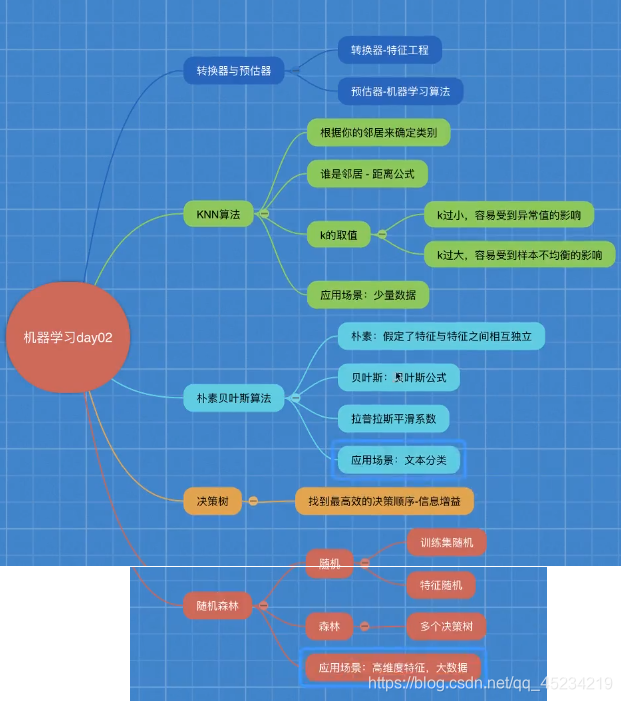
学习目录:

四.朴素贝叶斯算法



例子: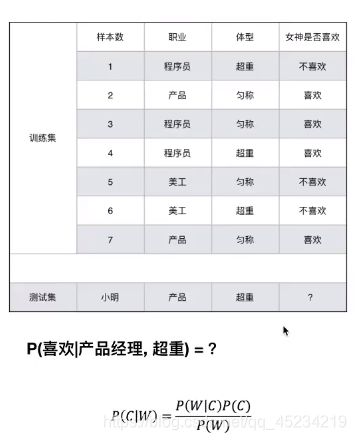

朴素贝叶斯的应用(含拉普拉斯平滑系数):文本分类案例
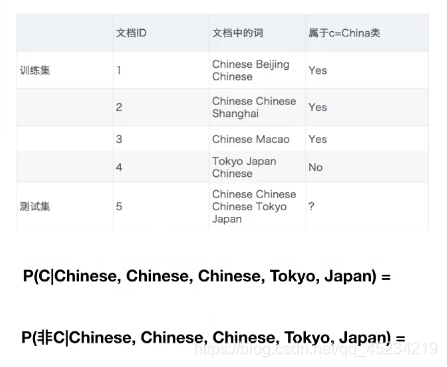


案例:20类新闻文本分类
**流程:**获取数据(不需要做数据处理,英文sklearn数据是处理好的)
划分数据集
特征工程(由于是文章,所以要做文本特征抽取)
朴素贝叶斯预估器流程
模型评估
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.naive_bayes import MultinomialNB
def nb_news():
#获取数据集
news = fetch_20newsgroups(subset='all')
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
#特征工程
transfer = TfidfVectorizer()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)#不使用fit(),因为对验证集进行标准化要按照训练集的标准化标准进行
#朴素贝叶斯算法预估流程
estimator=MultinomialNB()#调用贝叶斯算法
estimator.fit(x_train,y_train)
#模型评估
#方法一:直接比对真实值和预测值
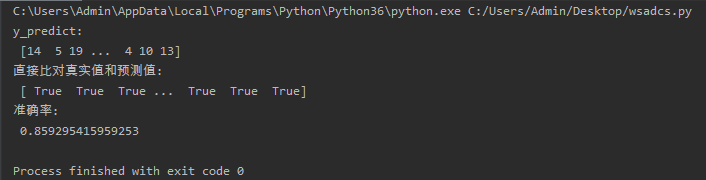
y_predict=estimator.predict(x_test)
print('y_predict:\n',y_predict)
print('直接比对真实值和预测值:\n', y_test=y_predict)
# 方法二:计算准确率
score = estimator.score(x_test,y_test)
print('准确率:\n', score)
if __name__=='__main__':
nb_news()
总结:朴素贝叶斯
优点:对缺失数据不太敏感,算法比较简单,常用语文本分类 分类准确度比较高,速度快
缺点:由于使用了样本属性相互独立的假设,所以如过特征与特征之间相互有关联时,效果会变差
分类算法总结: