基于视频的行人重识别-02
1.前言
这一节主要解释下数据的导入,模型的训练需要数据的支持,那么我们就需要对数据进行预处理以及数据的输入。
对于数据量比较少的时候,我们可以采用手动输入的形式,但当数据量较大时,这种方式就效率太低了。
我们需要使用 shuffle, 分割成mini-batch 等操作的时候,我们可以使用PyTorch的API快速地完成这些操作(Dataloader)。
DataLoader 是 torch 提供用来包装数据的工具,我们需要将自己的 (numpy array 或其他) 数据形式装换成 Tensor, 然后再放进这个包装器中使用。
Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。
在前一节,我们已经实现了将mars数据集封装到dataset中,接下来我们要重写dataset方法,按照我们想要的方式将数据传递给Dataloader。
2 重写dataset
对于行人重识别和VIdeo-base ReID 在这个部分有所区别。
2.1导入包
from __future__ import print_function, absolute_import
import os
from PIL import Image
import numpy as np
import torch
from torch.utils.data import Dataset
import random
# import data_manager
# import torchvision.transforms as T
# from torch.utils.data import DataLoader
# from torch.autograd import Variable
2.2读取图片方法
def read_image(img_path):
"""Keep reading image until succeed.
This can avoid IOError incurred by heavy IO process."""
got_img = False
while not got_img:
try:
img = Image.open(img_path).convert('RGB')
got_img = True
except IOError:
print("IOError incurred when reading '{}'. Will redo. Don't worry. Just chill.".format(img_path))
pass
return img
2.3重写dataset
当我们集成了一个 Dataset类之后,我们需要重写init、len、getitem 方法,
- init主要是获取一些必要的参数
- len方法提供了dataset的大小;
- getitem 方法, 该方法支持从 0 到 len(self)的索引
# 这个方法可以用于常见的基于视频重识别的数据集
class VideoDataset(Dataset):
"""Video Person ReID Dataset.
Note batch data has shape (batch, seq_len, channel, height, width).
"""
# 枚举读取方法
sample_methods = ['evenly', 'random', 'all']
# 重写init 在创建类对象时调用
def __init__(self, dataset, seq_len=15, sample='evenly', transform=None):
# dataset为上一节mars对象
self.dataset = dataset
# seq——len 默认为15 项目中一般为4
self.seq_len = seq_len
# 采样方式
self.sample = sample
# 数据增强方式
self.transform = transform
# 返回dataset的大小
def __len__(self):
return len(self.dataset)
# 从 0 到 len(self)的索引
def __getitem__(self, index):
#print(index, len(self.dataset))
img_paths, pid, camid = self.dataset[index]
num = len(img_paths)
# 训练集 输入
if self.sample == 'random':
"""
Randomly sample seq_len consecutive frames from num frames,
if num is smaller than seq_len, then replicate items.
This sampling strategy is used in training phase.
"""
# 从n帧里挑出连续的seq帧作为样本
frame_indices = list(range(num))
rand_end = max(0, len(frame_indices) - self.seq_len - 1)
begin_index = random.randint(0, rand_end)
end_index = min(begin_index + self.seq_len, len(frame_indices))
indices = frame_indices[begin_index:end_index]
# 如果indices帧数不足seq,使用indices补全
for index in indices:
if len(indices) >= self.seq_len:
break
indices.append(index)
indices=np.array(indices)
# 这里准备数组 就是要把img拼接在一起
imgs = []
for index in indices:
index=int(index)
img_path = img_paths[index]
img = read_image(img_path)
if self.transform is not None:
img = self.transform(img)
img = img.unsqueeze(0)
imgs.append(img)
# imgs = [s,c,h,w]
imgs = torch.cat(imgs, dim=0)
#imgs=imgs.permute(1,0,2,3)
return imgs, pid, camid
# 测试集输入
elif self.sample == 'dense':
"""
Sample all frames in a video into a list of clips, each clip contains seq_len frames, batch_size needs to be set to 1.
This sampling strategy is used in test phase.
"""
cur_index=0
frame_indices = list(range(num))
indices_list=[]
# 训练和测试的不同就在于测试需要分析每一张图片
while num-cur_index > self.seq_len:
# 每次向list中添加seq长度的list
indices_list.append(frame_indices[cur_index:cur_index+self.seq_len])
cur_index+=self.seq_len
last_seq=frame_indices[cur_index:]
# 最后不足4个 补全
for index in last_seq:
if len(last_seq) >= self.seq_len:
break
last_seq.append(index)
