文章目录
一, MapReduce概述
1.1 MapReduce定义
- MapReduce是一个分布式程序的编程框架, 是用户开发"基于Hadoop的数据分析应用"的核心框架.
- MapReduce 核心功能是将用户编写的
业务逻辑代码和自带默认组件整合成一个完成的分布式运算程序, 并发运行在Hadoop集群上.
1.2 MapReduce优缺点
| 优点 | 缺点 |
|---|---|
| 易于编程(只需实现一些接口, 就能完成分布式程序) | 不擅长实时性计算(做不到秒回计算结果) |
| 良好的扩展性(简单的增加机器来提升算力) | 不擅长流式计算(数据源只能是静态的而不是动态的) |
| 高容错性(节点挂了,自动转移计算) | 不擅长DAG计算(因为输出结果都保存在磁盘上, DAG会造成大量的磁盘IO) |
| PB以上海量数据的离线处理 | \ |
1.2.1 优点
1.MapReduce易于编程
用户只关心业务逻辑, 实现一些简单的接口- MR 简单的实现一些接口, 就可以完成一个分布式程序, 这个分布式程序可以分布到大量廉价的PC机器上运行. 也就是说你写一个分布式程序, 跟写一个简单的串行程序是一模一样的. 正因为此特点, MapReduce编程变得非常流行.
2. 良好的扩展性
- 当计算资源得不到满足时, 我们可以通过简单的
增加机器来扩展MR的计算能力.
3. 高容错性
- MR的设计初衷是使程序能够部署在廉价的PC机器上, 这就要求它具有较高的容错性. 比如
其中的一台机器挂了, MR可以把上面的计算任务转移到另外一个节点运行. 不至于这个任务运行失败, 而且这个过程不需要人工参与, 完全是Hadoop内部完成的.
4. 适合PB以上海量数据的离线处理
- 可以实现上千台服务器集群并发工作, 提供数据处理能力.
1.2.2 缺点
1. 不擅长实时计算
- MR无法像Mysql一样, 在毫秒或者秒级内返回结果.
2. 不擅长流式计算
- 流式计算(SparkStreaming, flink)的输入数据是动态的, 而MR的输入数据是静态的, 不能动态变化. 这是因为MapReduce自身的设计特点决定了数据源必须是静态的.
3. 不擅长DAG(有向无环图)计算
DAG-多个应用程序存在依赖关系, 后一个程序的输入为前一个程序的输出结果.这种情况下, 每个MapReduce作业的输出结果都会写入到磁盘, 会造成大量的磁盘IO, 导致性能非常的低下. Spark就比较擅长.
1.3 MapReduce 的核心思想

- 分布式的运算程序往往需要分成至少2个阶段;
- 第一个阶段的MapTask并发实例, 完全并发运行, 互不相干.
- 第二个阶段的ReduceTask并发实例互不相干, 但是他们的数据依赖于上一个阶段的所有MapTask并发示例的输出.
- MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段, 如果用户发业务逻辑非常复杂, 那就只能多个MapReduce程序, 串行运行.
1.4 MapReduce进程
- 一个完整的MapReduce程序在分布式运行时有
三类实例进程:- MrAppMaster : 负责整个程序的过程调度和状态协调.
- MapTask : 负责Map阶段的整个数据处理流程.
- ReduceTask : 负责Reduce阶段的整个数据处理流程.
1.5 官方WordCount源码, 1.6 常用数据序列化类型

源码: (算了不贴了, 下面自己实现加深理解)
1.7 MapReduce 编程规范
- 用户编写的程序分为三个部分: Mapper, Reduce 和 Driver
[Mapper阶段]
- 用户自定义的Mapper要继承自己的父类Mapper.
- Mapper的输入数据是K-V的对的形式.
- Mapper的业务逻辑写在main()中.
- Mapper的输出数据是K-V对的形式.
- map()(即MapTask进程)对每个<K,V>调用一次.
[Reduce阶段]
- 用户自定义的 Reduce要继承自己的父类Reducer.
- Reducer的输入数据类型对应Mapper的输出数据类型, 也是K-V.
- Reducer的业务逻辑写在reduce()中.
- 重要:
ReduceTask进程对每一组相同k的<k,v>调用一次reduce().至于为什么, 请看后面的几篇关于Shuffle机制的文章.
[Driver阶段]
- 相当于YARN集群的客户端, 用于提交我们的整个程序到YARN集群, 提交的是封装了MapReduce程序相关运行参数的job对象.
1.8 WordCount 案例实操
大致思想:

- 为了实现一个WordCount实例, 我们在IDE中新建一个Maven项目, 在pom文件中写好相应的依赖, 并配置好log4j以能够方便的显示日志信息.
