文章目录
1.概述
Redis当中的hash类似于java当中的HashMap,但也存在着很多的区别。在Redis当中,hash有两种底层实现方式。
- 当数据量较小的时候,采用zipList作为hash的底层实现,在上一篇该系列的博客当中详细介绍了zipList的实现。
- 另一种方式是使用字典dict来实现的。
本篇博客主要介绍dict的实现方式。
2.数据结构定义
2.1 字典dict
dict的结构定义如下:
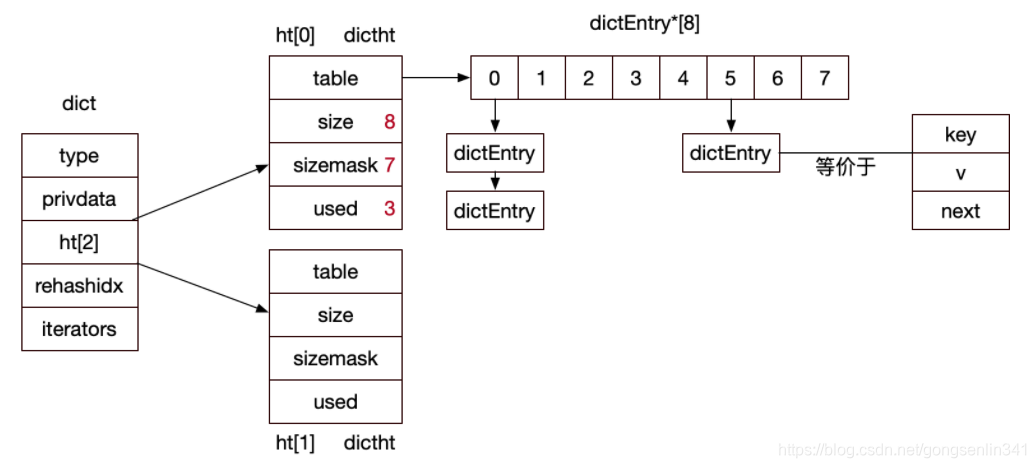
typedf struct dict{
dictType *type;//和特定类型键值对相关的函数;
void *privdata;//上述特定函数的可选参数;
dictht ht[2];//两张hash表
int rehashidx;//rehash索引,字典没有进行rehash时,此值为-1
unsigned long iterators; //正在迭代的迭代器数量
}dict;
- type 是一个指向 dict.h/dictType 结构的指针,保存了一系列用于操作特定类型键值对的函数;
- privdata 保存了需要传给上述特定函数的可选参数;
- ht[2] 两个hash表,使用两个hash表的作用之后会说明。
- rehashidx 用于标记rehash的进度,若当前这个值为-1,则表示字典没有在执行rehash操作。
- Iterators 记录正在迭代的迭代器的数量。
对于字典的结构有了初步印象之后,里面比较关键的dictht hash表的结构是怎样的呢?继续往下看!
2.2 哈希表ditcht
hash表的结构定义如下:
typedf struct dictht{
dictEntry **table;//存储数据的数组 二维
unsigned long size;//数组的大小
unsigned long sizemask;//哈希表的大小的掩码,用于计算索引值,总是等于size-1
unsigned long used; 哈希表中中元素个数
}dictht;
- table 是一个二维数组,第一维度数组表示hash表的槽位,第二个维度是每一个槽对应的链表。因为是采用拉链法来解决冲突的,所以存在相同槽位的数据,会以链表的形式连接在一起。
- size 表示数组的大小,也就是槽位的数量。
- sizemask 哈希表的大小的掩码,用于计算索引值。
- used 记录hash表中实际存放元素的个数。
二维数组的结构又是如何定义的呢?
