一、引言
实际数据中的属性通常是高度相关的。这种依赖关系提供了相互预测属性的能力。预测和异常检测的概念密切相关。毕竟,离群值与特定模型的预期值(或预测值)不一致。线性模型关注于使用属性间依赖来实现这个目标。在经典的统计学文献中,这个过程被称为回归建模。
回归建模是相关分析的一种参数形式。某些形式的相关性分析试图从其他自变量中预测因变量,而其他形式的相关性分析则以潜变量的形式总结整个数据。后者的一个例子是主成分分析方法。这两种形式的建模在离群值分析的不同场景中都非常有用。前者对于时间序列等复杂数据类型更有用,而后者对于常规的多维数据类型更有用。
线性模型的主要假设是,(正常)数据嵌入在一个低维子空间。因此,不符合这种嵌入模型的数据点被视为离群值。在线性方法中,目标是找到低维子空间,其中异常点的行为与其他点非常不同。
二、线性回归模型
在线性回归,数据中的观测值是用一个线性方程组来建模的。具体来说,数据中的不同维度使用一组线性方程相互关联,其中的系数需要以数据驱动的方式学习。由于观测值的数量通常比数据的维数大得多,这个方程组是一个过定的方程组,不能精确地求解(即,零误差)。因此,这些模型学习的系数最小化的平方误差的偏差的数据点从值预测的线性模型。误差函数的精确选择决定了某一特定变量是否得到特殊处理(即预测变量值的误差) ,或者变量是否得到均匀处理(即与估计的低维平面的误差距离)。这些对误差函数的不同选择不会导致相同的模型。事实上,特别是在存在异常值的情况下,这些模型在性质上是非常不同的。
回归分析通常被认为是统计学领域的一个重要应用。在这个应用程序的经典实例中,需要从一组独立变量中学习特定因变量的值。这是时间序列分析中的常见情况。自变量也称为解释变量。这是上下文数据类型的常见主题,其中一些属性(例如,时间、空间位置或相邻的序列值)被视为独立的,而其他属性(例如,温度或环境测量)则被视为相关的。对于简单的多维数据类型,所有的维度都以相同的方式处理,并估计所有属性之间的最佳拟合线性关系。
考虑一个领域,例如时间和空间数据,其中属性被划分为上下文和行为属性。在这种情况下,一个特定的行为属性值通常被预测为其上下文邻域中行为属性的线性函数,以确定偏离期望值的情况。这是通过从时间或空间数据中构建一个多维数据集来实现的,在这个数据集中,一个特定的行为属性值(例如当前时间的温度)被视为因变量,它的相关邻域行为值(例如前一个窗口中的温度)被视为独立变量。因此,用估计偏差来量化离群值得分。在这种情况下,异常值是根据预测因变量的误差来定义的,而自变量之间相互关系中的异常被认为不那么重要。因此,优化过程的重点是最小化因变量的预测误差,以建立正常数据的模型。偏离此模型的值被标记为离群值。
