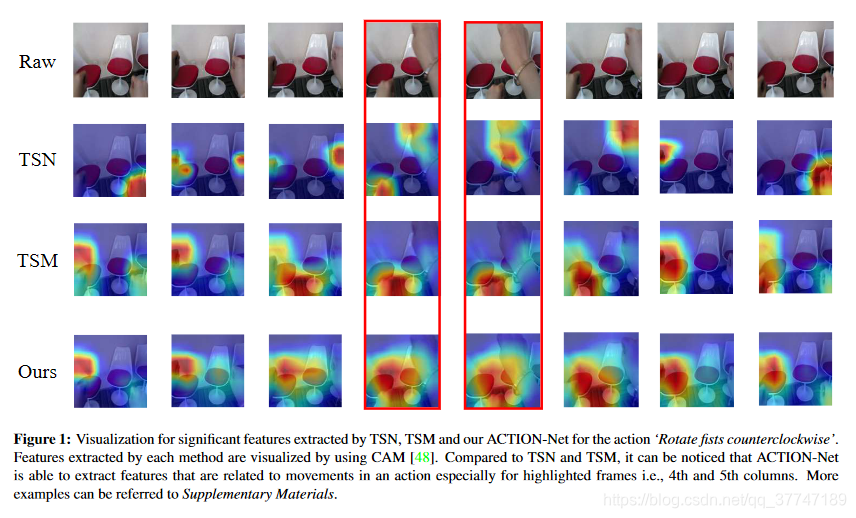
ACTION-Net: Multipath Excitation for Action Recognition
摘要
- 时空、信道、运动模式为视频动作识别的互补关键信息
- 2D不能捕捉时间信息,3D计算量大
- ACTION嵌入模块 包括三部分
- 时空激励STE路径 单通道三维卷积 表征时空特征
- 通道激励CE 自适应校准通道特征响应 显示建模通道之间的时间依赖
- 运动激励ME 计算特征级别的时间差异 激发运动敏感通道
- ACTION优于(resnet50、MobileNet v2、BNInception)
1.Introductions
贡献:
- 即插即用的动作模块
- 简单而有效的神经结构
- 在三个数据集上有优秀的性能
2.Related Works
2.1 3D-CNN框架
- I3D将ImageNet的2D卷积核换成了3D卷积核
- I3D使用双流架构表示运动模式
- 问题:参数多、过拟合、难聚合
2.2 2DCNN-based框架
- TSN均匀稀疏采样方案 直接使用2D cnn缺乏对视频序列的时间建模
- TSM 将部分频道的移位操作嵌入2Dcnn 缺乏对动作(相邻之间的差异)的显示建模
- 为2d cnn嵌入模块 MFNet、TEI Net、TEA
- STM 提出了一种用于建模时间和运动信息的快
- GSM利用群空间们控控制时空分解的相互作用
2.3 SENet
- SENet 想法在二维CNN嵌入挤压激励块
- SE以挤压和非挤压的方式利用两个FC,应用Sigmod激活基本通道特征 没有考虑到关键信息(时间属性)
- TEA 引入了ME(运动激励)和MTA(多重时间聚合)捕捉短期和长期时间金华
- 本文提出了超越SE的STE和CE,解决了时空视角和时间维度上的相互依赖
- 将STE、CE和ME以并行的方式组合成动作模块,激活视频中多种信息
Design of ACTION
符号解释:
- N–batch size
- T–number of segments
- C–channels
- H–height
- W–width
- r-- channel reduce radio
本文中,除了ACTION模型之外,所有的张量都是4维。
在输入ACTION之前,我们首先要把输入的4D张量重塑为5D张量(N,T,C,H,W)
然后,5D输出在被送入下一个2d卷积模块之前再被重塑为4D
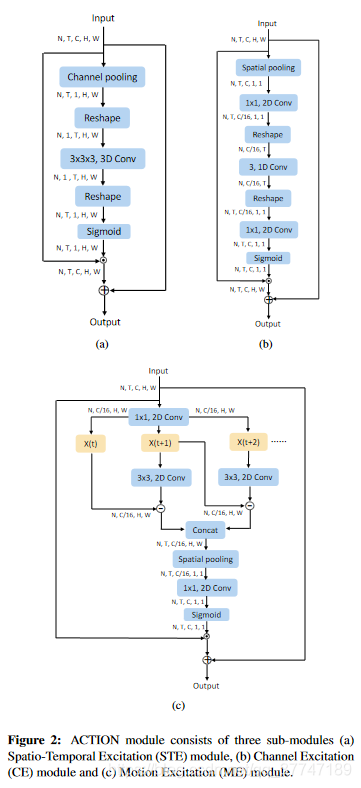
3.1Spatio-Temporal Excitation (STE)
SET是一种利用三维卷积来激发时空信息的有效方法,如图2(a)。
SET通过生成一个时空掩码 M ∈ R [ N , T , 1 , H , W ] M∈R^{[N,T,1,H,W]} M∈R[N,T,1,H,W]用于跨所有通道对输入 X ∈ R [ N , T , C , H , W ] X∈R^{[N,T,C,H,W]} X∈R[N,T,C,H,W]进行逐元素相乘。
如图2(a):
-
input: X ∈ R [ N , T , C , H , W ] X∈R^{[N,T,C,H,W]} X∈R[N,T,C,H,W]
-
对输入张量沿tchannels进行水平池化得到一个全局时空张量 F ∈ R [ N , T , 1 , H , W ] F∈R^{[N,T,1,H,W]} F∈R[N,T,1,H,W]
-
对F进行Reshape F ∈ R [ N , 1 , T , H , W ] F∈R^{[N,1,T,H,W]} F∈R[N,1,T,H,W]
-
将F输入到一个3×3×3的卷积层K中,可表示为:
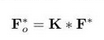
-
然后将 F o ∗ F^*_o Fo∗重构为 F o ∈ R [ N , T , 1 , H , W ] F_o∈R^{[N,T,1,H,W]} Fo∈R[N,T,1,H,W]