2.3 真正的存储结构dictEntry
上面提到的二维数组dictEntry,是真正的存储key-value键值对的地方,结构定义如下:
typedf struct dictEntry{
void *key;//键
union{
void val;
unit64_t u64;
int64_t s64;
double d;
}v;//值
struct dictEntry *next;//指向下一个节点的指针
}dictEntry;
key表示键,v表示值
next是指向下一个结点的指针,因为这里的hash表是通过拉链法来解决冲突的。
下面是完整的dict字典的结构图
3. 扩容和缩容
hash表的扩容是为了减少hash冲突的概率,当hash表中的数据逐渐增多的时候,会导致冲突的概率增大,从而导致每个槽位下的链表的长度会变长。那么就会影响到查询的效率了。
而hash表的缩容是为了减少空间的消耗。Redis的数据是保存在内存当中的,若一个hash表占用很大的空间,里面的数据却很少,那么是极度的浪费,所以需要缩容操作。
在Java当中HashMap有负载因子0.75,当hash表当中实际的元素是hash表槽位的0.75倍的时候,会发生扩容。同样的,在Redis当中,也有负载因子的概念,计算公式是hash表中已保存结点的数量/hash表的长度。
也就是上面结构中提到的 factor = ht[0].used / ht[0].size
Redis中,有三条关于扩容和缩容的规则:
- 没有执行BGSAVE和BGREWRITEAOF指令的情况下,hash表的负载因子大于等于1的时候进行扩容。
- 正在执行BGSAVE和BGREWRITEAOF指令的情况下,hash表的负载因子大于等于5的时候进行扩容。
- 负载因子小于0.1的时候,Redis自动开始对Hash表进行缩容操作。
而不管缩容还是扩容,大小是有规定的,如下:
-
扩容:扩容后的dictEntry数组长度为第一个大于等于 ht[0].used * 2 的 2^n
也就是第一个大于等于已使用数量的两倍的2的幂次方。
-
缩容:缩容后的dictEntry数组长度为第一个大于等于 ht[0].used 的 2^n
也就是第一个大于等于已使用数量的2的幂次方。
4. rehash
第三节介绍了为何需要扩容缩容、扩容缩容的规则以及时机。下面将介绍扩容和缩容的过程,在Redis当中在扩容和缩容的时候,会执行rehash。
对比Java当中的HashMap的rehash,java当中需要新建一个hash表,然后一次性的将旧表里的数据进行rehash到新的hash表当中,之后在释放掉原油的hash表。而这一过程的时间复杂度达到了O(n)。
但是Redis是使用单线程的方式来执行请求命令的,所以无法接受一个时间复杂度为O(n)的操作,所以这就需要渐进式rehash。
渐进式,顾名思义也就是一步一步的进行rehash,将一个完整的rehash的过程给拆成多次取执行。
下面是完整的rehash的过程
- 首先当需要扩容或者缩容的时候,会根据上面提到的规则,在dictht[1]当中分配足够的空间。
- 然后在dict当中维护一个变量,也就是前面提到的rehashidx,用于标记rehash的进度,将其初始化为0,表示rehash正式开始。
- rehash进行期间,每次对字典执行添加、删除、查找或者更新操作的时候,除了执行指定的操作之外,还会顺带将dictht[0] hash表当中在rehashidx索引上的所有键值对进行rehash到dictht[1]当中,当一次rehash工作完成之后,会将rehashidx的值+1。
- 同时在循环时间事件serverCron当中,会调用rehash相关函数,在1ms的时间内,进行rehash处理,每次仅处理少量的转移任务(100个元素)
- 随着字典操作的不断执行,最终在某个时间点上,dictht[0]当中所有的键值对都会被rehash到dictht[1]当中,此时将rehashidx属性值设置为-1,表示rehash操作已经完成,将dictht[0]重新赋值dictht[1],接着清空dictht[1]。
想必在这个rehash过程当中,还有很多的疑问,rehash过程中,如何执行的增删改查呢?
- 增加操作:直接将数据添加到dictht[1]当中
- 修改操作:首先寻找数据在不在dictht[0]当中,若存在,则修改,否则去dictht[1]当中去找,若存在则修改。
- 删除操作:和上面修改一样,先要定位到元素所在哪个hash表当中,然后执行删除操作。
- 查找操作:和上面寻找的过程一样。
上面增删改查的操作,保证了dictht[0]当中的数据只会减少不增加,最终就没有数据了。
渐进式rehash的优缺点
优点:采用了分而治之的思想,将 rehash 操作分散到每一个对该哈希表的操作上以及定时函数上,避免了集中式rehash 带来的性能压力。
缺点:在 rehash 的时间内,需要保存两个 hash 表,对内存的占用稍大,而且如果在 redis 服务器本来内存满了的时候,突然进行 rehash 会造成大量的 key 被抛弃。
5. hash相关指令
5.1 hset/hsetnx
-
hset
使用方法:hset hash field value
将哈希表hash 中键为field的值设置为value

若当前hash表不存在,那么会新建一个哈希表并执行hset操作。返回1
若field键值对已经存在于哈希表中,新的value会覆盖旧值。返回0
-
hsetnx
使用方法:hsetnx hash field value
和上面的区别在于,仅当field尚未存在于哈希表当中,将它的值设置为value
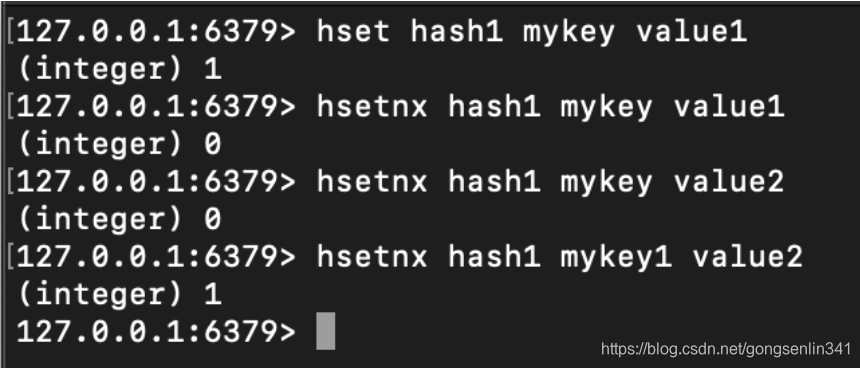
若给定的field已经存在于哈希表当中,则不进行覆盖,返回0.否则执行设置键值对返回1.
5.2 hget
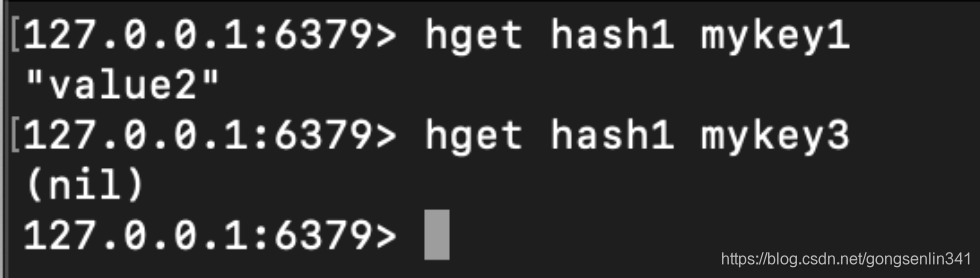
使用方法:hget hash field
返回哈希表hash当中 键为field的值。
不存在返回nil
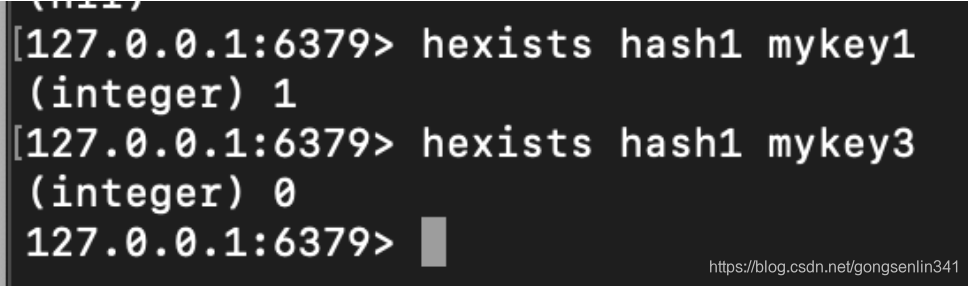
5.3 exists
使用方法:exists hash field
和上面的类似,只是这里是判断哈希表hash中是否存在键field
存在返回1 不存在返回0
5.4 hdel
使用方法:hdel hash field [field …]
删除哈希表hash当中一个或多个指定键的键值对,不存在的键会被忽略掉。返回删除成功的键值对的数量。

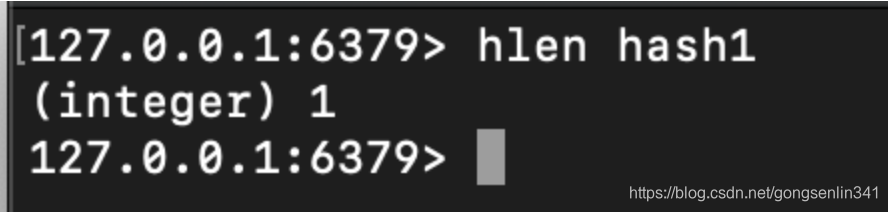
5.5 hlen
使用方法:hlen hash
返回哈希表hash当中 键值对的数量
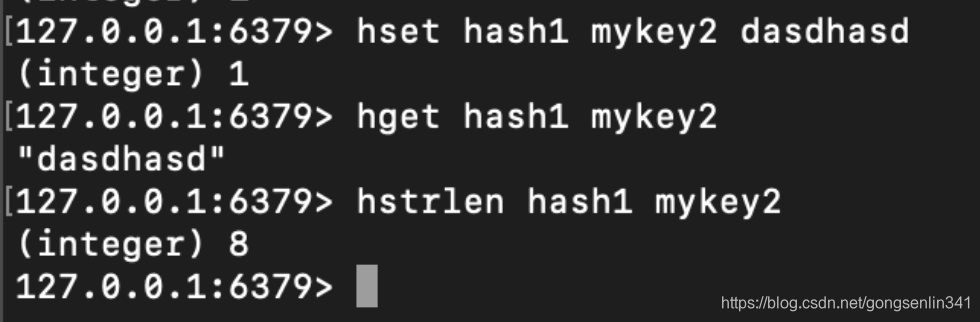
5.6 hstrlen
使用方法:hstrlen hash field
返回指定的哈希表hash当中的键为field对应的值的长度。
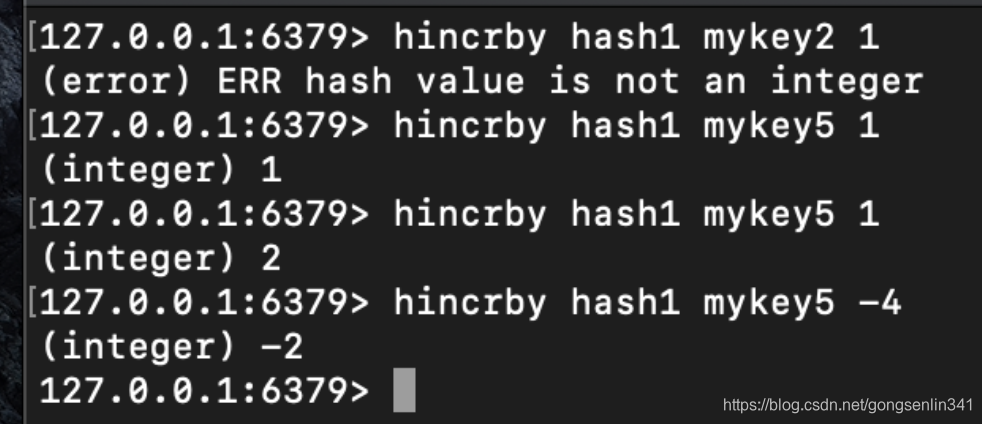
5.6 hincrby/hincrbyfloat
- hincrby
