基于视频的行人重识别-01
1.认识mars数据集
研究视频行人重识别基本上都绕不过mars数据集,作为视频行人重识别比较认可的数据集,各个顶刊的优秀论文都是在提高mars数据集的rank。
那么首先,让我们来认识一下这个数据集:
数据集地址
info文件
我们把上面链接中的内容下载下来,然后解压后按照下列这种方式保存:
 那么接下来,解释一下这些文件夹中的内容:
那么接下来,解释一下这些文件夹中的内容:
1.1 bbox_train
bbox_train文件夹中,有625个子文件夹(代表着625个行人id),共包含了8298个小段轨迹(tracklets),总共包含509,914张图片。
 注意一点:这里文件夹的名字不是连续的!
注意一点:这里文件夹的名字不是连续的!
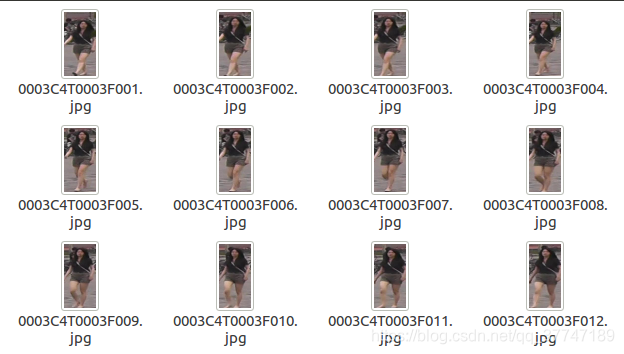
打开任意一个文件夹可以看到这些内容:(文件名后边会解释)
1.2 bbox_test
bbox_test文件夹中共有636个子文件夹(代表着636个行人id),共包含了12180个小段轨迹(tracklets),总共包含681,089张图片。在实验中这个文件夹被划分为图库集(gallery)+ 查询集(query)。在info文件夹中会解释这件事。
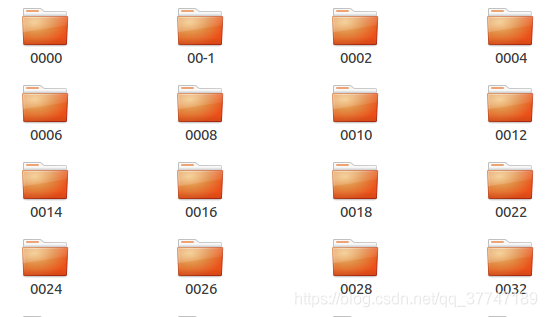 注意也都不是连续的!!!!
注意也都不是连续的!!!!
名称为00-1子文件夹表示无用的图片集,他们对应的行人id被设为**-1**,一般在算法中直接无视pid = -1的图片。

而名称0000子文件夹中,他们对应的行人id被设为0,表示干扰因素,对检索准确性产生负面影响。
1.3 info
info文件夹中包含了5个子文件,包含了整个数据集的信息,目的是方便使用数据集。
1.3.1 train_name.txt
这个txt文件里,按照顺序存放bbox_train文件夹里所有图片的名称,一共有509,914行(对应509914张图片)。
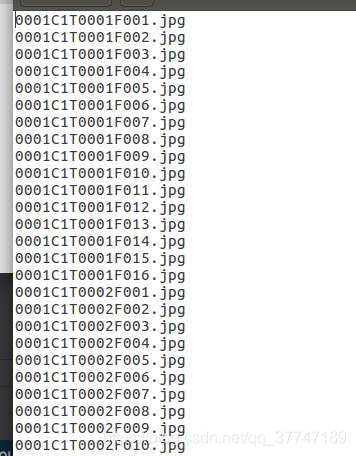 图片名称解释:
图片名称解释:
0001 C1 T0001 F0001.jpg为例。
0001表示的行人的id,也就是 bbox_train文件夹中对应的 0001子文件夹名;
C1表示摄像头的id,说明这张图片是在第1个摄像头下拍摄的(一共有6个摄像头);
T0001表示关于这个行人视频段中的第1个小段视频(tracklet);
F0001表示在这张图片是在这个小段视频(tracklet)中的第1帧。在每个小段视频(tracklet)中,帧数从 F0001开始。
1.3.2 test_name.txt
同样地,在这个txt文件中,按照顺序存放bbox_test文件夹里所有图片的名称,一共有681,089行。
1.3.3 tracks_train_info.mat
.mat格式的文件是matlab保存的文件,用matlab打开后可以看到是一个8298 * 4的矩阵。
矩阵每一行代表着一个tracklet(轨迹);
第一列和第二列代表着图片的序号(开始、结束),这个序号与 train_name.txt文件中的行号一一对应;
第三列是行人的id,也就是 bbox_train文件夹中对应的 子文件夹名;
第4列是对应的摄像头id(一共有6个摄像头)。
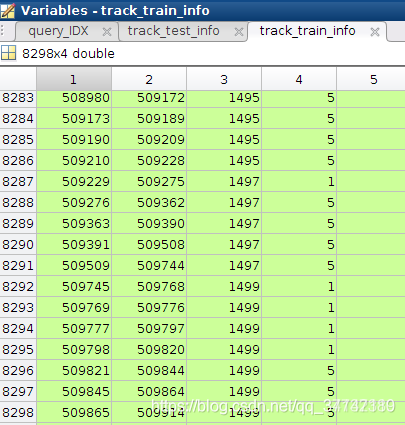