- 新建Maven项目, 填写GAV, 配置POM文件依赖(主要是hadoop, junit, log4j)如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
- 在Maven项目的 src->main->resources 目录下新建
log4j.properties并输入下面的配置:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- 接下来我们在src->main->java目录下创建一个包cn.qsc.mapreduce.wordcount, 并在包内新建一个
WordCountMapper.java文件
-
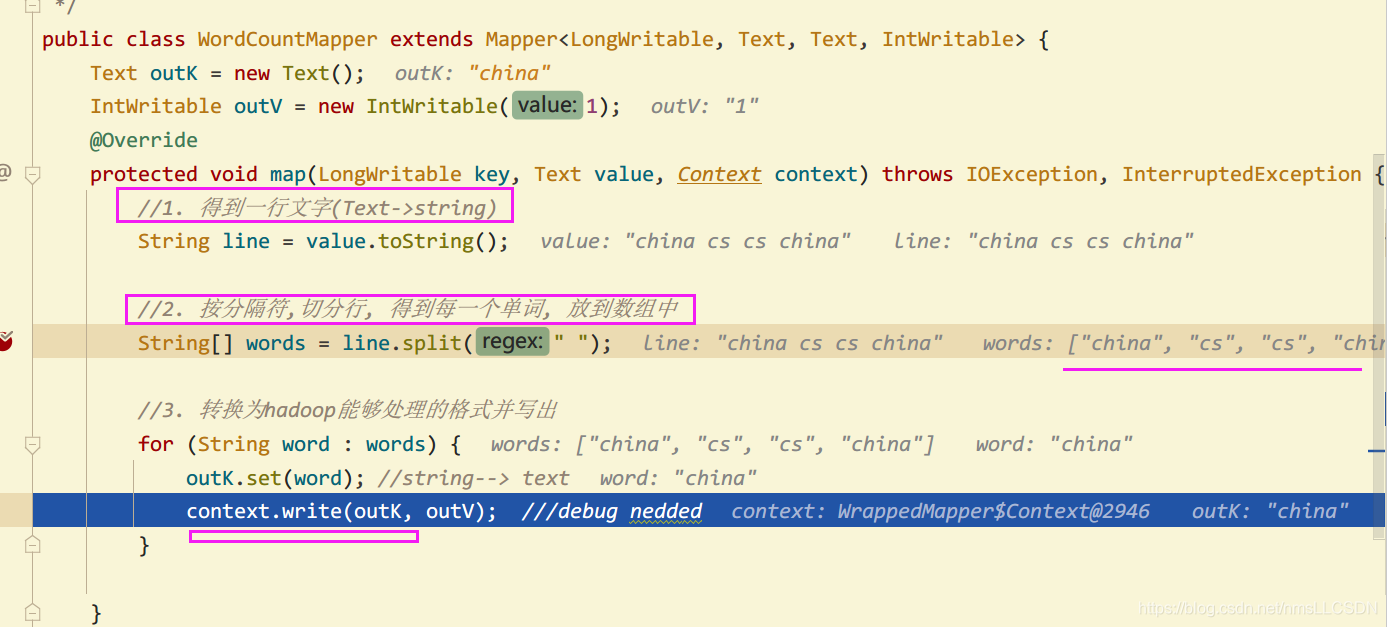
在MapReduce的WordCount案例中, Mapper(此处指 WordCountMapper.calss)的任务是读入每一行单词, 并用特定的符号(空格)分割出每一个单词, 然后以<单词,1>的数据类型输出
-
具体代码如下:
package cn.qsc.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* KEYIN, map阶段输入的key(数据类型: longWritable);该行的首字母相对于文本文件首地址的偏移量(切记不要忘记 回车一个+ 换行一个)
* VALUEIN, map阶段输入的value(数据类型: text); 文本文件的一行字符串, 以回车为结束标志
* KEYOUT, map阶段输出的key(数据类型: text); 一个个的单词
* VALUEOUT, map阶段输出的value(数据类型: IntWritable);单词个数, map阶段不计算, 默认为1
*/
// ctrl + p 显示方法参数类型
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//这两行跳过直接看下面的map方法
//为了节省时间复杂度(map方法一行被调用一次, map方法内的切割, 一个单词就被调用一次, 所以) //
Text outK = new Text();
//map阶段不进行聚合(也就是计算单词重复次数), 我们只需要进行切割, 所以输出的VALUEOUT都是1
IntWritable outV = new IntWritable(1);
/**
*
* @param key 偏移量
* @param value 代指文件中的一行字符串(Text类型的), 如果要分割记得先转换为String类型
* @param context 上下文, Mapper通过它跟reducer, 系统进行联络
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1. 获取一行value
//usb usb
//因为value是text类型的字符串但没有字符串相关的方法, 所以value 转换为String类型, 进行字符串相关的操作
String line = value.toString();
//2. 切割
//usb
//usb
String[] words = line.split(" "); //按空格切割(如何切割根据原始数据来定), 并把每个单词存到String类型的数组
//3. 遍历String数组words, 并把单词转换为Text格式
//因为Mapper的输出是<key,Value> key是单个的单词(Text类型), value=1(IntWritable类型)
//Q: 如何把String-> Text? text对象.set(string)
//同时为了避免每次处理一行字符串的时候都进行Text对象创建浪费资源,
// 我们把text对象作为全局变量
for (String word : words) {
//把words(stirng类型)转换为text类型, 即Text k = new Text(); k.set(word);
// 这里为了减少复杂度, 把 k的新建操作提到了全局变量的位置
outK.set(word);
//以<key,value>--<单词, 1>的形式写出
//同样, 为了减少时间复杂度, 把输出的单词个数(即VALUEOUT) outV的新建操作提到了全局变量的位置
context.write(outK,outV); //对应于MAPPER的KEYOUT和VALUEOUT
}
}
}
- 接下来新建
WordCount.java文件实现对字符串计数
- 具体代码如下:
package cn.qsc.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**reducer把Mapper的输出结果作为其输入
* KEYIN, Mapper阶段的输出key(Text类型), 指的是一个个的单词, 可以重复
* VALUEIN, Mapper阶段的输出value(IntWritable类型), 就是数字1
* KEYOUT, Reducer阶段的输出key(Text类型), 指的是一个个独一无二的单词
* VALUEOUT, Reducer阶段的输出value(IntWritable类型), 每个单词出现次数的和
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable ouTV = new IntWritable();
/**
*
* @param key reduce阶段输入的key的类型(text);;; 一个个的单词
* @param values 如: key: sb, values(集合): (1,1)
* @param context 上下文
*
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
//累加每个key(单词)出现的次数
for (IntWritable value : values) {
sum += value.get();
}
ouTV.set(sum);
//写出
context.write(key, ouTV);
}
}
- 接下来新建
WordCountDriver.java七步套路, 熟记即可.