我们通常所说的异常检测中并不会对任何变量给与特殊对待,异常值的定义是基于基础数据点的整体分布,因此需要采⽤⼀种更⼀般的回归建模:即以相似的⽅式对待所有变量,通过最小化数据对该平⾯的投影误差确定最佳回归平⾯。在这种情况下,假设我们有⼀组变量X1,X2,…,Xd,对应的回归平面如下:
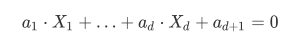
为了后续计算的⽅便,对参数进⾏如下约束:
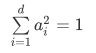
以L2范数作为⽬标函数:
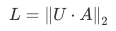
三、PCA
最小二乘公式只是简单地试图找到一个(d-1)维超平面,沿正交方向得到一个最佳拟合的数据值和误差。主成分分析是这个问题的一般化。具体地说,它可以找到任意维数的最优表示超平面。换句话说,PCA 方法可以确定 k 维超平面(对于 k < d 的任意值) ,从而使剩余(d-k)维数上的平方投影误差最小。最小二乘的优化解是主成分分析的一个特例,它是通过设置 k = d-1得到的。
与异常检测相关的主成分分析的主要性质如下:
- 如果前k个特征向量选定之后(根据最⼤的k个特征值),由这些特征向量定义的k维超平⾯是在所有维度为k的超平⾯中,所有数据点到它的均⽅距离尽可能小的平⾯。
- 如果将数据转换为与正交特征向量对应的轴系,则转换后的数据沿每个特征向量维的⽅差等于相应的特征值。在这种新表⽰中,转换后的数据的协⽅差为0。
- 由于沿特征值小的特征向量的转换数据的⽅差很低,因此沿这些⽅向的变换数据与平均值的显着偏差可能表⽰离群值。

主成分分析⽐因变量回归能更稳定地处理少数异常值的存在。这是因为主成分分析是根据最优超平⾯来计算误差的,而不是⼀个特定的变量。当数据中加⼊更多的离群点时,最优超平⾯的变化通常不会⼤到影响离群点的选择。因此,这种⽅法更有可能选择正确的异常值,因为回归模型⼀开始就更准确。
四、实例
1.数据可视化
import warnings
warnings.filterwarnings(‘ignore’)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
##载⼊训练集和测试集;
path = ‘./’
f=open(path+‘breast-cancer-unsupervised-ad.csv’)
Train_data = pd.read_csv(f)
##简略观察数据(head()+shape)
Train_data.head()
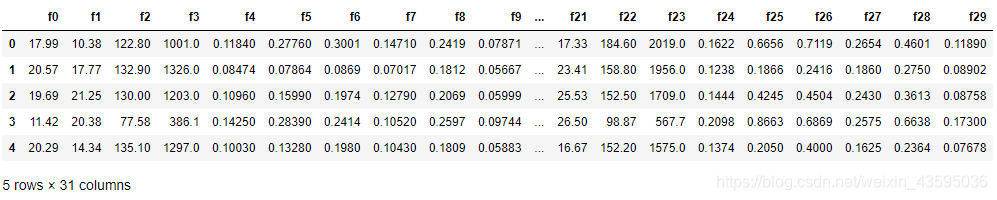
##简略观察数据(tail()+shape)
Train_data.tail()

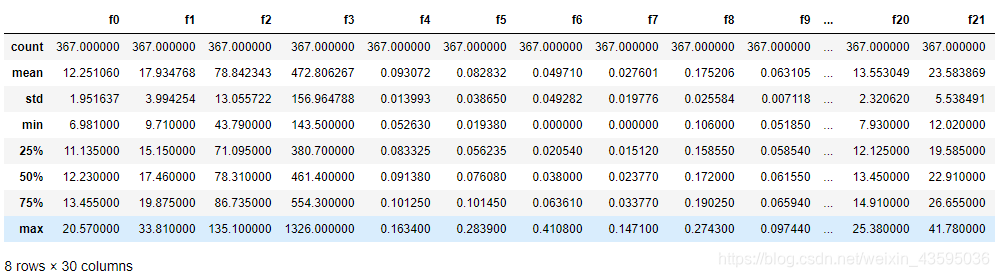
##通过describe()来熟悉数据的相关统计量
