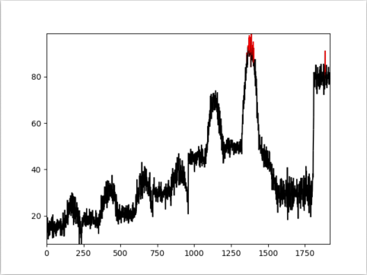
3sigma方法
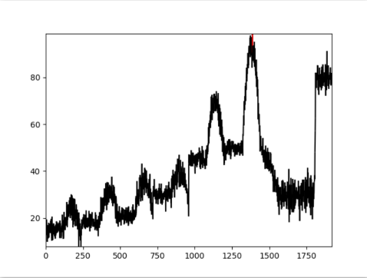
这个方法比较简单,这里就不详细介绍了,该方法与固定阈值方法的优缺点相同,这里只给出利用3sigma进行检测后的结果,如下图所示。可以看出利用3sigma方法只能找出一个异常点,漏报问题严重。
统计方法
统计方法整体的优点在于计算速度快,模型简单,易于实现。缺点在于模型对场景适配性不足,模型不够通用,一般只能进行单一维度的异常检测等等。
同比振幅检测
首先计算过去N天(一般是14天)的同比振幅最大值max_amplitude,其次计算当前的观测点与过去一天的同比值value,如果value>thresold*max_amplitude则认为当前点是异常的,反之则认为是正常的。该方法的优点在于利用了数据的周期性,规避了数据曲线自身周期性突变的情况。缺点在于周期性突变的时间必须重合,否则容易误警。下图给出了同比振幅检测的检测结果,后两部分之所以被视为异常是因为这两个段变化相对于之前的周期更大,当然这个判断的结果是可以通过阈值进行调整的。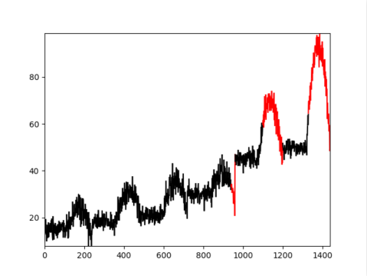
EWMA方法
EWMA方法可以视为一个简单的预测方法,他的主要想法是时间越近的数据权重越高,时间越远的数据权重越小。该方法的具体表达式如下所示,运用该方法进行异常检测时,首先对当前点计算EWMA值,然后利用3sigma方法进行异常点的判断。这个方法的优点在于容易检测到突变型异常,并且对于一个异常较短时间后发生的另一个异常的检测有较好的效果。缺点在于对于渐进型而非突变型异常检测能力较弱,异常持续一段时间后可能被视为正常。下图展示了使用EWMA方法进行异常检测的效果,可以看出整体效果还是很好的,对于孤立的异常点可以好的检测出来。

环比点检测
环比点检测方法首先计算待测点于过去30分钟的历史值的增幅比率,然后统计增幅比率超过增幅阈值的个数,如果异常数超过了阈值则认为是异常点。该方法的优点在于可以有效的检测出单点突增以及渐进型异常,缺点是异常持续一段时间后可能被判断为正常。下图展示了环比点检测的检测效果。

环比振幅检测
环比振幅检测方法需要计算过去10分钟与过去1h均值的振幅比率,并于阈值进行比较,超过阈值则认为是异常,否则认为是正常点。该方法的优点在于对于持续一段时间的异常检测比较明显,可以检测出短期的持续型异常,缺点在于容易掩盖单点突增的异常。下图展示了环比振幅检测的检测效果。

K_test检测
K_test检测通过判断两组数据是否来属于同一分布进行判断待测点是否是异常点。在进行K_test检测时首先将数据分成两部分(最近10分钟数据作为一组,10分钟前1小时数据为一组),其次对两组数据进行Kolmogorov-Smirnov检测(判断两组数据是否服从同一分布),如果两组数据服从统一分布,那么待测点是正常点;如果两组数据不服从统一分布,那么需要对近10钟的数据进行平稳性检验,如果不平稳则说明待测点是异常数据。K_test检测对于持续一段时间的异常检测有比较好的检测效果,容易忽略单点的突变现象。下图显示了K_test检测效果,可以看出异常刚刚产生时可以很快检测出,但是一段时间后,检测效果就不明显了。