package cn.cyy.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1. 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2. 设置jar包路径
job.setJarByClass(WordCountDriver.class);
//3. 关联Mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4. 设置Mapper输出的key-value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5. 设置最终输出的key-value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6. 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\user\\wordcount\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\user\\wordcount\\output"));
//7. 提交job
//verbose为true, 监控并打印信息
boolean res = job.waitForCompletion(true);
System.exit(res ? 1 : 0);
}
}
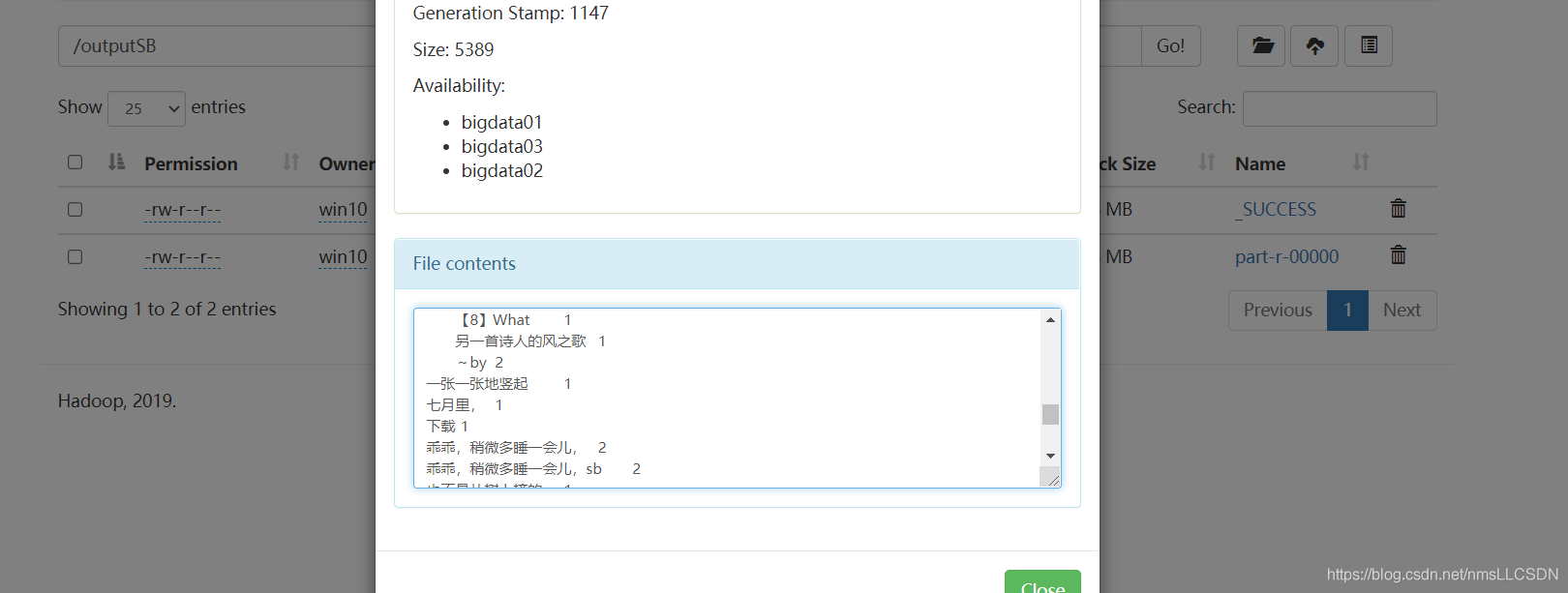
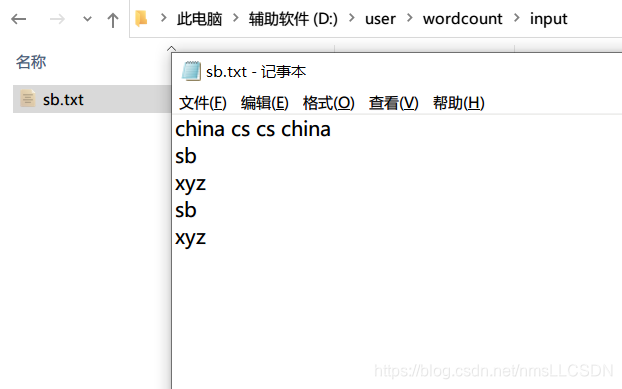
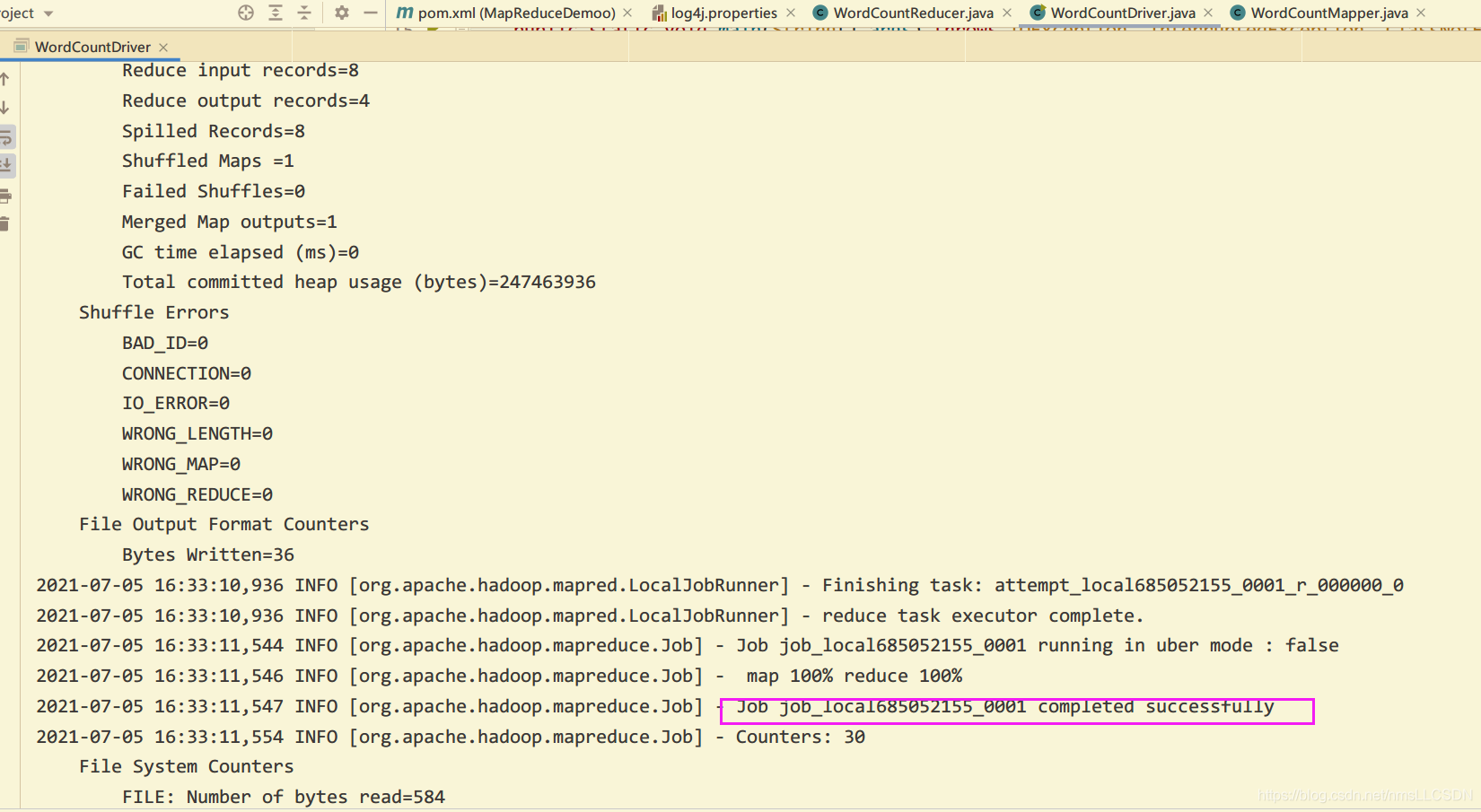
验证:
-
输入文本文件路径和内容如下图:
-
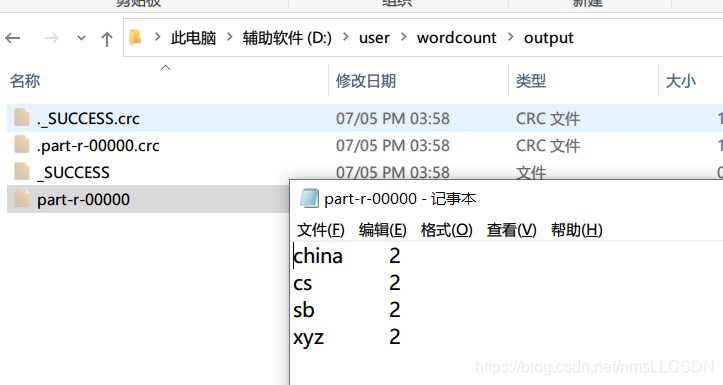
WordCount输出路径和输出结果如下图:
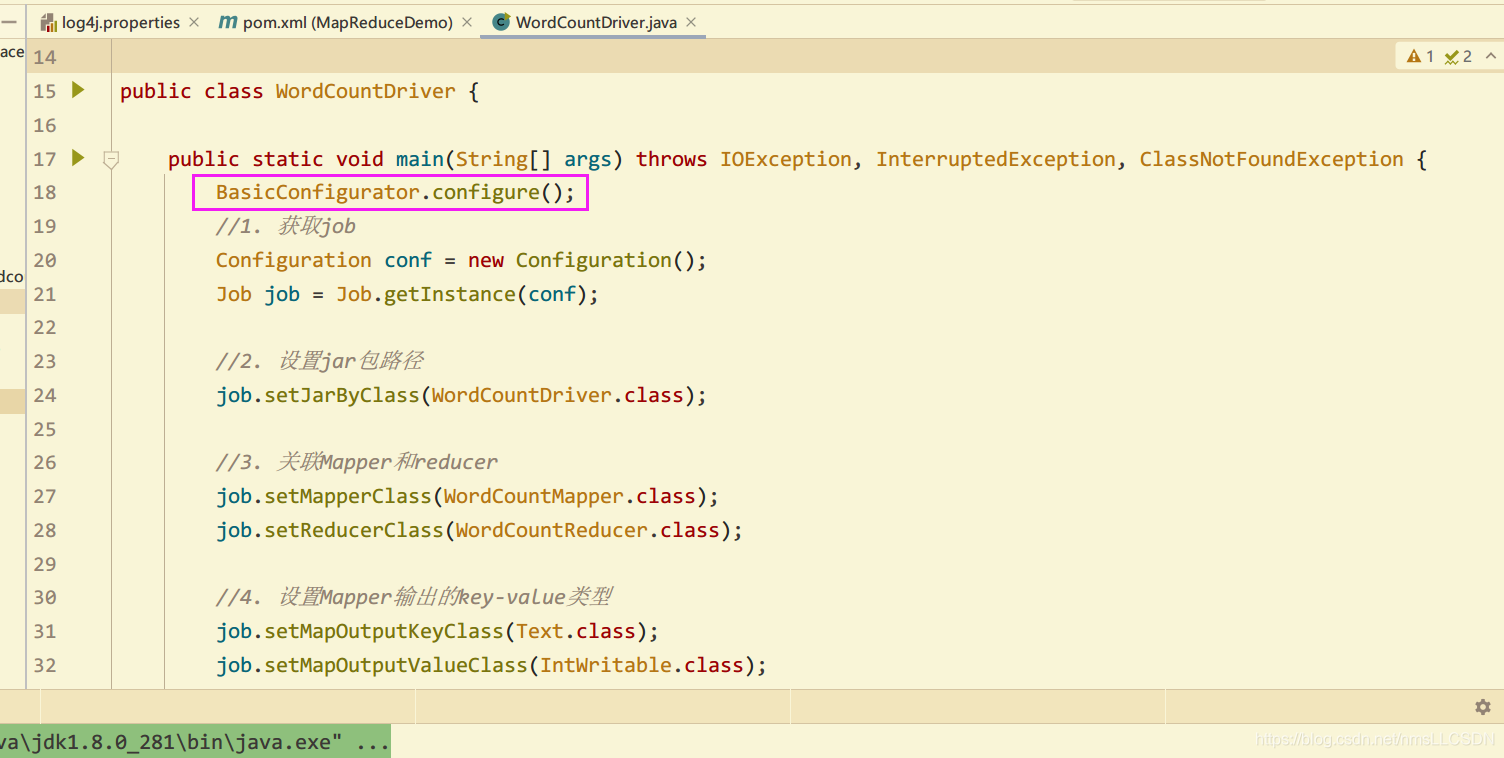
在执行中可能遇到的问题及其解决办法
关于log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).的问题
- 书写上面代码需要记住的几个点
- 继承类时候, 不要忘记填写类泛型.
- IntWritable value -->Int s,
s = value.get();(类型转换的方法) - Int s–> IntWritable value,
IntWritable value = new IntWritable(s);或者是
IntWritable val; val.set(s)
1.9 通过Debug了解WordCount的详细执行过程
注意,
本文中DEBUG只关注Mapper 和 Reduce工作的过程,至于Mapper之前的(Job提交), 从Mapper到Reduce之间的(Shuffle), Reduce之后的过程在后面重点写文章.
断点情况:
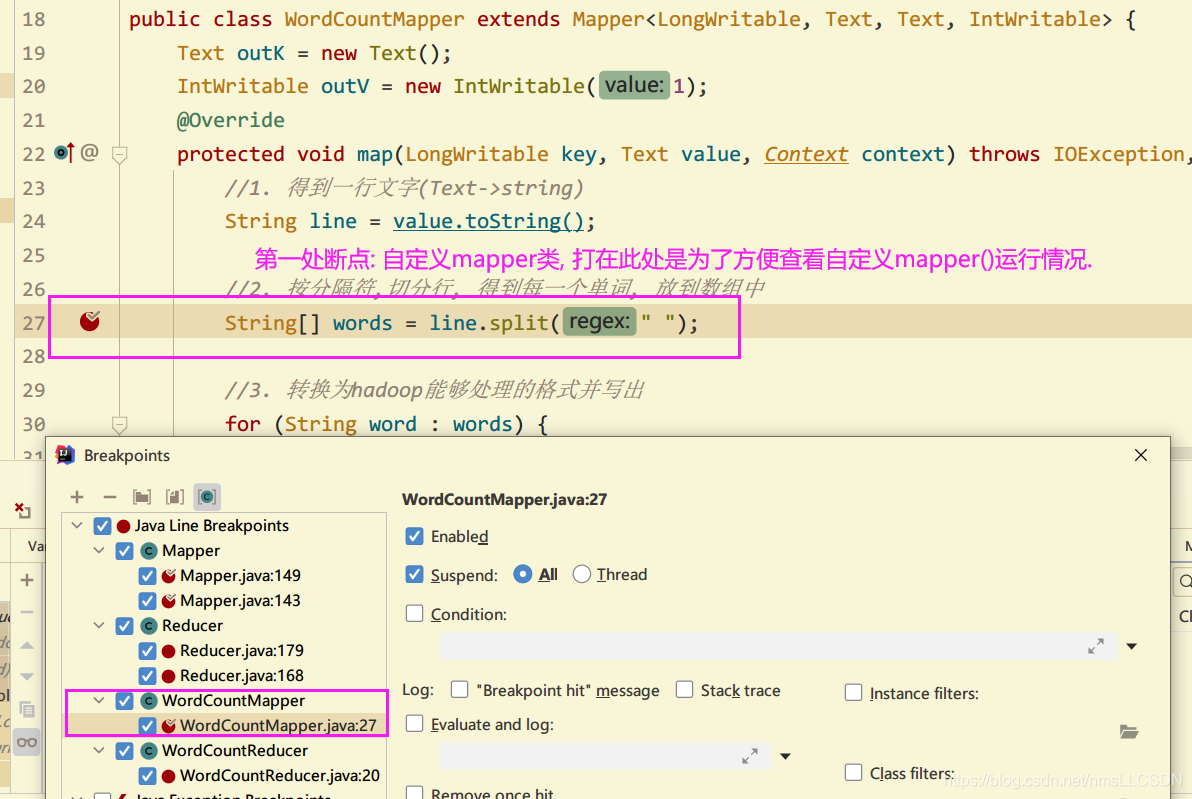
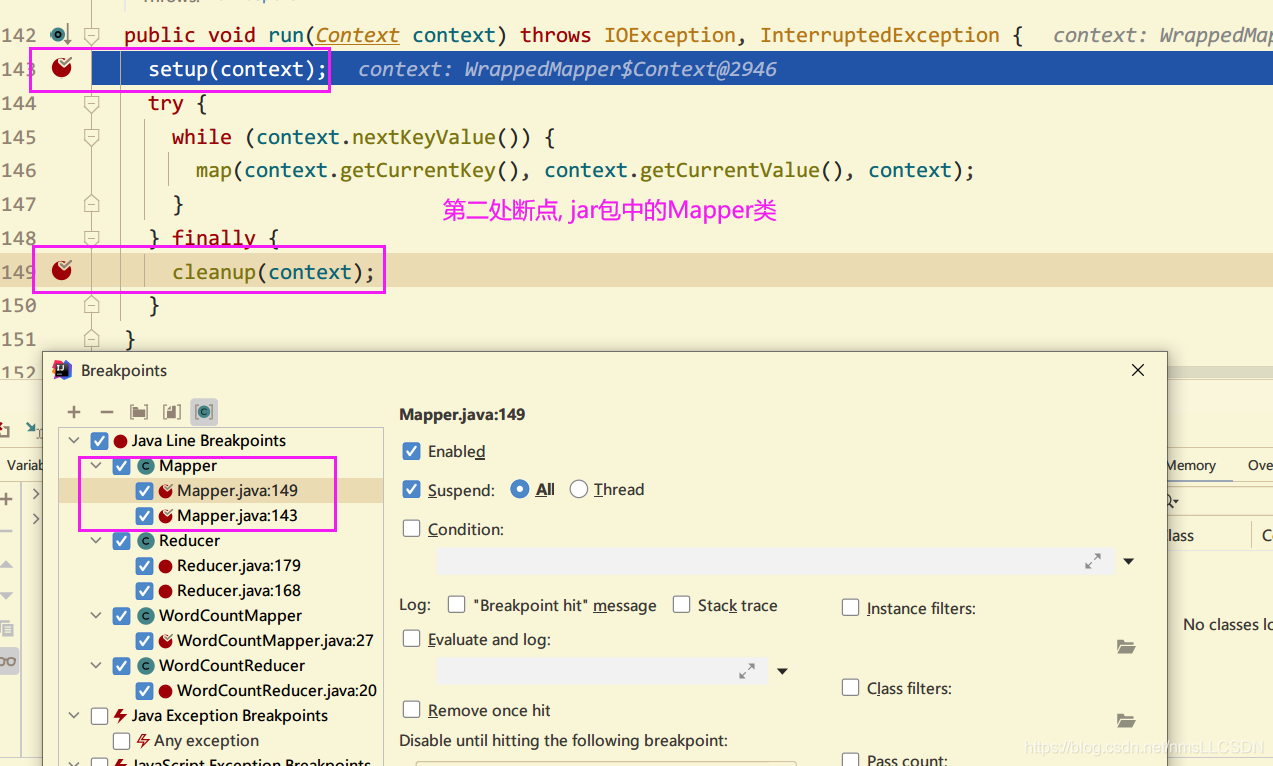
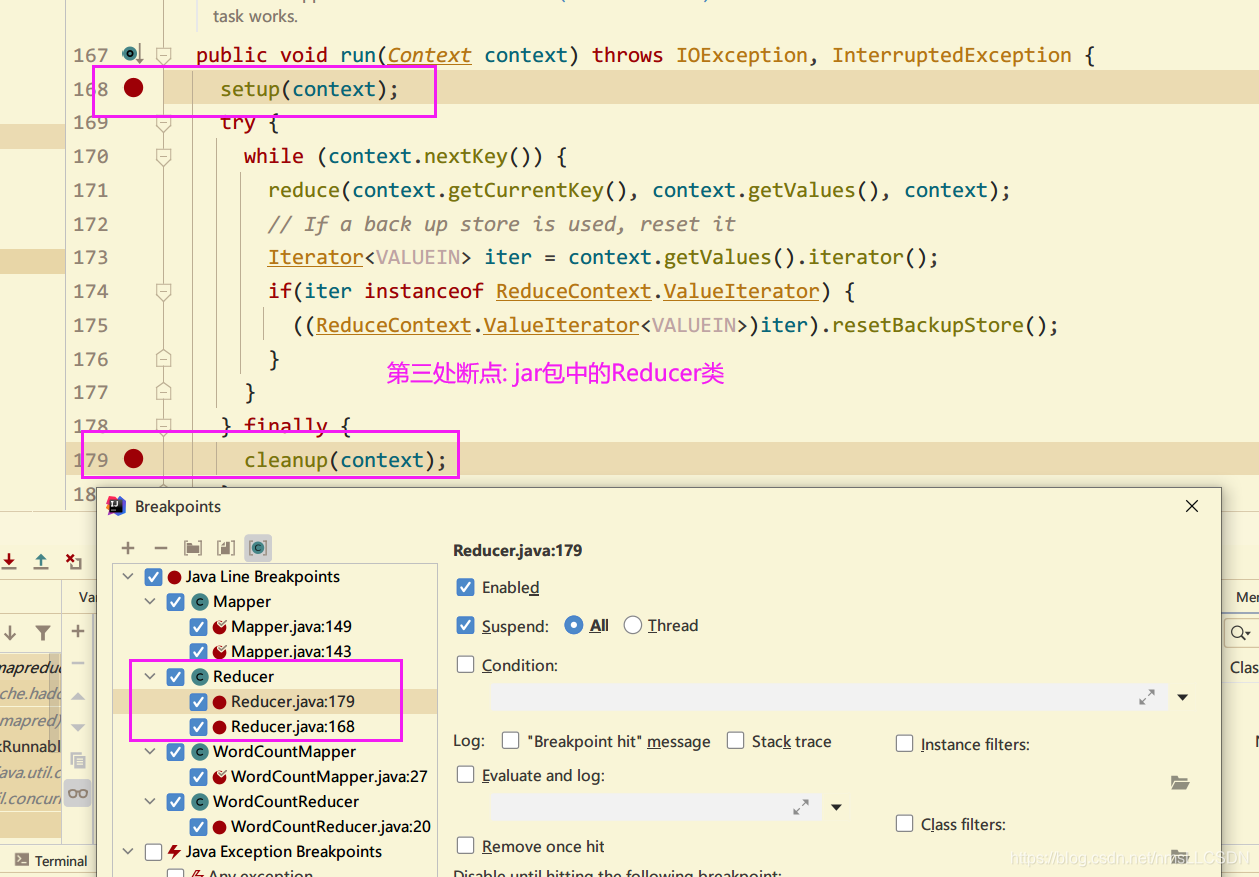

断点执行情况:
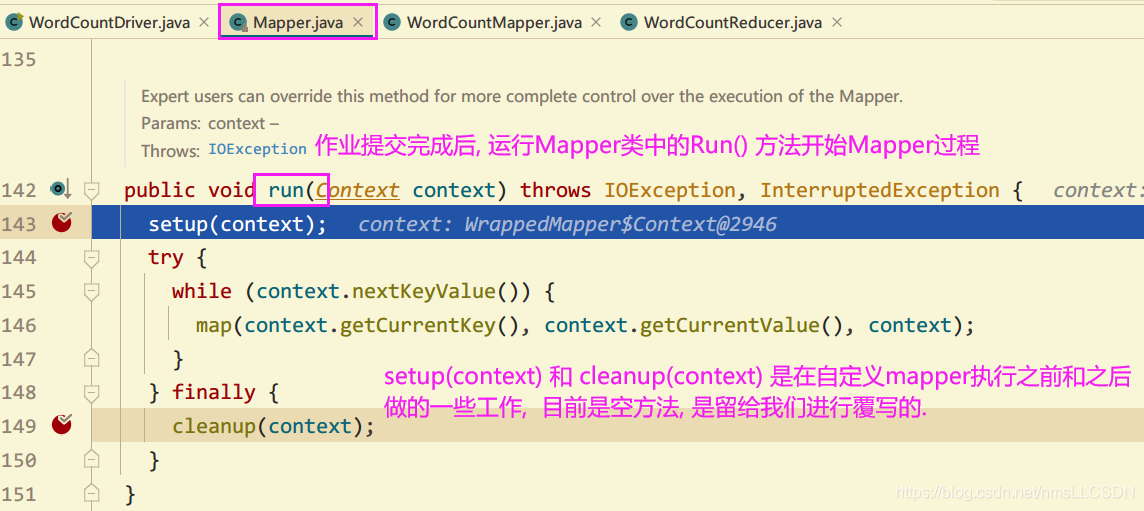
while(context.nextKeylValue()) --> 此方法表示文件还有内空时候, 继续进入自定义Mapper方法内, 每一行就循环一次, 调用自定义mapper处理一次.
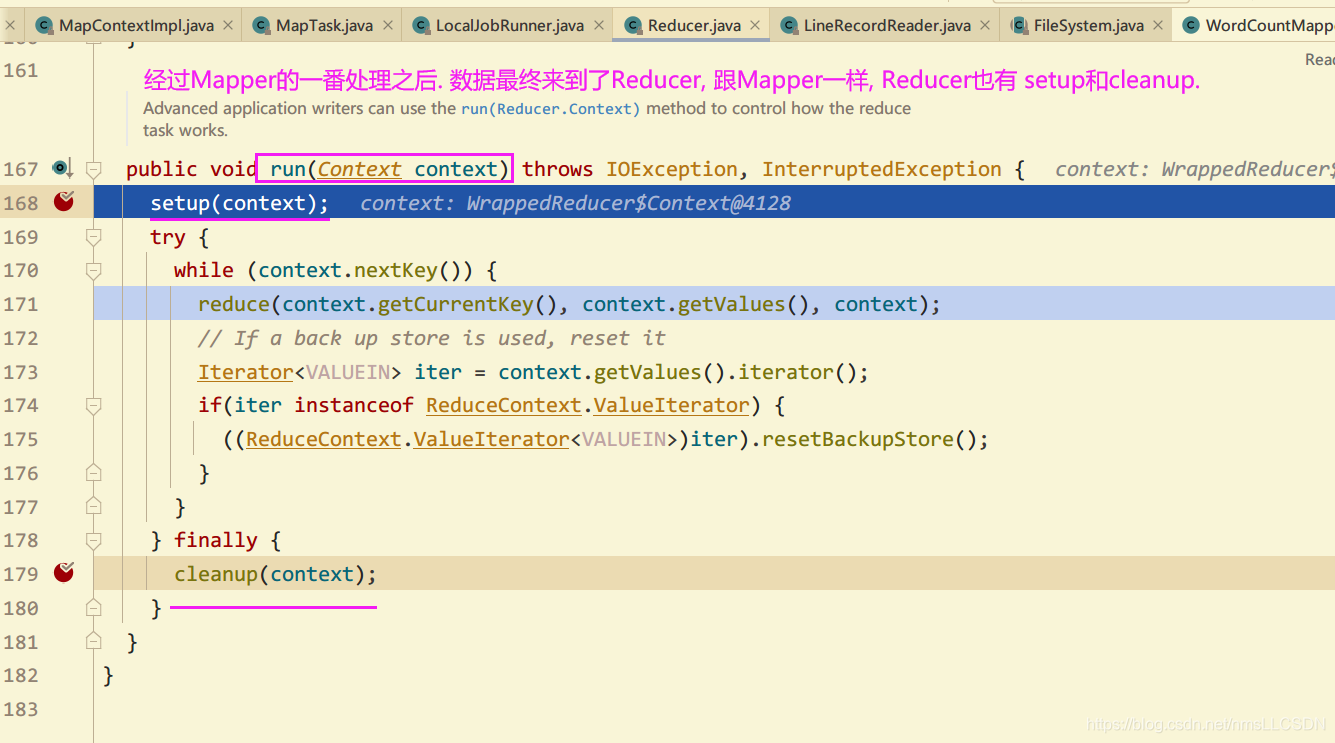
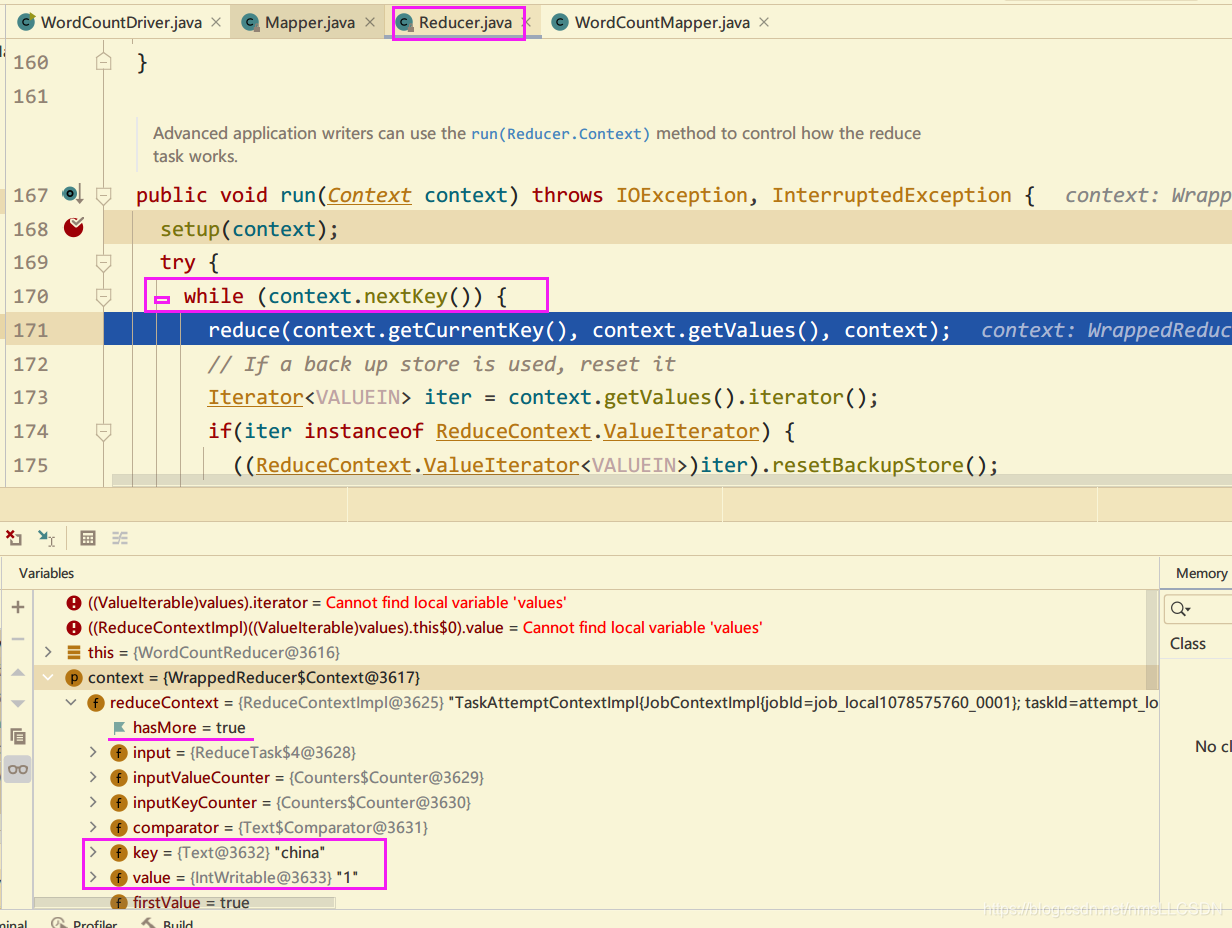
1.10 把1.8自己编写的WordCount打成Jar包放到Hadoop集群内运行
注意: 因为我们本来在Windows上运行本地集群, 输入和输出目录都是指定了Windows上的磁盘目录的, 要是上传到了Linux集群上应当如何再去指定呢?
- 之前在使用官方的WordCount 案例时, 我们是在输入执行命令时顺便把输出和输出的目录给指定了的.
- 那么我们打包自定义的WordCount应该做怎样的修改呢 ? 简单, 把path()中的路径参数改为args[xx]即可, 意思就是直接从main方法处获取输入的参数
如下图所示
- 本地运行下:

- Linux集群下:

- 修改上面所说的输入输出路径之后, 我们开始把Maven项目打包成Jar包.
- 注意: 要是把依赖的环境也打包的话, 需要在pom.xml文件中添加以下内容
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
- 在Maven的生命周期里面选择 package开始打包, 并把生成的jar包随便起个名拉到集群中去.

- 开启集群, 在shell里面执行命令如下:
注意: Driver必须要全类名
hadoop jar sb.jar cn.cyy.wordcount.WordCountDriver /input /outputSB
- 在HdFS管理页面查看输出文件: