SQL语言
创建与修改
虽然我知道像datagrip这种GUI点一下鼠标就能完成了但是考虑到这样对于期末考试来说还是很不友好所以我还是要讲一下这种基操
创建与删除数据库
create database mydb
drop database mydb
创建数据表
create table mytab(
name char(10),
number char(20)
);
设置完整性约束
create table mytab(
name char(10) not null,# 不能为空
number char(20) primary key,# 主键约束
gender char(5) check(sex in('男','女'))# check约束,mysql无法使用,但语法不报错
grade int foreign key(自己要约束列名) references 其它表名(表名里要约束的列名)# mysql里面需要添加一句constraint
);
删除表
drop table 表名;
基本表的修改
alter table 表名 add 新列名 数据类型 约束,
alter table 表名 add constraint 约束名 约束,
drop column 列名,
drop constraint 约束名,
alter column 列名 数据类型,
但是我还是喜欢用modify,比上面那个容易记住多了
alter table 表名 add 新列名 数据类型 约束,
alter table 表名 modify 列名 数据类型 约束,
alter table 表名 drop column 列名/约束名,
如果要删除完整性约束的列,那么必须先删除完整性约束
选择与查询
创建与删除索引
create 索引类别 index 索引名 on 表名(列名),
drop index 索引名 on 表名,
单表查询
select 列1,列2
from 表名1,表名2
where 条件
group by 列名 having 条件,//group by 的作用是将查询结果按此列名的值进行分组,与列值相等的为一组,having 则只会使满足条件的组才被筛选出来
order by 列名 asc/desc,//按照列名升序或降序
查询列
select 列1,列2
from 表名
select * from 表名//查询此表所有
查询经过计算的值
//例如,这YEAR是返回日期的年份
select YEAR(列名1)
from 表名;
//别名使用
select pname,'Age is:' page,YEAR(GETDATE())-YEAR(birth) age
from patient;
//那么,查询结果的列名就是:pname,page,age,而且page还全是Age is
查询元组
//去除相同行
select distinct 列名
from 表名;
where细讲
//可用到的字符
比较:=,>,<,>=,<=,!=,<>,!>,!<
确定范围:between and,not between and
确定集合:in,not in
字符匹配:like,not like
空值:is null,is not null
逻辑运算:and or not
几个where典型案例
where dep='内科';
where fee<500;
where birth between '2010-01-01'and'2020-04-01';
where dep not in('内科','呼吸科');
where name like '匹配串' escape '\';//其中,%代表任意长度,_代表任意单个字符,escape转义
where tel is null;
where dep='内科' and title='主任医师';
查询结果排序
查询语句末尾加上
order by 列名 asc/desc
简单统计查询
count(distinct/all *)//统计记录个数
count(distinct/all 列名)//统计一列中值的个数