 注意对照两张图片~
注意对照两张图片~
1.3.4 tracks_train_info.mat
这个文件用matlab打开后可以看到是一个12180 * 4的矩阵。
矩阵每一行代表着一个tracklet;
第一列和第二列代表着图片的序号,这个序号与 test_name.txt 文件中的行号一一对应;
第三列是行人的id,也就是 bbox_test文件夹中对应的 子文件夹名;;
第4列是对应的摄像头id(一共有6个摄像头)。
和上面的类似~
1.3.5 query_IDX.mat
这个文件用matlab打开后可以看到是一个1 * 1980的矩阵(挑了1980个查询id),可以看到每一列是对应上面 tracks_test_info.mat文件中的第几行。
比如1978列中的值为12177,对应的是 tracks_test_info.mat文件中的第12177行(一行对应一个tracks)。
而12177行中,可以看到其id=1496(行人id)。不难发现同样id=1496的行还有12166, 12167等(一个行人对应了多段轨迹)。
其实这说明在 名称为1496子文件夹中(行人id为1496),有多个小段视频(tracklet)。
值得注意的是, 并不是所有查询集的id,图库都有对应的相同id行人的行。在1980个查询id中,有效的id(在图库中存在相同id的行)数 = 1840。
也就是说,有些文件夹里只有1个tracklet。

1.4 总结
总的来说 :
- 一个训练集会对应多个行人id,一个id会对应多个tracks,一个tracks又对应着多张图片。
- 训练集和测试级没有重复的行人id
- 测试集中挑选的部分作为query
2.mars数据集管理data_manager
前面介绍行人重识别的时候,也同样有这一部分,目地在于把硬盘中的mars数据集,封装到dataset中。
方法大多数都相同,就直接贴代码了:
# 导入相关包
from __future__ import print_function, absolute_import
import os
import glob
import re
import sys
import urllib
import tarfile
import zipfile
import os.path as osp
from scipy.io import loadmat
import numpy as np
import random
from utils.util import mkdir_if_missing, write_json, read_json
"""Dataset classes"""
# 定义类方法
class Mars(object):
"""
MARS
Reference:
Zheng et al. MARS: A Video Benchmark for Large-Scale Person Re-identification. ECCV 2016.
Dataset statistics:
# identities: 1261
# tracklets: 8298 (train) + 1980 (query) + 9330 (gallery)
# cameras: 6
Args:
min_seq_len (int): tracklet with length shorter than this value will be discarded (default: 0).
