问题提出
实际生产过程中,出产投入使用之前,经常会评价某些参数是否有异常,然后再判断是否要重新检测。评价并不是简单的根据特定参数的阈值来的,而是根据宏观上产出群体的所有参数分布得出的。
比如生成飞机引擎,震动和热量参数,对所有出产的引擎进行测试,得到如下分布:
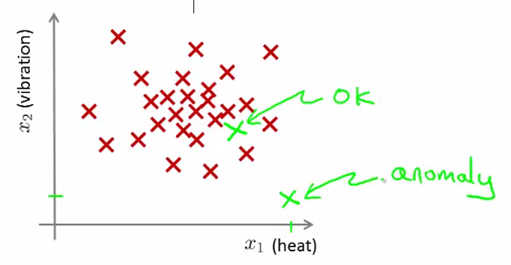
为了评价这种差异,定性分析如下:

高斯分布
从上面的直观感受、定性分析可知越接近中心区域的越不可能是异常。为了定量分析,引入高斯分布。即认为所有的参数符合高斯分布。数学表达为:X∽N(μ,σ2)” role=”presentation” style=”position: relative;”>X∽N(μ,σ2)X∽N(μ,σ2)为方差。
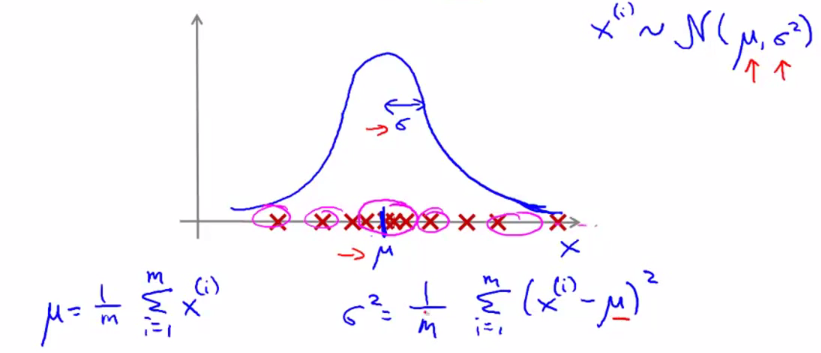
高斯分布的异常检测算法

开发和评估一个异常检测系统
- 训练、交叉检验、测试样本分配比例:
- 使用F1−score” role=”presentation” style=”position: relative;”>F1−scoreF1−score1公式进行评估
F1−score=2pqp+q” role=”presentation” style=”text-align: center; position: relative;”>F1−score=2pqp+qF1−score=2pqp+q
其中p” role=”presentation” style=”position: relative;”>pp分别表示查准率和召回率。

异常检测和有监督学习对比
- 特性区别
| 异常检测 | 有监督学习 |
| 正样本比较少 | 正样本充足 |
| 异常类型很多,且不可预测 | 待检测的正样本与已检测过的相似 |
- 使用场景区别
| 异常检测 | 有监督学习 |
| 欺骗检测 | 垃圾邮件分类 |
| 制造业质检 | 天气预测 |
| 动力环境监测 | 癌症分类 |
| …. | …. |
选择用什么属性
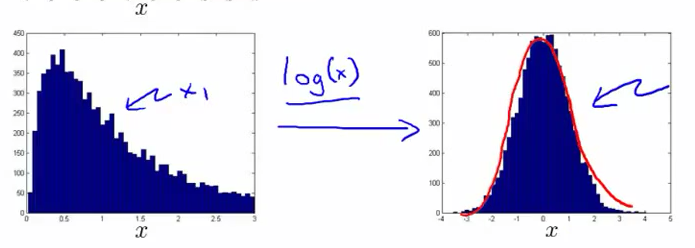
调整属性,以满足高斯分布。如下图,先得到所有样本某一属性x1” role=”presentation” style=”position: relative;”>x1x1取对数:
多变量高斯分布
直接用与样本中心点的距离来评价是否异常有时候不准确,如下图:
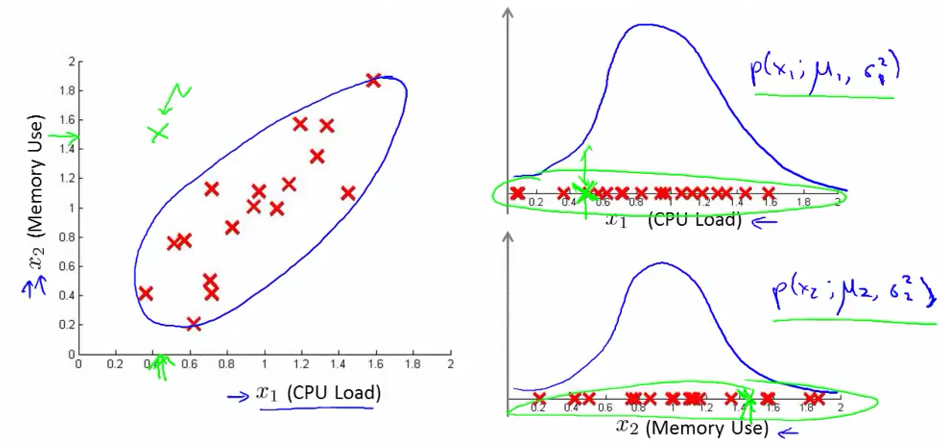
图中绿色的点距离样本中心比较近,其中右边两个图为样本在两维度的投影。但是直观感觉也是应该检测出的异常点。为了应对这种情形,引入了多变量高斯分布。
多变量高斯分布,对应不同的均值μ” role=”presentation” style=”position: relative;”>μμ特性如下图:

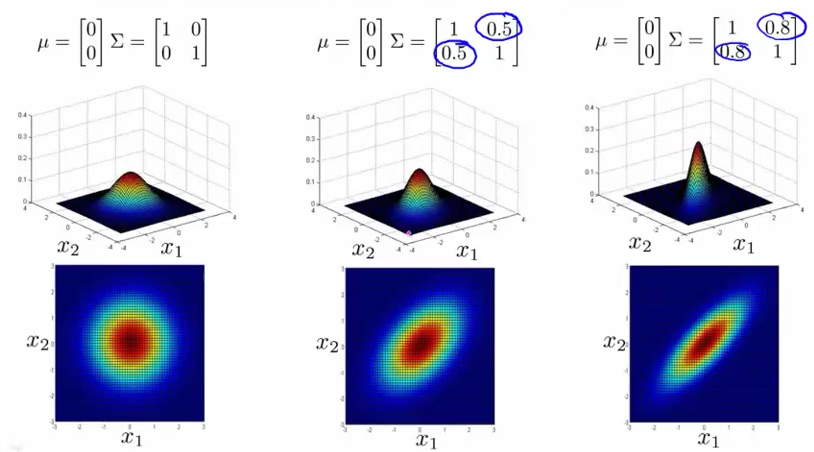
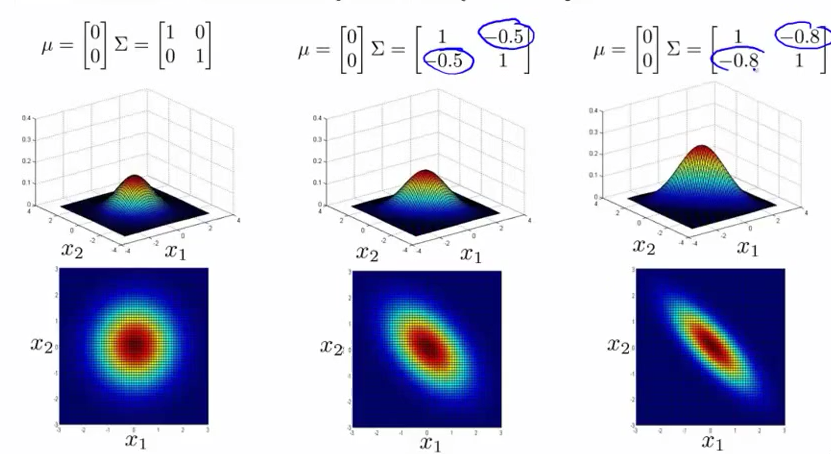
多变量高斯分布的概率公式:
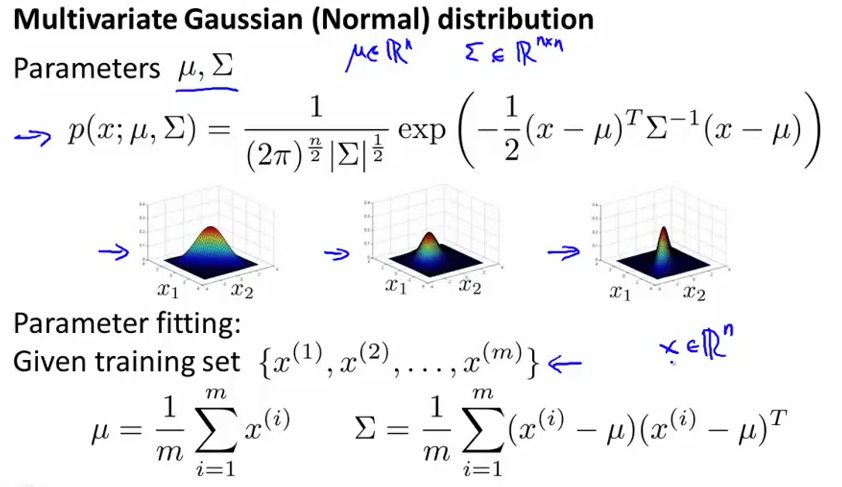
使用多变量高斯分布进行异常检测

| 多变量连乘模型 | 多变量高斯模型 |
| 需要手工设置新属性以求相关属性参数比例不对的,比如CPUloadmemory” role=”presentation” style=”position: relative;”>CPUloadmemoryCPUloadmemory | 自动获取关联属性表现 |
| 计算简单 | 计算耗时,需要计算Σ−1” role=”presentation” style=”position: relative;”>Σ−1Σ−1 |
| 即使属性数n” role=”presentation” style=”position: relative;”>nn很小,算法也可以跑起来 | 必须n<m” role=”presentation” style=”position: relative;”>n<mn<m无解 |