聚类方法
DBSCAN算法
聚类方法中能够进行异常检测的算法不多,DBSCAN算法是其中比较优秀的一种。DBSCAN算法通过邻域距离和最小包含点数两个参数,可以找出数据中的核心点,边界点。而既不是边界点也不是核心点的点即为噪声点。核心点,边界点的概念这里不做解释,请自行查询。本分享中对于DBSCAN算法的原理我就不做详细的说明了,这里给出DBSCAN算法原始论文地址,有需要的同学可以自行阅读。https://www.aaai.org/Papers/KDD/1996/KDD96-037.pdf.下图给出DBSCAN算法异常检测的效果,可以看出检测的效果还是很好的。
机器学习方法
IForeast算法
IForeast算法是周志华老师设计的一种异常点检测算法,该方法通过利用数据构建iTree,进而构建iForest,是一种无监督的检测方法,具有很好的效果,具体的原理见:
http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf.
IForeast算法的优点是无监督模型,算法稳定,可以进行高维度检测,但是算法不适用于特别高维的数据,由于每次选取数据空间都是随机选取一个维度,建完树后仍然有大量的维度信息没有被使用,导致算法可靠性降低。下图展示了IForeast算法的检测结果,可以看出该方法的检测效果还是比较好的。而且由于算法集成在sklearn包中,可以将训练好的模型保存为文件形式,每个模型大约1~2M。

3
外网质量监控异常检测
下面我通过一个实际的场景来具体的说明一下,我们是如何利用异常检测算法来进行流量异常判断的。
场景背景
网络质量问题一直是一个限制产品质量的瓶颈问题,对网络质量的探测与及早预测能够有效的解决网络延迟等问题,从而极大的提高用户的体验。为了检测网络质量,我们以CDN机器模拟用户,向公司拥有的所有vip发送消息,采集平均延迟(avgdelay)和丢包率(loss)两个网络数据作为评价网络质量的指标,通过对这两个指标的判断从而实现外网质量检测的目的。整体的外网质量监控流程如下图所示,我们原始的策略是:loss>0.5认为是异常,对于avgdelay不做判断。改进策略是:利用异常检测算法检测avgdelay,不同的链路根据自身历史数据变化分析计算,阈值不同,实现高敏度差异性检测。

难点与解决方案
实时性强
场景覆盖了多个核心业务的全部2k多个目的vip,源cdn机房覆盖5个ISP,25个省市,总共超过10W+的链路需要判断。这些链路需要每分钟进行一次数据采集并及时进行异常检测,所以对于实时性的要求很高。 解决方案:利用redis缓存一部分数据(最近2小时共计120点),从而节省了从数据库中获取历史数据的时间,某些模型可以提前训练好并加载在内存中,以备使用。单一模型判断不准确
前面介绍了很多异常检测方法,但是在实际应用时发现某些模型不适用于场景,而且仅用单一模型进行异常检测精度很低。 解决方案:多模型进行组合判断,这里采用比较简单的加权众投决策。根据不同模型的检测效果确定模型的权重。链路众多,模型存储和加载困难
刚刚说过此场景中需要判断10W+链路,模型需要预先训练好并加载在内存中从而减少计算的时间。就IForeast模型为例,一个模型大约需要1~2M,10W+模型需要10~20G。模型所需的内存巨大,并且不可能全部加载到运行内存中。 解决方案:针对链路和数据众多,模型数量巨大的问题,我们希望通过对链路进行聚类的方式进行降维,从而减少所需训练的模型数量。计算数据redis预存储
针对链路众多,数据量大,检测实时性强的问题,我们考虑利用redis中pubsub实时性强的特点加以解决。实际的解决方案如下图所示,接收端每分钟对10W+的链路数据进行采集,并存入redis中;redis预先保存着119位数据,接到数据后从而保证每个链路存在120位数据,针对缺失数据用null补充;当收到数据后将全部的120位数据以参数的形式传给异常检测模型中进行检测,从而实时的产生异常报警。

多模型组合判断,众投决策
下图展示了分别用环比振幅检测,环比点检测,孤立森林算法以及三种方法按照一定权重融合后的组合模型对某链路进行的异常检测效果。从图中可以明显看出单一模型各自都有一些异常点无法判断出,组合模型对于异常点的判断更为全面。当然,再计算模型阈值时,我们假定数据中异常点的比率为10%,这个数值可能不是很合理,这需要根据实际场景进行调整。