Train_data.describe()
##通过info()来熟悉数据类型
Train_data.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 367 entries, 0 to 366
Data columns (total 31 columns):
Column Non-Null Count Dtype
0 f0 367 non-null float64
1 f1 367 non-null float64
2 f2 367 non-null float64
3 f3 367 non-null float64
4 f4 367 non-null float64
5 f5 367 non-null float64
6 f6 367 non-null float64
7 f7 367 non-null float64
8 f8 367 non-null float64
9 f9 367 non-null float64
10 f10 367 non-null float64
11 f11 367 non-null float64
12 f12 367 non-null float64
13 f13 367 non-null float64
14 f14 367 non-null float64
15 f15 367 non-null float64
16 f16 367 non-null float64
17 f17 367 non-null float64
18 f18 367 non-null float64
19 f19 367 non-null float64
20 f20 367 non-null float64
21 f21 367 non-null float64
22 f22 367 non-null float64
23 f23 367 non-null float64
24 f24 367 non-null float64
25 f25 367 non-null float64
26 f26 367 non-null float64
27 f27 367 non-null float64
28 f28 367 non-null float64
29 f29 367 non-null float64
30 label 367 non-null object
dtypes: float64(30), object(1)
memory usage: 89.0+ KB
numeric_features = [‘f’ + str(i) for i in range(30)]
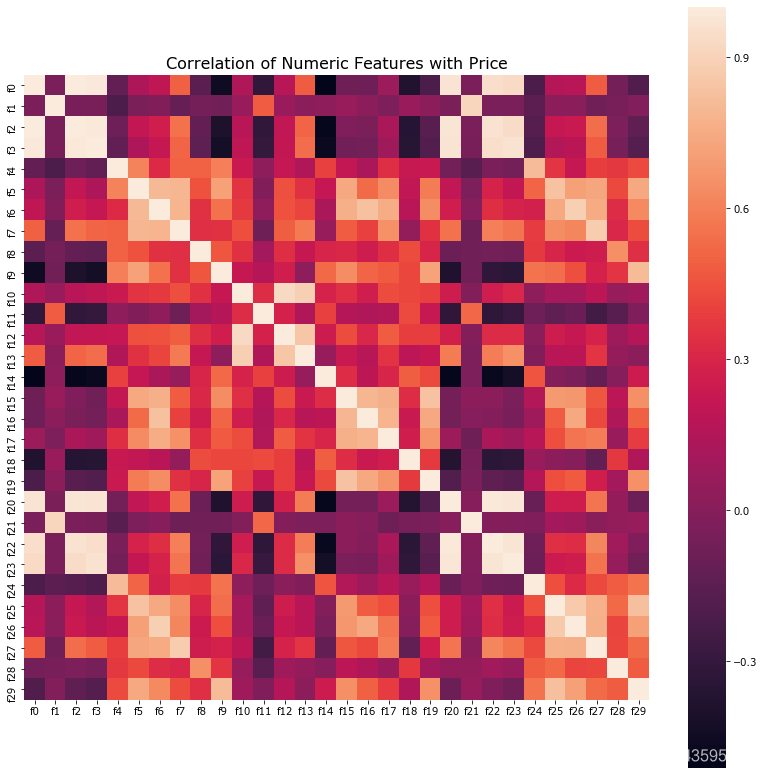
##相关性分析