# imdices——list = [(0,4),(4,8),...]
indices_list.append(last_seq)
imgs_list=[]
for indices in indices_list:
imgs = []
for index in indices:
index=int(index)
img_path = img_paths[index]
img = read_image(img_path)
if self.transform is not None:
img = self.transform(img)
img = img.unsqueeze(0)
imgs.append(img)
# imgs =[s,c,h,w]
imgs = torch.cat(imgs, dim=0)
#imgs=imgs.permute(1,0,2,3)
# imgs_list = [1,s,c,h,w]
imgs_list.append(imgs)
imgs_array = torch.stack(imgs_list)
return imgs_array, pid, camid
else:
raise KeyError("Unknown sample method: {}. Expected one of {}".format(self.sample, self.sample_methods))
3结果test解释
3.1 训练集导入
# test
if __name__ == "__main__":
dataset =data_manager.init_dataset(name="mars")
transform_train = T.Compose([
T.Resize((224, 112)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]),
])
trainloader = DataLoader(
VideoDataset(dataset.train, seq_len=4, sample='random', transform=transform_train),
batch_size=32, shuffle=True, num_workers=1,
pin_memory=False, drop_last=False,
)
# queryloader = VideoDataset(dataset.query,sample='dense',seq_len=16,transform=transform_test)
for batch_idx, (imgs, pids, camids) in enumerate(trainloader):
imgs = Variable(imgs, volatile=True)
print(imgs.size())
# b=1, n=number of clips, s=seq
b, s, c, h, w = imgs.size()
print(b,s,c,h,w)
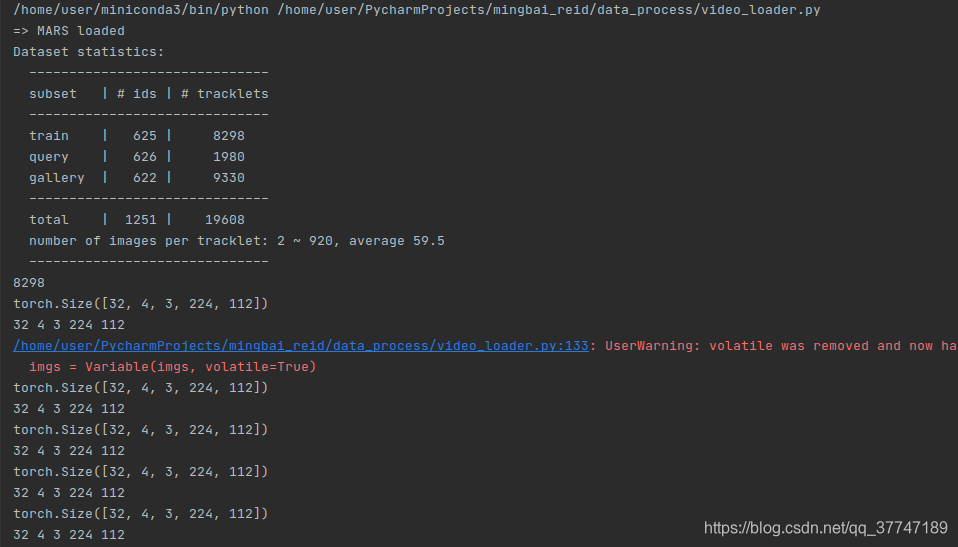
- dataset长度为8298,对应训练集tracklets的个数
- imgs的大小为imgs.Size([32, 4, 3, 224, 112]) 对应[b,s,c,h,w]
3.2 query数据集导入
# test
if __name__ == "__main__":
dataset =data_manager.init_dataset(name="mars")
transform_test = T.Compose([