"""
# 设置mars路径 这个要根据自己文件夹中存放数据集的位置
root = '/home/user/桌面/code/data/mars'
# 读取对应文件夹路径
train_name_path = osp.join(root, 'info/train_name.txt')
test_name_path = osp.join(root, 'info/test_name.txt')
track_train_info_path = osp.join(root, 'info/tracks_train_info.mat')
track_test_info_path = osp.join(root, 'info/tracks_test_info.mat')
query_IDX_path = osp.join(root, 'info/query_IDX.mat')
# 初始化类方法
def __init__(self, min_seq_len=0):
# 1 提高工程性 确保文件都存在
self._check_before_run()
# 2 prepare meta data
# 获得所有的训练集图片名字,放在train_names列表中;
# 获取所有测试集图片名字,放在test_names 列表中。
train_names = self._get_names(self.train_name_path)
test_names = self._get_names(self.test_name_path)
# 使用loadmat()函数读取.mat文件,它读取出来的data是字典格式的,通过['track_train_info']这个key,找到对应的value。获得的是一个数组格式数据。
track_train = loadmat(self.track_train_info_path)['track_train_info'] # numpy.ndarray (8298, 4) 8298tracks 4:start、end、id、cid
track_test = loadmat(self.track_test_info_path)['track_test_info'] # numpy.ndarray (12180, 4) 12180tracks 4:start、end、id、cid
query_IDX = loadmat(self.query_IDX_path)['query_IDX'].squeeze() # numpy.ndarray (1980,)
# 查询集的行号减一,跟track_test中的行号索引保持一致。
query_IDX -= 1 # index from 0
# 根据 query_IDX行号索引,找到track_test中对应行的数据 numpy.ndarray (1980, 4)
track_query = track_test[query_IDX,:]
# 图库集的行号 = 原始的track_test行号 - query_IDX中包含的行号
gallery_IDX = [i for i in range(track_test.shape[0]) if i not in query_IDX]
# 根据图库集行号,在track_test中找到对应行的数据,numpy.ndarray (1980, 4)
track_gallery = track_test[gallery_IDX,:]
# 3 数据处理
train, num_train_tracklets, num_train_pids, num_train_imgs = \
self._process_data(train_names, track_train, home_dir='bbox_train', relabel=True, min_seq_len=min_seq_len)
query, num_query_tracklets, num_query_pids, num_query_imgs = \
self._process_data(test_names, track_query, home_dir='bbox_test', relabel=False, min_seq_len=min_seq_len)
gallery, num_gallery_tracklets, num_gallery_pids, num_gallery_imgs = \
self._process_data(test_names, track_gallery, home_dir='bbox_test', relabel=False, min_seq_len=min_seq_len)
num_imgs_per_tracklet = num_train_imgs + num_query_imgs + num_gallery_imgs
min_num = np.min(num_imgs_per_tracklet)
max_num = np.max(num_imgs_per_tracklet)
avg_num = np.mean(num_imgs_per_tracklet)
num_total_pids = num_train_pids + num_query_pids
num_total_tracklets = num_train_tracklets + num_query_tracklets + num_gallery_tracklets
print("=> MARS loaded")
print("Dataset statistics:")
print(" ------------------------------")
print(" subset | # ids | # tracklets")
print(" ------------------------------")
print(" train | {:5d} | {:8d}".format(num_train_pids, num_train_tracklets))
print(" query | {:5d} | {:8d}".format(num_query_pids, num_query_tracklets))
print(" gallery | {:5d} | {:8d}".format(num_gallery_pids, num_gallery_tracklets))
print(" ------------------------------")
print(" total | {:5d} | {:8d}".format(num_total_pids, num_total_tracklets))
print(" number of images per tracklet: {} ~ {}, average {:.1f}".format(min_num, max_num, avg_num))
print(" ------------------------------")
self.train = train
self.query = query
self.gallery = gallery
self.num_train_pids = num_train_pids
self.num_query_pids = num_query_pids
self.num_gallery_pids = num_gallery_pids
# 检验文件是否存在
def _check_before_run(self):
"""Check if all files are available before going deeper"""
if not osp.exists(self.root):
raise RuntimeError("'{}' is not available".format(self.root))
if not osp.exists(self.train_name_path):
raise RuntimeError("'{}' is not available".format(self.train_name_path))
if not osp.exists(self.test_name_path):
raise RuntimeError("'{}' is not available".format(self.test_name_path))
if not osp.exists(self.track_train_info_path):
raise RuntimeError("'{}' is not available".format(self.track_train_info_path))
if not osp.exists(self.track_test_info_path):
raise RuntimeError("'{}' is not available".format(self.track_test_info_path))
if not osp.exists(self.query_IDX_path):
raise RuntimeError("'{}' is not available".format(self.query_IDX_path))
# 获取txt文件中的字符串(图片名字),放在names列表中。
def _get_names(self, fpath):
names = []
with open(fpath, 'r') as f:
for line in f:
new_line = line.rstrip()
names.append(new_line)
return names
# 对获得的数据按照规则进行截断 获得tracklets, num_tracklets, num_pids, num_imgs_per_tracklet
def _process_data(self, names, meta_data, home_dir=None, relabel=False, min_seq_len=0):
assert home_dir in ['bbox_train', 'bbox_test']
num_tracklets = meta_data.shape[0]
pid_list = list(set(meta_data[:,2].tolist()))
num_pids = len(pid_list)
if relabel: pid2label = {
pid:label for label, pid in enumerate(pid_list)}
tracklets = []
num_imgs_per_tracklet = []
#txt_name = self.root + home_dir + str(len(meta_data)) + '.txt'
#fid = open(txt_name, "w")
for tracklet_idx in range(num_tracklets):
data = meta_data[tracklet_idx,...]
