【ybtoj 高效进阶 2.2】【hash】 单词背诵
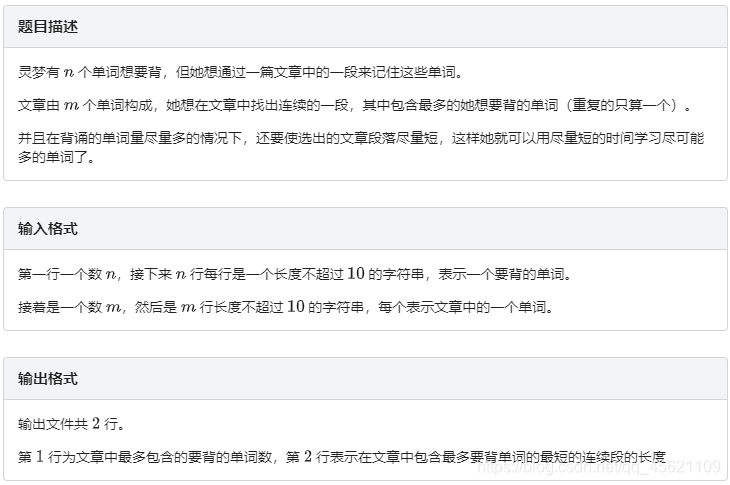
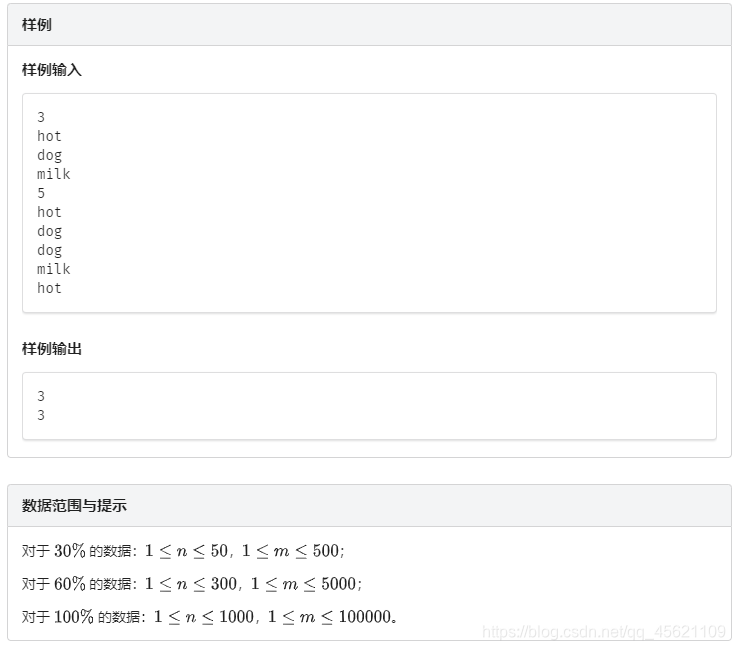
题目
解题思路
求出所有单词的哈希值
根据哈希值排序
找到文章中的词在需背单词里的位置
枚举左边界
因为左边界只是向右移动一个,记录当前段包含的单词,减掉当前左边界那个单词,就是新的一段的初始
右边界不断往后移
除非需背单词都包含了,只需要移左边界
代码
#include <algorithm>
#include <iostream>
#include <cstring>
#include <cstdio>
#define ull unsigned long long
using namespace std;
const ull p = 131;
struct lzf {
int w;
ull z;
} h[1020];
string x;
ull y;
int n, m, r, ans, dcs, ans1, a[1020000], v[1020];
bool cmp(lzf t, lzf f) {
return t.z < f.z; } //按哈希值培训
int find(ull y) {
int l = 1, r = n;
while (l <= r) {
int mid = (l + r) / 2;
if (h[mid].z < y)
l = mid + 1;
else if (h[mid].z > y)
r = mid - 1;
else
return h[mid].w;
}
return -1;
} //二分找位置
ull hash(string s) {
ull ans = 0;
int l = s.size();
for (int i = 0; i < l; i++) ans = ans * p + (s[i] - '0');
return ans;
} //求哈希值
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
cin >> x;
h[i].w = i;
h[i].z = hash(x);
}
sort(h + 1, h + n + 1, cmp);
scanf("%d", &m);
for (int i = 1; i <= m; i++) {
cin >> x;
y = hash(x);
int w = find(y);
if (w > 0) {
if (!v[w])
ans++; //能在文章里找到需背单词的个数
v[w] = 1;
}
a[i] = w;
}
memset(v, 0, sizeof(v));
r = 1, ans1 = 2147483647; //r是右边界,ans1是需背文章的长度
for (int l = 1; l <= m; l++) {
while (dcs < ans && r <= m) {
if (a[r] >= 0) {
if (!v[a[r]])
dcs++;
v[a[r]]++;
} //
r++;
} //更新当前段包含需背的单词
if (dcs == ans)
ans1 = min(ans1, r - l); //包含所有能背的需背单词
if (a[l] >= 0) {
v[a[l]]--;
if (!v[a[l]])
dcs--; //dcs是当前段包含需背的单词
}
}
printf("%d\n%d", ans, ans1);
return 0;
}