T.Resize((224, 112)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]),
])
trainloader = DataLoader(
VideoDataset(dataset.query, seq_len=4, sample='dense', transform=transform_test),
batch_size=1, shuffle=False, num_workers=4,
pin_memory=False, drop_last=False,
)
# queryloader = VideoDataset(dataset.query,sample='dense',seq_len=16,transform=transform_test)
for batch_idx, (imgs, pids, camids) in enumerate(trainloader):
imgs = Variable(imgs, volatile=True)
print(imgs.size())
# b=1, n=number of clips, s=seq
b,n, s, c, h, w = imgs.size()
print(b,s,c,h,w)
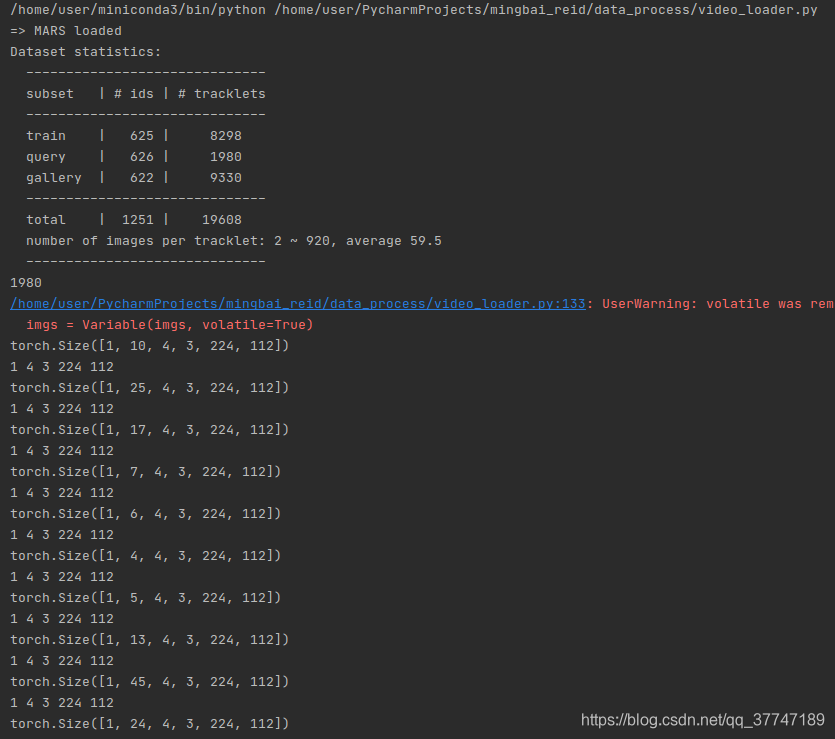
- 1980为query的tracklets
- imgs_arrays.size() = [1,10,4,3,224,112] # [b,n,s,c,h,w ]
- 第一个tracks含有39张图片,每4张为一个seq,所以有n=10
3.3 gallery数据集的导入
# test
if __name__ == "__main__":
dataset =data_manager.init_dataset(name="mars")
transform_test = T.Compose([
T.Resize((224, 112)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]),
])
trainloader = DataLoader(
VideoDataset(dataset.gallery, seq_len=4, sample='dense', transform=transform_test),
batch_size=1, shuffle=False, num_workers=1,
pin_memory=False, drop_last=False,
)
# queryloader = VideoDataset(dataset.query,sample='dense',seq_len=16,transform=transform_test)
for batch_idx, (imgs, pids, camids) in enumerate(trainloader):
imgs = Variable(imgs, volatile=True)
print(imgs.size())
# b=1, n=number of clips, s=seq
b,n, s, c, h, w = imgs.size()
print(b,n,s,c,h,w)
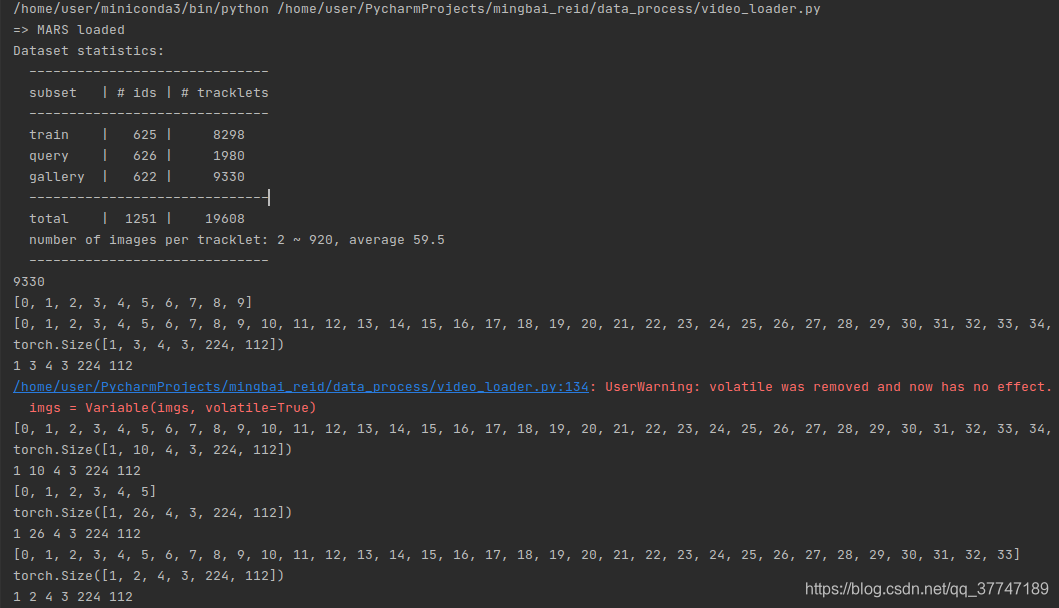
- gallery数据集共有9330个tracklets
- imgs.size() = [1,3,4,3,224,112] ## [b,n,s,c,h,w ]
- 和query数据集基本一致