使用方法:hincrby hash field increment
给指定的哈希表hash 中的field键对应的value值加上increment
增加的值可以是负数,相当于执行了减法操作。
-
若哈希表hash不存在,则会新建一个哈希表并执行命令。
-
若field不存在,那么在执行命令之前,会讲field对应的值初始化为0,然后执行hincrby
-
对一个字符串的值执行hincrby 会抛出错误。
-
hincrbyfloat
和上面的区别在于,这里是浮点数的变动。
5.7 hmset
使用方法:hmset hash field value [field value …]
和hset的区别在于,这个指令可以同时讲多个键值对设置到哈希表hash当中。

5.8 hmget
使用方法:hmget hash field [field …]
返回指定哈希表hash当中键为field的值,可以是多个
若不存在则返回nil
5.9 hkeys/hvals
-
hkeys
使用方法 :hkeys hash
返回哈希表 hash中所有的键

-
hvals
使用方法:hvals hash
返回哈希表hash中所有键对应的值
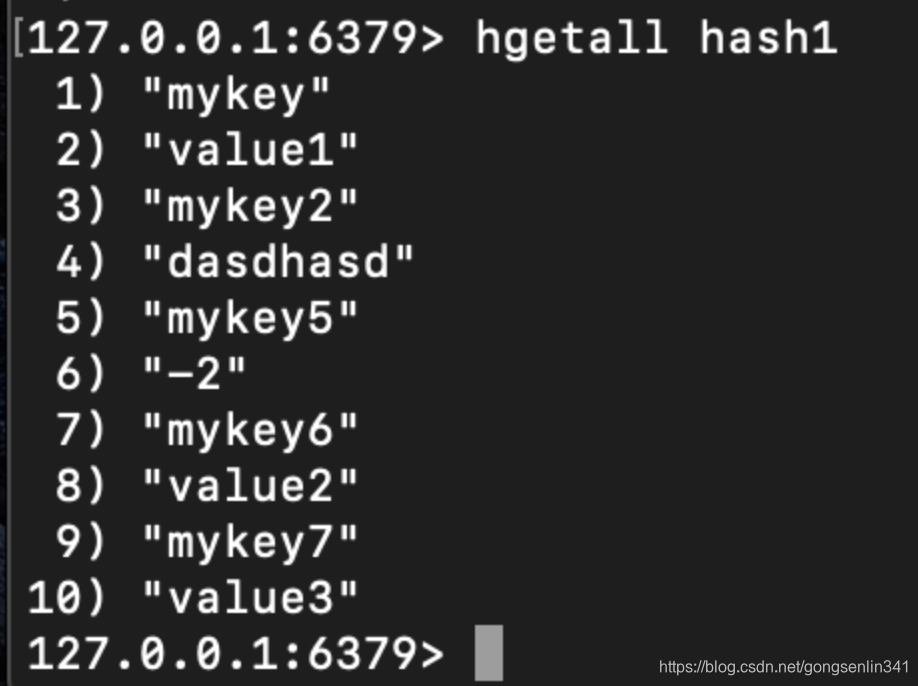
5.10 hgetall
使用方法:hgetall hash
返回哈希表hash中所有的键值对,键在前值在后的输出