sum(distinct/all 列名//计算一列(int型)的总和
avg(distinct/all 列名)//计算一列(int型)的平均值
max(distinct/all 列名)//求一列中的最大值
min(distinct/all 列名)//求一列中的最小值
几个统计查询典型案例
select count(distinct *)
from doc;
//在聚集函数遇到空值时,除count(*)外,都跳过空值而只处理非空值
分组查询
//查询重复的姓名
select dname,count(*)
from doc
group by dname
having count(*)>1;
//where用于基表和视图,having用于组(group/order by)
复合查询
等值与非等值连接查询
select doc.*,curefee.*,patient.*
from doc,patient,curefee
where doc.dID=curefee.dID
and patient.pID=curefee.pID;
自然连接:若在等值连接中把重复属性列去掉则为自然连接
select 没有重复的属性列
from doc,patient,curefee
where doc.dID=curefee.dID
and patient.pID=curefee.pID;
自身连接
//同一张表的连接称为自身连接,但是需要给别名以示区别
select second.dname,second.title
from doc first,doc second
where first.dname='王丹' and first.dep=second.dep;
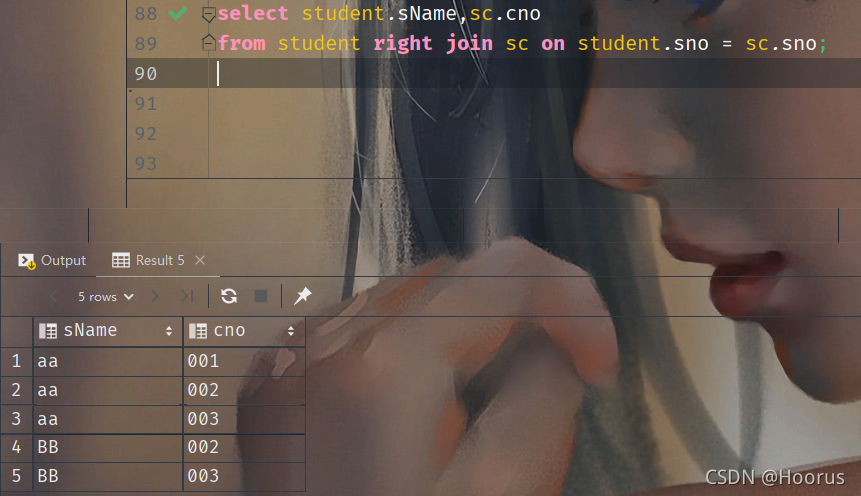
外连接
//将主题表中不满足连接条件的记录一并输出
select doc.*,curefee.pID,curefee.fee
from doc left join curefee on doc.dID=curefee.dID;
外连接实例:
 自然连接示例
自然连接示例
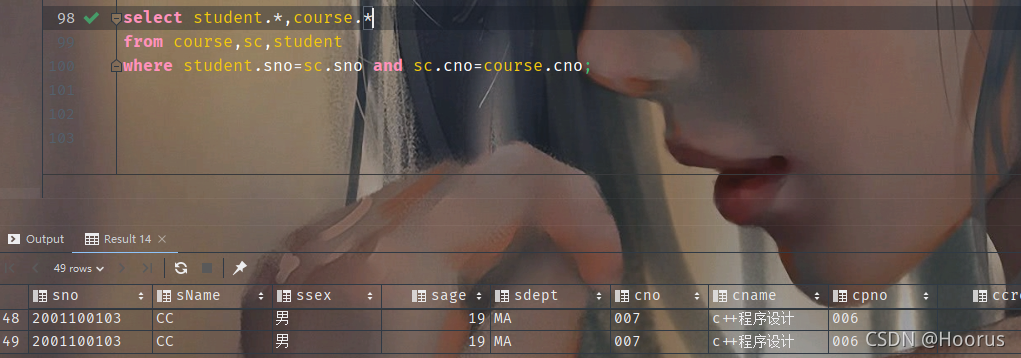
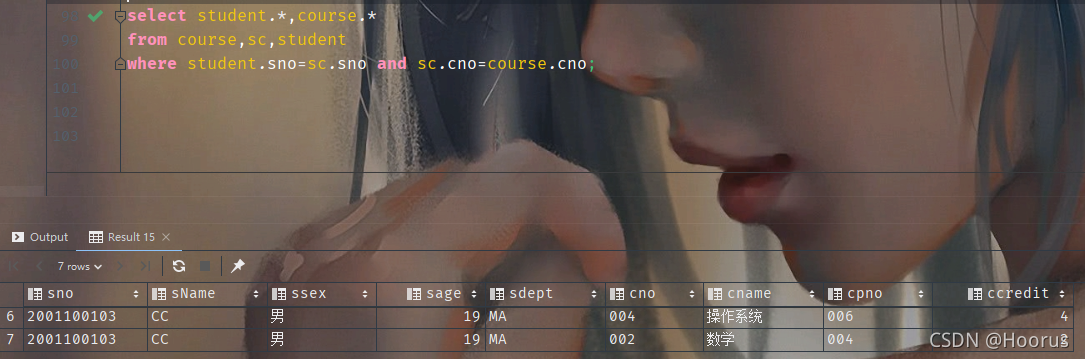
可以经过对比发现,这两个表的关系是数据量与数据量的平方。这是新手很容易碰到的情况–数据突然多出来很多,因为二维关系表(矩阵)会因为部分条件未约束而进行全笛卡尔乘积,导致多出了n*(n-1)个数据。因此,千万记住要充分考虑条件约束
嵌套查询——in的使用
select dname
from doc
where dID in
(select dID
from curefee
where pID='p4');
集合查询
mysql不支持差集和交集
//union用于合并与去重查询结果
insert into 数据库名.数据表名(列名)values(相应数据);
delete from 数据库名.表名 where 列名=相应数据;
视图
//创建、删除与修改视图
create view 视图名(列名)
as
查询语句
with check option;
drop view 视图名;
alter view 视图名
as
select pname,sex
from patient;
//插入、修改与删除
insert into 视图名 value(列名)
delete from 表名 where 约束
习题解答
什么是视图 ?视图和基本表之间的主要区别是什么?
视图:用户查看数据库的一种方式,从一个或多个基本表(或视图)中导出的表
区别:视图是虚表,用户可以通过他来浏览表中感兴趣的部分或全部数据,而数据的物理存放位置仍然在于基本表中。当基本表的数据发生变化时,视图的数据也随之改变。视图定义好后,可以像基本表一样查询,更新,删除,但在更新操作上有一定的限制。
视图的作用是什么?
①使不同用户以不同角度看待同一问题
②可以根据需要定制数据,保证数据安全
③可以简化查询操作
④可以简化应用程序开发
⑤对重构数据库提供了一定程度的逻辑独立性