-
自回归模型的定义
自回归模型(Autoregressive Model)是用自身做回归变量的过程,即利用前期若干时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型[1],它是时间序列中的一种常见形式[2]。

-
AR模型的状态空间形式(AR-Process in State Space Form)
AR模型可以写成状态空间模型的形式[4] [5] [6],令:

-
AR模型的求解
AR模型可以采用Yule-Walker方程的形式进行求解[3]。考虑p阶AR模型有相应的AR特征多项式和相应的AR特征方程:


-
AR模型示例

5 Python对模型参数的求解
这里加上一点自己在运用模型时的感受,在实际我在运用AR模型进行时序数据的预测时,最常见有两个板块:
(一)AR 模型的判定:
这一部分的主要任务是,判断该问题是否适用 AR 模型建模,以及大致确定阶数 p。
如果一个时间序列满足以下两个条件:
- ACF 具有拖尾性,即 ACF(k) 不会在 k 大于某个常数之后就恒等于 0。
- PACF 具有截尾性,即 PACF(k) 在 k>p 时变为 0。
第 2 个条件还可以用来确定阶数 p。考虑到存在随机误差的存在,因此 PACF 在 p 阶延迟后未必严格为 0 ,而是在 0 附近的小范围内波动。
例如:

从图中可以看出:1, 2, 4, 8, 20 都可以采用, 进一步理解就是要采用多少阶的模型比如AR(1), AR(2)….但是有一点,从AR模型公式看,当阶越大,数据处理难度越高。
(二) AR 模型的参数估计:
1. 模型的有效性检验:
一个好的拟合模型应该能够提取观测值序列中几乎所有的样本相关信息,即残差序列应该为白噪声序列。因此,模型的有效性检验即为残差序列的白噪声检验。如果残差序列是白噪声,那么理论赏其延迟任意阶的自相关系数为 0,考虑数据的偏差,那么绝大多数应该在 0 附近的范围内,通常在 95% 的置信水平(2倍标准差)以内。
2. 参数的显著性检验
这一部分的目标是,删除那些不显著参数使模型结构最为精简。对于模型参数 aj(j=1,…,p) 的检验,其原假设和备择假设分别为
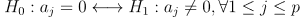
检验统计量为 t 统计量:
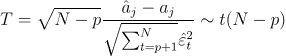
在给定的显著水平 α 下,当检验统计量 T 大部分位于分点 t 1 − α / 2 t_1-α/2 t1−α/2,或该统计量的 P 值小于 α 时,则可以以 1-α 的置信水平拒绝原假设,认为模型参数显著。反之,则不能显著拒绝参数为 0 的假设。
通过python程序可以得到:
import matplotlib.pyplot as plt
import pandas as pd
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf #自相关图
def adf_test(ts):
'''
参数值:
1.t统计量的值
2.t统计量的P值
3.延迟阶数
4.ADF回归和计算的观测值的个数
5.配合第一个一起看的,是在99%,95%,90%置信区间下的临界的ADF检验的值
'''
adftest = adfuller(ts, autolag='AIC')
adf_res = pd.Series(adftest[0:4],
index=['Test Statistic','p-value','Lags Used','Number of Observations Used'])
for key, value in adftest[4].items():
adf_res['Critical Value (%s)' % key] = value
return adf_res
inputfile = 'D:/Python/Python_learning/Mach_model/AR_model/data.xlsx' #销量及其他属性数据
data = pd.read_excel(inputfile, index_col = u'时间')
#发现图片有明显的递增趋势,可以判断是非平稳的序列
data_drop = data.dropna() #将数据data dropna()
plot_acf(data_drop) #自相关图
plt.show()
adf_res = adf_test(data)
print(adf_res)程序结果:
运用AR模型后的参数
Test Statistic 1.816580
p-value 0.998381
Lags Used 10.000000
Number of Observations Used 26.000000
Critical Value (10%) -2.630095
Critical Value (5%) -2.981247
Critical Value (1%) -3.711212
dtype: float64从模型中可以看出“Lags Used ”也就是延迟阶数为:10,算是比较大的阶数。
同时,可以绘制出它的自相关图:
