1. 问题
压缩列表在Redis中用来存储哪些类型的数据?
2. 介绍
压缩列表是redis为了节省内存而开发的,由一系列特殊编码的连续内存块组成的有序数据结构。
用途: zset键,哈希键
3. 底层实现
说明:
ziplist_bytes: 四个字节,记录占用总字节数
ziplist_tail_offset: 四个字节,代表第一个节点距离最后一个节点的字节数
ziplist_length: 两个字节,代表entry节点个数
zlentry: 压缩列表实体
oxFF: 一个字节,代表固定结束符
zlentry数据结构
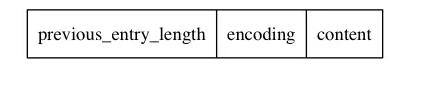
说明: previous_entry_length代表前一个节点的总字节数
encoding代表压缩列表存储数据的格式,可以存储16位,32位,64位的整数以及字符串
content代表具体的内容
4. 注意点
当哈希对象可以同时满足以下两个条件时, 哈希对象使用
ziplist编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于
64字节;- 哈希对象保存的键值对数量小于
512个;- 不满足上述条件,会使用hashtable
连锁更新:
假设原本 entry1 节点占用字节数为 211(小于 254),那么 entry2 的 previous_entry_length 会使用一个字节存储 entry1的字节数211,现在我们新插入一个节点 NEWEntry,这个节点比较大,占用了 512 个字节。
那么,我们知道,NEWEntry 节点插入后,entry2 的 previous_entry_length 存储不了 512,那么 redis 就会重分配内存,增加 entry2 的内存分配,并分配给 previous_entry_length 五个字节存储 NEWEntry 节点长度。
看似没什么问题,但是如果极端情况下,entry2 扩容四个字节后,导致自身占用字节数超过 254,就会又触发后一个节点的内存占用空间扩大,非常极端情况下,会导致所有的节点都扩容,这就是连锁更新,一次更新导致大量甚至全部节点都更新内存的分配。
5. 测试