numeric = Train_data[numeric_features]
correlation = numeric.corr()
f , ax = plt.subplots(figsize = (14, 14))
sns.heatmap(correlation,square = True)
plt.title(‘Correlation of Numeric Features with Price’,y=1,size=16)
plt.show()
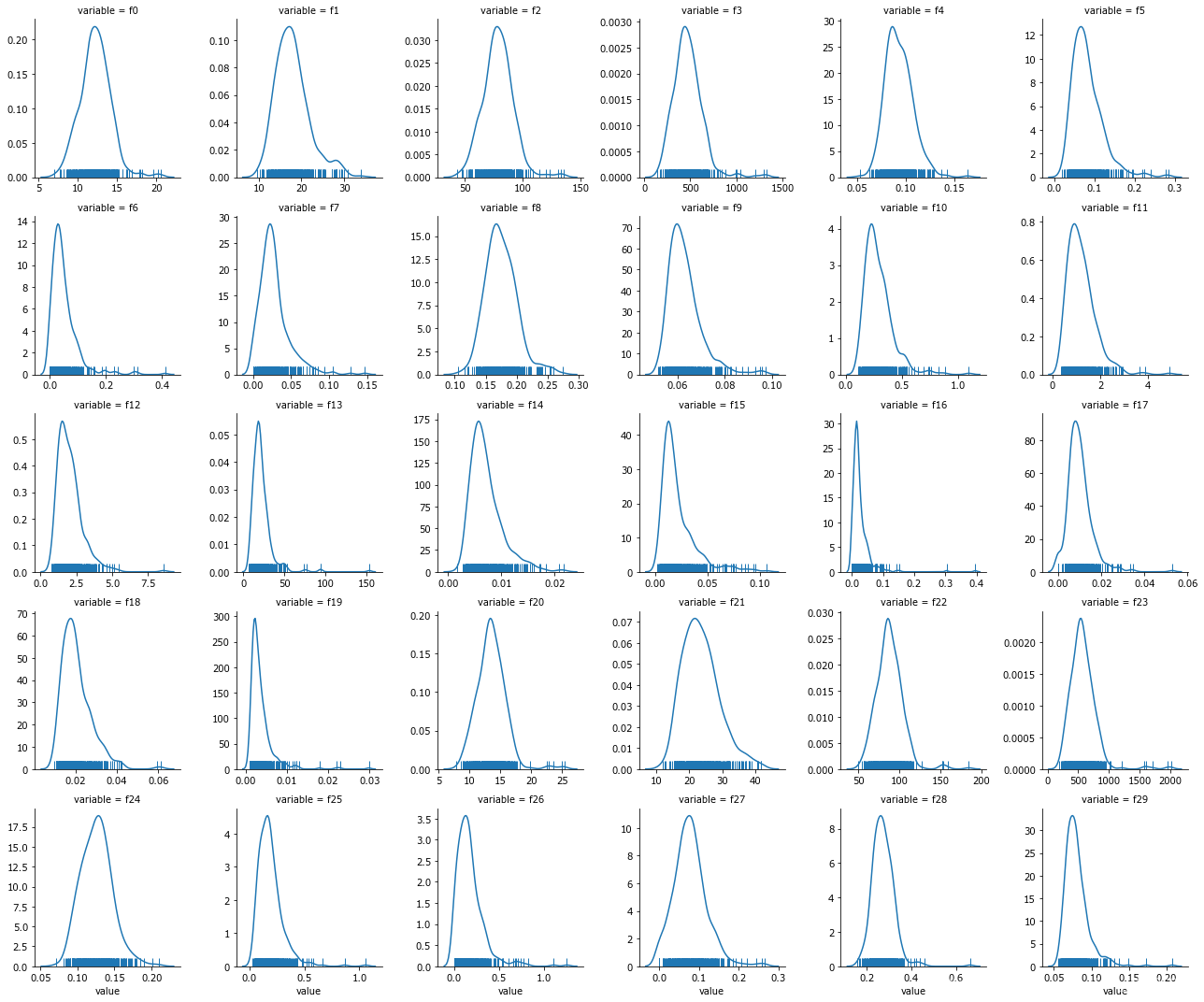
##每个数字特征得分布可视化
f = pd.melt(Train_data, value_vars=numeric_features)
g = sns.FacetGrid(f, col=“variable”,col_wrap=6, sharex=False, sharey=False)
g = g.map(sns.distplot, “value”, hist=False, rug=True)
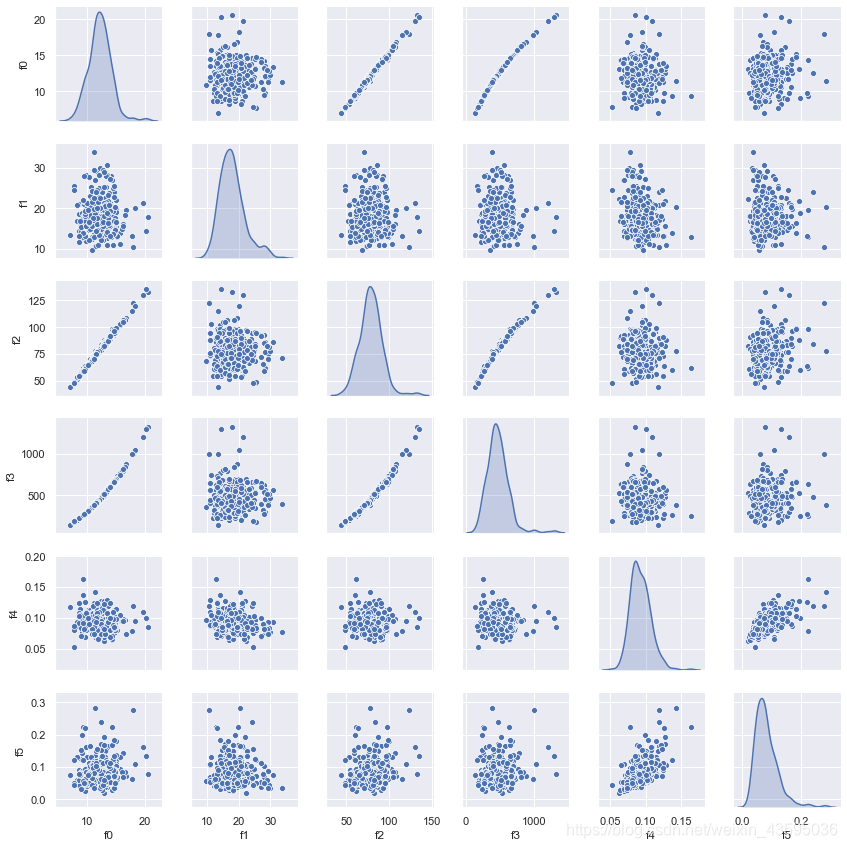
sns.set()
#因为30个特征生成两两之间的相关性图有30x30 共900个子图,子图看起来很密,也比较吃配置。
#所以这里只展示前6个特征两两之间的相关性。
sns.pairplot(Train_data[numeric_features[:6]],size = 2 ,kind =‘scatter’,diag_kind=‘kde’)
plt.savefig(‘correlation.png’)
plt.show()
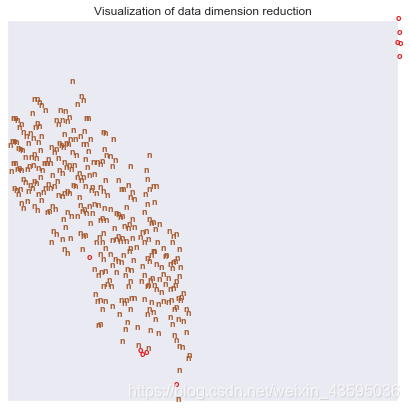
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, # 嵌入空间的维度(嵌入空间的意思就是结果空间)
init=‘pca’, # 嵌入空间的初始化,接收字符串‘random’,‘pca’或者一个numpy数组
random_state=0)
result = tsne.fit_transform(numeric)
x_min, x_max = np.min(result, 0), np.max(result, 0)
result = (result - x_min) / (x_max - x_min)
label = Train_data[‘label’]
fig = plt.figure(figsize = (7, 7))
#f , ax = plt.subplots()
color = {‘o’:0, ‘n’:7}
for i in range(result.shape[0]):
