那什么是正则表达式呢?
- 正则表达式
是一种通过符号和字符串进行匹配规则的,对文件内容的查询结果进行影响。
正则表达式是由普通字符和元字符构成。
1.其中普通字符包括大小写字母,数字,标点符号及一些其它符号。
2.而元字符则是指那些在正则表达式中有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
常用正则:grep、sed、awk、pgrep、mkdir、touch……
touch a{1…100}.txt
[root@localhost ~]# ifconfig ens33 | grep "inet 192.168.6.20 " | awk ‘{print $5}’
broadcast
- grep组合正则表达式的用法
(1)n:显示行号,查询的指定字符串在文件中所在的行号
grep -n "ServerName" /usr/local/httpd/conf/httpd.conf
(2)i:显示内容不区分大小写
grep -in "ServerName" /usr/local/httpd/conf/httpd.conf
(3)v:反向查询,显示不包含指定字符串的行
grep -vn "ServerName" /usr/local/httpd/conf/httpd.conf
(3)[ ] :匹配[ ]中任意字符,or的意思

grep -in "Server[Nn][avty]me" /usr/local/httpd/conf/httpd.conf
[root@localhost ~]# grep -n shu[twqwqn]do[abcde]n /etc/passwd
[root@localhost ~]# grep -n shu[twqwqn]do[abcdew]n /etc/passwd
7:shutdown:x :6:0:shutdown:/sbin:/sbin/shutdown
(4)^ :以指定的字符或字符串开头
grep -n "^[Ss]" /usr/local/httpd/conf/httpd.conf
(5)$ :放在字符串前面,表示调用变量,字符串为变量名。放在字符串后面,表示以该字符串结尾。
特殊用法: $ abc {$ 表示调用变量}
注意:如果结尾为.则需要加转义符。因为.在 正则表达式中也是一个元字符,所以需要用转义符\将具有特殊意义的字符转化成普通字符。
grep -n "html$" /usr/local/httpd/conf/httpd.conf
grep -n "\.$" /usr/local/httpd/conf/httpd.conf
df | grep "/$"
cat httpd.conf | grep "\.$"
grep "com:80$" httpd.conf
(6)^$ :显示空行
grep -n "^$" /usr/local/httpd/conf/httpd.conf
(7)
[起始数字-结束数字] : 在指定的数字范围之间 [1-10]
[起始字母-结束字母] : 在指定的字母范围之间 [a-u]
grep -n “[A-Z]” /usr/local/httpd/conf/httpd.conf
[A-Z] :连续范围的数字或字母
数字举例:
[root@localhost ~]# grep -n ^[1..5] /etc/passwd [*..*]这种写法是错误的
43:123:x:1000:1000:123:/home/123:/bin/bash
44:10
[root@localhost ~]# grep -n ^[1-30] /etc/passwd 正确写法
43:123:x:1000:1000:123:/home/123:/bin/bash
44:10
45:20
[root@localhost ~]# grep -n ^[1-10] /etc/passwd 特殊情况
43:123:x:1000:1000:123:/home/123:/bin/bash
44:10
- 基础正则表达式
(1)取反值
格式一、
^[^] :取反值,不是以指定字母开头的字符串
查找“oo”前不是“w”的字符串
grep -n '[^w]oo' test.txt
格式二、
[^] : 取反值,查询出包含“除指定的字母或数字范围外”的字符串
[^a-z] [^A-Z] [^0-9]
grep "[^a-z]ork" httpd.conf
(2){ } :指定之前的字符重复出现的数量,{ } 需要加转义符 还有:\. \* \( \) \$ \/
指定字符{数字1,数字2} : 表示字符串中,指定字符连续出现的数量范围 “wo{2,5}rk”
指定字符{数字1} : 表示字符串中,指定字符连续出现的数量范围 “wo{2}rk”
例:
查询包含1-3个o的字符串
grep -n 'wo\{1,3\}d' test.txt o\{1,3\}
查询数量为2以上连续出现的字符串
grep -n 'o\{2\}' test.txt o\{2\} oooo:这也是oo的双倍
(3)正则中的通配符:
. 代替一个字符,可以连续使用,不能代表空值
* 代替一组字符,可以为空
.* 字符可有可无
grep ‘r…o’ /etc/passwd
查询r和o中间有2个字符的,空格算一个字符
grep -n ‘ooo*’ /etc/passwd.old
查询两个o以上的字符串
在查询“oo o*”中,必须以oo成对出现的,而在查询“ooo o*”,必须以ooo成对出现
如果是“o o*”,则第一个o必须存在,第二个o是零个或者多个,所以包含o、oo、ooo、oooo、……
若查询“oo o*”,查询两个o以上的字符串。搜索关键字是两a。包含oo、ooo、oooo、……
若查询“ooo o*”,查询三个o以上的字符串。包含ooo、oooo、……
grep -n ‘.*’ /etc/passwd.old
所有都出现
- 扩展正则表达式
在shell中,增加了一些更简化的正则表达式元字符,只有一小部分命令支持扩展正则表达式。
使用命令:
grep命令仅支持基础正则表达式。如果使用扩展正则表达式,需要使用egrep或awk命令!
1)egrep -n ‘woo+d’ test.txt #“wo{2,}rk"可以写成"wo+rk”
+ :重复一个或者一个以上的前一个字符
2)egrep -n ‘o?oo’ test.txt #代表查询指定文件中包含oo,且第一个o可要可不要的字符串
? :零个或者一个的前一个字符
3)egrep -n ‘o?’ test.txt
查询没有或有一个以上o的字符串
4)egrep -n ‘oo?’ test.txt
查询一个或有一个以上o的字符串
5)egrep -n ‘ooo?’ test.txt
查询两个或有两个以上o的字符串
6)egrep -n ‘name|Name’ /usr/local/httpd/conf/httpd.conf
查询文件中与指定字符串相同的内容
7)egrep -n ‘t(a|e)st’ /usr/local/httpd/conf/httpd.conf (只能对某一字符进行限制)
查询“组”字符串
8)egrep -n ‘A(xyz)+C’ /usr/local/httpd/conf/httpd.conf
#查询开头的“A”结尾是“C”,中间有一个以上的“xyz”字符串的意思。(一个以上代表:xyzxyzxyz...)
辨别多个重复的组
以上后三个必须加引号,而之前的可加可不加!!!
———————————————————————————————————————————————————————
shell编程三剑客: GREP SED AWK
sed命令教学
awk命令教学
【1】sed是一种在线编辑器,它一次处理一行内容。
Sed主要作用:
用来自动编辑一个或多个文件;
简化对文件的反复操作;
编写转换程序等。
【默认情况下,所有的sed命令都是在模式空间内执行的(也就是不修改源文件)!因此输入的文件并不会发生任何变化,除非是用重定向存储输出 】
用法:
两种格式
sed [选项] ‘操作’ 参数
sed [选项] -f scriptfile 参数
[选项]
常见的sed命令选项主要包含以下几种:
-n、–quiet或silent:仅显示处理后的结果
-i:编辑文本内容
-e或-expression=:用指定命令或者脚本来处理输入的文本文件
-f或-file=:用指定的脚本文件来处理输入的文本文件
-h或–help:显示帮助
‘操作’
“操作”用于指定对文件操作的动作行为,也就是sed命令。通常情况下是采用“[n1[,n2]]”操作参数的格式。n1、n2是可选的,不一定会存在,代表选择进行操作的参数。
如:操作需要在5~20行之间进行,则表示为“5,20动作行为”。
常见的操作包括以下几种:
a: 增加,在当前行下面增加一行指定内容。
c: 替换,将选定行替换为指定内容
d: 删除,删除选定的行
i : 插入,在选定行上面插入一行指定内容
p: 打印, 如果同时指定行,表示打印指定行。如果不指定行,则表示打印所有内容。如果有非打印字符,则以ASCII码输出。其通常与“-n”选项一起使用。
s : 替换,替换指定字符
y: 字符转换
参数:是指操作的目标文件。当存在多个操作对象时,文件之间用逗号“,”分隔!
而scriptfile表示脚本文件,需要用选项“-f”指定。当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标文件。
可以在命令行状态直接对文件内容进行编辑和查看
- a:在指定的行号后添加一行内容
sed -i ‘1a#chkconfig:35 25 25’ /usr/local/httpd/conf/httpd.conf 注意,不能给空文件添加数据。
sed -i ‘/#ServerName/a \192.168.100.100’ /usr/local/httpd/conf/httpd.conf
在#ServerName的下一行添加192.168.100.100
- p:输出符合条件的文本内容
sed -n ‘90p’ /usr/local/httpd/conf/httpd.conf
查看第90行内容
sed -n ‘90,100p’ /usr/local/httpd/conf/httpd.conf
查看第90-100行内容
sed -n “95,+10p” /etc/httpd/conf/httpd.conf
读取行号往下指定行数量的内容
sed -n ‘$=’ /usr/local/httpd/conf/httpd.conf
查看总行数
- d:删除文件中指定的行数
cp /usr/local/httpd/conf/httpd.conf /usr/local/httpd/conf/httpd.txt
head -16 /usr/local/httpd/conf/httpd.txt
删除指定范围的行:
sed -i “360,364d” /usr/local/httpd/conf/httpd.txt
sed -i “355, +10d” /usr/local/httpd/conf/httpd.txt
sed -i ‘/apache/d’ /usr/local/httpd/conf/httpd.txt
删除带有指定字符串的行
sed -i ‘/apache/!d’ /usr/local/httpd/conf/httpd.txt
删除不包含指定字符串的所有行
sed -i ‘/^#/d’ /usr/local/httpd/conf/httpd.txt
删除所有#开头的行
sed -i ‘/^$/d’ /usr/local/httpd/conf/httpd.txt
删除所有空行
- s:修改指定文件中的内容(常用)
vim a.txt
server
SERVER
Server
aaabaaaa
dddkdda
sed -i ‘s/server/SERVER1/’ a.txt
将每行的第一个字符串进行修改
sed -i ‘s/server/SERVER1/3’ a.txt
后面的数字3代表将每行的【第几个同名字符串】进行修改
sed -i ‘/server/c #haha’ /a.txt
替换指定字符串所在的行
只替换指定的字符串,不会替换整行。
sed -i ‘s/server/SERVER/g’ /a.txt 后面的g表示对全文进行修改
【2】awk:功能强大的编辑工具。逐行读取输入文本,并根据指定的匹配模式进行查找(一般多用于显示指定的字段)

【1】分割符,默认为空格分割符。将文件的每一行的第一个字段分割出来
awk -F: ‘{print $1}’ /etc/passwd
awk ‘{print}’ /a.txt = cat /a.txt
awk ‘{print $0}’ /a.txt = cat /a.txt awk使用$0表示整个行(记录)
【2】输出第一到第三行内容
awk 'NR==1,NR==3{
print $0}' /a.txt
awk '(NR>=1)&&(NR<=3){
print}' /a.txt
【3】输出第一和第三行内容
awk 'NR==1||NR==3{
print}' /a.txt
【4】
awk ‘(NR%2)==0{print}’ /a.txt
输出所有偶数行内容
awk ‘(NR%2)==1{print}’ /a.txt
输出所有奇数行内容
awk ‘/^root/{print}’ /etc/passwd
输出以root开头的行
awk ‘/nologin$/{print}’ /etc/passwd
输出以nologin结尾的行
awk ‘BEGIN{X=0};//bin/bash$/{x++};END{print x}’ /etc/passwd
统计以bin/bash结尾的行数
awk的工作流程:
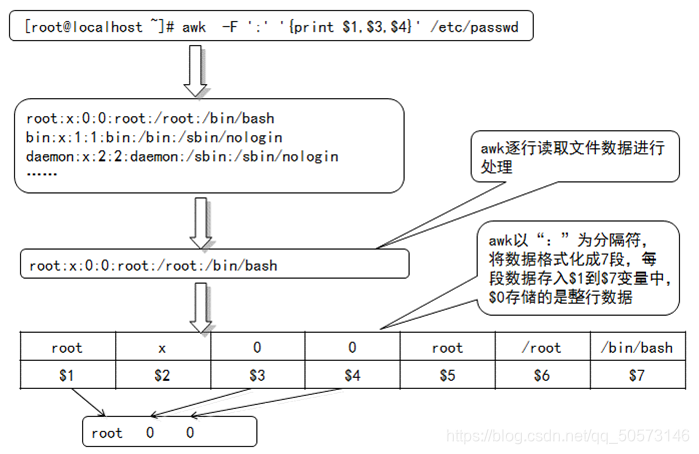
拓展:
awk包含几个特殊的内置变量(可直接用)
FS : 指定每行文本的字段分隔符,默认为空格或制表位
NF : 当前处理的行的字段个数
NR:当前处理的行的行号(序数)
$0 :当前处理的行的整行内容
$n :当前处理行的第n个字段(第n列)
FILENAME:被处理的文件名
RS :数据记录分隔。默认为n,即每行为一条记录
-F: 指定 :为分隔符,默认为空格分隔
让我们一起努力,加油!!!

LAMP动态网站平台