start_index, end_index, pid, camid = data
if pid == -1: continue # junk images are just ignored
assert 1 <= camid <= 6
if relabel: pid = pid2label[pid]
camid -= 1 # index starts from 0
img_names = names[start_index-1:end_index]
# make sure image names correspond to the same person
pnames = [img_name[:4] for img_name in img_names]
assert len(set(pnames)) == 1, "Error: a single tracklet contains different person images"
# make sure all images are captured under the same camera
camnames = [img_name[5] for img_name in img_names]
assert len(set(camnames)) == 1, "Error: images are captured under different cameras!"
# append image names with directory information
img_paths = [osp.join(self.root, home_dir, img_name[:4], img_name) for img_name in img_names]
if len(img_paths) >= min_seq_len:
img_paths = tuple(img_paths)
tracklets.append((img_paths, pid, camid))
num_imgs_per_tracklet.append(len(img_paths))
#fid.write(img_names[0] + '\n')
#fid.close()
num_tracklets = len(tracklets)
return tracklets, num_tracklets, num_pids, num_imgs_per_tracklet
"""Create dataset"""
__factory = {
'mars': Mars,
'ilidsvid': iLIDSVID,
'prid': PRID,
}
def get_names():
return __factory.keys()
def init_dataset(name, *args, **kwargs):
if name not in __factory.keys():
raise KeyError("Unknown dataset: {}".format(name))
return __factory[name](*args, **kwargs)
# test
if __name__ == '__main__':
init_dataset(name="mars")
#dataset = Market1501()
#dataset = Mars()
结果:
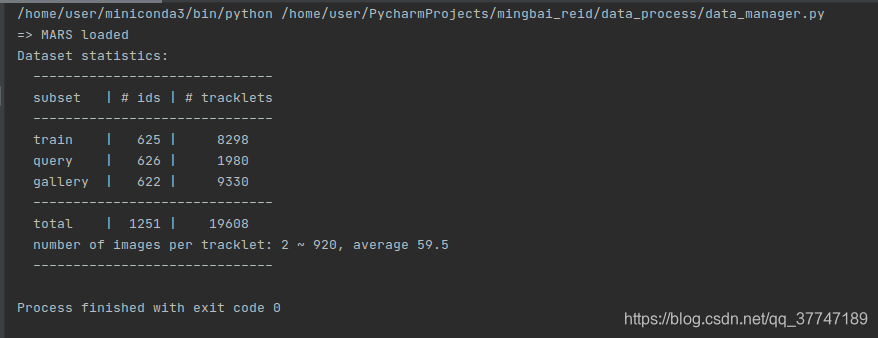 解释:
解释:
- 训练集:
- 625个id 总共8298个轨迹
- 测试集:
- query 626个id 挑选了1980个轨迹(不一定都有效 ,一个行人也可能只有一个tracks)
- gallery 622个id 剩下的9330个轨迹
总共1251个行人id,train+query ,轨迹数8298+1980+9330=19608个