-
通过激活函数Sigmod 得到 M ∈ R [ N , T , 1 , H , W ] M∈R^{[N,T,1,H,W]} M∈R[N,T,1,H,W]
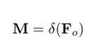
-
最终输出可以解释为:
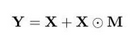
3.2Channel Excitation (CE)
CE的结构和图2 (b)所示的SE结构相似,CE和SE的区别是在两个FC层之间插入了一个一维卷积层来表征信道特征的时间信息。
-
给定输入: X ∈ R [ N , T , C , H , W ] X∈R^{[N,T,C,H,W]} X∈R[N,T,C,H,W]
-
空间平均池化 获取输入特征的空间信息,得到张量 F ∈ R [ N , T , C , 1 , 1 ] F∈R^{[N,T,C,1,1]} F∈R[N,T,C,1,1]
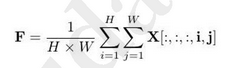
-
用压缩通道比r(r=16)来压缩F的通道数,表示为:
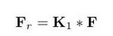
-
K 1 K_1 K1是一个1×1的卷积核, F r ∈ R [ N , T , C / r , 1 , 1 ] F_r∈R^{[N,T,C/r,1,1]} Fr∈R[N,T,C/r,1,1]
-
然后将 F r F_r Fr重构为 F r ∗ ∈ R [ N , C / r , T , 1 , 1 ] F^*_r∈R^{[N,C/r,T,1,1]} Fr∗∈R[N,C/r,T,1,1]
-
再使用内核大小为3的1维卷积核 K 2 K_2 K2来处理 F r ∗ F^*_r Fr∗
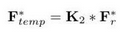
-
得到 F t e m p ∗ ∈ R [ N , C / r , T , 1 , 1 ] F^*_{temp}∈R^{[N,C/r,T,1,1]} Ftemp∗∈R[N,C/r,T,1,1],reshape得到 F t e m p ∈ R [ N , T , C / r , 1 , 1 ] F_{temp}∈R^{[N,T,C/r,1,1]} Ftemp∈R[N,T,C/r,1,1]
-
再通过一个1×1的2D的卷积核 K 3 K_3 K3,并使用激活函数Sigmod激活,公式如下:
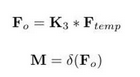
-
最后CE的输出公式和STE的输出公式相同
3.3Motion Excitation (ME)
ME的目的是基于特征级而不是像素级建模运动信息,本文将ME与前两节提到的两个模块来并行的使用。
具体结构如图2(c):
-
使用1×1的卷积核,采用与CE相同的压缩与解压缩策略。
-
运动特征按照如下操作进行:
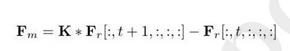
-
K是3×3的二维卷积层, F m ∈ R [ N , 1 , C / r , H , W ] F_{m}∈R^{[N,1,C/r,H,W]} Fm∈R[N,1,C/r,H,W],
-
对 F m F_m Fm根据时间维度运动特征进行拼接,并将0填充到最后一个元素
-
得到 F M ∈ R [ N , T , C / r , H , W ] F_{M}∈R^{[N,T,C/r,H,W]} FM∈R[N,T,C/r,H,W]
-
接着按照和前两个模块相似的操作,得到 M ∈ R [ N , T , C , 1 , 1 ] M∈R^{[N,T,C,1,1]} M∈R[N,T,C,1,1]
3.4 ACTION-Net
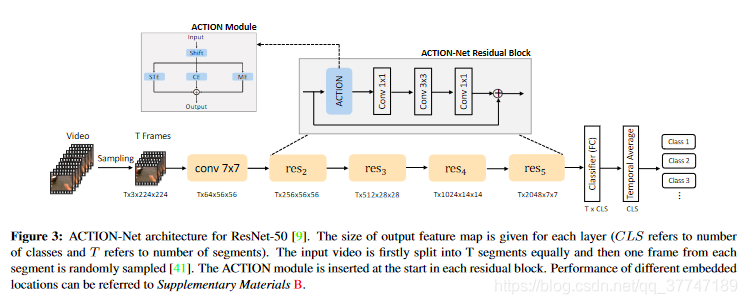
整体模块如上图所示,Resnet-50的ACTION-Net架构,不需要对块中的原始组件进行修改。