链路聚类降维,模型预加载
前文提到过,场景存在10W+链路,一个模型大约需要1~2M,如果每个链路都需要进行模型训练,那么需要10~20G的内存,这个存储量比较大。因为我们决定对链路进行聚类,从而起到降维的作用。常见的聚类模型有:DBSCAN模型,Kmeans模型以及MiniBatchKmeans模型,下面分别介绍一下他们的特点以及在此场景中应用的效果。
DBSCAN模型
DBSCAN模型的优点在于不需要设定聚类个数,模型会自动将数据分为多个类别。这个特点其实在这个场景中是很有用的,因为我们不知道应该将链路聚为多少类最合适。但是DBSCAN模型的缺点在于调参困难,链路众多,通过绘图等方式人工调参效果很差。因此我选择用差分进化算法帮助寻找参数。但是调参的速度很慢,因此放弃这种方法。
Kmeans模型
Kmeans模型的优点在于参数少,只需要提供聚类的个数即可,但是缺点在于聚类个数难以确定,大规模数据聚类速度缓慢(本场景预计需要2天时间),得到的是局优解,对噪声敏感。由于聚类速度慢,因此也被舍弃。
MiniBatchKmeans模型
MiniBatchKmeans模型是Kmeans模型的改进,每次不选取所有的数据进行聚类,而是每次随机选取一部分数据聚类,分批聚类的方式减少计算量,提高速度。该方法适用于大规模多特征数据聚类,本场景每次聚类平均需要7s。MiniBatchKmeans模型我在这里不做详细的介绍,我提供该模型的论文地址,有兴趣的同学可以自行阅读。

选定了聚类模型后,还有两个问题需要解决,第一是聚类模型中特征的提取与构造,第二是聚类个数的选择。
特征的构造
原始数据是某条链路过去7天的平均延迟,我在构造特征时遵循新数据权重大,旧数据权重小的原则进行特征的构造。具体的特征结构如下所示:
这里需要解释一下,avg1D(10%,90%)指的是,将最近1天的数据进行由大致小顺序排序,取最大的前10%数据以及剩余的90%的数据的平均值,作为2个特征。item数值则按照数据权重大,旧数据权重小的原则计算得来的,每天的权重依次缩小二分之一。
K值的选择
聚类个数的选择十分重要,将直接影响聚类的效果。考虑到每个模型大小约1~2M,因此将K的取值范围定为[50,150]。常见的K值选取的方法有两种,(1)手肘法,即依次计算不同K值的聚类后的sse,并绘制K-sse曲线,如果形成下图类似的手肘形式,那么就取拐点值作为K值,因此下图中应该取K=4。
(2)最优值方法,聚类时希望类内距越小越好,类间距越大越好,因此计算value作为衡量聚类效果的指标,value具体表达如下。可以看出value值越小则聚类效果越好。
针对这两个方法,我分别遍历K的不同取值,并绘制了K-sse曲线以及K-value曲线,如下所示。可以看出K-sse曲线并没有显示出手肘形式,不存在拐点。因此我们选用最优值方法,选择value最小值对应的K作为聚类个数,此处K=78.


最终效果展示
下图展示了分别用环比振幅检测,环比点检测,孤立森林算法以及三种方法按照一定权重融合后的组合模型对某链路进行的异常检测效果。可以看出孤立森林算法检测出的异常点明显比其他模型检测出的多,因为该模型是用一类链路的平均值进行训练的,因此对单一链路效果略差。但是融合模型规避了这一问题。

4
异常检测常见问题与思考
最后,我想写一点关于异常检测的常见问题,作为结束。异常检测作为AIOps领域的通用场景,被广泛的应用与研究。本文中提到的一些方法都比较简单,当然还有很多复杂而且优秀的方法,本文没有涉猎。实际应用者总会在算法模型的选择上纠结,我也常常对此产生困惑。所以首先,我便来聊一聊模型的选择问题,这仅仅是我自己的看法,仅做参考。我觉得作为算法工程师,我们应该对于复杂的模型有自己的追求,不停的研究准确度更高的模型,不断地开阔自己的思路。但是精度高的模型往往跟随着复杂度大,训练速度缓慢的问题,所以研究是一方面,但是落地又是一方面。针对实际场景应该选择最适合的方法,即使最简单的固定阈值方法最有效,也不要为了AI而AI,要摒弃模型越高大上越好的想法,作为聪明的人应该做聪明的事。应该思考如何将高大上的模型适配于当前的场景。除了模型的选择,我还想说一下人工标注以及人工经验对于AI的重要程度。提到人工标注,可能常见于分类等有监督模型中,对于无监督模型,因为对于数据的要求中可以没有标签,因此标注就不那么常见了。但是在实际的应用中,我发现,其实人工标注不论在有监督还是无监督的模型中都是极其重要的。就以本文所提的异常检测模型,都是一些无监督的模型,但是即使是无监督的模型,也需要通过阈值对比才能产生结果,阈值的训练是很复杂的,针对不同的场景,不同的数据源,阈值也不同。因此,如何提高异常检测的准确度,选择优秀的模型是一个方面,还有就是可以通过人工标注的方式,对AI判断出的异常加以修正,从而反馈模型,起到提高检测质量的目的。人工经验也是很重要的,并不是有了算法模型就可以把人工经验抛到一边,否则就是一种浪费。我们利用人工经验帮助我们进行数据的筛选,将过于异常的数据筛选出去,从未保证数据的跨度较小。也可以利用人工经验辅助算法,从而提高检测的准确性。