plt.text(result[i, 0], result[i, 1], str(label[i]),
color=plt.cm.Set1(color[label[i]] / 10.),
fontdict={‘weight’: ‘bold’, ‘size’: 9})
plt.xticks([])
plt.yticks([])
plt.title(‘Visualization of data dimension reduction’)
plt.show()
2.使用pyod库生成example并使用该库的pca模块进行检测
from pyod.models.pca import PCA
from pyod.utils.data import generate_data
from pyod.utils.data import evaluate_print
from pyod.utils.example import visualize
#Generate sample data
X_train, y_train, X_test, y_test =
generate_data(n_train=1000, # number of training points
n_test=250, # number of testing points
n_features=2,
contamination=0.05, # percentage of outliers
random_state=29)
#train one_class_svm detector
clf_name = ‘PCA’
clf = PCA()
clf.fit(X_train)
#get the prediction labels and outlier scores of the training data
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
#get the prediction on the test data
y_test_pred = clf.predict(X_test) # outlier labels (0 or 1)
y_test_scores = clf.decision_function(X_test) # outlier scores
#evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,y_test_pred, show_figure=True, save_figure=False)
On Training Data:
PCA ROC:0.997, precision @ rank n:0.94
On Test Data:
PCA ROC:0.9793, precision @ rank n:0.75
